目录
一、窗口函数的知识点
1.1 窗户函数的定义
1.2 窗户函数的语法
1.3 窗口函数分类
1.4 前后函数:lag/lead
二、实际案例
2.1 股票的波峰波谷
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 前后列转换(面试题)
0 问题描述
1 数据准备
2 数据分析
3 小结
一、窗口函数的知识点
1.1 窗户函数的定义
窗口函数可以拆分为【窗口+函数】。窗口函数官网指路:LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundation![]() https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
- 窗口:定义函数计算范围(窗口函数:针对分组后的数据,从逻辑角度指定计算的范围,并没有从物理上真正的切分,只有group by 是物理分组,真正意义上的分组)
- 函数:定义函数计算逻辑
- 窗口函数的位置:跟sql里面聚合函数的位置一样,from -> join -> on -> where -> group by->select 后面的普通字段,窗口函数 -> having -> order by -> lmit 。 窗口函数不能跟聚合函数同时出现。聚合函数包括count、sum、 min、max、avg。
- sql 执行顺序:from -> join -> on -> where -> group by->select 后面的普通字段,聚合函数-> having -> order by -> limit
1.2 窗户函数的语法
<窗口函数>window_name over ( [partition by 字段...] [order by 字段...] [窗口子句] )
- window_name:给窗口指定一个别名。
- over:用来指定函数执行的窗口范围,如果后面括号中什么都不写,即over() ,意味着窗口包含满足where 条件的所有行,窗口函数基于所有行进行计算。
- 符号[] 代表:可选项; | : 代表二选一
- partition by 子句: 窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行。分组间互相独立。
- order by 子句 :每个partition内部按照哪些字段进行排序,如果没有partition ,那就直接按照最大的窗口排序,且默认是按照升序(asc)排列。
- 窗口子句:显示声明范围(不写窗口子句的话,会有默认值)。常用的窗口子句如下:
rows between unbounded preceding and unbounded following; -- 上无边界到下无边界(一般用于求 总和)rows between unbounded preceding and current row; --上无边界到当前记录(累计值)rows between 1 preceding and current row; --从上一行到当前行rows between 1 preceding and 1 following; --从上一行到下一行rows between current row and 1 following; --从当前行到下一行ps: over()里面有order by子句,但没有窗口子句时 ,即: <窗口函数> over ( partition by 字段... order by 字段... ),此时窗口子句是有默认值的-> rows between unbounded preceding and current row (上无边界到当前行)。
此时窗口函数语法:<窗口函数> over ( partition by 字段... order by 字段... ) 等价于
<窗口函数> over ( partition by 字段... order by 字段... rows between unbounded preceding and current row)
需要注意有个特殊情况:当order by 后面跟的某个字段是有重复行的时候, <窗口函数> over ( partition by 字段... order by 字段... ) 不写窗口子句的情况下,窗口子句的默认值是:range between unbounded preceding and current row(上无边界到当前相同行的最后一行)。
因此,遇到order by 后面跟的某个字段出现重复行,且需要计算【上无边界到当前行】,那就需要手动指定 窗口子句 rows between unbounded preceding and current row ,偷懒省略窗口子句会出问题~
ps: 窗口函数的执行顺序是在where之后,所以如果where子句需要用窗口函数作为条件,需要多一层查询,在子查询外面进行。
【例如】求出登录记录出现间断的用户Id
selectid
from (selectid,login_date,lead(login_date, 1, '9999-12-31')over (partition by id order by login_date) next_login_date--窗口函数 lead(向后取n行)--lead(column1,n,default)over(partition by column2 order by column3) 查询当前行的后边第n行数据,如果没有就为nullfrom (--用户在同一天可能登录多次,需要去重selectid,date_format(`date`, 'yyyy-MM-dd') as login_datefrom user_loggroup by id, date_format(`date`, 'yyyy-MM-dd')) tmp1) tmp2
where datediff(next_login_date, login_date) >=2
group by id;-
窗口函数本身也有执行顺序: <窗口函数>over ( partition by order by 窗口子句 )的执行顺序:over -> partition by -> order by -> 窗口子句 -> 函数
1.3 窗口函数分类
哪些函数可以是窗口函数呢?(放在over关键字前面的)
-
聚合函数
sum(column) over (partition by .. order by .. 窗口子句);
count(column) over (partition by .. order by .. 窗口子句);
max(column) over (partition by .. order by .. 窗口子句);
min(column) over (partition by .. order by .. 窗口子句);
avg(column) over (partition by .. order by .. 窗口子句);ps : 高级聚合函数:
collect_list 收集并形成list集合,结果不去重;
collect_set 收集并形成set集合,结果去重;
举例:
--每个月的入职人数以及姓名select
month(replace(hiredate,'/','-')),count(*) as cnt,collect_list(name) as name_list
from employee
group by month(replace(hiredate,'/','-'));/*
输出结果
month cn name_list
4 2 ["宋青书","周芷若"]
6 1 ["黄蓉"]
7 1 ["郭靖"]
8 2 ["张无忌","杨过"]
9 2 ["赵敏","小龙女"]*/-
排序函数
rank() 、row_number() 、dense_rank() 函数不支持自定义窗口子句。
-- 顺序排序——1、2、3
