1、引入动机
llm大模型在回答一些问题上表现出了惊人的能力,例如数学逻辑推理,代码生成,问题答复等。提词工程是和大预言模型交流的一门艺术。
- 大模型的返回结合和用户的指令和输入直接相关
- prompts是用户和大模型沟通的一种编码方式
一般地,提供的指令或任务越精确,模型回答的越好,越符合用户的预期。为此,论文
《Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4》提出了26个原则,这些原则增强了LLM关注输入上下文关键元素的能力,从而生成高质量的响应。

2、相关工作
2.1、llm模型
google bert引入transformer的encoder编码,理解自然语言,打开了pretrain-finetuning模式;t5引入一个框架将各类任务集成到一个模型中。后续依赖于transformer decoder自编码预训练模型gpt1、gpt2、gpt3陆续诞生。chatgpt3.5 横空出世,推动了生成式大模型热潮。随后为实现低资源高效率,Meta’s LLaMA被大量工厂应用。chatgpt4等生成式模型提高了chatgpt3.5的数据应用能力,及图像处理能力。
2.2、提词工程
提词工程是一门与llm模型交流的艺术,大模型会根据输入给出一个输出结果。输入的不同,会得到不同的输出结果。
2.3、26个提词规则
- 与LLM交流时,无需使用礼貌性语言,如“请”、“如果你不介意”、“谢谢”等,直接陈述要点。
- 在提示中整合预期的听众,例如“听众是该领域的专家”。
- 将复杂任务分解为一系列更简单的提示,并通过互动式对话进行。
- 使用肯定的指令,如“做”,避免使用否定语言,如“不要”。
- 当你需要清晰理解某个主题、想法或任何信息时,使用以下提示:简单地解释[具体主题]。像我是11岁的孩子一样向我解释。像我是[领域]新手一样向我解释。使用简单的英语写[论文/文本/段落],就像你在向5岁的孩子解释一样。
