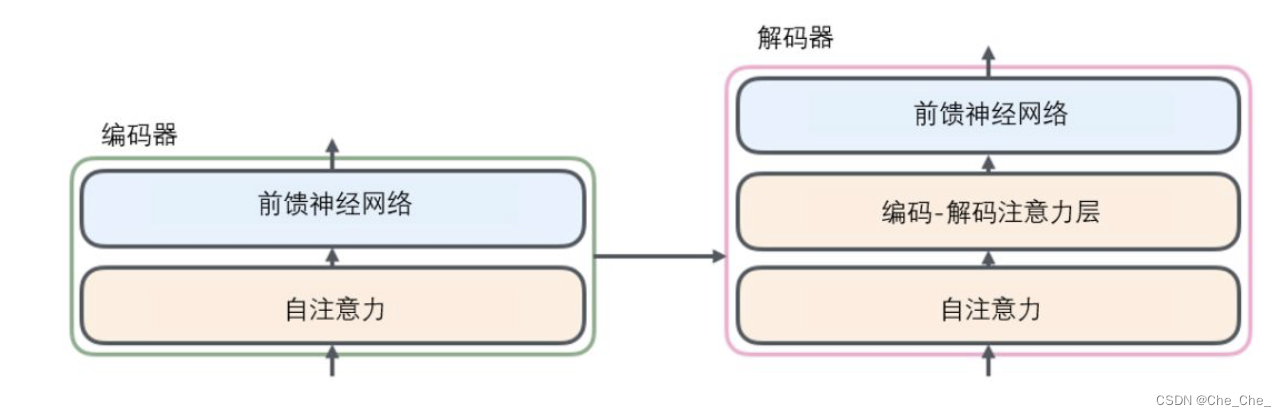
背景&前言
不知道你们做爬虫的时候,有没有碰到和我一样的情况:将页面提取成纯文本的时候,由于页面中各种链接、加粗字体等,直接提取会造成结果一坨一坨的,非常不规整。有时候还要自己对标题等元素进行修改,麻烦的很。最好呢,有个判断元素类型的方法,能让我们看碟下菜。恰好呢,网上又没有这样的文章,于是乎我就来将一下我在互联网冲浪带回来的经验。
精华
那么如何判断元素类型呢?用name()函数。不过还有一个难点,就是怎么判断当前元素,这个网上文章比较少。怎么办呢?答案是直接调函数。
if item.xpath("name()") == "ul":print("哈哈,被我判断出来了")或者加上contains()函数一起:
if item.xpath("contains(name(), 'ul')"):print("哈哈,又被我判断出来了")下面就再介绍一下我碰到具体问题的情况吧。
问题
直接解析提取页面的文本时,会出现非常不规整的结果。
原页面:

页面源代码:

基本是ul-li下有链接a、字体小花样strike等。
直接打印提取代码:
# 定位节点
div = html.xpath("//div[contains(@class,'content-entity-body')]//text()")# 提取
for item in div:print(item)直接提取打印结果:

可以看到结果很乱。
解决方法
方法一
判断当前元素,分别进行处理。
提取代码:
# 定位节点,注意这里和之前的方法也不同了
div = html.xpath("//div[contains(@class,'content-entity-body')]")[0]# 提取
for item in div:if item.xpath("contains(name(), 'ul')"):# if item.xpath("name()") == "ul": # 这样也行for li in item.xpath("./li"):text += ''.join(li.xpath(".//text()")) + '\n'else:text += ''.join(item.xpath(".//text()")) + '\n'结果:

结果好多了。
方法二
土路子,绕过这个问题,直接判断子节点,因为ul后必跟li。这当然不失为一种办法。
提取代码:
# 定位节点
div = html.xpath("//div[contains(@class,'content-entity-body')]")[0]# 提取
for item in div:# if item.xpath("name()") == "ul":# if item.xpath("contains(name(), 'ul')"):if item.xpath("./li"): # 直接判断子节点for li in item.xpath("./li"):text += ''.join(li.xpath(".//text()")) + '\n'else:text += ''.join(item.xpath(".//text()")) + '\n'结果同上。





![[机器学习]简单线性回归——梯度下降法](https://img-blog.csdnimg.cn/direct/87a9d033ecfa4544a34c1b4261c32d75.png)