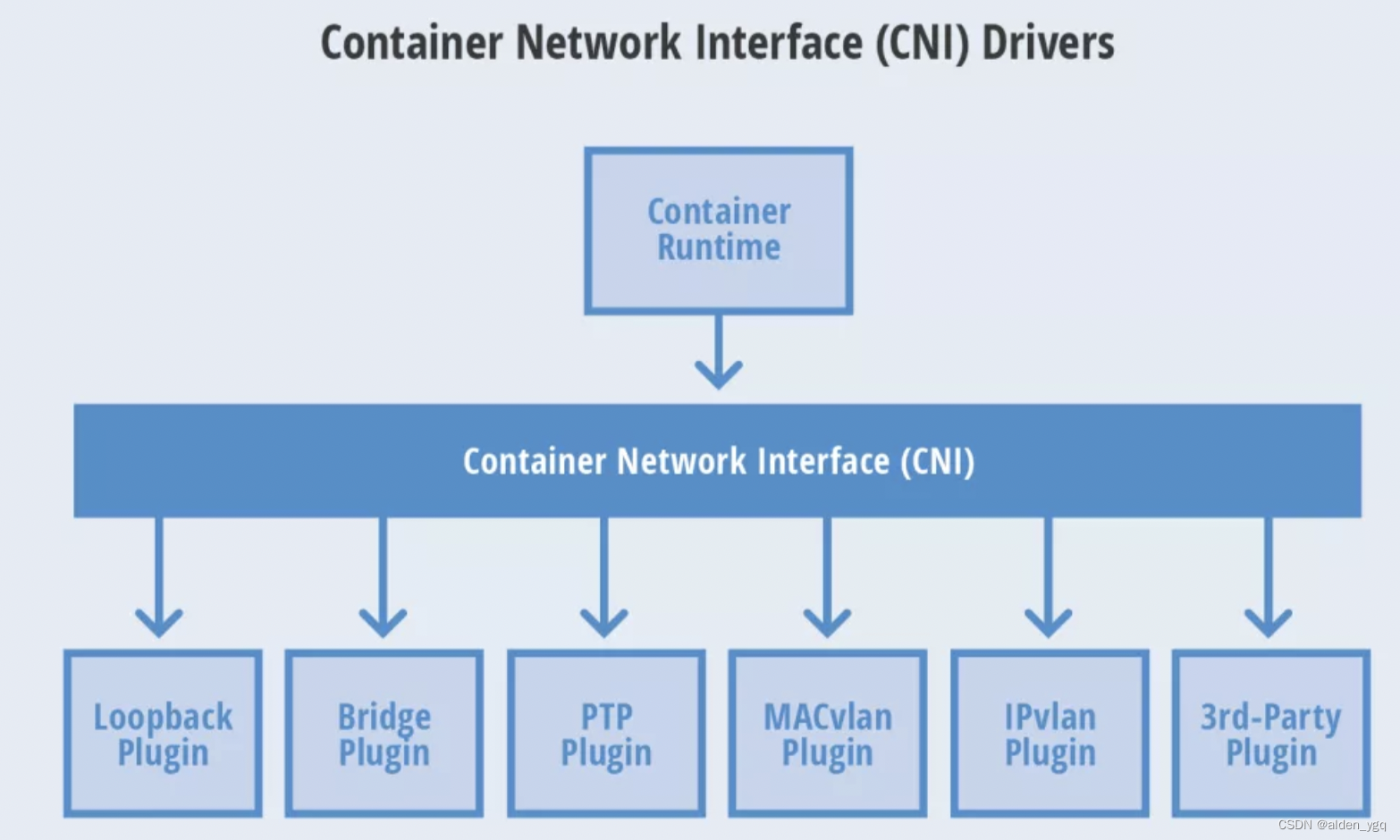
1 CNI概述
1.1 什么是CNI?
Kubernetes 本身并没有实现自己的容器网络,而是借助 CNI 标准,通过插件化的方式来集成各种网络插件,实现集群内部网络相互通信。
CNI(Container Network Interface,容器网络的 API 接口),是 Google 和 CoreOS 联合定制的网络标准,它是在 RKT 网络提议的基础上发展起来的,综合考虑了灵活性、扩展性、IP 分配、多网卡等因素。Kubernetes 网络的发展方向是希望通过 Plugin 的方式来集成不同的网络方案, CNI 就是这一努力的结果。
CNI 旨在为容器平台提供网络的标准化,为解决容器网络连接和容器销毁时的资源释放,提供了一套框架。所以 CNI 可以支持大量不同的网络模式,并且容易实现。不同的容器平台(e.g. Kubernetes、Mesos 和 RKT)能够通过相同的接口调用不同的网络组件。
CNI(容器网络接口)是一个云原生计算基金会项目,它包含了一些规范和库,用于编写在 Linux 容器中配置网络接口的一系列插件。CNI 只关注容器的网络连接,并在容器被删除时移除所分配的资源。
Kubernetes 使用 CNI 作为网络提供商和 Kubernetes Pod 网络之间的接口。
1.2 CNI 规范
CNI 规范的几点原则:
- CNI Plugin 负责连接容器(Linux network namespace)。
- CNI 的网络定义以 JSON 的格式存储。
- 有关网络的配置通过 stdin(Linux 标准输入)的方式传递给 CNI Plugin,其他的参数通过 ENV(环境变量)的方式传递。
- CNI 插件是以 exec(可执行文件)的方式实现的。
CNI 规范定义的核心接口:
- ADD:将容器添加到网络;
- DEL:从网络中删除一个容器;
- CHECK:检查容器的网络是否符合预期等;
- ....