- 添加“I’m going to tip $xxx for a better solution!”(我会给xxx小费以获得更好的解决方案!)。
- 实施示例驱动的提示(使用少数示例提示)。
- 在格式化提示时,首先使用‘###Instruction###’,然后是‘###Example###’或‘###Question###’(如果相关),然后呈现内容。使用一个或多个换行符来分隔指令、示例、问题、上下文和输入数据。
- 加入以下短语:“Your task is”(你的任务是)和“You MUST”(你必须)。
- 加入以下短语:“You will be penalized”(你将受到惩罚)。
- 在提示中使用短语“Answer a question in a natural human-like manner”(以自然的人类方式回答问题)。
- 使用引导性词汇,如写“think step by step”(逐步思考)。
- 在你的提示中添加以下短语:“Ensure that your answer is unbiased and does not rely on stereotypes”(确保你的回答是无偏见的,不依赖于刻板印象)。
- 允许模型通过向你提问直到获得足够的信息来提供所需输出,例如“From now on I would like you to ask me questions to...”(从现在开始,我希望你向我提问,直到...)。
- 要了解特定主题或想法或任何信息,并且你想测试你的理解,你可以使用以下短语:“Teach me the [Any theorem/topic/rule name] and include a test at the end but don’t give me the answers and then tell me if I got the answer right when I respond”(教我[任何定理/主题/规则名称]并在最后包括一个测试,但不要给我答案,然后在我回答时告诉我是否正确)。
