欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
文章目录
- 掌上先机后端面试(Java基础能力夯实)
- 题目分析
- 1、对于 SQL 优化的理解
- 2、left join 和 exists 的区别和使用场景
- 3、left join 和 inner join 的区别
- 4、查找在 A 表中存在,在 B 表中不存在的记录用什么比较好?
- 5、说说 ArrayList 和 LinkedList 区别
- 6、ArrayList 扩容的过程
- 7、它们两个适用的场景
- 8、ArrayList 和 LinkedLisst 怎么变成线程安全
- 9、Collections 加锁的原理
- 10、了解哪些设计模式?
- 11、写一个懒汉式单例
- 12、synchronized 能加在哪些地方?
- 13、volatile 不是直接保证可见性了,为啥还要 DCL?
- 14、聚簇索引和非聚簇索引的区别
- 15、回表什么时候会发生?
掌上先机后端面试(Java基础能力夯实)
题目分析
1、对于 SQL 优化的理解
SQL 优化的目的就是让查询速度变快,也就是让 SQL 查询尽量走索引,来优化查询速度
那么常用的一般就是最左前缀原则和覆盖索引
- 最左前缀原则:表示在联合索引的情况下, 让 where 语句中的条件遵循最左前缀原则,来让 SQL 语句可以走索引
- 覆盖索引:让 select 中的字段都为索引字段,那么就不需要二次回表查询,大幅提高 SQL 查询速度
还有其他的一些 SQL 优化,比如 order by 的优化,也就是让 where 语句的条件 + order by 语句的条件结合起来符合最左前缀原则,那么也是会走索引的
还有 in 和 exists 的优化,这两个关键字都是对两个表进行筛选数据的,原则就是小表驱动大表,先过滤掉大部分的数据,只留下一小部分数据再去另一个表中做筛选,速度肯定是比拿着很多的数据去另一个表中做筛选要快很多的!
上边我主要说了从哪些方面可以对 SQL 进行优化,具体的细节这里先不写了(比较多),如果需要的话可以找我领取《面试突击》的 pdf 文档,里边都有解析。
2、left join 和 exists 的区别和使用场景
先说一下这两个的区别:
- left join 是连表查询,会返回左边表的所有数据,如果右表有匹配的记录则显示右表中对应的记录,如果右表中没有匹配的记录,则右表对应的列全部为 Null
- exists 是一种子查询,返回 true 或 false,用于判断在另一个表中是否有对应的记录,但是并不需要这些记录的具体内容
适用场景:
- left join 适用于需要保留左表中的全部记录,并且只关心右表中匹配的行记录的情况,但是如果使用 left join 处理大量数据时,可能会有性能问题
- exists 适用于判断某个条件是否满足,也就是某些记录在另一个表中是否存在,并不关心这些记录的具体内容是什么
这里给出 exists 的使用示例,以及使用建议:
当 A 表的数据集小于 B 表的数据集时,使用 exists
将主查询 A 的数据放到子查询 B 中做条件验证,根据验证结果(true 或 false)来决定主查询的数据是否保留
select * from A where exists (select 1 from B where B.id = A.id)
3、left join 和 inner join 的区别
两者的区别:
- join 和 inner join 是相同的,inner join 可以简写为 join,表示两个表的交集
- left join 是左连接,以左表为主,查询左表所有数据,显示右表与左表相关联部分的数据
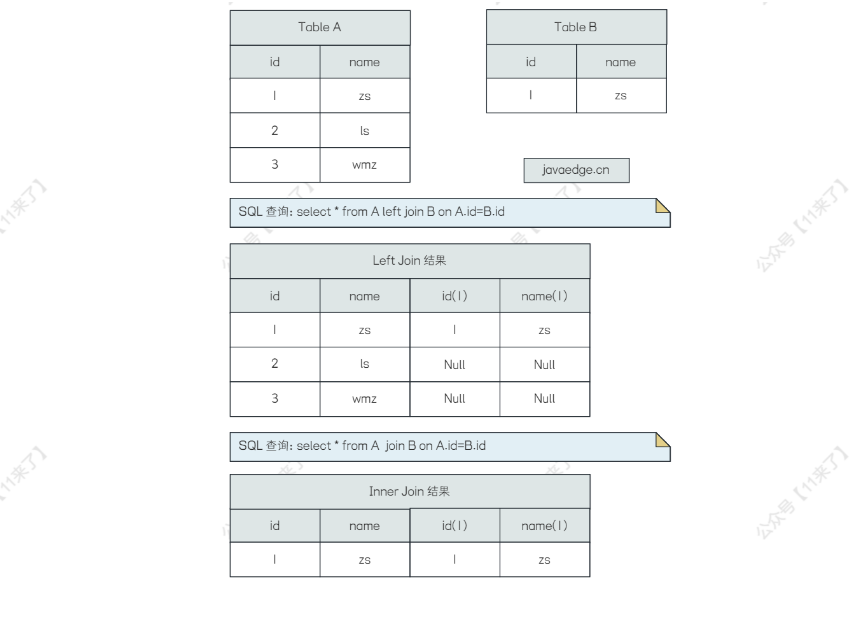
图示:
有如下两个表:Table A 和 Table B,使用 left join 和 inner join 区别如图所示:
4、查找在 A 表中存在,在 B 表中不存在的记录用什么比较好?