CNI 对象定义了两个组件,包括:
- Container Management System
- Network Plugin:CNI 接收到的具体请求都是由 Plugin 来完成的,例如:创建容器网络空间(network namespace)、把网络接口(interface)放到对应的网络空间、给网络接口分配 IP 等。
1.3 CNI Plugin
在部署 Kubernetes 的时候,有一个步骤是安装 kubernetes-cni 包,它的目的就是在宿主机上安装 CNI 插件所需的基础可执行文件。这些可执行文件包括(查看 /opt/cni/bin 目录可以看到):
$ ls -al /opt/cni/bin/
total 73088
-rwxr-xr-x 1 root root 3890407 Aug 17 2017 bridge
-rwxr-xr-x 1 root root 9921982 Aug 17 2017 dhcp
-rwxr-xr-x 1 root root 2814104 Aug 17 2017 flannel
-rwxr-xr-x 1 root root 2991965 Aug 17 2017 host-local
-rwxr-xr-x 1 root root 3475802 Aug 17 2017 ipvlan
-rwxr-xr-x 1 root root 3026388 Aug 17 2017 loopback
-rwxr-xr-x 1 root root 3520724 Aug 17 2017 macvlan
-rwxr-xr-x 1 root root 3470464 Aug 17 2017 portmap
-rwxr-xr-x 1 root root 3877986 Aug 17 2017 ptp
-rwxr-xr-x 1 root root 2605279 Aug 17 2017 sample
-rwxr-xr-x 1 root root 2808402 Aug 17 2017 tuning
-rwxr-xr-x 1 root root 3475750 Aug 17 2017 vlan从 Network Plugin 实现的功能可以把 CNI Plugin 分为 5 类:
- Main 插件:创建具体的网络设备。有以下类型:
- bridge:网桥设备,连接 Container 和 Host;
- ipvlan:为容器增加 ipvlan 网卡;
- loopback:回环设备;
- macvlan:为容器创建一个 MAC 地址;
- ptp:创建一对 Veth Pair;
- vlan:分配一个 vlan 设备;
- host-device:将已存在的设备移入容器内。
- IPAM 插件:负责分配 IP 地址。有以下类型:
- dhcp:容器向 DHCP 服务器发起请求,给 Pod 发放或回收 IP 地址;
- host-local:使用预先配置的 IP 地址段来进行分配;
- static:为容器分配一个静态 IPv4/IPv6 地址,主要用于 Debug 场景。
- META 插件:其他功能的插件。有以下类型
- tuning:通过 sysctl 调整网络设备参数;
- portmap:通过 iptables 配置端口映射;
- bandwidth:使用 Token Bucket Filter 来限流;
- sbr:为网卡设置 source based routing;
- firewall:通过 iptables 给容器网络的进出流量进行限制。
- Windows 插件:专门用于 Windows 平台的 CNI 插件。
- win-bridge
- win-overlay 网络插件。
- 第三方网络插件:第三方开源的网络插件众多,每个组件都有各自的优点及适应的场景,难以形成统一的标准组件,常用有 Flannel、Calico、Cilium、OVN 网络插件。
大部分的 CN I插件功能设计上遵守功能职责单一原则,比如:
- Bridge 插件负责网桥的相关配置;
- Firewall 插件负责防火墙相关配置;
- Portmap 插件负责端口映射相关配置
1.4 CNI工作原理
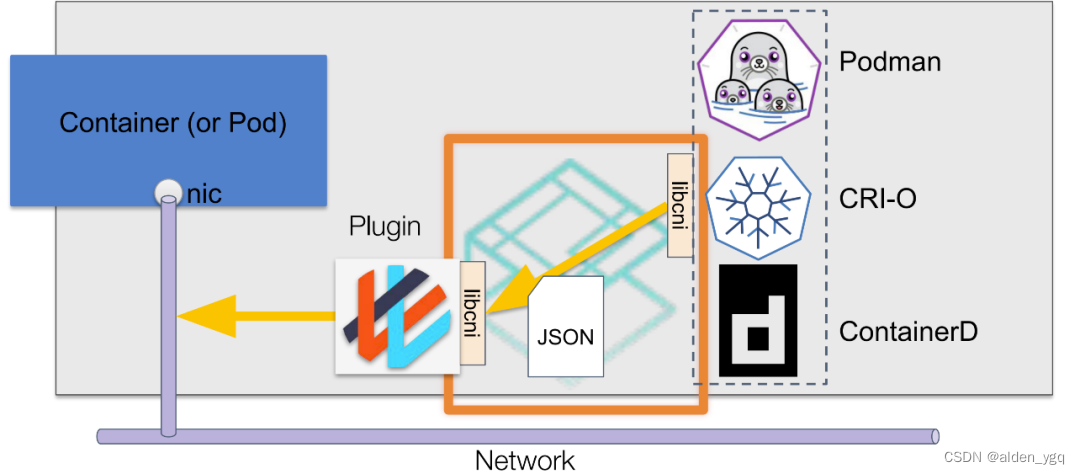
CNI通过JSON格式的配置文件来描述网络配置,当需要设置容器网络时,由容器运行时负责执行CNI插件,并通过CNI插件的标准输入(stdin)来传递配置文件信息,通过标准输出(stdout)接收插件的执行结果。图中的 libcni 是CNI提供的一个go package,封装了一些符合CNI规范的标准操作,便于容器运行时和网络插件对接CNI标准。
案例:假如需要调用bridge插件将容器接入到主机网桥,则调用的命令如下:
# CNI_COMMAND=ADD 顾名思义表示创建。
# XXX=XXX 其他参数定义见下文。
# < config.json 表示从标准输入传递配置文件
CNI_COMMAND=ADD XXX=XXX ./bridge < config.json1.4.1 网络插件入参
容器运行时通过设置环境变量以及从标准输入传入的配置文件来向插件传递参数。
1.4.1.1 环境变量
- CNI_COMMAND :定义期望的操作,可以是ADD,DEL,CHECK或VERSION。
- CNI_CONTAINERID : 容器ID,由容器运行时管理的容器唯一标识符。
- CNI_NETNS:容器网络命名空间的路径。(形如
/run/netns/[nsname])。 - CNI_IFNAME :需要被创建的网络接口名称,例如eth0。
- CNI_ARGS :运行时调用时传入的额外参数,格式为分号分隔的key-value对,例如 FOO=BAR;ABC=123
- CNI_PATH : CNI插件可执行文件的路径,例如
/opt/cni/bin。
1.4.1.2 配置文件
文件示例:
{"cniVersion": "0.4.0", // 表示希望插件遵循的CNI标准的版本。"name": "dbnet", // 表示网络名称。这个名称并非指网络接口名称,是便于CNI管理的一个表示。应当在当前主机(或其他管理域)上全局唯一。"type": "bridge", // 插件类型"bridge": "cni0", // bridge插件的参数,指定网桥名称。"ipam": { // IP Allocation Management,管理IP地址分配。"type": "host-local", // ipam插件的类型。// ipam 定义的参数"subnet": "10.1.0.0/16","gateway": "10.1.0.1"}
}1.4.1.2.1 公共定义部分
配置文件分为公共部分和插件定义部分。公共部分在CNI项目中使用结构体NetworkConfig定义:
type NetworkConfig struct {Network *types.NetConfBytes []byte
}
...
// NetConf describes a network.