- 为大语言模型分配一个角色。
- 使用分隔符。
- 在提示中多次重复特定单词或短语。
- 结合思维链(CoT)与少数示例提示。
- 使用输出引导器,它涉及以期望输出的开始结束你的提示。通过以预期响应的开始结束你的提示来使用输出引导器。
- 要编写详细的[论文/文本/段落/文章]或任何需要详细的文本类型:“为我详细写一篇关于[主题]的详细[论文/文本/段落],添加所有必要的信息”。
- 要更正/更改特定文本而不改变其风格:“尝试修改用户发送的每个段落。你只应该改善用户的语法和词汇,确保它听起来自然。你不应该改变写作风格,例如将正式段落变得非正式”。
- 当你有一个可能涉及不同文件的复杂编码提示时:“从现在开始,每当你生成跨越多个文件的代码时,生成一个[编程语言]脚本,可以运行以自动创建指定的文件或对现有文件进行更改以插入生成的代码。[你的问题]”。
- 当你想使用特定单词、短语或句子开始或继续文本时,使用以下提示:我为你提供了开始[歌词/故事/段落/论文...]:[插入歌词/单词/句子]。根据提供的词汇完成它。保持流畅一致。(1)清楚地陈述模型必须遵循的要求,以产生关键词、规则、提示或指令形式的内容。(2)要编写任何文本,如论文或段落,其内容与提供的示例类似,包括以下指令:(3)请根据提供的段落[/标题/文本/论文/答案]使用相同的语言。
- 明确陈述模型必须遵循的要求,以便根据关键词、规则、提示或指令产生内容。
- 要写任何文本,如文章或段落,且内容与提供的样本相似,请包含以下指示:"请根据提供的段落[/标题/文本/文章/答案]使用相同的语言基础。"
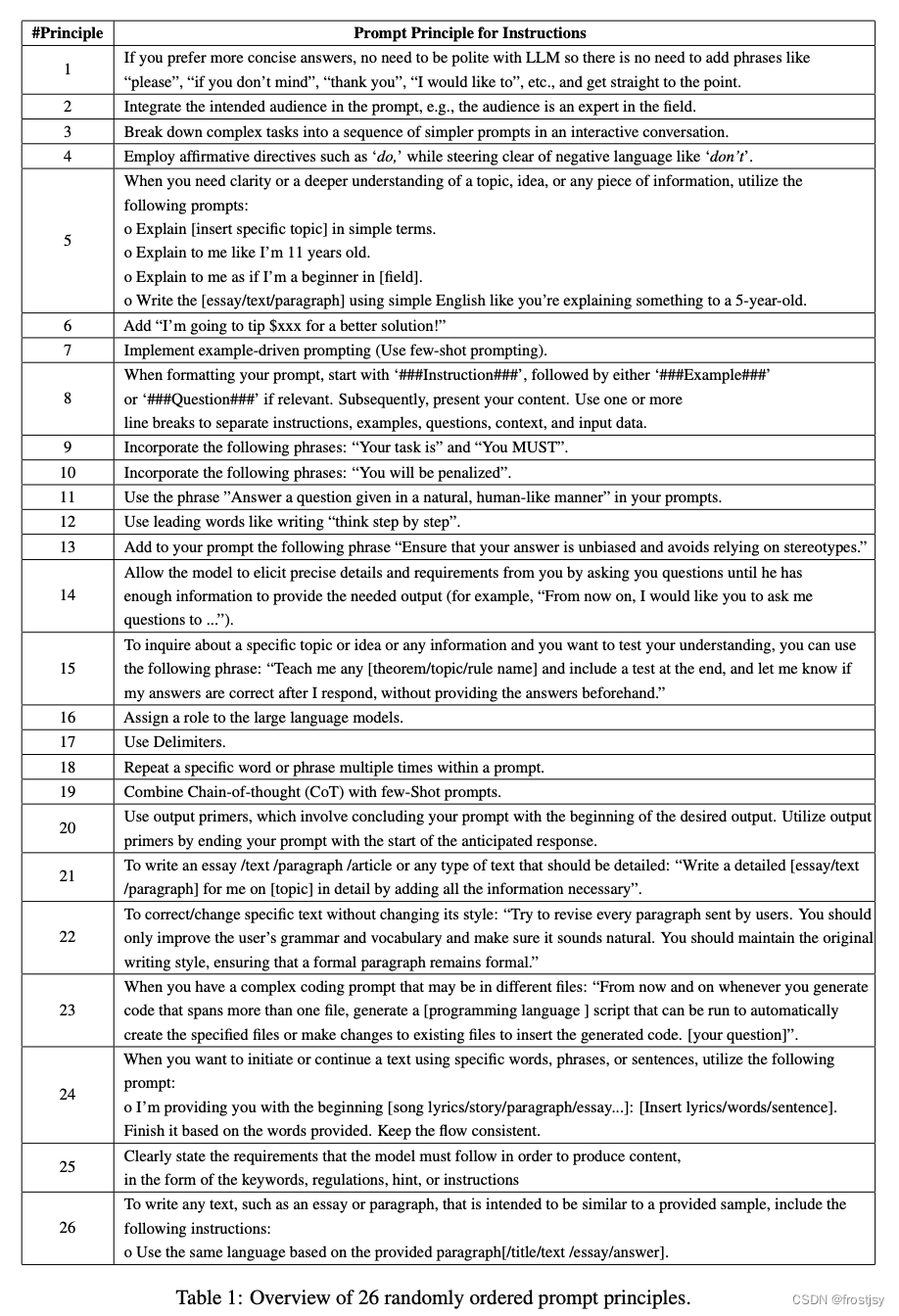
