概念
先看看ElasticSearch的整体架构:
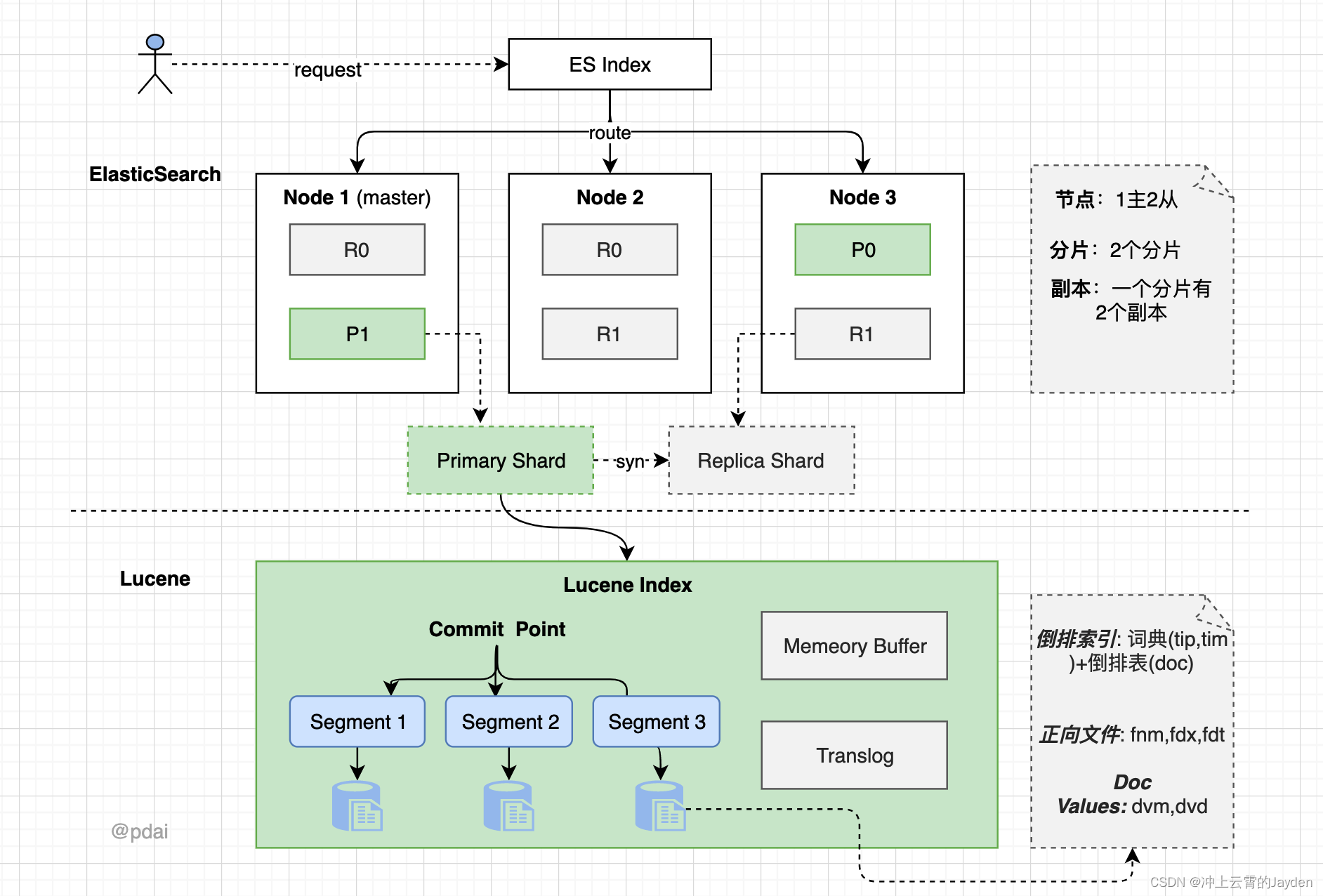
- 一个 ES Index 在集群模式下,有多个 Node (节点)组成。每个节点就是 ES 的Instance (实例)。
- 每个节点上会有多个 shard (分片), P1 P2 是主分片, R1 R2 是副本分片
- 每个分片上对应着就是一个 Lucene Index(底层索引文件)
Lucene Index 是一个统称
由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档。
commit point记录了所有 segments 的信息
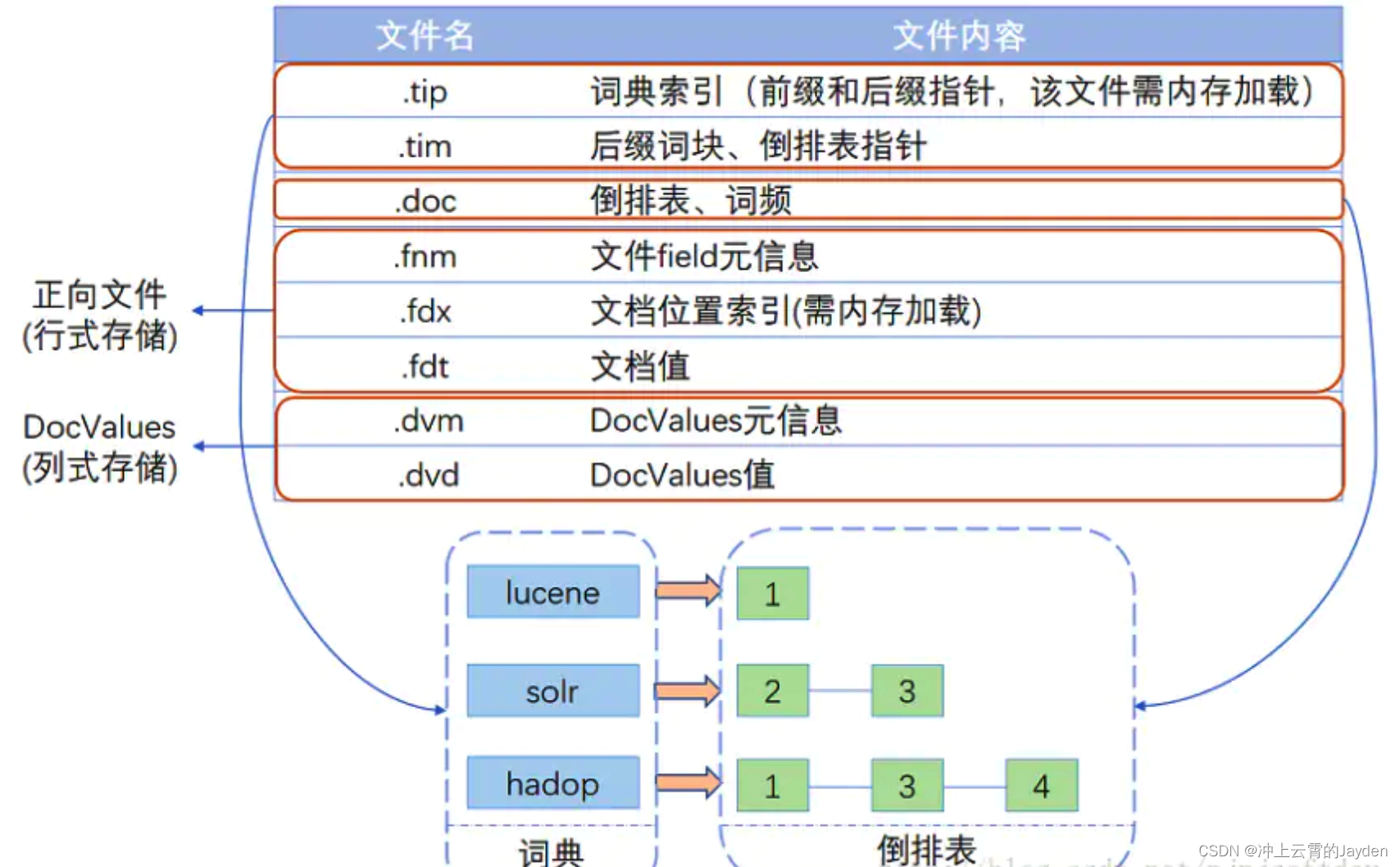
Lucene的索引结构中有哪些文件呢?
