用途:个人学习笔记,有所借鉴,欢迎指正
前言:
主要包含对requests库和Web爬虫解析库的使用,python爬虫自动化,批量信息收集
Python开发工具:PyCharm 2022.1 激活破解码_安装教程 (2022年8月25日更新~)-小白学堂
一、EDUSRC平台爬取接收漏洞的教育机构名称
1、爬取目标:EDUSRC平台此网页第1-209页的所有教育机构名称,保存到txt文件中

2、Python代码实现:
import requests,time
from bs4 import BeautifulSoup#<tr>
# <td class="am-text-center">1</td>
# <td class="am-text-center">
# <a href="/list/firm/3761">上海交通大学</a>
# </td>
# <td class="am-text-center">3994</td>
# <td class="am-text-center">10523</td>
#</tr>def get_eduName():for i in range(1,209):url = 'https://src.sjtu.edu.cn/rank/firm/0/?page=%s'%str(i)try:s=requests.get(url).textprint('------->正在获取第%s页面数据'%str(i))soup = BeautifulSoup(s, 'lxml')edu1=soup.find_all('tr')for edu in edu1:edu_name=edu.a.stringprint(edu_name)with open('eduname.txt','a+',encoding='utf-8') as f:f.write(edu_name+'\n')f.close()except Exception as e:time.sleep(1)passif __name__ == '__main__':get_eduName()二、利用FOFA搜索引擎批量爬取与目标相关的URL地址
1、FOFA搜索语法:收集目标名称相关所有URL地址

2、Python代码实现
import requests
from bs4 import BeautifulSoupheader={#登录fofa,浏览器查看数据包中的登录凭证fofa_token'cookie':'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjgyNzMsIm1pZCI6MTAwMDIxOTg4LCJ1c2VybmFtZSI6InhpYW9kaXNlYyIsImV4cCI6MTY3MTI4MjUzOH0.0ukMGFIrIvzDOzpUl9JglOoMpzbIPCczGRDeqKdmFYHfStd2jdwc6LGby3Ke0UR2suvErzhOTPYL2ACe4Goi8Q; '
}url='https://fofa.info/result?qbase64=dGl0bGU9IuS4iua1t%2BS6pOmAmuWkp%2BWtpiIgJiYgY291bnRyeT0iQ04i'
s=requests.get(url,headers=header).text
soup = BeautifulSoup(s, 'lxml')
#获取页数
edu1=soup.find_all('p',attrs={'class': 'hsxa-nav-font-size'})
for edu in edu1:edu_name = edu.span.get_text()i=int(edu_name)/10yeshu=int(i)+1print(yeshu)for ye in range(1,yeshu+1):url = 'https://fofa.info/result?qbase64=dGl0bGU9IuS4iua1t%2BS6pOmAmuWkp%2BWtpiIgJiYgY291bnRyeT0iQ04i&page='+str(ye)+'&page_size=10'print(url)s = requests.get(url, headers=header).textedu1=soup.find_all('span',attrs={'class': 'hsxa-host'})for edu in edu1:edu_name = edu.a.get_text().strip()print(edu_name)
3、使用Goby新建扫描任务,导入收集到的URL目标,批量扫描漏洞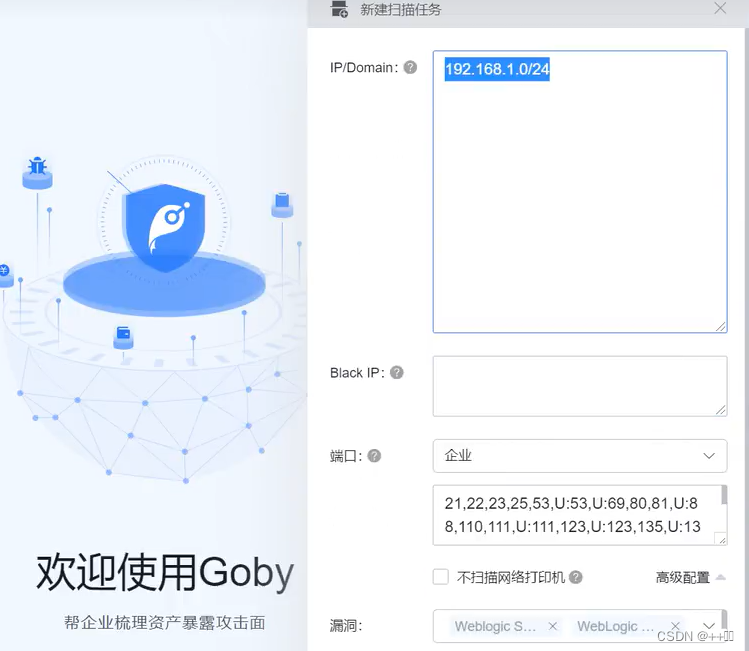
三、 使用FOFA查询接口批量查询收集URL
Python代码实现:
import requests
import base64#https://fofa.info/api/v1/search/all?email=your_email&key=your_key&qbase64=dGl0bGU9ImJpbmcidef get_fofa_data(email,apikey):for eduname in open('eduname.txt',encoding='utf-8'):e=eduname.strip()search='"%s" && country="CN" && title=="Error 404--Not Found"'%eb=base64.b64encode(search.encode('utf-8'))b=b.decode('utf-8')url='https://fofa.info/api/v1/search/all?email=%s&key=%s&qbase64=%s'%(email,apikey,b)s=requests.get(url).json()print('查询->'+eduname)print(url)if s['size'] != 0:print(eduname+'有数据啦!')for ip in s['results']:print(ip[0])else:print('没有数据')if __name__ == '__main__':email='471656814@qq.com' #自己fofa账号apikey='0fccc926c6d0c4922cbdc620659b9a42' #fofa个人中心的apikeyget_fofa_data(email,apikey)



![[office] excel表格怎么绘制股票的CCI指标- #媒体#学习方法#笔记](https://img-blog.csdnimg.cn/img_convert/1ebb79143684ee3abb3d1201b0417670.jpeg)