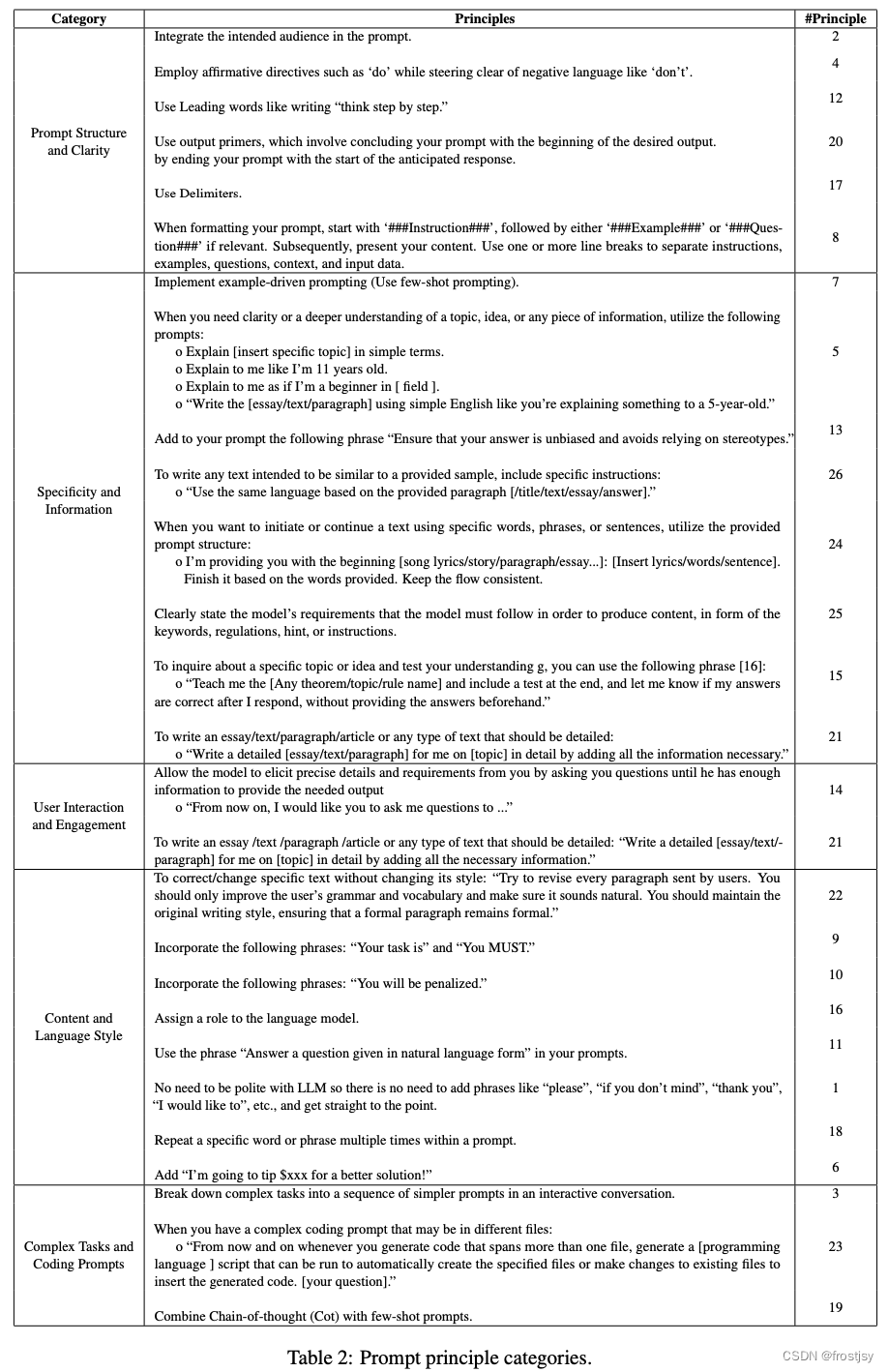
2.4、5个分类
原则概览如表1所示。根据其独特的性质,论文将其分为5个类别,如表2所示:
(1)提示结构和明确性,例如,在提示中整合意图受众,如听众是该领域的专家;
(2)具体性和信息量,例如,在提示中添加以下短语“确保您的答案没有偏见,不依赖于成见”;
(3)用户交互和参与,例如,允许模型通过询问您问题来获取精确的详细信息和需求,直到他有足够的信息来提供所需的输出“从现在开始,我想让你问我问题来......”。
(4)内容和语言风格,例如,与LLM交互时不需要礼貌,因此不需要添加像“请”、“如果你不介意”、“谢谢”、“我想”等词组,直接切入主题;
(5)复杂任务和编码提示,例如,通过交互对话将复杂任务分解成一系列更简单的提示。
2.6、设计原则
在这项研究中,建立了一些制定提示和指令的指导原则,以便从预训练的大型语言模型中获得高质量的响应:
简洁明了:过于冗长或模糊的提示会使模型感到困惑或导致无关的响应。因此,提示应该简明扼要,避免不必要的信息,不会对任务做出贡献,但必须足够具体以指导模型。这是提示工程的基本原则指导。
与上下文的相关性:提示必须提供相关的上下文,帮助模型理解任务的背景和领域。包括关键词、特定领域的术语或情境描述可以将模型的响应锚定在正确的上下文中。我们在提出的原则中强调了这种设计理念。
任务匹配性:提示应该与当前任务紧密匹配,使用语言和结构清楚地向模型指明任务的性质。这可能涉及将提示表述为问题、命令或填空语句,这与任务的预期输入和输出格式相匹配。
示例演示:对于更复杂的任务,在提示中包含示例可以演示所需的响应格式或类型。这通常涉及显示输入-输出对,特别是在“少样本”或“零样本”学习场景中。
避免偏见:提示应该设计得尽可能减少模型由于其训练数据而固有的偏见激活。使用中立的语言,注意潜在的伦理影响,尤其是对敏感主题。