type NetConf struct {CNIVersion string `json:"cniVersion,omitempty"`Name string `json:"name,omitempty"`Type string `json:"type,omitempty"`Capabilities map[string]bool `json:"capabilities,omitempty"`IPAM IPAM `json:"ipam,omitempty"`DNS DNS `json:"dns"`RawPrevResult map[string]interface{} `json:"prevResult,omitempty"`PrevResult Result `json:"-"`
}
cniVersion表示希望插件遵循的CNI标准的版本。name表示网络名称。这个名称并非指网络接口名称,是便于CNI管理的一个表示。应当在当前主机(或其他管理域)上全局唯一。type表示插件的名称,也就是插件对应的可执行文件的名称。bridge该参数属于bridge插件的参数,指定主机网桥的名称。ipam表示IP地址分配插件的配置,ipam.type则表示ipam的插件类型。
更详细的信息,可以参考官方文档。
1.4.1.2.2 插件定义部分
上文提到,配置文件最终是传递给具体的CNI插件的,因此插件定义部分才是配置文件的“完全体”。公共部分定义只是为了方便各插件将其嵌入到自身的配置文件定义结构体中,举bridge插件为例:
type NetConf struct {types.NetConf // <-- 嵌入公共部分// 底下的都是插件定义部分BrName string `json:"bridge"`IsGW bool `json:"isGateway"`IsDefaultGW bool `json:"isDefaultGateway"`ForceAddress bool `json:"forceAddress"`IPMasq bool `json:"ipMasq"`MTU int `json:"mtu"`HairpinMode bool `json:"hairpinMode"`PromiscMode bool `json:"promiscMode"`Vlan int `json:"vlan"`Args struct {Cni BridgeArgs `json:"cni,omitempty"`} `json:"args,omitempty"`RuntimeConfig struct {Mac string `json:"mac,omitempty"`} `json:"runtimeConfig,omitempty"`mac string
}
各插件的配置文件文档可参考官方文档。
1.4.1.3 插件操作类型
CNI插件的操作类型只有四种:ADD , DEL , CHECK 和 VERSION。插件调用者通过环境变量 CNI_COMMAND 来指定需要执行的操作。
1.4.1.3.1 ADD
ADD 操作负责将容器添加到网络,或对现有的网络设置做更改。具体地说,ADD 操作要么:
- 为容器所在的网络命名空间创建一个网络接口,或者
- 修改容器所在网络命名空间中的指定网络接口
例如通过 ADD 将容器网络接口接入到主机的网桥中。
其中网络接口名称由 CNI_IFNAME 指定,网络命名空间由 CNI_NETNS 指定。
1.4.1.3.2 DEL
DEL 操作负责从网络中删除容器,或取消对应的修改,可以理解为是 ADD 的逆操作。具体地说,DEL 操作要么:
- 为容器所在的网络命名空间删除一个网络接口,或者
- 撤销 ADD 操作的修改
例如通过 DEL 将容器网络接口从主机网桥中删除。
其中网络接口名称由 CNI_IFNAME 指定,网络命名空间由 CNI_NETNS 指定。
1.4.1.3.3 CHECK
CHECK 操作是v0.4.0加入的类型,用于检查网络设置是否符合预期。容器运行时可以通过CHECK来检查网络设置是否出现错误,当CHECK返回错误时(返回了一个非0状态码),容器运行时可以选择Kill掉容器,通过重新启动来重新获得一个正确的网络配置。
1.4.1.3.4 VERSION
VERSION 操作用于查看插件支持的版本信息。
$ CNI_COMMAND=VERSION /opt/cni/bin/bridge
{"cniVersion":"0.4.0","supportedVersions":["0.1.0","0.2.0","0.3.0","0.3.1","0.4.0"]}1.4.2 网络插件调用方式
1.4.2.1 链式调用
单个CNI插件的职责是单一的,比如bridge插件负责网桥的相关配置, firewall插件负责防火墙相关配置, portmap 插件负责端口映射相关配置。因此,当网络设置比较复杂时,通常需要调用多个插件来完成。CNI支持插件的链式调用,可以将多个插件组合起来,按顺序调用。例如先调用 bridge 插件设置容器IP,将容器网卡与主机网桥连通,再调用portmap插件做容器端口映射。容器运行时可以通过在配置文件设置plugins数组达到链式调用的目的:
{"cniVersion": "0.4.0","name": "dbnet","plugins": [{"type": "bridge",// type (plugin) specific"bridge": "cni0"},"ipam": {"type": "host-local",// ipam specific"subnet": "10.1.0.0/16","gateway": "10.1.0.1"}},{"type": "tuning","sysctl": {"net.core.somaxconn": "500"}}]
}细心的读者会发现,plugins这个字段并没有出现在上文描述的配置文件结构体中。的确,CNI使用了另一个结构体——NetworkConfigList来保存链式调用的配置:
type NetworkConfigList struct {Name stringCNIVersion stringDisableCheck boolPlugins []*NetworkConfig Bytes []byte
}
但CNI插件是不认识这个配置类型的。实际上,在调用CNI插件时,需要将NetworkConfigList转换成对应插件的配置文件格式,再通过标准输入(stdin)传递给CNI插件。例如在上面的示例中,实际上会先使用下面的配置文件调用 bridge 插件:
{"cniVersion": "0.4.0","name": "dbnet","type": "bridge","bridge": "cni0","ipam": {"type": "host-local","subnet": "10.1.0.0/16","gateway": "10.1.0.1"}
}再使用下面的配置文件调用tuning插件:
{"cniVersion": "0.4.0","name": "dbnet","type": "tuning","sysctl": {"net.core.somaxconn": "500"},"prevResult": { // 调用bridge插件的返回结果...}
}需要注意的是,当插件进行链式调用的时候,不仅需要对NetworkConfigList做格式转换,而且需要将前一次插件的返回结果添加到配置文件中(通过prevResult字段),不得不说是一项繁琐而重复的工作。不过幸好libcni 已经为封装好了,容器运行时不需要关心如何转换配置文件,如何填入上一次插件的返回结果,只需要调用 libcni 的相关方法即可。
1.4.2.2 调用案例
1.4.2.2.1 下载CNI插件
为方便起见,直接下载可执行文件:
wget https://github.com/containernetworking/plugins/releases/download/v0.9.1/cni-plugins-linux-amd64-v0.9.1.tgz
mkdir -p ~/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.9.1.tgz -C ./cni/bin
chmod +x ~/cni/bin/*
ls ~/cni/bin/
bandwidth bridge dhcp firewall flannel host-device host-local ipvlan loopback macvlan portmap ptp sbr static tuning vlan vrfz如果是在K8S节点上实验,通常节点上已经有CNI插件了,不需要再下载,但要注意将后续的 CNI_PATH 修改成/opt/cni/bin。
案例一:调用单个插件
在该案例中中,用户只需直接调用CNI插件,为容器设置eth0接口,为其分配IP地址,并接入主机网桥mynet0。
跟docker默认使用的使用网络模式一样,只不过是将docker0换成了mynet0。
1)启动容器
虽然Docker不使用CNI规范,但可以通过指定 --net=none 的方式让Docker不设置容器网络。以nginx镜像为例:
