导语
本文介绍了ODIS框架,这是一种新颖的Text-to-SQL方法,它结合了领域外示例和合成生成的领域内示例,以提升大型语言模型在In-context Learning中的性能。
- 标题:Selective Demonstrations for Cross-domain Text-to-SQL
- 会议:EMNLP 2023 Findings
- 链接:https://arxiv.org/abs/2310.06302
- 机构:The Ohio State University
1 引言
LLMs(如GPT-3、Codex、PaLM和LLaMA)在上下文学习(ICL)中展现了处理各种语言任务的强大能力。ICL依赖于包含任务指令和零或几个关于任务的示例演示的提示。近期研究已经评估了LLMs在跨领域文本到SQL任务上的性能,该任务将自然语言问题(NLQ)转换为新数据库的SQL查询。以往的工作让LLMs使用仅包含数据库信息而没有任何演示的提示,或利用与测试数据库不同的数据库相关联的领域外注释的NLQ-SQL对作为演示示例。
注意:这里的领域内就是指我们提供给LLM的Few-shot样例是和我们要解决的问题Question为同一个数据库的情形;领域外则是指使用的样例是其他数据库的情形。
然而,Rajkumar等人发现,使用领域内注释示例作为演示可以显著提升LLMs的性能,但获取此类数据可能成本较高,因为注释过程需要SQL专业人员。更重要的是,为每个新数据库注释示例会降低文本到SQL应用的泛化能力。这些观察自然引发了两个问题:
- 领域内注释示例中的哪些关键因素有助于性能提升?
- 我们能否在不依赖领域内注释的情况下利用领域内演示的好处?
本文首先研究领域内演示示例的作用,然后开发新技术在不利用领域内注释的情况下创建演示。作者评估了领域内注释中的三个方面:文本到SQL任务知识和格式、输入NLQ分布和输出SQL分布。实验表明,SQL分布在领域内演示中起着关键作用。这一发现启发作者通过生成采样SQL查询来合成领域内数据的想法。本文是首个利用合成示例进行文本到SQL的上下文学习的。此外,作者引入了一个新颖的演示选择框架ODIS,它利用领域外演示和领域内合成数据。通过自动从领域外和合成领域内数据中选择演示示例,并采用SQL引导的检索方法,该方法在两个跨领域文本到SQL数据集上一致优于微调和上下文学习的最先进模型。