通过使用 left join 和 not exists 就可以实现
- LEFT JOIN
使用 left join 的话,对 A 和 B 两个表联表查,如果 B 表中的字段为 null 说明在 B 表中不存在
select A.* from A left join B on A.id=B.id where B.id is null
- NOT EXISTS
使用 not exists 的话,子查询不为空的话,表示 A 表的数据在 B 表中存在,再通过 not exists 取反即可
select A.* from A where not exists (select 1 from B where A.id = B.id)
性能表现:
- 使用 left join 时,如果 A 表数据量比较大,B 表数据量比较小时,性能表现较好
- 使用 not exists 时,如果 A 表数据量比较小,B 表数据量比较大时,性能表现较好
5、说说 ArrayList 和 LinkedList 区别
ArrayList 底层是基于 数组 实现的,而 LinkedList 底层是基于 双向链表 实现的 ,这里主要说一下数组和链表的一些区别即可,区别主要表现在访问、插入、删除这三个操作上:
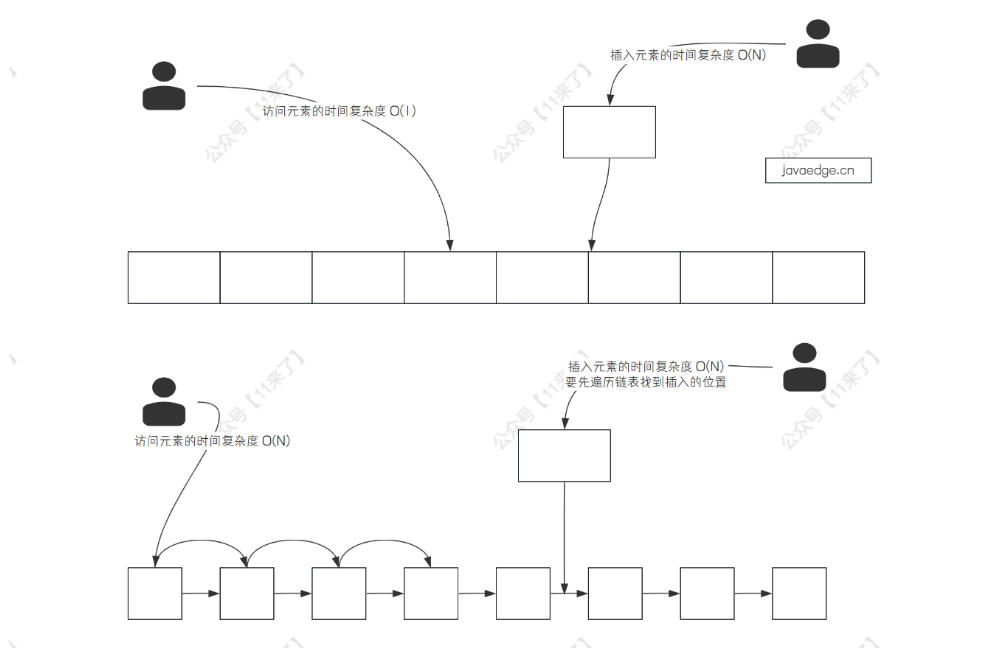
- 对于插入元素和删除元素的性能来说
- LinkedList 要好一些,如果在头尾插入元素时间复杂度为 O(1),如果在指定位置插入元素,那么时间复杂度是 O(n)
- 而向 ArrayList 中间插入元素时,需要将后边的元素都向后移动一位,时间复杂度为 O(n)
- 是否支持快速访问
- ArrayList 可以根据下标快速访问元素,时间复杂度 O(1)
- LinkedList 不可以快速访问元素,需要遍历链表,时间复杂度 O(n)
综上,可以发现 LinkedList 和 ArrayList 相比,没有太大优势,一般在项目中不会使用 LinkedList
6、ArrayList 扩容的过程
ArrayList 底层是基于数组实现的,是动态数组,那么它的大小也是动态变化的,这里我说一下扩容的流程:
当添加元素时,发现容量不足,则对数组进行扩容,大小扩容为原来的 1.5 倍,int newCapacity = oldCapacity + (oldCapacity >> 1),通过位运算进行扩容后容量的计算(位运算比较快)
ArrayList 会创建一个新的数组,表示扩容后的数组,将旧数据全部复制到新数组中去,再让 ArrayList 中的数组引用指向新的数组即可
7、它们两个适用的场景