contid=$(docker run -d --net=none --name nginx nginx) # 容器ID
pid=$(docker inspect -f '{{ .State.Pid }}' $contid) # 容器进程ID
netnspath=/proc/$pid/ns/net # 命名空间路径启动容器的同时,我们需要记录一下容器ID,命名空间路径,方便后续传递给CNI插件。容器启动后,可以看到除了lo网卡,容器没有其他的网络设置:
nsenter -t $pid -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forevernsenter是namespace enter的简写,顾名思义,这是一个在某命名空间下执行命令的工具。-t表示进程ID, -n表示进入对应进程的网络命名空间。
2)添加容器网络接口并连接主机网桥
接下来我们使用bridge插件为容器创建网络接口,并连接到主机网桥。创建bridge.json配置文件,内容如下:
{"cniVersion": "0.4.0","name": "mynet","type": "bridge","bridge": "mynet0","isDefaultGateway": true,"forceAddress": false,"ipMasq": true,"hairpinMode": true,"ipam": {"type": "host-local","subnet": "10.10.0.0/16"}
}调用bridge插件ADD操作:
CNI_COMMAND=ADD CNI_CONTAINERID=$contid CNI_NETNS=$netnspath CNI_IFNAME=eth0 CNI_PATH=~/cni/bin ~/cni/bin/bridge < bridge.json调用成功的话,会输出类似的返回值:
{"cniVersion": "0.4.0","interfaces": [....],"ips": [{"version": "4","interface": 2,"address": "10.10.0.2/16", //给容器分配的IP地址"gateway": "10.10.0.1" }],"routes": [.....],"dns": {}
}再次查看容器网络设置:
nsenter -t $pid -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
5: eth0@if40: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group defaultlink/ether c2:8f:ea:1b:7f:85 brd ff:ff:ff:ff:ff:ff link-netnsid 0inet 10.10.0.2/16 brd 10.10.255.255 scope global eth0valid_lft forever preferred_lft forever可以看到容器中已经新增了eth0网络接口,并在ipam插件设定的子网下为其分配了IP地址。host-local类型的 ipam插件会将已分配的IP信息保存到文件,避免IP冲突,默认的保存路径为/var/lib/cni/network/$NETWORK_NAME
3)从主机访问验证
由于mynet0是我们添加的网桥,还未设置路由,因此验证前我们需要先为容器所在的网段添加路由:
ip route add 10.10.0.0/16 dev mynet0 src 10.10.0.1 # 添加路由
curl -I 10.10.0.2 # IP换成实际分配给容器的IP地址
HTTP/1.1 200 OK
....4)删除容器网络接口
删除的调用入参跟添加的入参是一样的,除了CNI_COMMAND要替换成DEL:
CNI_COMMAND=DEL CNI_CONTAINERID=$contid CNI_NETNS=$netnspath CNI_IFNAME=eth0 CNI_PATH=~/cni/bin ~/cni/bin/bridge < bridge.json注意:上述的删除命令并未清理主机的mynet0网桥。如果你希望删除主机网桥,可以执行
ip link delete mynet0 type bridge命令删除。
案例二:链式调用
在案例2中,将在案例1的基础上,使用portmap插件为容器添加端口映射。
1)使用cnitool工具
前面的介绍中,我们知道在链式调用过程中,调用方需要转换配置文件,并需要将上一次插件的返回结果插入到本次插件的配置文件中。这是一项繁琐的工作,而libcni已经将这些过程封装好了,在示例2中,我们将使用基于 libcni的命令行工具cnitool来简化这些操作。
示例2将复用示例1中的容器,因此在开始示例2时,请确保已删除示例1中的网络接口。
通过源码编译或go install来安装cnitool:
go install github.com/containernetworking/cni/cnitool@latest2)配置文件
libcni会读取.conflist后缀的配置文件,我们在当前目录创建portmap.conflist:
{"cniVersion": "0.4.0","name": "portmap","plugins": [{"type": "bridge","bridge": "mynet0","isDefaultGateway": true, "forceAddress": false, "ipMasq": true, "hairpinMode": true,"ipam": {"type": "host-local","subnet": "10.10.0.0/16","gateway": "10.10.0.1"}},{"type": "portmap","runtimeConfig": {"portMappings": [{"hostPort": 8080, "containerPort": 80, "protocol": "tcp"}]}}]
}从上述的配置文件定义了两个CNI插件,bridge和portmap。根据上述的配置文件,cnitool会先为容器添加网络接口并连接到主机mynet0网桥上(就跟示例1一样),然后再调用portmap插件,将容器的80端口映射到主机的8080端口,就跟docker run -p 8080:80 xxx一样。
3)设置容器网络
使用cnitool我们还需要设置两个环境变量:
NETCONFPATH: 指定配置文件(*.conflist)的所在路径,默认路径为 /etc/cni/net.d
CNI_PATH :指定CNI插件的存放路径。
使用cnitool add命令为容器设置网络:
CNI_PATH=~/cni/bin NETCONFPATH=. cnitool add portmap $netnspath设置成功后,访问宿主机8080端口即可访问到容器的nginx服务。
4)删除网络配置
使用cnitool del命令删除容器网络:
CNI_PATH=~/cni/bin NETCONFPATH=. cnitool del portmap $netnspath注意,上述的删除命令并未清理主机的mynet0网桥。如果你希望删除主机网桥,可以执行ip link delete mynet0 type bridge命令删除。
1.5 CNI 使用了哪些网络模型?
CNI 网络插件使用封装网络模型(例如 Virtual Extensible Lan,缩写是 VXLAN)或非封装网络模型(例如 Border Gateway Protocol,缩写是 BGP)来实现网络结构。
1.5.1 什么是封装网络?
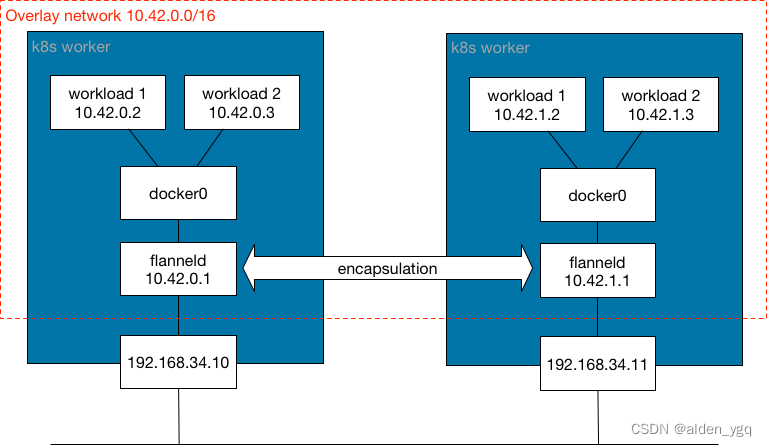
此网络模型提供了一个逻辑二层(L2)网络,该网络封装在跨 Kubernetes 集群节点的现有三层(L3)网络拓扑上。使用此模型,可以为容器提供一个隔离的 L2 网络,而无需分发路由。封装网络带来了少量的处理开销以及由于覆盖封装生成 IP header 造成的 IP 包大小增加。封装信息由 Kubernetes worker 之间的 UDP 端口分发,交换如何访问 MAC 地址的网络控制平面信息。此类网络模型中常用的封装是 VXLAN、Internet 协议安全性 (IPSec) 和 IP-in-IP。简单来说,封装网络模型在 Kubernetes worker 之间生成了一种扩展网桥,其中连接了 pod。
如果用户偏向使用扩展 L2 网桥,则可以选择此网络模型。此网络模型对 Kubernetes worker 的 L3 网络延迟很敏感。如果数据中心位于不同的地理位置,请确保它们之间的延迟较低,以避免最终的网络分段。
使用这种网络模型的 CNI 网络插件包括 Flannel、Canal、Weave 和 Cilium。默认情况下,Calico 不会使用此模型,但用户可以对其进行配置。
1.5.2 什么是非封装网络?