总体而言,本文贡献包括三个方面:
- 对领域内演示的不同方面对文本到SQL的影响进行了全面分析。
- 提出了一个演示选择框架ODIS,它利用领域外和合成生成的领域内演示。
- 通过采用SQL引导的检索方法来选择领域外和合成领域内演示,ODIS一致优于基线方法和最先进的方法。
2 领域内示例的分析
这部分分析了领域内注释演示的作用和贡献。
2.1 实验设置
使用Spider和KaggleDBQA数据集。采用留一法评估领域内演示。具体来说,对于给定的测试示例,从与同一数据库关联的其余示例中随机选择演示,条件是所选演示示例不与测试示例共享相同的SQL模板,遵循模板分割方法。还要求所选演示具有不同的模板。图1展示了一个包含Spider数据库concert_singer中两个领域内演示的提示示例。使用Codex的Code-davinci-002作为LLM。

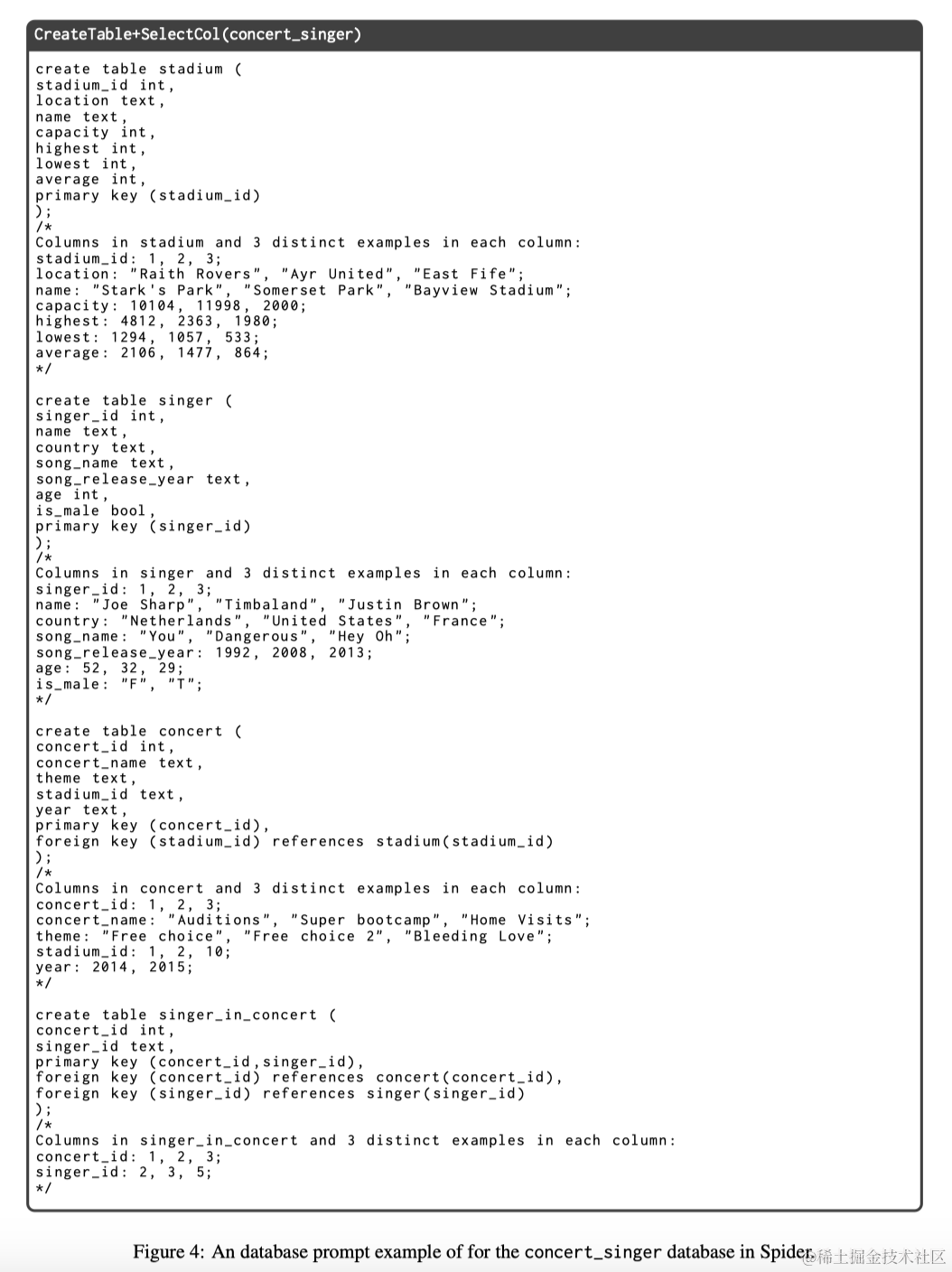
2.2 领域内注释的有效性
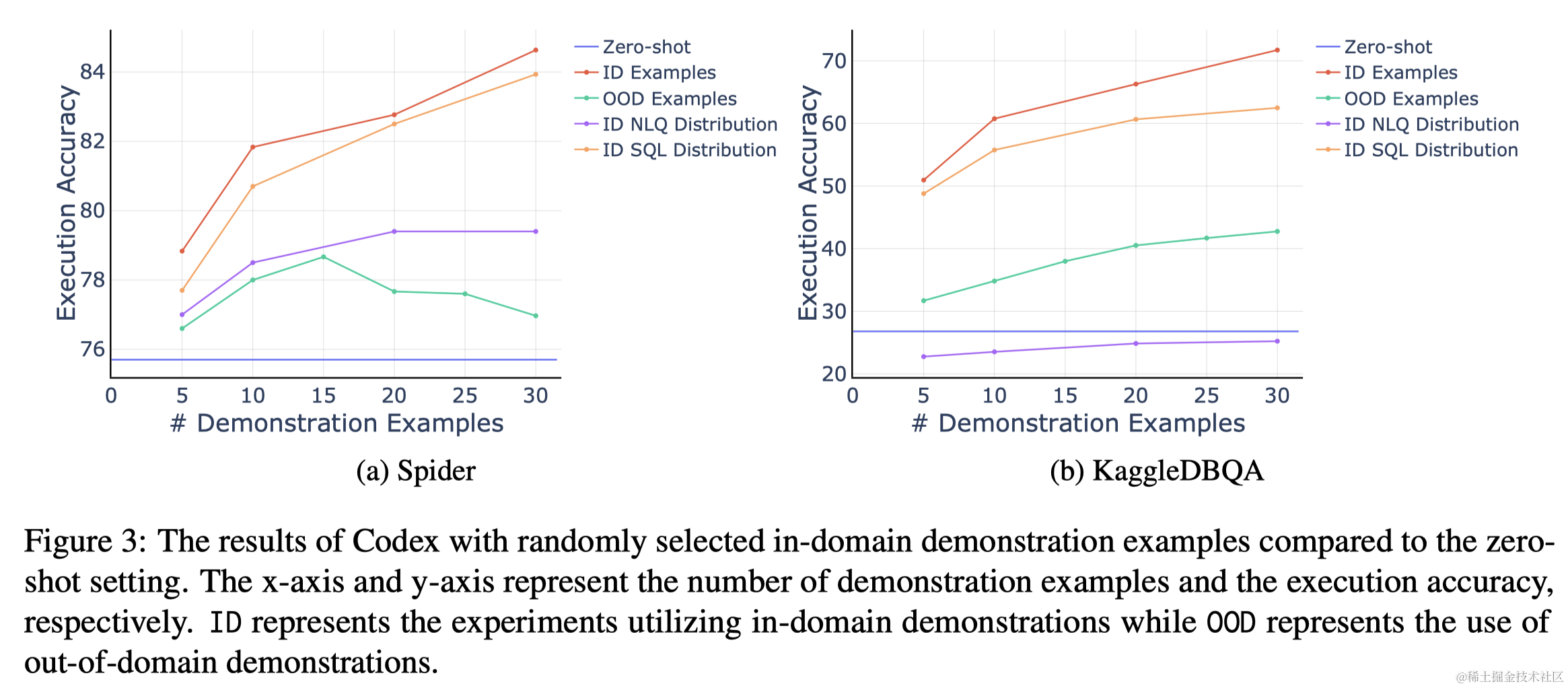
图3展示了Codex在Spider和KaggleDBQA上的执行准确度。Zero-shot设置下,Codex在Spider和KaggleDBQA上分别达到了75.7%和26.8%的执行准确度。使用领域内示例显著提高了Codex的性能。值得注意的是,随着领域内演示示例数量的增加,Codex的性能持续提升。
为了了解领域内演示中的关键因素,本文进行实验分析领域内演示的三个方面:
- 文本到SQL任务知识和格式、
- 领域内NLQ分布
- 领域内SQL查询分布。
第一个方面涉及领域无关的知识,而后两个方面特定于领域。
文本到SQL任务知识和格式
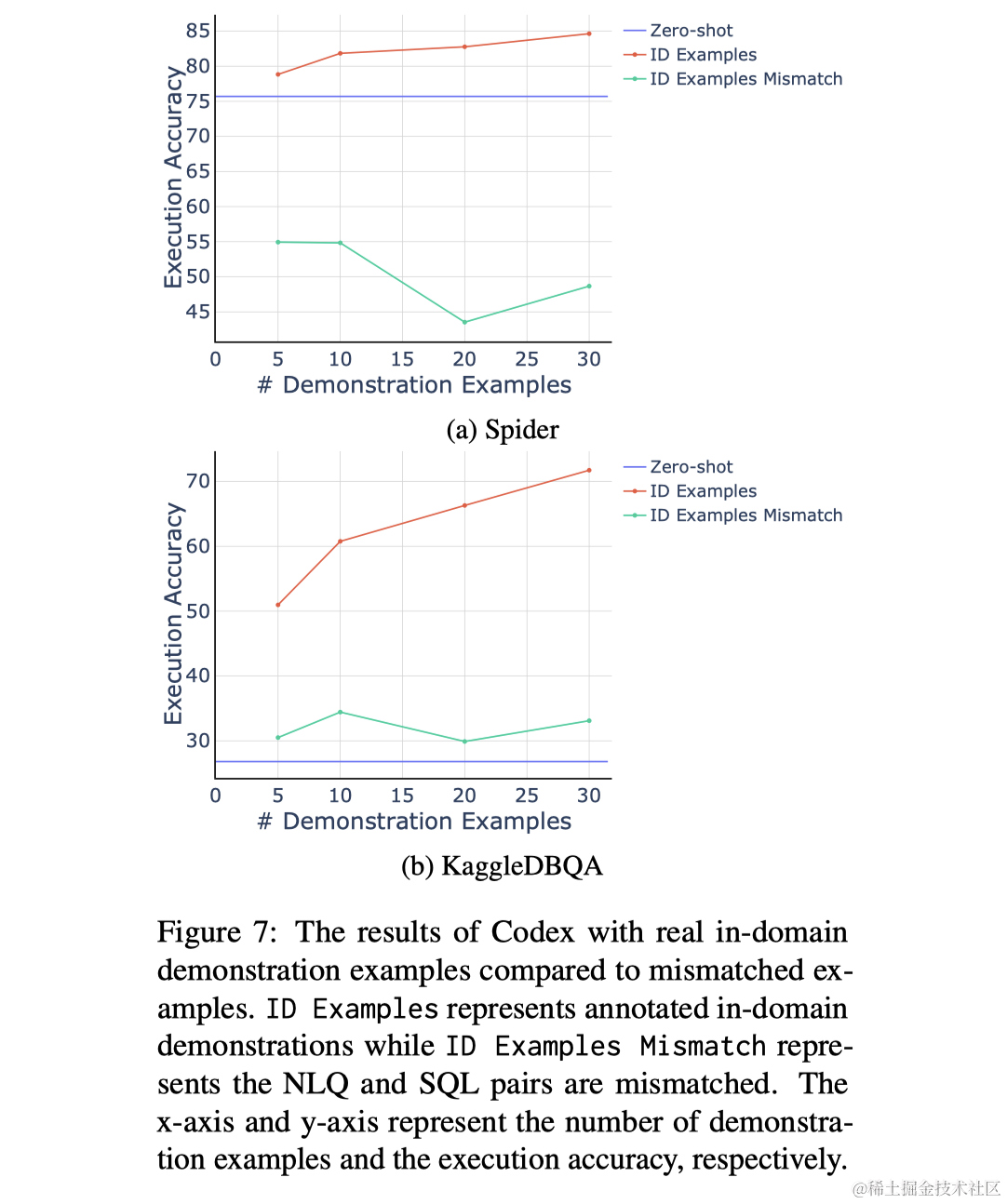