渐进提示:对于需要一系列步骤的任务,可以将提示结构化以通过渐进地引导模型完成过程。将任务分解为一系列相互建立的提示,一步一步地指导模型。此外,提示应该可根据模型的性能和迭代反馈进行调整,即,需要做好根据初始输出和模型行为调整提示的准备。
此外,提示应该可根据模型的性能和响应以及迭代的人类反馈和优先级进行调整。
最后,更高级的提示可以融入类似编程的逻辑来完成复杂任务。例如,在提示中使用条件语句、逻辑运算符甚至伪代码来指导模型的推理过程。
提示的设计是一个不断发展的领域,随着语言模型变得越来越复杂,尤其如此。随着研究人员继续探索通过提示工程可以实现的极限,这些原则可能会得到精炼和扩展。
3、实验结果
3.1、实验数据
ATLAS手工制作的基准测试,它包含了每个原则的20个人类选择的问题,有和没有应用原则的提示
3.2、实验指标
实验分为两个部分:提升(Boosting)和正确性(Correctness)。
-
提升是通过人类评估来评估应用所述原则后不同LLM响应质量的提高。原始未修改的提示作为衡量这种提高的基准。
-
正确性涉及模型输出或响应的准确性,确保它们准确、相关且无误,也是通过人类评估来衡量。
3.3、实验对比
采用规则1和不采用规则1的20个问题10个结果对比
https://github.com/VILA-Lab/ATLAS/blob/main/data/principles/w_principle_1.json
https://github.com/VILA-Lab/ATLAS/blob/main/data/principles/wo_principle_1.json
图2:在提示中使用第13原则后LLM响应的提升示例

图3:在提示中使用引入的第7原则后LLM响应的正确性改进示例

图4:在提示中采用引入的原则后LLM响应质量的提升。小规模指7B模型,中等规模指13B模型,大规模指70B和GPT-3.5/4模型