一般不会使用 LinkedList,而是会选择 ArrayList,因为 LinkedList 如果向中间插入元素的话,复杂度也是 O(N) 的(需要先遍历找到要插入的位置),所以相比于 ArrayList 来说并没有太大的优势
8、ArrayList 和 LinkedLisst 怎么变成线程安全
这里主要说一下 ArrayList,LinkedList 的原理也是类似的
要保证 ArrayList 的线程安全,有两种方法:
- 使用 Collections.synchronizedList
- 这种方法比较简单粗暴,生成的集合中所有的操作都是通过 synchronized 来保证线程安全的
- 使用 CopyOnWriteArrayList
- 这种方法会在每次修改数据时,创建一个新的数据副本,在新数据上进行修改
- 对于读操作来说,如果数据修改完毕,数组指针指向了新数组,那就可以读到最新数据;如果数据没有修改完毕,数组指针还是指向就数组,那么读取的还是旧数据
适用场景和性能表现:
- 对于 Collections.synchronizedList 来说,由于读操作是直接读,不需要额外的操作,而写操作需要复制一份新的副本,读操作远远快于写操作,因此它适用于读多写少的场景
- 对于 CopyOnWriteArrayList 来说,由于所有操作都是通过 synchronized 来保证同步的,读和写的加锁后性能都差不多,因此它适用于读和写比较平均的场景
9、Collections 加锁的原理
Collections.synchronizedList 的原理就是给所有的操作都包装上了一层 synchronized 来保证操作是同步的
注意事项:
通过 Collections.synchronizedList 保证线程安全时,如果使用迭代器 Iterator 来遍历列表的时候,需要手动添加 synchronized 来保证线程安全,在 for each 的时候,也需要手动添加 synchronized 来保证线程安全,因为 for each 的底层也是通过 Iterator 来实现的
// Iterator
synchronized (list) {Iterator i = list.iterator(); // Must be in synchronized blockwhile (i.hasNext())// ...
}
// for each
synchronized (list) {for (Integer i : list) {try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(i + ",");}
}
10、了解哪些设计模式?