作者使用注释的领域外数据作为提供任务格式和知识的替代来源,让模型从与其他数据库相关联的注释NLQ和SQL对中学习正确的任务格式和知识。实验结果表明(图3中的OOD Examples),接触具有相同任务格式和知识的领域外示例确实可以提升模型的性能,但这种提升与领域内示例相比较小。此外,使用领域内演示实现的性能提升在一定数量的示例后趋于收敛,这与领域外示例所观察到的持续性能提升形成对比。另一个实验显示(图7),当使用不匹配的NLQs和SQLs作为演示时,模型的性能显著降低,强调了在演示中包含正确任务知识和格式的必要性。
领域内输入NLQ分布
除了任务知识,领域内示例还向LLMs展示了输入NLQ的分布。最近的研究表明,LLMs可以从了解输入分布中受益,特别是在分类任务中。为了评估输入分布的重要性,作者用Codex在Zero-shot设置下生成的预测替换演示示例中的gold SQL查询。这样,模型可以了解输入NLQ的分布,而不需要接触注释的SQL或超出其自身预测的任何额外知识。图3中的“ID NLQ分布”表明,对于Spider,提供领域内NLQ分布带来了一些好处,但与使用完整领域内数据相比不相上下。此外,对于KaggleDBQA数据集,提供领域内NLQ和自我预测的SQL查询并未显示出与不使用任何示例相比的任何优势,作者认为这是由于Codex在KaggleDBQA的零次示例设置下的准确度较低。
领域内输出SQL分布
领域内演示示例还具有向LLMs揭示输出SQL分布的作用。为了评估这一方面的重要性,使用相同的LLM(Codex)从oracle SQL查询生成合成NLQ。在演示示例中,用这些合成NLQ替换注释的NLQ,同时保持SQL查询不变。这种设置允许LLMs接触领域内SQL分布,同时不了解注释的领域内NLQ或超出其自身生成的NLQ的其他输入。图3中的“ID SQL分布”结果表明,提供带有合成NLQ的注释SQL查询可以大幅提升模型在Spider和KaggleDBQA数据集上的性能。此外,随着包含更多演示示例,性能提升继续增加,与使用实际领域内示例获得的结果一致。