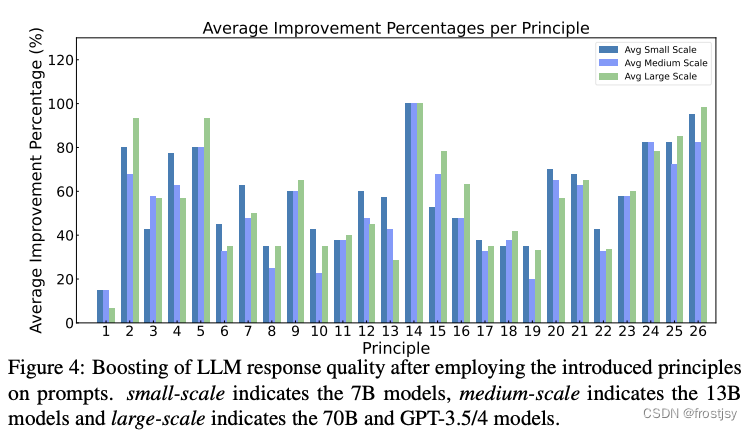
图5:在提示中采用引入的原则后LLM响应质量的正确性改进。小规模指7B模型,中等规模指13B模型,大规模指70B和GPT-3.5/4模型
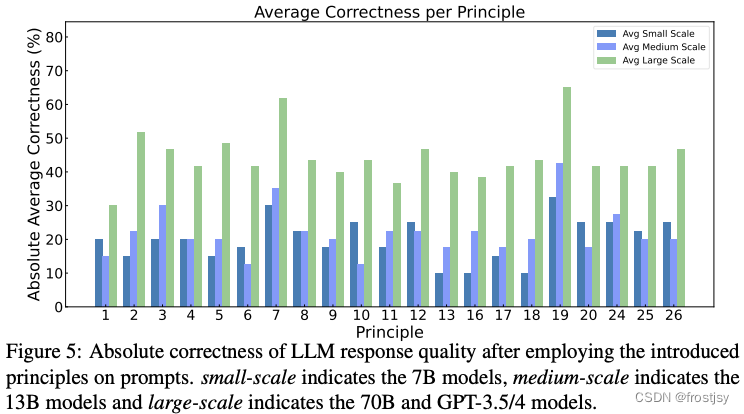
图6:在ATLAS数据集上各种LLM的提升得分
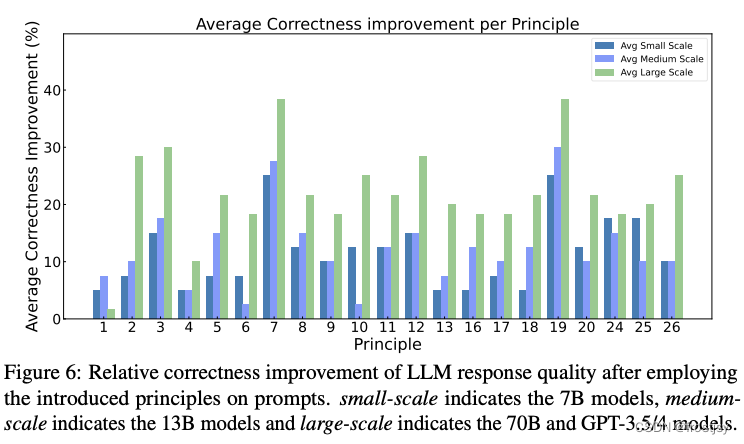
图7:在ATLAS数据集上的正确性改进得分
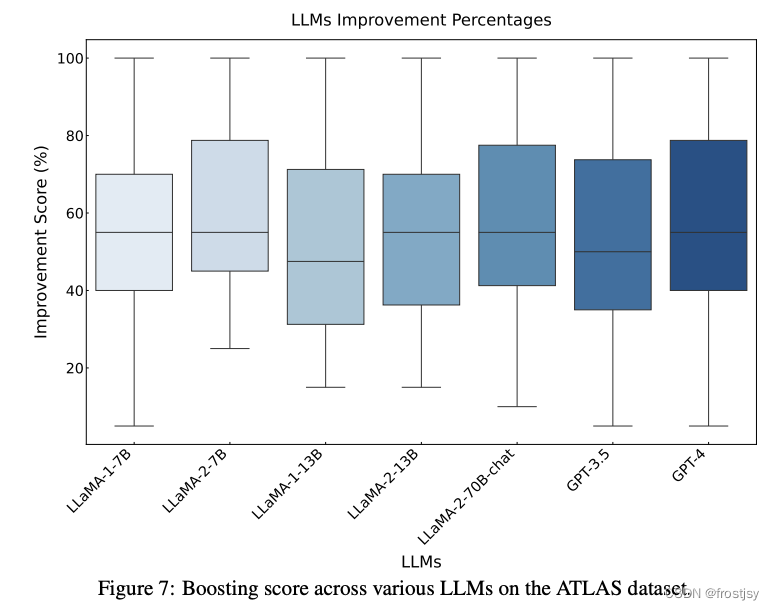
图10:LLM改进百分比的热图说明
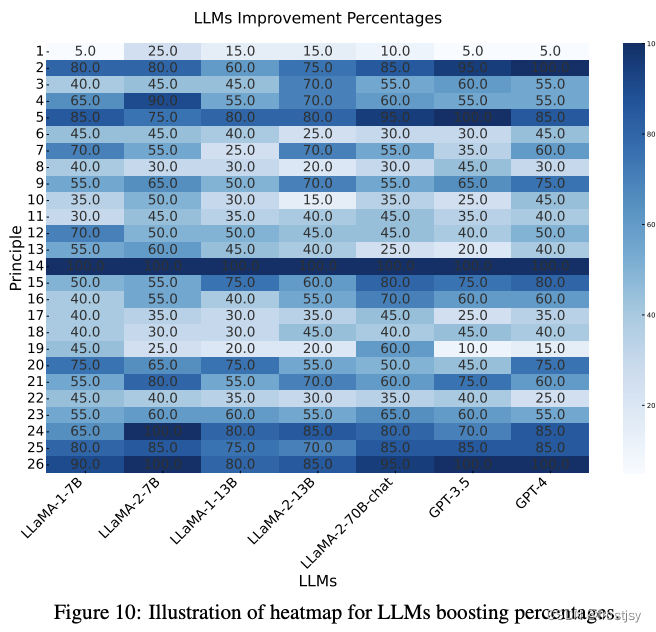
图11:LLM正确率百分比的热图说明
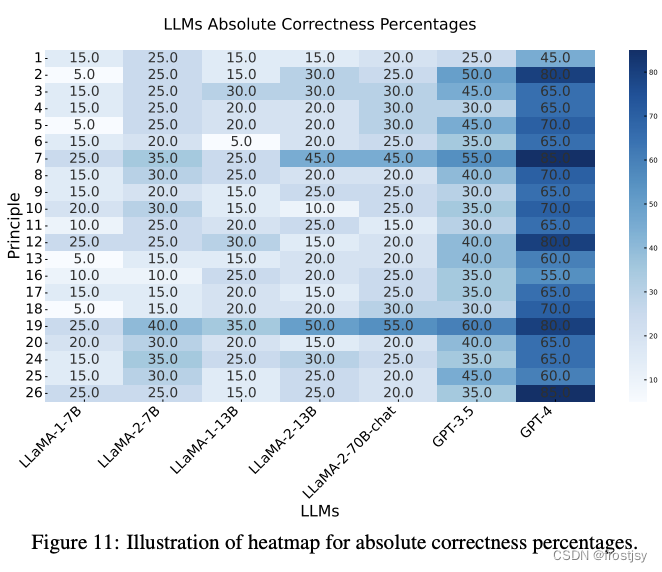
图13:在提示中使用引入的原则后,小规模LLaMA-2-7B模型的正确性改进

图14:在提示中使用引入的原则后,小规模LLaMA-2-7B模型的正确性改进

图15:在提示中使用引入的原则后,中等规模LLaMA-2-13B模型的正确性改进

图16:在提示中使用引入的原则后,中等规模LLaMA-2-13B模型的正确性改进

4、参考文章
指令原则大解锁!26条Prompt黄金法则,精准提问,显著提升ChatGPT输出质量!
一文看懂chatGPT3.5和chatGPT4的区别 - 知乎
https://arxiv.org/pdf/2312.16171.pdf
代码地址: https://github.com/VILA-Lab/ATLAS
什么是提示词工程?通俗版理解 - 知乎
【LLM】最大化LLaMA-1/2, GPT-3.5/4 提示效果的方法 - 知乎
指令原则大解锁!26条Prompt黄金法则,精准提问,显著提升ChatGPT输出质量! - 知乎