可以说一说你自己了解到的设计模式,比如单例模式、工厂模式、适配器模式、代理模式,这些都是比较常见的
像在 Spring 中的话,单例模式、工厂模式、代理模式都有使用
在 Spring MVC 中用到了适配器模式
还有 Netty 中的责任链模式
MQ 中的
11、写一个懒汉式单例
- 线程不安全的懒汉式单例
懒汉式单例也就是在真正需要使用这个对象的时候再去加载这个单例对象,通过 static 来保证这个对象是唯一的
public class Singleton {private static Singleton instance;private Singleton() {}public static Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;}
}
- 线程安全的懒汉式单例
当然上边写出的懒汉式单例还存在 线程安全 的问题,当多个线程同时来创建的时候,可能会创建多个单例对象,因此需要通过 synchronized 和 volatile 来进一步优化,synchronized 保证线程间的同步,将单例对象声明为 volatile 禁止指令重排
public class Singleton {private static volatile Singleton instance;private Singleton() {}public static Singleton getInstance() {if (instance == null) {synchronized (Singleton.class) {if (instance == null) {instance = new Singleton();}}}return instance;}
}
volatile 禁止指令重排
这里的指令重排是指底层硬件为了提升执行效率,对指令进行重排序,比如在上边的代码中 instance = new Singleeton() ,这一行代码对应的字节码有 3 个核心步骤:先创建一个 Singleton 对象、调用 Singleton 的初始化方法、将 Singleton 对象的引用赋值给 instance 变量
那么一般初始化方法的执行速度是比较慢的,可能会被重排序,排到后边去,指令重排序前后对比如下:
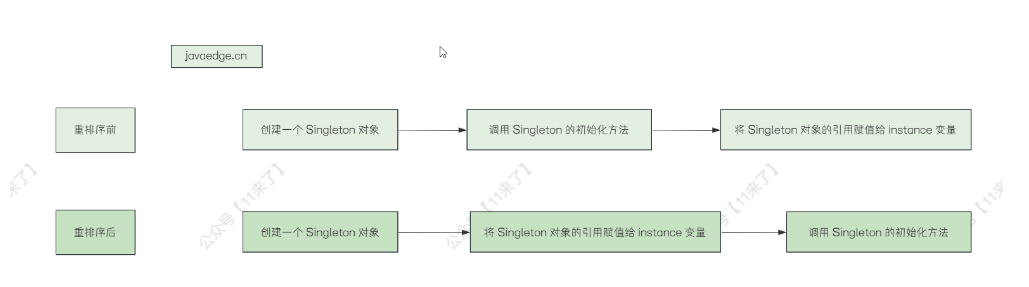
如果发生了指令重排,单线程环境下下是不会有问题的
但是在多线程环境下,第一个线程执行将 Singleton 的引用赋值给 instance 了,但是此时还没有执行完 Singleton 的初始化方法, 如果第二个线程进来,拿到这个 instance 变量,使用了这个未初始化完毕的 Singleton 实例对象,从而导致一些问题出现
12、synchronized 能加在哪些地方?
synchronized 加在不同的地方上,对应锁住的对象也是不同的,那么相对的锁粒度也是不同的
在具体使用中,要注意锁粒度越大,并发度就越低
- synchronized 加在方法上,锁的是 this 对象
比如创建一个在 Phone 对象的方法加上 synchronized 锁,如果创建 Phone phone = new Phone() 对象,那么锁定的就是这一个 phone 实例对象
class Phone {public synchronized void sendSMS() throws Exception {System.out.println("--------sendSMS");}public synchronized void sendEmail() throws Exception {System.out.println("--------sendEmail");}public void getHello() {System.out.println("---------getHello");}
}
- synchronized 加在静态方法上,锁的是Class对象,也就是字节码对象
加在静态方法上,锁定 Class 对象,这个锁的粒度就相比于锁定实例对象要大了
因为实例对象可以创建多个,而 Class 对象在 JVM 运行期间,只有一份
class Phone {public static synchronized void sendSMS() throws Exception {System.out.println("--------sendSMS");}
}
- synchronized 保证同步代码块同步执行,可以自己执行加锁对象
// 使用对象作为锁
public void someMethod() {synchronized (lockObject) {// 需要同步的代码}
}
// 使用类的 Class 对象作为锁
public void someMethod() {synchronized (MyClass.class) {// 需要同步的静态代码}
}
13、volatile 不是直接保证可见性了,为啥还要 DCL?