3 方法
3.1 领域外演示创建
考虑到LLMs对演示示例选择的敏感性,作者提出了基于预测SQL查询相似性的检索策略SimSQL。该策略目标是从一组领域外注释示例中检索与测试数据库和问题相似的演示示例。
对于一个测试数据库d和一个问题x,目标是从一组领域外注释示例 e 1 , . . . , e N e_1 , ..., e_N e1,...,eN 中检索M个数据库,每个数据库包含K个NLQ和SQL对,其中 e i = ( d b i , x i , y i , y ^ i ) e_i = (db_i , x_i , y_i , \hat{y}_i ) ei=(dbi,xi,yi,y^i),分别代表数据库、输入NLQ、注释的SQL查询和LLM在零次示例场景下预测的SQL查询。所选的M个数据库及其相关示例将在测试数据库和问题之前展示,如图2所示。
算法1展示了整体过程:
- 首先在Zero-shot场景下生成一个初始SQL预测 y ^ i \hat{y}_i y^i(第1行);
- 根据它们的预测SQL查询 y ^ i \hat{y}_i y^i和 y ^ \hat{y} y^的相似性对领域外示例进行排序(第2行);
- 从高相似性到低相似性扫描领域外示例。一旦在数据库中找到K个示例,该数据库及其K个示例就被选为演示数据库和示例(第7-9行)。当选择M个数据库时,算法停止(第10-12行)。使用BM25对SQL查询中的SQL关键词和模式标记进行相似性度量。
3.2 领域内合成演示创建
领域内合成演示选择包括两个阶段:(1) 合成数据生成,和 (2) 合成数据检索。
合成数据生成:首先采样合成SQL查询{ y i y_i yi },然后将SQL查询转换为自然语言问题{ x i x_i xi }。使用SHiP来采样合成SQL查询,从领域外数据库中提取模板,并从测试数据库中采样列和值来填充这些模板。接着,使用Codex来生成相应的合成NLQ。为提高合成数据的质量,添加一个验证过程。使用Codex将合成NLQ x i x_i xi 反向转换为SQL y ^ i \hat{y}_i y^i,并过滤掉 y ^ i \hat{y}_i y^i 和 y i y_i yi 执行结果不同的示例。