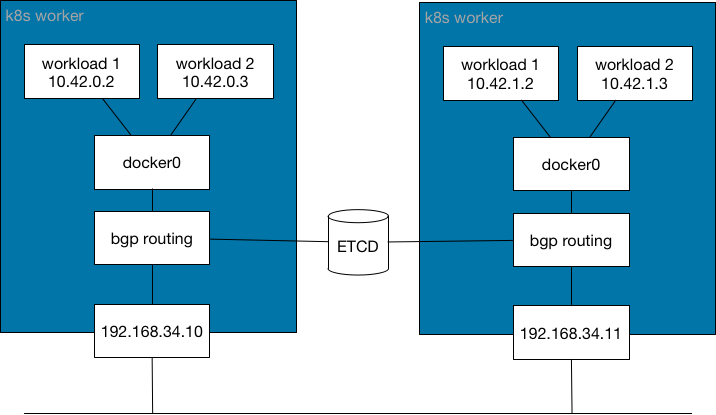
该网络模型提供了一个 L3 网络,用于在容器之间路由数据包。此模型不会生成隔离的 L2 网络,也不会产生开销。这些好处的代价是,Kubernetes worker 必须管理所需的所有路由分发。该网络模型不使用 IP header 进行封装,而是使用 Kubernetes Worker 之间的网络协议来分发路由信息以实现 Pod 连接,例如 BGP。
简而言之,这种网络模型在 Kubernetes worker 之间生成了一种扩展网络路由器,提供了如何连接 Pod 的信息。
如果用户偏向使用 L3 网络,则可以选择此网络模型。此模型在操作系统级别为 Kubernetes Worker 动态更新路由。对延迟较不敏感。
使用这种网络模型的 CNI 网络插件包括 Calico 和 Cilium。Cilium 可以使用此模型进行配置,即使这不是默认模式。
1.6 CNI社区插件
Kubernetes 它需要网络插件来提供集群内部和集群外部的网络通信。以下是一些常用的 k8s 网络插件:
- Flannel:Flannel 是最常用的 k8s 网络插件之一,它使用了虚拟网络技术来实现容器之间的通信,支持多种网络后端,如 VXLAN、UDP 和 Host-GW。
- Calico:Calico 是一种基于 BGP 的网络插件,它使用路由表来路由容器之间的流量,支持多种网络拓扑结构,并提供了安全性和网络策略功能。
- Canal:Canal 是一个组合了 Flannel 和 Calico 的网络插件,它使用 Flannel 来提供容器之间的通信,同时使用 Calico 来提供网络策略和安全性功能。
- Weave Net:Weave Net 是一种轻量级的网络插件,它使用虚拟网络技术来为容器提供 IP 地址,并支持多种网络后端,如 VXLAN、UDP 和 TCP/IP,同时还提供了网络策略和安全性功能。
- Cilium:Cilium 是一种基于 eBPF (Extended Berkeley Packet Filter) 技术的网络插件,它使用 Linux 内核的动态插件来提供网络功能,如路由、负载均衡、安全性和网络策略等。
- Contiv:Contiv 是一种基于 SDN 技术的网络插件,它提供了多种网络功能,如虚拟网络、网络隔离、负载均衡和安全策略等。
- Antrea:Antrea 是一种基于 OVS (Open vSwitch) 技术的网络插件,它提供了容器之间的通信、网络策略和安全性等功能,还支持多种网络拓扑结构。
-
kube-router:kube-router是一个开源的CNI插件,它结合了网络和服务代理功能。它支持BGP和IPIP协议,并具有负载均衡的特性。
| 提供商 | 项目 | Stars | Forks | Contributors |
| Canal | GitHub - projectcalico/canal: Policy based networking for cloud native applications | 679 | 100 | 21 |
| Flannel | GitHub - flannel-io/flannel: flannel is a network fabric for containers, designed for Kubernetes | 7k | 2.5k | 185 |
| Calico | GitHub - projectcalico/calico: Cloud native networking and network security | 3.1k | 741 | 224 |
| Weave | GitHub - weaveworks/weave: Simple, resilient multi-host containers networking and more. | 6.2k | 635 | 84 |
| Cilium | GitHub - cilium/cilium: eBPF-based Networking, Security, and Observability | 10.6k | 1.3k | 352 |
1.7 第三方网络插件的功能
| 插件 | 网络模型 | 路线分发 | 网络策略 | 网络 | 外部数据存储 | 加密 | Ingress/Egress策略 |
| Canal | 封装 (VXLAN) | 否 | 是 | 否 | K8s API | 是 | 是 |
| Flannel | 封装 (VXLAN) | 否 | 否 | 否 | K8s API | 是 | 否 |
| Calico | 封装(VXLAN,IPIP)或未封装 | 是 | 是 | 是 | Etcd 和 K8s API | 是 | 是 |
| Weave | 封装 | 是 | 是 | 是 | 否 | 是 | 是 |
| Cilium | 封装 (VXLAN) | 是 | 是 | 是 | Etcd 和 K8s API | 是 | 是 |
- 网络模型:封装或未封装
- 路由分发:一种外部网关协议,用于在互联网上交换路由和可达性信息。BGP 可以帮助进行跨集群 pod 之间的网络。此功能对于未封装的 CNI 网络插件是必须的,并且通常由 BGP 完成。如果想构建跨网段拆分的集群,路由分发是一个很好的功能。
- 网络策略:Kubernetes 提供了强制执行规则的功能,这些规则决定了哪些 service 可以使用网络策略进行相互通信。这是从 Kubernetes 1.7 起稳定的功能,可以与某些网络插件一起使用。
- 网格:允许在不同的 Kubernetes 集群间进行 service 之间的网络通信。
- 外部数据存储:具有此功能的 CNI 网络插件需要一个外部数据存储来存储数据。
- 加密:允许加密和安全的网络控制和数据平面。
- Ingress/Egress 策略:允许你管理 Kubernetes 和非 Kubernetes 通信的路由控制。
1.8 第三方插件实现方式
CNI 第三方网络插件通常有 3 种实现模式:
-
Overlay:靠隧道打通,不依赖底层网络;
-
Underlay:靠底层网络打通,强依赖底层网络;
-
路由:靠路由打通,部分依赖底层网络;
1.9 CNI 使用的 I/O 接口虚拟化
根据 CNI 插件不同的实现方式,也会使用到不同的 I/O 接口虚拟化技术。
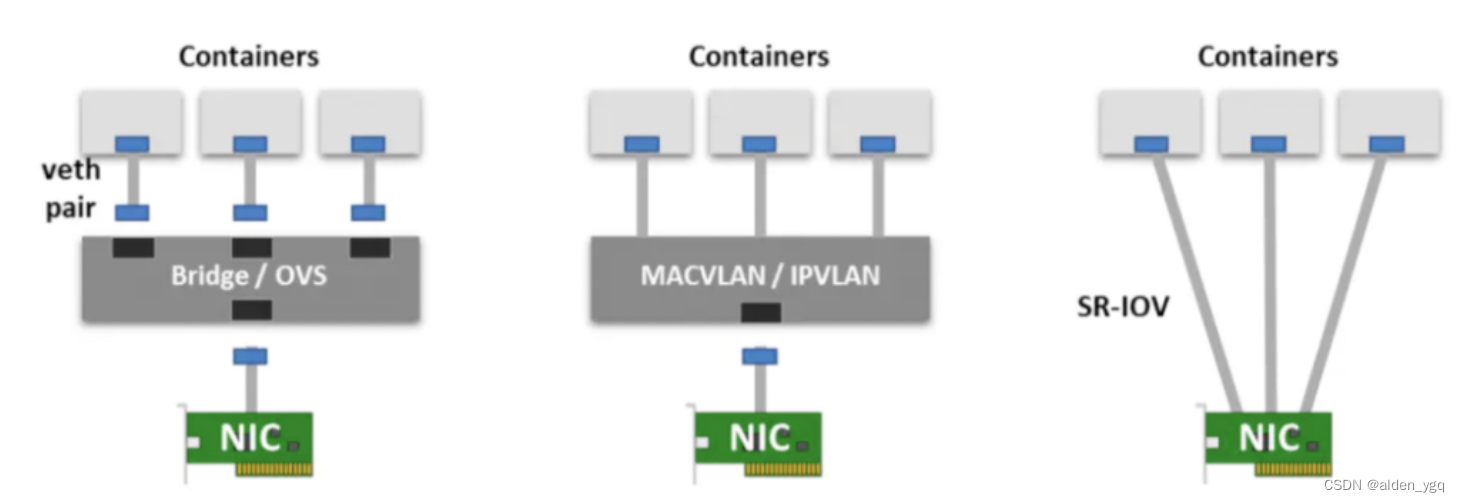
- Veth-Pair:创建一个 Veth-Pair 对,两端分别接入到 Host root namespace(Linux Bridge / Open vSwitch)和 Container network namespace。Container 内发出的网络数据包,通过 vSwitch 进入到 Host OS Kernel Network Stack。
- Multi-Plexing(多路复用):使用一个 MACVLAN / IPVLAN 中间网络设备,虚拟出多个 Virtual NIC 接入到 Container,根据 MAC/IP 地址来区分数据报文如何转发到具体的容器。
- Hardware switching(硬件交换):SR-IOV 内部实现了一个 Hardware Switch,通过 VFs 的方式接入到每个 Pods。
2 k8s 支持哪些 CNI 插件?