row_number() over(partition by .. order by .. )-- 并列排序,跳过重复序号——1、1、3(横向加)
rank() over(partition by .. order by .. )-- 并列排序,不跳过重复序号——1、1、2(纵向加)
dense_rank() over(partition by .. order by .. )-
前后函数
-- 取得column列的前n行,如果存在则返回,如果不存在,返回默认值default
lag(column,n,default) over(partition by order by) as lag_test
-- 取得column列的后n行,如果存在则返回,如果不存在,返回默认值default
lead(column,n,default) over(partition by order by) as lead_test-
头尾函数
---当前窗口column列的第一个数值,如果有null值,则跳过
first_value(column,true) over (partition by ..order by.. 窗口子句) ---当前窗口column列的第一个数值,如果有null值,不跳过
first_value(column,false) over (partition by ..order by.. 窗口子句)--- 当前窗口column列的最后一个数值,如果有null值,则跳过
last_value(column,true) over (partition by ..order by.. 窗口子句) --- 当前窗口column列的最后一个数值,如果有null值,不跳过
last_value(column,false) over (partition by ..order by.. 窗口子句) 1.4 前后函数:lag/lead
lead和lag函数,这两个函数一般用于计算差值,上面已介绍其语法。lag和lead函数不支持自定义窗口子句。
-- 取得column列的前n行,如果存在则返回,如果不存在,返回默认值default
lag(column,n,default) over(partition by order by) as lag_test
-- 取得column列的后n行,如果存在则返回,如果不存在,返回默认值default
lead(column,n,default) over(partition by order by) as lead_test二、实际案例
2.1 股票的波峰波谷
0 问题描述
求股票的波峰Crest 和 波谷trough
波峰:当天的股票价格大于前一天和后一天
波谷:当天的股票价格小于前一天和后一天1 数据准备
create table if not exists table2
(id int comment '股票id',dt string comment '日期',price int comment '价格'
)comment '股票价格波动信息';insert overwrite table table2 values
(1,'2019-01-01',10001),
(1,'2019-01-03',1001),
(1,'2019-01-02',1001),
(1,'2019-01-04',1000),
(1,'2019-01-05',1002),
(1,'2019-01-06',1003),
(1,'2019-01-07',1004),
(1,'2019-01-08',998),
(1,'2019-01-09',997),
(2,'2019-01-01',1002),
(2,'2019-01-02',1003),
(2,'2019-01-03',1004),
(2,'2019-01-04',998),
(2,'2019-01-05',999),
(2,'2019-01-06',997),
(2,'2019-01-07',996);2 数据分析
此题容易理解,利用lag()和lead()函数便可以解决。
selectid,dt,price,casewhen price > lag_price and price > lead_price then 'crest'when price < lag_price and price < lead_price then 'trough'end as price_type
from (selectid,dt,price,lag(price, 1) over (partition by id order by dt) as lag_price,lead(price, 1) over (partition by id order by dt) as lead_pricefrom table2) tmp1;3 小结
lead和lag函数一般用于计算当前行与上一行,或者当前行与下一行之间的差值。在用户间断登陆问题中也遇到过此函数。指路:HiveSQL题——用户连续登陆-CSDN博客文章浏览阅读220次,点赞4次,收藏3次。HiveSQL题——用户连续登陆https://blog.csdn.net/SHWAITME/article/details/135900251?spm=1001.2014.3001.5501
2.2 前后列转换(面试题)
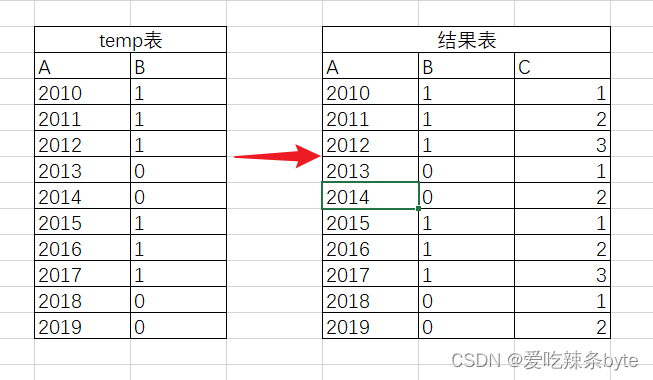
0 问题描述
表temp包含A,B 两列,使用SQL对该B列进行处理,形成C列。按照A列顺序,B列值不变,C列累计技术 B列值变化,则C列重新开始计数,如图所示
1 数据准备
with table4 as (select 2010 as A,1 as Bunion allselect 2011 as A,1 as Bunion allselect 2012 as A,1 as Bunion allselect 2013 as A,0 as Bunion allselect 2014 as A,0 as Bunion allselect 2015 as A,1 as Bunion allselect 2016 as A,1 as Bunion allselect 2017 as A,1 as Bunion allselect 2018 as A,0 as Bunion allselect 2019 as A,0 as B
)2 数据分析
with table4 as (select 2010 as A,1 as Bunion allselect 2011 as A,1 as Bunion allselect 2012 as A,1 as Bunion allselect 2013 as A,0 as Bunion allselect 2014 as A,0 as Bunion allselect 2015 as A,1 as Bunion allselect 2016 as A,1 as Bunion allselect 2017 as A,1 as Bunion allselect 2018 as A,0 as Bunion allselect 2019 as A,0 as B
)selectA,B,row_number() over (partition by T order by A) as C
from (selectA,B,--over (order by A) 本质是 :over(order by rows between unbounded preceding and current row )--省略的是:上无边界到当前行sum(change) over (order by A) Tfrom (selectA,B,-- 向上取一行,取不到的记为0lag(B, 1, 0) over (order by A) as Lag,casewhen B <> lag(B, 1, 0) over (order by A) then 1else 0end as changefrom table4) tmp1) tmp2;3 小结
lead /lag函数常用于差值计算。