合成数据检索:考虑到oracle SQL分布通常依赖于领域特定的先验知识,因此,本文的重点不是寻找与测试问题高度相似的SQL查询,而是检索涵盖预期SQL查询不同方面的多个查询。采用了Levy等人(2022)提出的算法启发的贪婪算法。算法2概述了从合成领域内示例中检索演示的过程:
- 创建一个需要覆盖的标记集合 S u n c o v e r S_{uncover} Suncover ,它以测试问题的初始SQL预测中提到的SQL关键词和模式标记为初始化(第3行)。
- 检索与S uncover 相似度最高的合成SQL,相似度用BM25分数测量(第5行)。 S u n c o v e r S_{uncover} Suncover 将通过移除检索到的SQL查询中的标记和添加检索到的示例到演示列表来更新(第8 - 9行)。重复这个过程,直到 S u n c o v e r S_{uncover} Suncover 变为空(第17行)或无法检索到包含 S u n c o v e r S_{uncover} Suncover 中任何标记的合成SQL(第14行)。
- 如果选择的示例数量少于最大期望值,再次重复步骤(1)和(2)(第2行)。
4 实验
4.1 基准方法与前期工作
- 基于微调的方法:SmBoP、T5+Picard、ShiP+Picard和RESDSQL。
- 上下文学习方法:包括Rajkumar等人、Chang和Fosler-Lussier、Lan等人提出的方法,还包括了SYNCHROMESH和SKILLKNN、LEVER、Self-Debug和DIN-SQL。
- 我们的方法:将其与仅使用领域外数据或合成领域内源的演示示例的基准方法进行比较。此外,通过将SimSQL和CovSQL与随机检索策略以及基于输入NLQ相似度的SimNLQ方法进行比较,以评估这些策略。使用SentenceBERT编码的句子嵌入的余弦距离来衡量相似度。
4.2 实验设置