Lucene处理流程
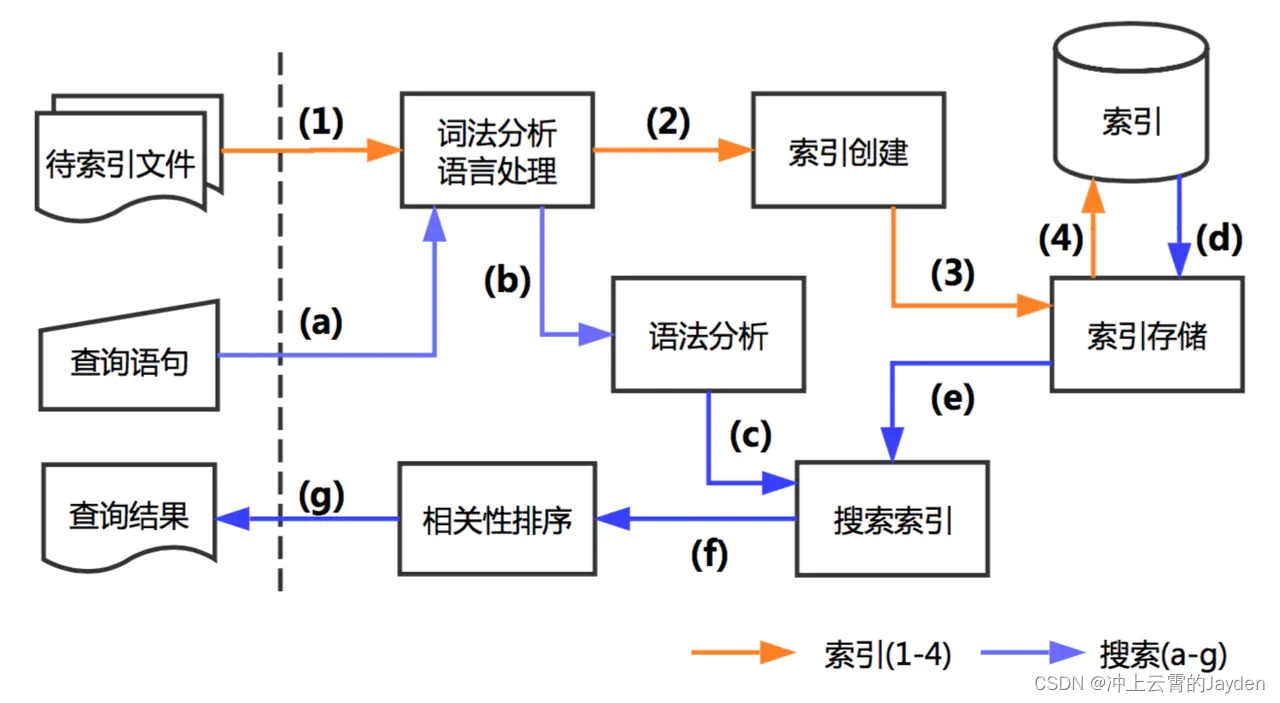
创建索引的过程:
- 准备待索引的原文档,数据来源可能是文件、数据库或网络
- 对文档的内容进行分词组件处理,形成一系列的Term
- 索引组件对文档和Term处理,形成字典和倒排表
搜索索引的过程:
- 对查询语句进行分词处理,形成一系列Term
- 根据倒排索引表查找出包含Term的文档,并进行合并形成符合结果的文档集
- 比对查询语句与各个文档相关性得分,并按照得分高低返回
语法分析/语言处理很重要的一项
语法分析首先,将一块文本分成适合于倒排索引的独立的 词条 ,之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall。
语法分析由分析器执行,
- 字符过滤器 首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML,或者将 & 转化成 and。
- 分词器 其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
- Token 过滤器 最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化 Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump 和 leap 这种同义词)。
Near Realtime(NRT)
近实时。数据提交索引后,立马就可以搜索到。
索引
在Elasticsearch中,索引是一种数据结构,用于存储和管理文档。它是所有可搜索数据的最小单位,类似于关系型数据库中的表。每个索引由若干个类型组成,类型又包含多个文档。
索引的主要作用是提高搜索效率。Elasticsearch使用了一种名为倒排索引的数据结构,它可以快速地找到包含特定关键词的文档。此外,索引还包含了关于文档结构和字段类型的信息,这些信息用于确定如何对文档进行索引和搜索。
在Elasticsearch中,索引的名称必须是小写的,并且不能包含任何特殊字符。每个索引都是独立的,可以在不同的服务器上进行分布式的存储和管理。
倒排索引
倒排索引(Inverted Index)是Elasticsearch的核心概念之一,它是一个用于快速查找文档的数据结构。倒排索引的主要组成部分包括:
- Term Dictionary(术语字典):这是一个存储所有Term(术语)的列表,Term是文档中的单词或短语。术语字典通常使用哈希表或其他数据结构来实现,以便快速查找Term。
- Term Index(术语索引):这是一个用于快速查找Term Dictionary中特定Term的索引。术语索引通常使用B树或其他平衡搜索树来实现,以便在O(log n)时间内找到Term。
- Posting List(倒排列表):这是每个Term对应的文档列表,包含了每个文档中该Term的出现频率和出现位置等信息。倒排列表可以帮助我们快速找到包含特定Term的所有文档。
倒排索引的工作原理是这样的:当我们想要搜索包含特定关键词的文档时,Elasticsearch会首先在Term Dictionary中找到这个关键词,然后在Term Index中找到这个关键词在Term Dictionary中的位置。最后,Elasticsearch会在Posting List中找到包含这个关键词的所有文档,并按照相关性对这些文档进行排序,返回给用户。
倒排索引的优点是它可以大大提高搜索效率,因为我们可以直接通过关键词找到相关的文档,而不需要遍历整个文档集合。此外,倒排索引还可以支持多种复杂的搜索功能,如模糊搜索、短语搜索和多关键词搜索等。
Type 类型
指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。
Document 文档
被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
TF(Term Frequency,词项频率)
TF 表示某个词项(term)在单一文档中出现的频率。它的计算方法是统计该词项在文档中出现的次数,并可能对其进行规范化处理以避免偏向较长的文档。具体来说,TF 值越高,表示该词项在文档中越重要。
DF(Document Frequency,文档频率)
DF 表示包含某个词项的文档数量。它用于衡量一个词项的普遍重要性或稀有性。一般情况下,DF 值较低的词项(即在较少的文档中出现)被认为对于查询更为重要,因为它们能更好地区分文档。
这两个指标通常用于计算 TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率),这是一种统计方法,用以评估一个词语对于一个文档集或一个语料库中的其中一份文档的重要程度。
其核心思想是:如果某个词语在一篇文章中出现的频率高(高 TF 值),且在其他文章中很少出现(高 IDF 值,即低 DF 值),则认为这个词语具有很好的类别区分能力,对文档的相关性贡献较大。
BM25
BM25是一种排名函数,用于估算与一个文档集合中的文档相对于查询的相关性。这种模型是在信息检索领域中广泛使用的,特别是作为一种全文搜索算法,比如Elasticsearch中的默认算法。
BM25是传统的TF-IDF(词频-逆文档频率)模型的变种,能够更好地处理长文档和查询。
BM25模型的名称来源于“Best Matching”,而25只是一个历史上的版本号。这个模型基于概率检索框架(Probabilistic Retrieval Framework),但它进行了一系列假设和近似,使其能够在实际应用中更高效。
以下是BM25评分模型的一些关键特征:
-
词频(TF, Term Frequency):BM25模型认为,一个词在文档中出现的次数越多,这个词越能代表文档的内容。然而,与基本的TF-IDF不同,BM25使用了词频的饱和度,即在一定程度上增加一个词的出现次数对评分的影响是有限的。
-
逆文档频率(IDF, Inverse Document Frequency):如果一个词在很少的文档中出现,那么它往往能提供较多的信息量,因此有较高的IDF分数。BM25同样采用了这个概念,但是它对IDF的计算方式做了一些调整。
-
文档长度:BM25考虑了文档的长度。长文档很可能包含更多的词,但并不一定是更相关的。因此,BM25引入了一个正规化参数,来调整文档长度的影响。
BM25评分函数通常表示为以下形式:
[ text{Score}(D,Q) = sum_{i=1}^{n} IDF(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})} ]
其中:
- ( D ) 是文档;
- ( Q ) 是用户查询;
- ( q_i ) 是查询中的第 ( i ) 个词;
- ( f(q_i, D) ) 是词 ( q_i ) 在文档 ( D ) 中的词频;
- ( |D| ) 是文档 ( D ) 的长度(词数);