我们还是先列出来 DCL(双端检锁)的代码:
if (instance == null) {synchronized (Singleton.class) {if (instance == null) {instance = new Singleton();}}
}
给 instance 变量加上 volatile 是保证了 instance 变量的原子性,如果不使用 DCL 的话,如下,假设多个线程同时进入到 synchronized 代码块中,那么第一个线程拿到锁,进来初始化 instance 变量,之后释放锁,第二个线程再拿到锁,进来之后他并不知道 instance 变量已经被初始化了,于是又初始化了一下,违背了单例模式
if (instance == null) {synchronized (Singleton.class) {instance = new Singleton();}
}
14、聚簇索引和非聚簇索引的区别
这个是 MySQL 中基础的内容了,不多赘述了
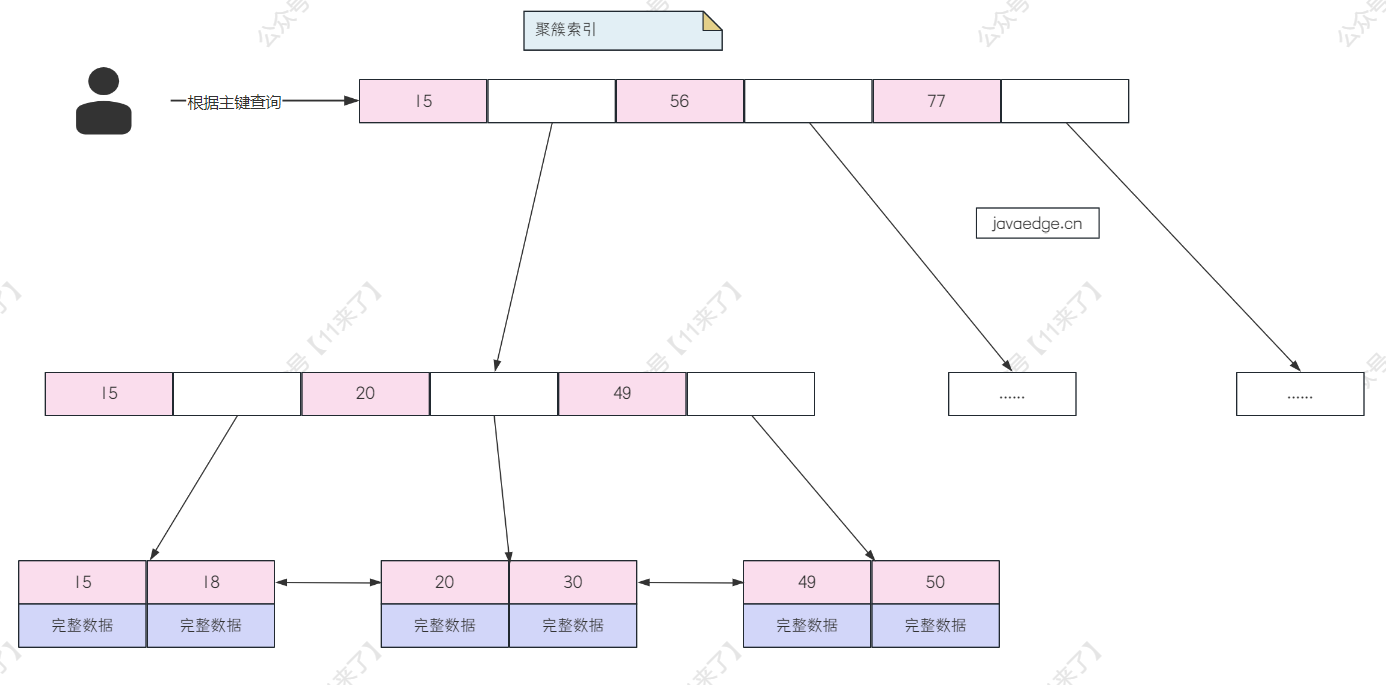
- 聚簇索引:在聚簇索引中,数据行的物理存储顺序与索引中的顺序相同。换句话说,聚簇索引决定了表中数据的物理存储顺序。每个表只能有一个聚簇索引,通常是由主键自动创建。在InnoDB存储引擎中,
聚簇索引的叶子节点直接包含行数据。 - 非聚簇索引:非聚簇索引(也称为二级索引或辅助索引)与聚簇索引不同,它在索引结构中存储的是
索引键值和指向数据行的指针(在InnoDB中通常是主键值)。非聚簇索引的叶子节点不包含实际的数据行,而是包含指向数据行的引用。一个表可以有多个非聚簇索引。
15、回表什么时候会发生?