使用Spider的训练集作为选择领域外演示示例的池,在最终预测中使用了闭源LLMs Codex和ChatGPT,以及开源LLM CodeLLama进行实验3。由于资源限制,仅使用Codex来检索演示示例。
5 结果
5.1 主要结果
表1和表2展示了ODIS在Spider和KaggleDBQA数据集上与最新方法的执行准确度。ODIS展示了比仅依赖领域外或合成领域内演示示例的基准方法更优越的性能,无论使用哪种LLM。这些结果强调了在ODIS框架中利用两种来源的演示示例的有效性。
5.2 分析
领域外检索:基于预测SQL查询相似性的检索方法优于随机选择和基于NLQ相似性的方法。使用oracle SQL查询进一步提高了性能。
领域内合成演示检索:检索覆盖初始SQL预测不同部分的合成SQL查询表现更优。CoverSQL和SimSQL方法在KaggleDBQA数据集上取得了相同的结果,超过随机选择和基于NLQ相似性的方法。
合成数据的影响:合成数据的质量对ODIS框架至关重要。使用不同的SQL合成方法(如SHiP和GAZP)对性能有显著影响。
鲁棒性评估:在Dr. Spider测试中,ODIS表现出较高的鲁棒性,尤其在NLQ扰动情况下,性能超过监督学习和其他上下文学习方法。
6 相关工作
略
7 总结和未来工作
本研究深入分析了领域内演示示例的关键方面,并确定SQL分布为关键因素。本文提出了一个新颖的演示选择框架ODIS,它利用基于SQL的检索方法结合领域外演示和领域内合成示例的优势。在不同的大型语言模型上取得的显著性能表明,与基线和最新方法相比,本文的框架非常有效。
未来工作方面,计划从以下方向考虑:
- 统一检索策略:将探索一个统一的检索策略,打破领域外和领域内合成数据之间的界限,实现它们之间的自动选择。
- 提升初始模型性能:考虑使用更高性能的初始文本到SQL模型以进一步提高性能,如第5.2节通过使用oracle SQL查询所展示的。
- 参数高效微调:考虑将ODIS扩展到Few-shot Learning,通过利用这些混合数据源(领域外示例和领域内合成示例)进行参数高效微调,留待未来研究探索。