- ( \text{avgdl} ) 是集合中所有文档的平均长度;
- ( k_1 ) 和 ( b ) 是可调参数,通常 ( k_1 ) 在 1.2 到 2.0 之间,( b ) 通常设为 0.75;
- ( IDF(q_i) ) 是词 ( q_i ) 的逆文档频率。
Elasticsearch中的BM25可以通过映射(mapping)和查询时的设置来调整参数,因此开发者可以根据自己的需求调整相关性评分的行为。例如,可以修改 ( k_1 ) 或 ( b ) 参数,以控制词频的饱和度和文档长度的影响。
BM25模型是一种非常灵活和有效的方法,能够准确地反映出查询词与文档之间的相关性,因此它被广泛应用在包括Elasticsearch在内的各种全文搜索和信息检索系统中。
分片(Shard)
Elasticsearch分片是指将索引拆分成多个部分的过程,这些部分可以分布在一个或多个节点上,从而提高性能和可伸缩性。在Elasticsearch中,索引是由一个或多个分片组成的。每个分片都是一个功能完整的搜索引擎,并且能够独立地执行数据存储、索引和搜索操作。分片的概念使得Elasticsearch可以处理大量数据并在多个服务器之间进行分布。
Elasticsearch如何分片:
当创建一个Elasticsearch索引时,可以指定该索引要使用的主分片(primary shard)数量。每个主分片都有其对应的复制分片(replica shard),复制分片的数量也可以指定。复制分片的主要目的是提供数据冗余,提高系统的容错能力,并且能够扩展搜索操作的处理能力。
Elasticsearch使用散列分配机制来决定文档将存储在哪个分片中。当文档被索引时,其ID(或者自定义的路由值)被用于计算一个散列。这个散列值接着被用于确定目标主分片,文档将存储在该主分片中,以及它的复制分片上。
在查询时如何使用分片:
当Elasticsearch处理查询时,查询被广播到索引中的所有分片(包括主分片和复制分片)。每个分片独立地执行查询并返回其结果。然后,这些结果被合并和排序,形成最终的查询结果集。
由于复制分片是主分片的完整副本,因此它们也用于查询操作。这意味着,如果有多个复制分片,Elasticsearch可以将查询负载均衡到不同的分片上,从而提高查询性能。
分片的使用使得Elasticsearch能够横向扩展,处理更大规模的数据集,也能够通过增加复制分片来提高查询吞吐量。但是,设定索引的分片数量是一个需要仔细考虑的决策,因为一旦索引创建后,主分片的数量将无法更改,且过多的分片可能导致资源浪费及降低性能。
在分片数据时和查询处理时,Elasticsearch内部进行了很多优化,以确保这一分布式过程对用户尽可能透明。开发者和管理员可以使用Elasticsearch API监控和管理分片,包括分片健康状态、重新分配分片等操作。
Elasticsearch中的数据是以索引的形式存储的,每个索引可以被分成多个分片(shards),这样可以实现数据的水平扩展和分布式搜索能力。下面详细解释数据的分片过程、分片存储位置以及分片大小。
数据如何分片
当你创建一个Elasticsearch索引时,你可以指定该索引要包含的主分片(primary shards)数量。每个文档在索引之前都会根据其唯一的_id字段经由哈希函数计算出应该存放在哪个分片中。Elasticsearch默认使用一种叫作"Uniform Resource Identifier" (URI) Search的哈希函数。
例如,如果你创建了一个包含5个主分片的索引,每个新的文档都会被哈希到这5个分片之一中。这个过程是自动的,确保了数据在分片之间的均匀分布。
分片存在哪里
分片被分布在整个Elasticsearch集群的节点上。Elasticsearch会自动处理数据的分配和重新分配,以保持集群负载均衡。当新节点加入到集群时,或者当节点失败时,分片可能会被重新分配到其他节点上。
在物理层面,分片实际上是存储在Elasticsearch节点的磁盘上的,每个节点可以存储多个分片。你可以通过配置文件来指定分片数据存储的具体位置。
分片大小
Elasticsearch并没有硬性规定每个分片的大小。分片的大小取决于你的使用案例和数据量。通常来说,一个分片的理想大小是几GB到几十GB。太大或太小的分片都可能对性能造成负面影响。
对于一个给定的索引,理想的主分片数量取决于:
- 索引预计的数据量
- 集群中可用硬件资源(如CPU、内存、磁盘)
为了保持良好的性能和扩展性,经常需要通过实验和监控来调整分片大小和数量,以适应不断变化的数据负载。
复制分片
除了主分片,Elasticsearch还允许你为每个索引创建复制分片(replica shards)。复制分片的数量也可以在创建索引时指定,以提高数据的可用性和分布式搜索的吞吐量。
复制分片是主分片的完整副本,可以在主分片不可用时提供数据,并且还可以分担读取操作的负载,从而提高搜索性能。
总结来说,Elasticsearch的分片机制提供了灵活的数据组织方式,可以根据实际需要和资源情况进行调整,以实现数据和搜索操作的水平扩展。
查询分片状态
1.查看索引的分配状态
get _cat/shards/mall_order_test?v
v:作用就是列出表头;
输出结果:
index shard prirep state docs store ip node
mall_order_test 0 p STARTED 4 8.6kb 10.14.128.231 es-cn-09k1wi493002cgixs-5e9acf7d-0001
mall_order_test 0 r STARTED 4 8.6kb 10.14.128.229 es-cn-09k1wi493002cgixs-5e9acf7d-0003
2.查看集群分片状态
GET /_cat/allocation?v
shards disk.indices disk.used disk.avail disk.total disk.percent host ip node427 92.9gb 103.8gb 92.8gb 196.7gb 52 10.14.128.229 10.14.128.229 es-cn-09k1wi493002cgixs-5e9acf7d-0003428 92.9gb 103.7gb 93gb 196.7gb 52 10.14.128.230 10.14.128.230 es-cn-09k1wi493002cgixs-5e9acf7d-0002427 95.2gb 121.6gb 75gb 196.7gb 61 10.14.128.231 10.14.128.231 es-cn-09k1wi493002cgixs-5e9acf7d-0001
输出包含每个节点的分片数量、磁盘空间统计、ip和名称信息。
映射(Mapping)
映射(Mapping)是定义文档及其包含的字段如何存储和索引的过程。每个文档都是字段的集合,每个字段都有自己的数据类型。为数据创建一个映射定义,包含与文档相关的字段列表。
类似MySQL定义的表结构。
停用词
什么是停用词?