RKE 可选择的 CNI 插件集成包括:Canal、Flannel、Calico 和 Weave 。RKE2 可以使用的是 Cillium、Calico、Canal 和 Multus。
2.1 Flannel插件
Flannel是一个在Kubernetes集群中广泛使用的容器网络解决方案,它旨在简化不同节点上容器的通信,并实现容器之间的互联。Flannel通过虚拟网络覆盖技术(overlay network)来连接不同节点上的容器,提供了一种轻量级且易于部署的网络解决方案。
2.1.1 Flannel插件工作原理
Flannel的工作原理如下:
1)节点注册:Kubernetes集群中的每个节点都会注册到etcd(分布式键值存储系统)中,并分配唯一的子网段(Subnet)。
2)路由表管理:Flannel在每个节点上运行一个代理(flanneld),代理负责管理节点之间的路由表。这些路由表信息也存储在etcd中。
3)虚拟网络:Flannel使用overlay network技术创建虚拟网络,该网络覆盖在底层节点网络之上。当容器需要跨节点通信时,Flannel会在节点间创建虚拟网络连接。
4)容器通信:当容器A需要与容器B通信时,数据包会通过虚拟网络连接到达容器B所在的节点,然后通过节点上的flanneld代理转发给容器B。
2.1.2 常见的Flannel后端驱动
Flannel支持多种后端驱动来实现虚拟网络覆盖。以下是一些常见的Flannel后端驱动:
- VXLAN:使用VXLAN封装数据包,实现跨节点的二层通信,是Flannel的默认后端驱动。
- UDP:通过UDP封装数据包,在网络中创建隧道以实现容器间的通信。
- Host-GW:直接使用主机的路由表,将目标IP地址指向目标节点上的容器。
2.1.3 优点& 缺点
2.1.3.1 优点
Flannel的优点包括:
- 简单易用:Flannel的部署相对简单,对Kubernetes集群的配置没有太多要求,因此容易上手和管理。
- 轻量级:Flannel的设计目标是保持轻量级,对底层网络基础设施的要求相对较低。
- 可扩展性:Flannel支持大规模的容器部署,能够适应不断增长的容器数量。
2.1.3.2 缺点
Flannel也有一些局限性:
-
性能:虽然Flannel的性能通常是足够的,但在特定场景下可能会因为overlay网络的额外封装导致一些性能损失。
-
可靠性:Flannel的可靠性取决于底层网络和etcd的稳定性。如果etcd出现问题,可能会影响Flannel的功能。
2.1.4 Pod IP(容器IP)地址分配方法
Flannel在每个主机运行一个代理"flanneld"负责从预置的网络地址空间"10.244.0.0/16"中为每个节点主机分配一个独立的子网"如10.244.0.0/24、10.244.1.0/24...依次类推",每个节点都拥有一个独立子网。Flannel直接通过Kubernetes API 或Etcd来存储网络配置、分配的子网和任何辅助数据(例如主机的公共IP)。
# ps aux |grep flannel |grep -v grep
root 129882 0.1 1.1 1406468 21844 ? Ssl 01:58 0:01 /opt/bin/flanneld --ip-masq --kube-subnet-mgr
# ifconfig
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450inet 10.244.0.1 netmask 255.255.255.0 broadcast 10.244.0.255inet6 fe80::40e6:c0ff:fe73:7322 prefixlen 64 scopeid 0x20<link>ether 42:e6:c0:73:73:22 txqueuelen 1000 (Ethernet)RX packets 2135 bytes 173643 (169.5 KiB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 2144 bytes 221369 (216.1 KiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.124.134 netmask 255.255.255.0 broadcast 192.168.124.255ether 00:0c:29:40:e3:9f