当使用 SQL 查询时,如果走了索引,但是要查询的列并不全在索引上,因此还需要回表查询完整的数据
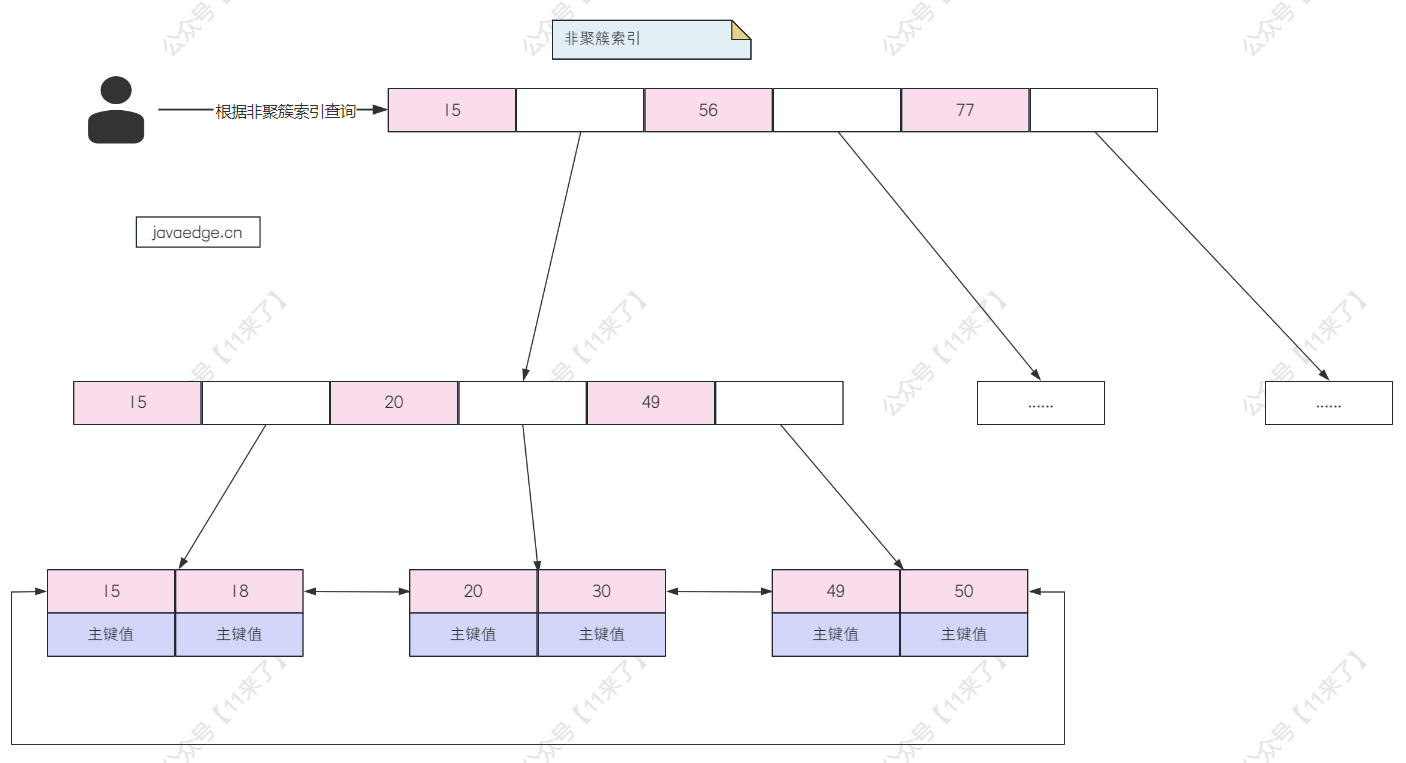
在非聚簇索引中,叶子节点保存的是主键的值,如果查询走的非聚簇索引,但是要查询的数据不只有主键的值,还有其他值,此时在非聚簇索引中拿到主键值,还需要再去聚簇索引回表查询,根据主键值查询到整行数据
- 聚簇索引和非聚簇索引如下,这里画图比较简略了
- 根据非聚簇索引查询的话,是通过普通的索引字段进行判断的(比如在 name 上建立索引,那就是通过 name 字段去非聚簇索引上进行查询)
- 根据聚簇索引查询的话,是通过主键进行判断的,直接从 SQL 语句中拿到主键值或者从非聚簇索引中拿到主键值,去聚簇索引中进行查询

![[嵌入式系统-6]:龙芯1B 开发学习套件 -3-软件层次架构](https://img-blog.csdnimg.cn/direct/813a322b84a74c00ab0613641e71008d.png)