停用词(Stop Words)是指在文本处理中,经常出现但通常不承载主要意义,并且对于理解文本的主旨没有或者有很少帮助的词语。这些词经常被搜索引擎和自然语言处理应用过滤掉,因为它们可能会干扰关键词的检索和分析。停用词的集合可以根据应用场景和目的不同而有所不同。
这里有一些英文和中文的常见停用词的例子:
英文停用词的例子:
- the
- is
- at
- which
- on
- for
- with
- without
- within
- through
- and
- or
- but
中文停用词的例子:
- 的
- 是
- 在
- 了
- 和
- 呢
- 啊
- 但是
- 还是
- 就是
- 那
- 这
- 与
这些词在语句中起到语法联系的作用,但在文本分析、信息检索(如搜索引擎索引)或数据挖掘等领域中,停用词不提供有意义的内容信息,因此往往会从处理流程中排除。在某些情况下,比如文本相似度计算或者风格分析,停用词可能会保留下来,因为它们能提供某种程度上的句子结构信息。
词干
词干是构成单词的基本部分,它通常包含了单词的主要意义。
在形态学中,从一个单词中去掉所有的前缀、后缀和词尾变化后,剩下的就是词干。词干可以用来生成单词的不同形式,例如:变换时态、数、性等。
例如,在英语中,动词“running”(跑步)的词干是“run”,通过添加不同的后缀可以得到如下单词:runs, ran, running等。又如名词“singer”(歌手)的词干是“sing”,它通过添加后缀“-er”形成了一个新的单词。
在一些其他语言中,词干的概念也非常重要。例如,在俄语或者拉丁语中,通过改变词干的形式或者添加不同的词尾,可以表达出不同的语法关系和词性变化。简单来说,词干是形态变化的基础,而词缀的添加则修改了词干的基础意义或者指明了单词的语法功能。
举个例子,对于英语单词“unhappiness”:
- “un-” 是一个否定的前缀
- “happy” 是词干,表示基本意义,即“快乐”
- “-ness” 是一个名词后缀,表示状态或者性质
这样,“unhappiness”这个词的词干是“happy”。通过前缀和后缀的添加,它变成了一个表达“不快乐的状态”的名词。
字段数据缓存(Field Data Cache)
字段数据缓存(filed data cache)是一种内存型的缓存,Elasticsearch在几种场合下都会使用它。
在text类型字段可以被搜索,但是不能聚合、排序和执行function_score脚本,不满足一些使用场景的。Elasticsearch通过设置字段fielddata(默认为false)使text了下字段既能搜索、聚合、排序和执行function_score脚本。Fielddata 参数说明
fielddate=true开启text字段词条加载到内存,此时可以配置fielddata_frequency_filter参数(包含min、max 配置可以是数值或者百分比)过滤特定词频的分词才加载到内存。fielddata_frequency_filter 参数说明。
fielddata数据是存在内存,内存大小的配置也是必须的,ElasticSearch Field Data Cache配置(indices.fielddata.cache.size)用于控制内存的使用。
对应内存使用情况Elasticsearch也提供了cat fielddata API:
GET /_cat/fielddata/<field>
GET /_cat/fielddata#使用例子
GET /_cat/fielddata?pretty=true&v
GET /_cat/fielddata/artId?pretty=true&v&format=json