txqueuelen 1000 (Ethernet)RX packets 21776361 bytes 3312500382 (3.0 GiB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 21943903 bytes 3680963238 (3.4 GiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0inet6 fe80::743d:5cff:febf:9d75 prefixlen 64 scopeid 0x20<link>ether 76:3d:5c:bf:9d:75 txqueuelen 0 (Ethernet)RX packets 0 bytes 0 (0.0 B)RX errors 0 dropped 0 overruns 0 frame 0TX packets 0 bytes 0 (0.0 B)TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0....veth5af012c2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450inet6 fe80::7c96:79ff:feb5:e5d1 prefixlen 64 scopeid 0x20<link>ether 7e:96:79:b5:e5:d1 txqueuelen 0 (Ethernet)RX packets 1071 bytes 102134 (99.7 KiB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 1091 bytes 112057 (109.4 KiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0veth72fc4936: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450inet6 fe80::f44a:83ff:fe6b:e926 prefixlen 64 scopeid 0x20<link>ether f6:4a:83:6b:e9:26 txqueuelen 0 (Ethernet)RX packets 1064 bytes 101399 (99.0 KiB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 1072 bytes 110626 (108.0 KiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Flannel会在每个创建的Pod从子网中"10.244.0.0/24"分配一个集群中全局唯一的PodIP,每个主机上创建一个名为"cni|cbr0"的拥有IP地址"10.244.0.1"的虚拟网卡(地址在全局唯一)作为Pod的网关,
用于跨主机Pod间网络通信。如下图所示: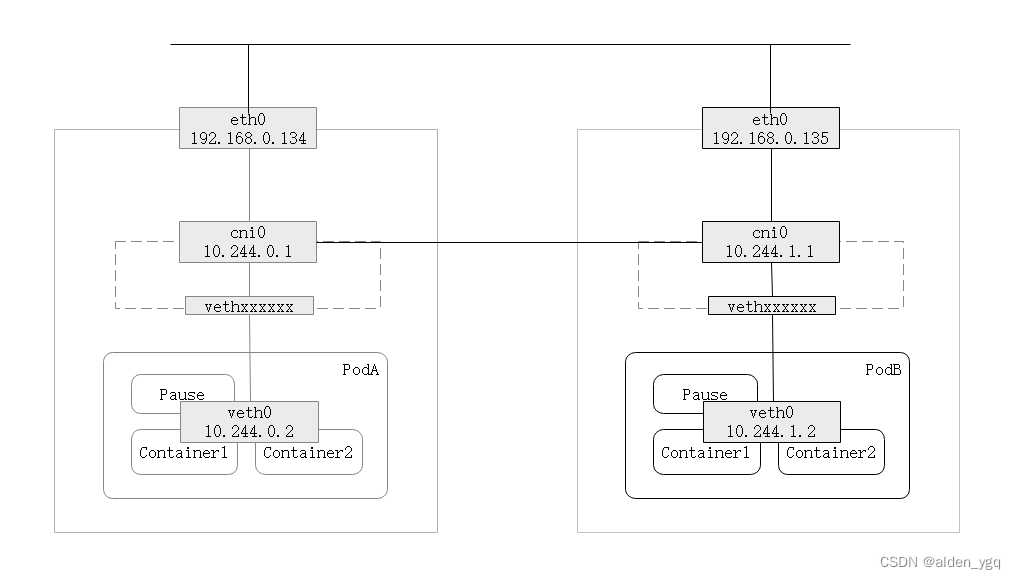
2.1.5 跨主机Pod网络通信实现方法
Flannel支持多种跨主机间Pod通信处理方法(backend mechanisms,又称之为后端机制)。
2.1.5.1 HOST-GW
host-gw,Host GateWay,主机网关,在节点主机上创建到达目标Pod地址的路由直接完成报文转发。
该模式仅适用于物理主机在同一个局域网中,在跨网段的物理主机网络中,需要在跨网段的路由设备上手动添加静态路由,随着路由的跳数会增加路由条目的数量,增加复杂度。
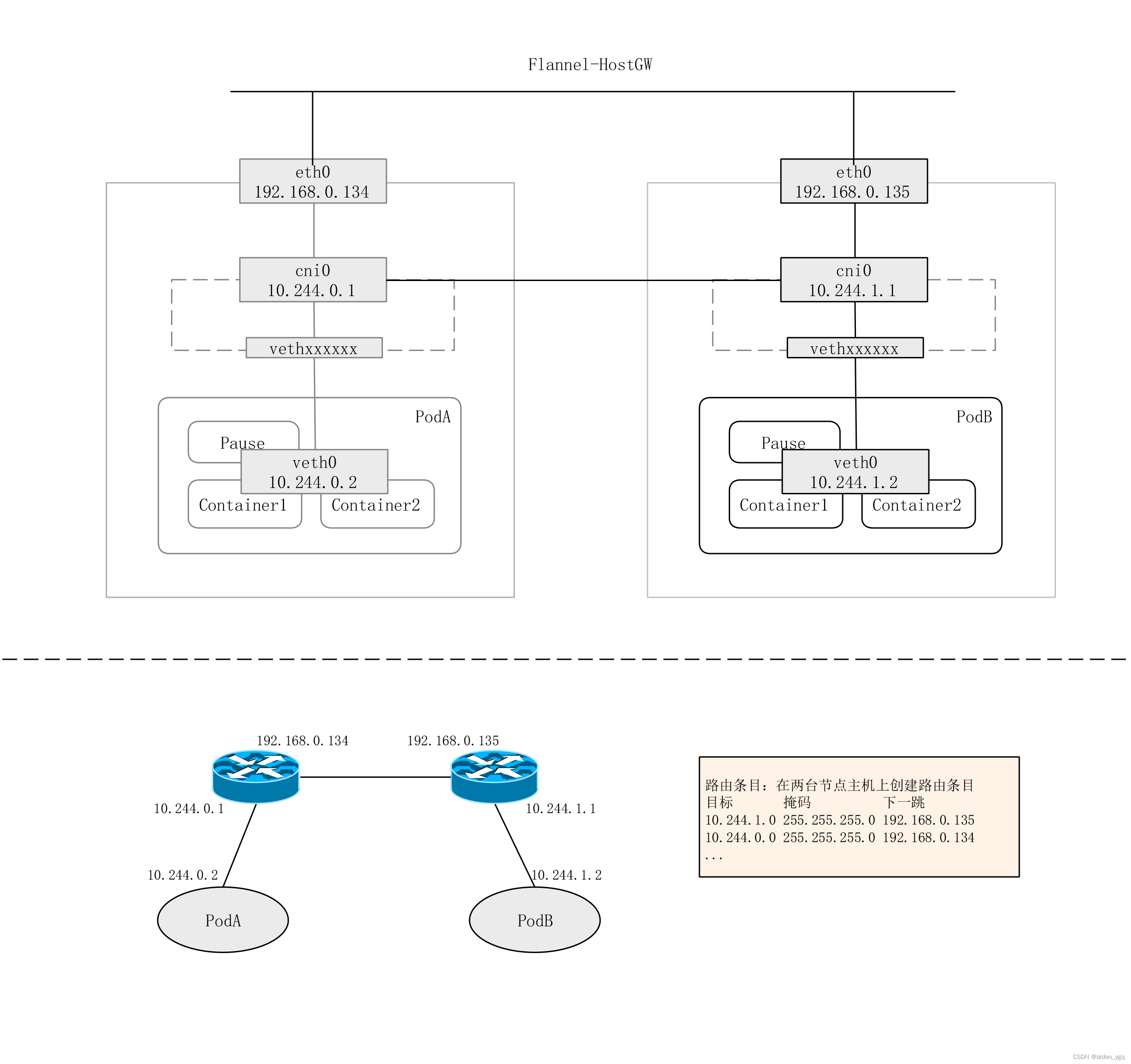
2.1.5.2 VXLAN
VxLAN(默认),VxLAN,Virtual extensible Local Area Network,虚拟可扩展局域网。Flannel使用Linux内核的VxLAN模块将虚拟网络数据包信息封装到物理网络的报文中,然后通过物理网络传输报文,类似于VPN隧道封装技术。这将会在所有节点主机上创建一个名叫"flannel.1"的虚拟网卡用于VxLAN报文的封装和解封装工作,Flannel会将这个网卡的MAC和IP相关信息记录到Etcd。
VxLAN有两种跨主机通信机制:
- VxLAN Default:默认机制