字段数据缓存通常(但不总是)是在第一次需要使用时被构建,然后被保存用于不同的操作。如果有很多数据,这种加载的过程可能花费很长时间和很多的CPU资源,使得第一次搜索变得缓慢。
那么提前加载好数据提高查询效率变得尤为重要,预热器(warmer)就会有用武之地。
预热器是Elasticsearch自动运行的查询,以确保内部的缓存被填充,使得查询所用数据在其真正使用之前被预先加载。
为什么字段数据缓存是如此的有必要?
提升操作效率。Elasticsearch需要这种缓存,是因为许多比较和分析的操作,都会处理大量的数据。而在合理的时间内完成这些操作的唯一方式,是访问内存里的数据。Elasticsearch最大限度地降低了这种缓存所消耗的内存容量,但它仍然是Java虚拟机中堆空间的最大用户之一。
字段数据有那些使用场景呢?
- 按照某个字段进行排序。
- 在某个字段上进行聚集。
- 使用doc[‘fieldname’]的标注,访问某个字段的值。
- 在function score查询中,,使用field value factor函数
- 在function score查询中,使用decay衰减函数。
- 在搜索请求中,使用field data fields从字段数据来获取字段内容。
- 缓存父子文档关系的ID
todo 具体使用
另外可以在索引文档时自动加载字段数据,只需要在文档映射时需要排序或者聚集的字段增加fielddata.loading 等于eager的配置。设置为eager后,Elasticsearch不会等第一次查询时才加载,而是在可加载时第一时间加载。
PUT /mall_goods_test
{"mappings": {"properties": {"title": {"type": "text","fields": {"verbatim":{"type":"keyword"}}},"attribute":{"type":"text","fields": {"verbatim":{"type":"keyword"}}},"desc":{"type":"text"},"price":{"type": "double","doc_values": true}}}
}
在title字段上增加字段数据缓存(运行一个term聚集,获取前10个标签)的verbatim标签。
写入数据和查询:
POST /mall_goods_test/_doc/1
{"title":"Apple iPhone 15 256GB Pro Max - 全新旗舰智能手机","attribute":"256GB Pro","desc":"iPhone 15 Pro Max采用了全新的设计语言,机身采用航空级铝合金打造,正面是一块6.7英寸的超视网膜XDR显示屏,分辨率高达4K,显示效果惊艳。同时,这款手机还支持120Hz的高刷新率,让您在浏览网页、玩游戏时更加流畅。","price": 4999
}POST /mall_goods_test/_doc/2
{"title":"Apple iPhone 15 512GB Pro Max - 全新旗舰智能手机","attribute":"512GB Pro Max","desc":"iPhone 15 Pro Max采用了全新的设计语言,机身采用航空级铝合金打造,正面是一块6.7英寸的超视网膜XDR显示屏,分辨率高达4K,显示效果惊艳。同时,这款手机还支持120Hz的高刷新率,让您在浏览网页、玩游戏时更加流畅。","price": 6999
}POST /mall_goods_test/_doc/3
{"title":"Apple iPhone 15 1TB Pro Max - 全新旗舰智能手机","attribute":"1TB Pro Max","desc":"iPhone 15 Pro Max采用了全新的设计语言,机身采用航空级铝合金打造,正面是一块6.7英寸的超视网膜XDR显示屏,分辨率高达4K,显示效果惊艳。同时,这款手机还支持120Hz的高刷新率,让您在浏览网页、玩游戏时更加流畅。","price": 12999
}
POST /mall_goods_test/_doc/4
{"title":"Xiaomi 15 - 全新旗舰智能手机","attribute":"1TB Pro Max","desc":"Xiaomi 15 Pro Max采用了全新的设计语言,机身采用航空级铝合金打造,正面是一块6.7英寸的超视网膜XDR显示屏,分辨率高达4K,显示效果惊艳。同时,这款手机还支持120Hz的高刷新率,让您在浏览网页、玩游戏时更加流畅。","price": 12999
}
POST /mall_goods_test/_doc/5
{"title":"Xiaomi 15 - 全新旗舰智能手机","attribute":"1TB Pro Max 天空蓝","desc":"Xiaomi 15 Pro Max采用了全新的设计语言,机身采用航空级铝合金打造,正面是一块6.7英寸的超视网膜XDR显示屏,分辨率高达4K,显示效果惊艳。同时,这款手机还支持120Hz的高刷新率,让您在浏览网页、玩游戏时更加流畅。","price": 12999
}# 查询
POST /mall_goods_test/_search
{"query": {"match": {"title": "15"}}, "aggs":{"title_tags":{"terms": {"field": "title.verbatim"}}}
}
POST /mall_goods_test/_search
{"query": {"match": {"title": "15"}}, "aggs":{"attribute_tags":{"terms": {"field": "attribute.verbatim"}}}
}


根据未分析的keyword类型数据作为一个分词进行统计。
字段数据的管理:
- 限制字段数据使用的内存量;
Elasticsearch默认不限制内存量量,而且指定时间过后数据也不会从缓存中自动过期失效。有设置内存使用量和字段数据在缓存里失效的过期时间来限制。Elasticsearch提供如下配置:
indices.fielddata.cache.size:400mb,内存到达上限后,使用最近最少使用策略(LRU)淘汰数据。配置值还可以指定30%,表示JVM堆大小的30%。indices.fielddata.cache.expire:25m
通常indices.fielddata.cache.size配置更加有意义,避免内存无限制增长。
- 使用字段数据的断路器;
- 使用文档值(doc value)来避免内存的使用。
字段数据查询断路器
如果一个请求加载的字段数据超过内存大小,发生内存溢出,为了避免这种情况,Elasticsearch提供了断路器概念。
对于字段数据而言,每当一个请求需要加载字段数据的时候(如根据某个字段排序),断路器评估数据加载导致的内存使用量,并检查加载是否会导致其超越最大限制。如果超限了,就会抛出一个异常,并阻止该操作的进行。
默认情况下,断路器的配置将字段数据的大小限制为JVM虚拟机堆大小的60%。你可以通过发送一个如下的请求,来进行配置,也可以使用40%配置值。
PUT _cluster/settings
{"transient": {"indices.breaker.fielddata.limit":"400mb"}
}
查询配置:
GET _cluster/settings
注意在版本1.4中,还有一个请求断路器,它对请求所产生的其他内存数据结构做出了限制,默认值为40%,这将确保它们不会引起0ut0fMemoryErroro。还有一个父断路器,它将确保字段数据和请求的断路器一共不会超过堆大小的70%·两个限制都可以通过集群更新设置(cluster update setting)API接口来更新分别是indices.breaker.request.limit和indices.breaker.total.limit
使用文档值(doc values)-避免内存的使用
文档值(doc values)在文件被索引的时候,获取了将要加载到内存中的数据,并将它们和普通索引数据一起存储到磁盘上。这就意味着,使用字段数据通常会使得内存不够,而文档值却可以从磁盘读取。
这样做有几个优点:
- 性能平滑地下降:默认的字段数据需要一次性加载到JVM的堆之中,和它有所不同的是,文档值是从磁盘读取,和其他索引一样。如果操作系统无法将所有的东西都塞进内存,就需要更多的磁盘询道,但是就不会再有昂贵的加载和淘汰操作、产生0ut0fMemoryError的风险以及断路器的异常(因为断路器会预防字段数据缓存使用过多的内存)。
- 更好的内存管理:当使用的时候,系统核心会将文档值缓存到内存中,从而避免了和堆使用相关的垃圾回收成本。
- 更快的加载:通过文档值,在索引的阶段会计算非倒排结构,所以即使是首次运行查询,Elasticsearch没有必要进行动态的正向化。由于正向化过程已经执行过,初始的请求能够更快地运行。
文档值也有一些缺点:
- 更大的索引规模:将所有的文档值存储在磁盘上,会使得索引变大。
- 稍微变慢的索引过程:在索引阶段需要计算文档值,将使得索引的过程变得更慢。
- 使用字段数据的请求,会稍微变慢:磁盘比内存读取速度慢,所以对于那些经常使用预加载字段数据缓存的请求,如果使用从磁盘读取的文档值,那么请求就会稍稍变慢。这些请求包括排序、切面(facet)和聚集。
Doc Values默认对所有字段启用,除了analyzed strings。也就是说所有的数字、地理坐标、日期、IP 和不分析( not_analyzed)字符类型都会默认开启。
PUT /mall_goods_test
{"mappings": {"properties": {"title": {"type": "text","fields": {"raw": {"type": "keyword"}},"fielddata": true},"attribute":{"type":"text"},"desc":{"type":"text"},"price":{"type": "double","doc_values": true}}}
}
price字段添加了doc_values=true参数,意味着使用文档值。
生态其他组件
Beats
Beats是一个面向轻量型采集器的平台,这些采集器可以从边缘机器向Logstash、ElasticSearch发送数据,它是由Go语言进行开发的,运行效率方面比较快。
不同Beats的套件是针对不同的数据源:
- Filebeat:实时洞察日志数据
- Packetbeat:分析网络数据包数据
- Winlogbeat:分析Windows事件日志
- Metricbeat:运送和分析指标
- Heartbeat:ping您的基础架构
- Auditbeat:将审计数据发送到Elasticsearch
- Functionbeat:使用无服务器基础架构运送云数据
- Journalbeat:分析期刊日志
Logstash
Logstash是动态数据收集管道,拥有可扩展的插件生态系统,支持从不同来源采集数据,转换数据,并将数据发送到不同的存储库中。
它具有如下特性:
- 实时解析和转换数据;
- 可扩展,具有200多个插件;
- 可靠性、安全性。Logstash会通过持久化队列来保证至少将运行中的事件送达一次,同时将数据进行传输加密;
- 监控;
Kibana
Kibana实现数据可视化,Kibana能够以图表的形式呈现数据,并且具有可扩展的用户界面,可以全方位的配置和管理ElasticSearch。
Kibana最早的时候是基于Logstash创建的工具,后被Elastic公司在2013年收购。
1)Kibana可以提供各种可视化的图表;
2)可以通过机器学习的技术,对异常情况进行检测,用于提前发现可疑问题;
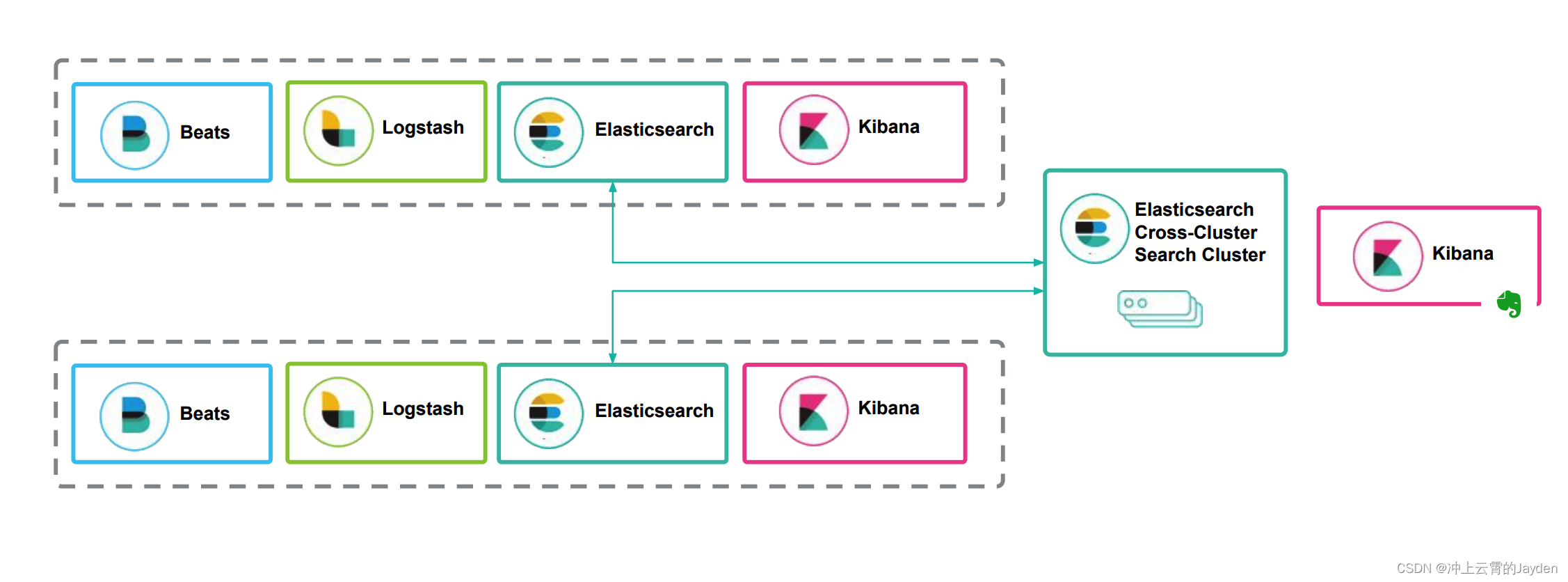
生态组合
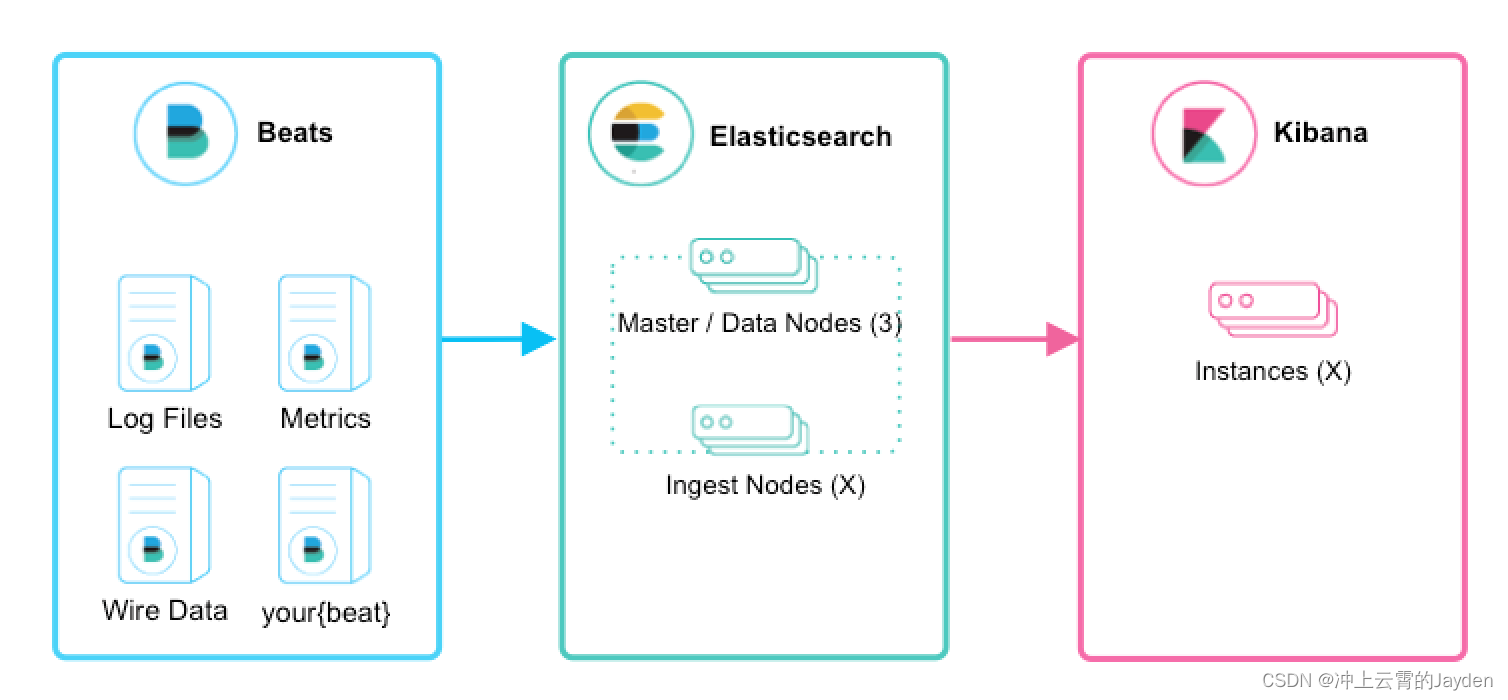
beats+elasticsearch+kibana
Beats采集数据后,存储在ES中,有Kibana可视化的展示。
beats+logstath+elasticsearch+kibana
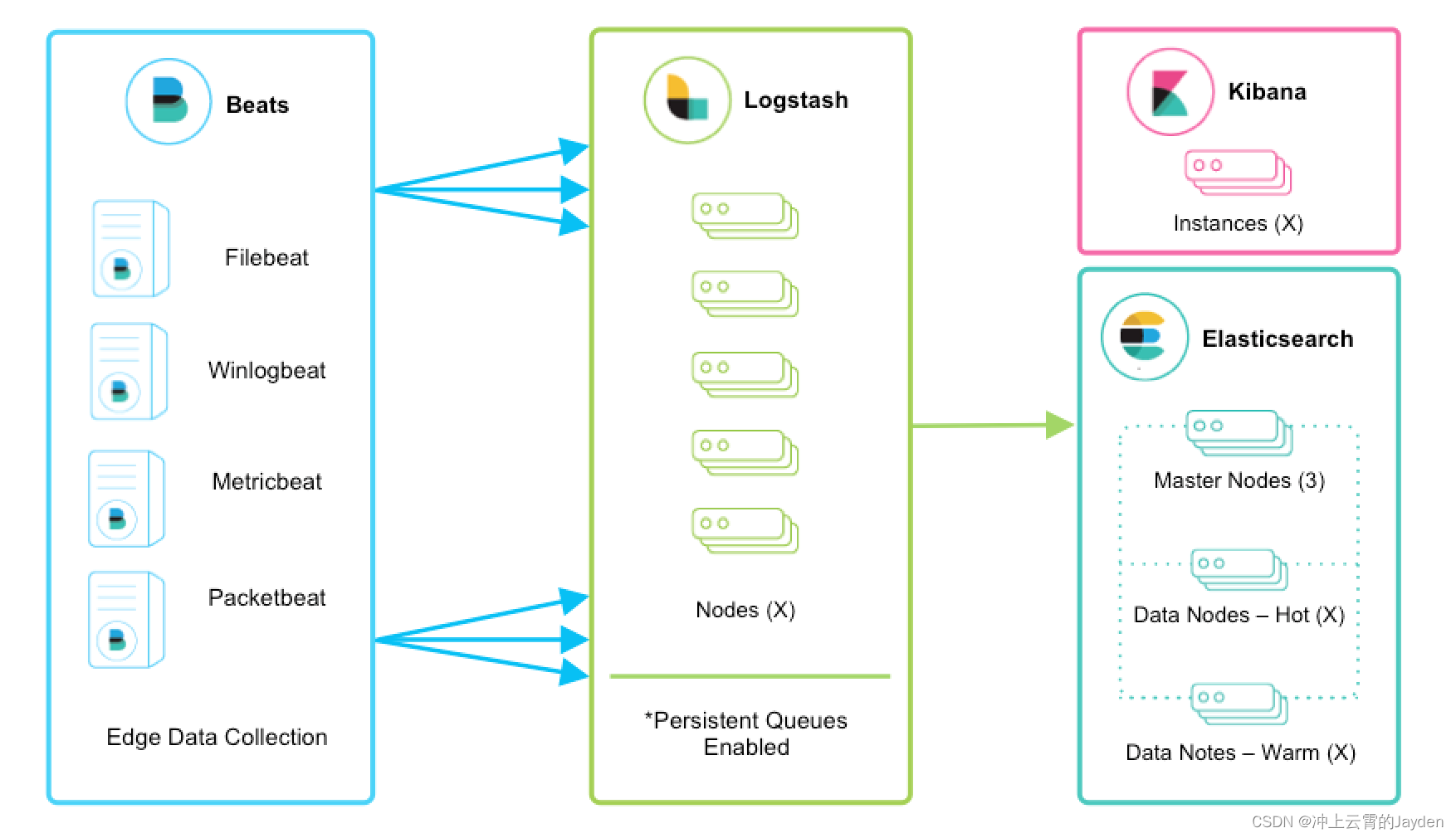
该框架是在上面的框架的基础上引入了logstash,引入logstash带来的好处如下:
(1)Logstash具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻背压。
(2)从其他数据源(例如数据库,S3或消息传递队列)中提取。
(3)将数据发送到多个目的地,例如S3,HDFS或写入文件。
(4)使用条件数据流逻辑组成更复杂的处理管道。
beats结合logstash带来的优势:
(1)水平可扩展性,高可用性和可变负载处理:beats和logstash可以实现节点之间的负载均衡,多个logstash可以实现logstash的高可用
(2)消息持久性与至少一次交付保证:使用beats或Winlogbeat进行日志收集时,可以保证至少一次交付。从Filebeat或Winlogbeat到Logstash以及从Logstash到Elasticsearch的两种通信协议都是同步的,并且支持确认。Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹性,确保磁盘冗余非常重要。
(3)具有身份验证和有线加密的端到端安全传输:从Beats到Logstash以及从 Logstash到Elasticsearch的传输都可以使用加密方式传递 。与Elasticsearch进行通讯时,有很多安全选项,包括基本身份验证,TLS,PKI,LDAP,AD和其他自定义领域
增加更多的数据源 比如:TCP,UDP和HTTP协议是将数据输入Logstash的常用方法
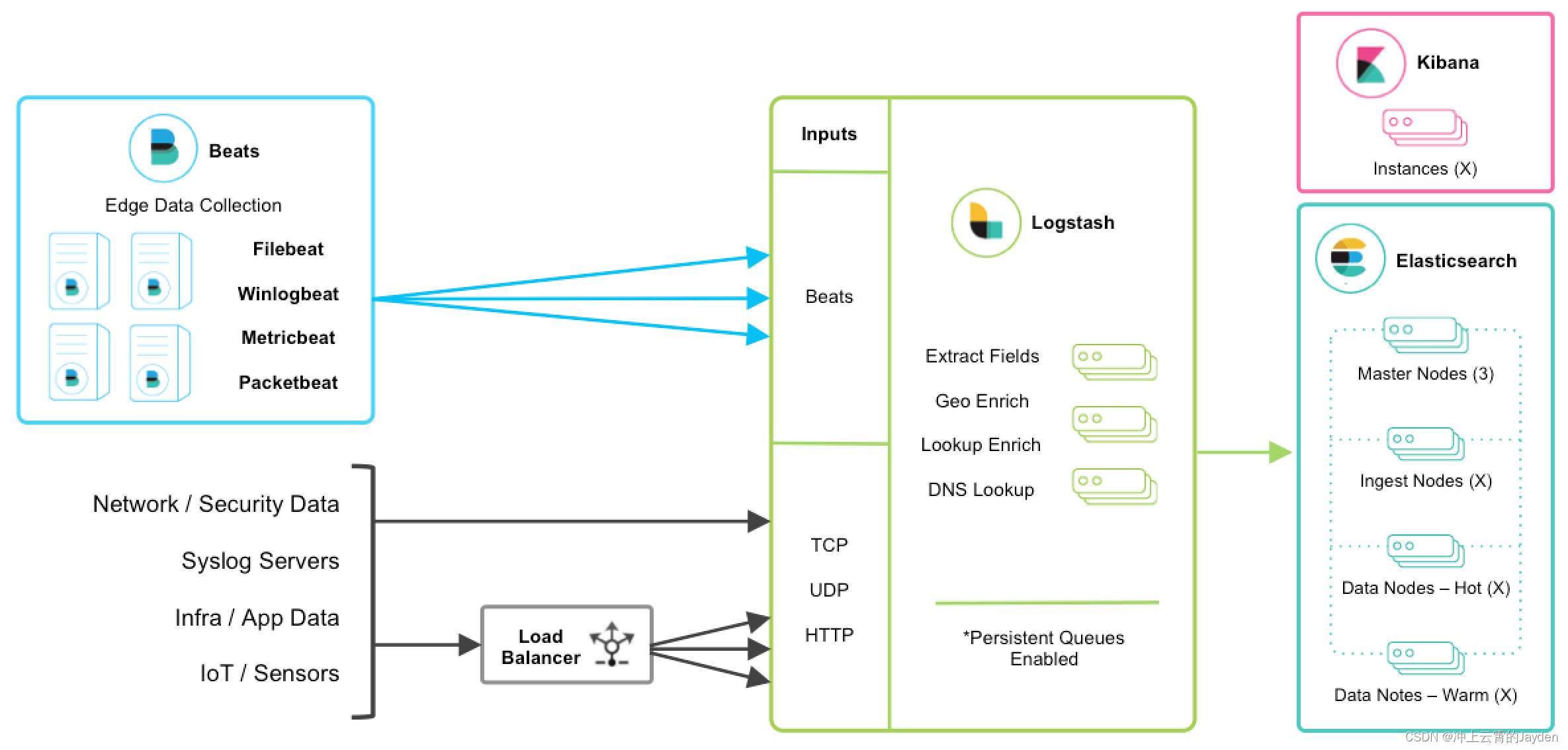
beats+MQ+logstash+elasticsearch+kibana
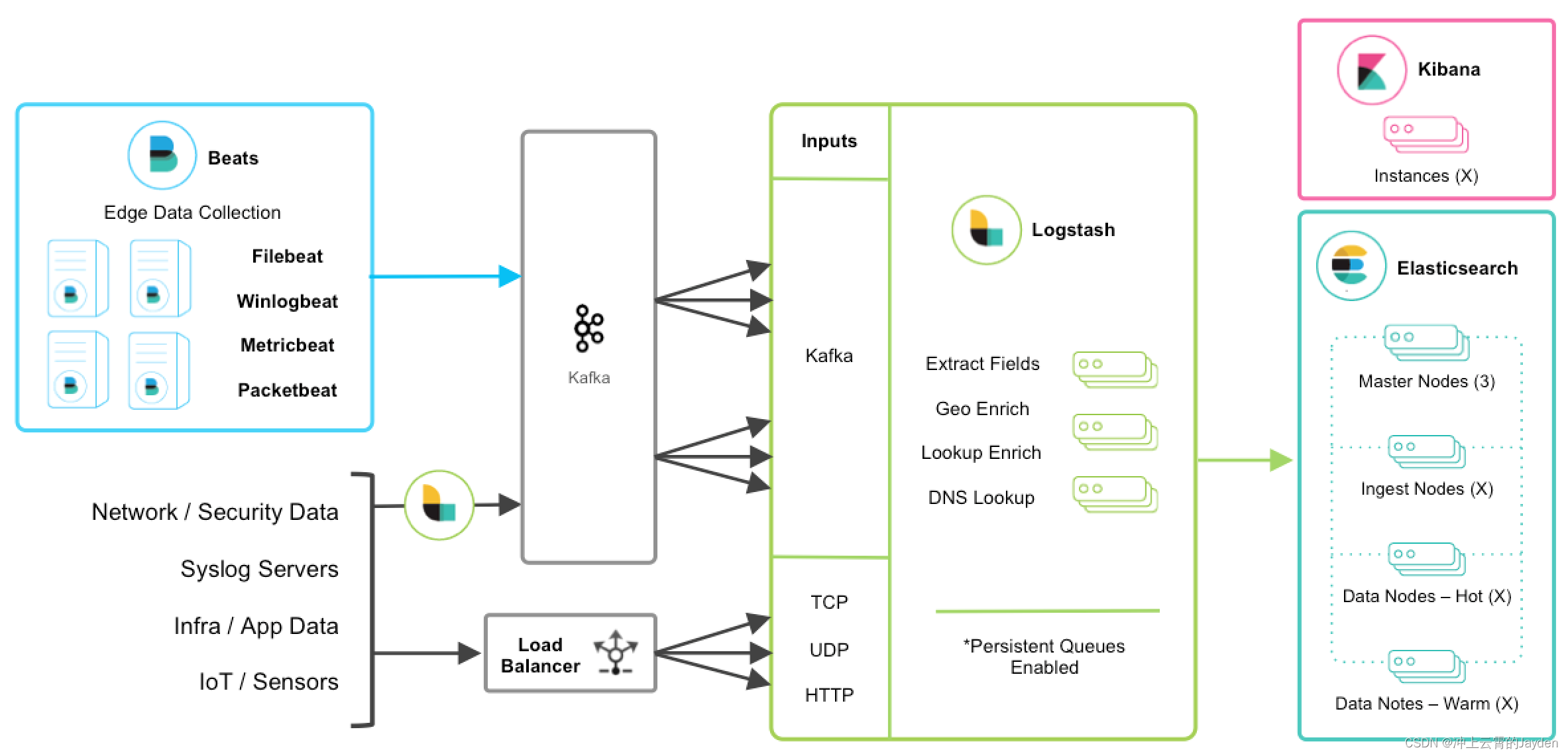
在如上的基础上我们可以在beats和logstash中间添加一些组件redis、kafka、RabbitMQ等,添加中间件将会有如下好处:
(1)降低对日志所在机器的影响,这些机器上一般都部署着反向代理或应用服务,本身负载就很重了,所以尽可能的在这些机器上少做事;
(2)如果有很多台机器需要做日志收集,那么让每台机器都向Elasticsearch持续写入数据,必然会对Elasticsearch造成压力,因此需要对数据进行缓冲,同时,这样的缓冲也可以一定程度的保护数据不丢失;
(3)将日志数据的格式化与处理放到Indexer中统一做,可以在一处修改代码、部署,避免需要到多台机器上去修改配置;
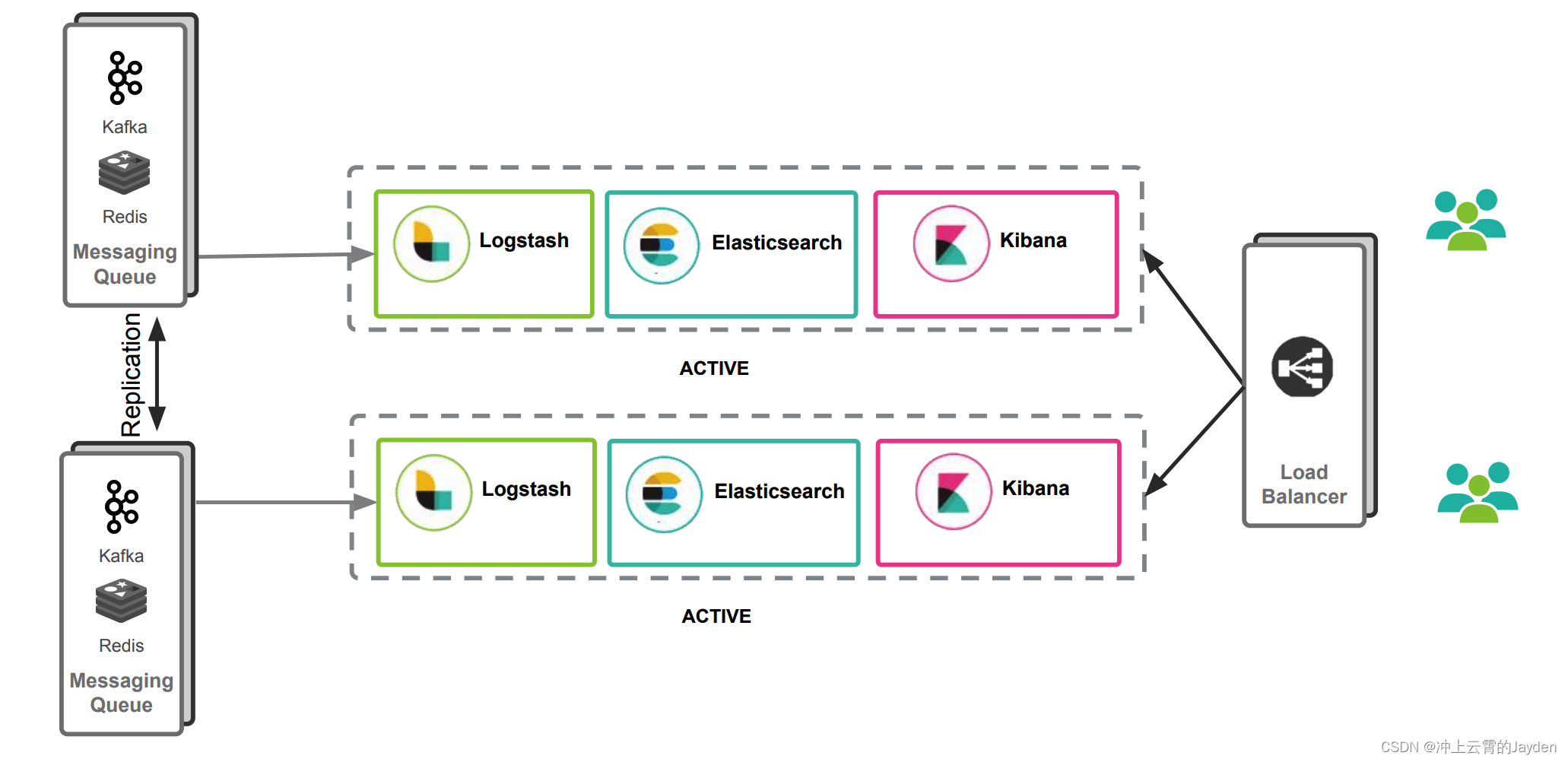
多数据中心方案
通过冗余实现数据高可用
两个数据采集中心(比如采集两个工厂的数据),采集数据后的汇聚
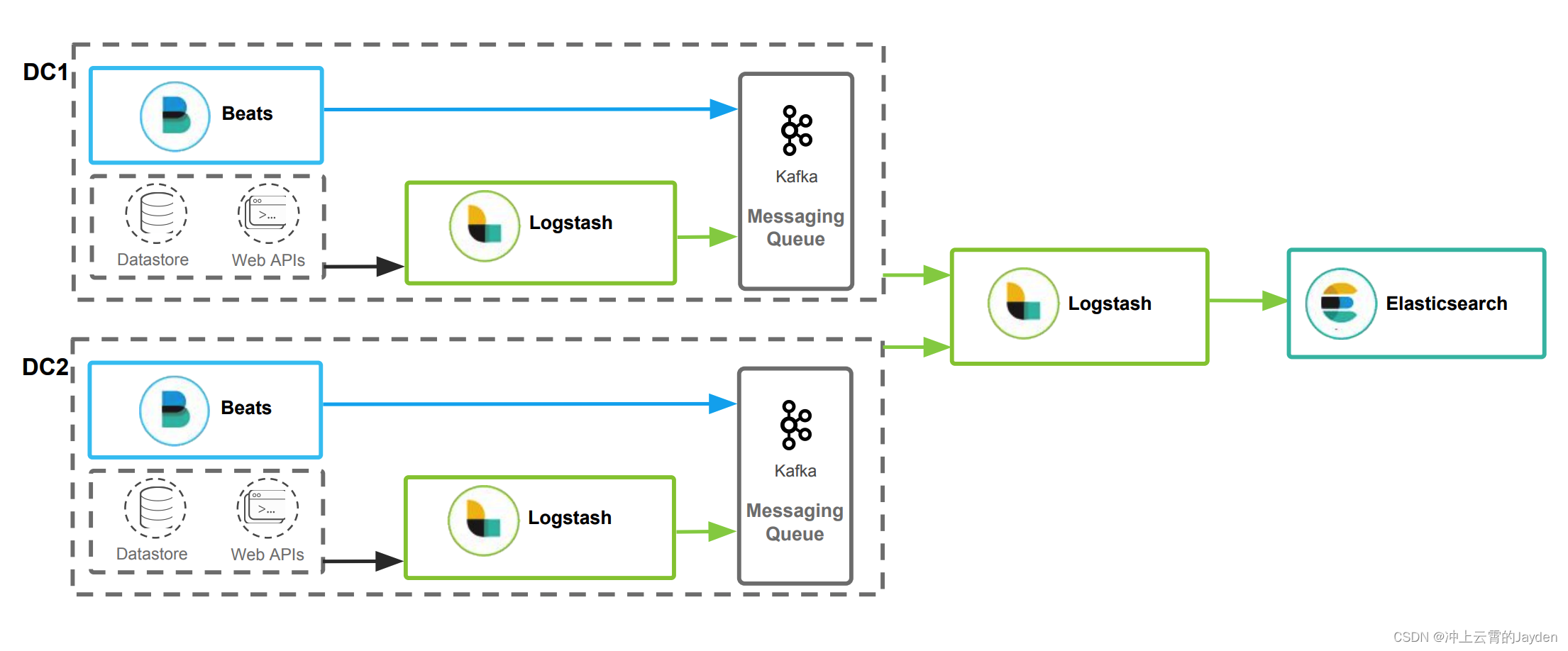
数据分散,跨集群的搜索