- VxLAN DirectRouting:使用直接路由的方式通信,类似于host-gw,当主机在同一个子网时则通过静态路由的方式直接将Pod网络报文转发到其他主机上,如果主机在不同子网中时则采用默认的VxLAN通信方式。在配置参数中使用"DirectRouting:true"即可。
2.1.5.2.1 VxLAN Default
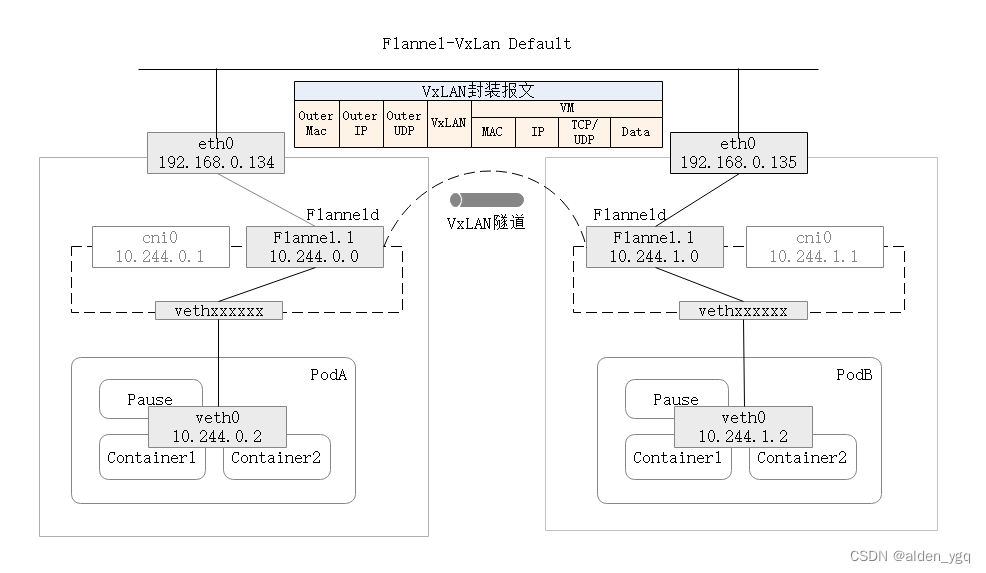
2.1.5.2.2 VxLAN Default
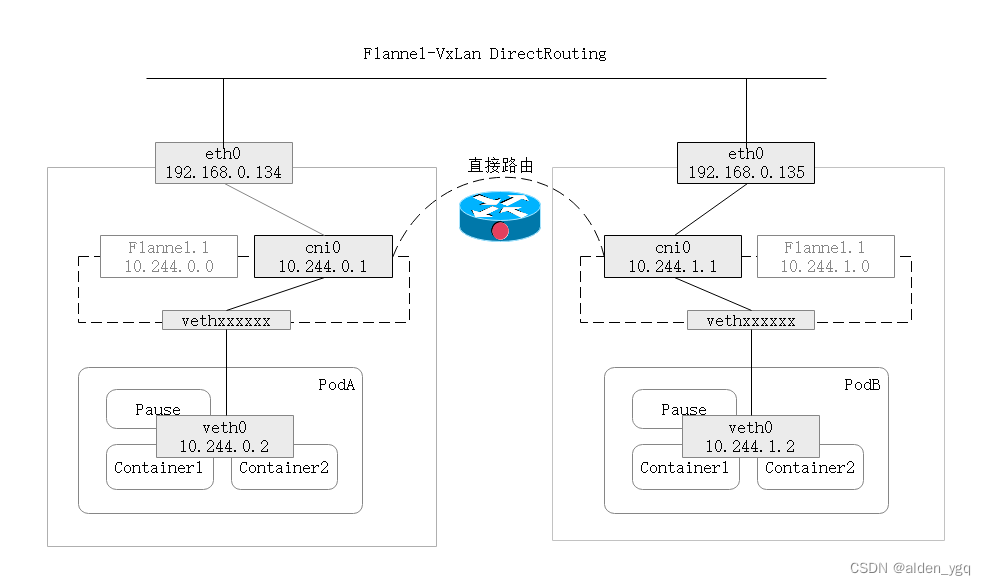
2.1.5.3 UDP
UDP,使用普通的UDP报文封装成隧道转发,工作原理等同于VxLAN,只不过封装的报文为UDP报文。仅用于调试,当前面两种模式不适用时,则可以使用该通信方式(早期的Linux内核不支持VxLAN)。该模式性能与前两种对比较低。
2.1.6 使用步骤
1)安装Flannel:Flannel通常作为Kubernetes集群的网络插件之一安装。可以使用kubectl命令行工具或Kubernetes配置文件来部署Flannel。安装过程可能因Kubernetes版本和部署方式而有所不同,请参考Flannel的官方文档或相关文档进行安装配置。
2)配置etcd:Flannel使用etcd(分布式键值存储系统)来存储节点注册信息和路由表信息。因此,在部署Flannel之前,确保已经正确设置并运行etcd集群。
3)配置Flannel:在Kubernetes集群的每个节点上,需要配置Flannel代理(flanneld)。Flannel代理使用etcd中的子网段信息来为每个节点分配唯一的子网段。这样,每个节点都知道如何与其他节点上的容器通信。
4)选择后端驱动:Flannel支持多种后端驱动来实现overlay网络。VXLAN是默认的后端驱动,但你可以根据需求选择其他驱动,如UDP、Host-GW等。后端驱动的选择可能会影响性能和网络拓扑,请根据实际情况进行选择。
5)验证网络:安装完成后,可以使用kubectl命令或其他网络测试工具验证Flannel网络是否正常工作。确保容器可以跨节点通信,并且网络连接是稳定可靠的。
6)网络策略:在Flannel中,默认情况下,所有容器之间都是互通的。如果你需要更精细的网络控制,你可以使用Kubernetes的网络策略(Network Policy)功能来实现容器之间的访问控制。
注意:Flannel是一种简单的网络解决方案,适用于大多数基本的Kubernetes网络需求。然而,如果业务场景对网络性能和安全性有更高的要求,可能需要考虑其他高级网络解决方案,如Calico、Cilium等。
2.1.7 Flannel配置详解
参考文档:https://github.com/flannel-io/flannel/blob/master/Documentation/backends.md
通过flannel.yaml清单文件可以看到flannel的配置信息保存到了ConfigMap/kube-flannel-cfg中名叫net-conf.json的文件。
用户可以通过修改相关配置来修改Flannel的工作模式和相关参数。
kind: ConfigMap
apiVersion: v1
metadata:name: kube-flannel-cfgnamespace: kube-systemlabels:tier: nodeapp: flannel
data:cni-conf.json: |{ "name": "cbr0","cniVersion": "0.3.1","plugins": [{ "type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}},{"type": "portmap","capabilities": {"portMappings": true}}]}net-conf.json: |{"Network": "10.244.0.0/16","Backend": {"Type": "vxlan"}}
2.1.7.1 配置Flannel工作模式为VXLAN相关配置项
VxLAN,Virtual extensible Local Area Network,虚拟可扩展局域网。
-
Type(string): vxlan,设置Flannel工作模式为"vxlan"。
-
VNI(number):设置要使用的VXLAN标识符(VNI)。在Linux中默认值为1。 在Windows上应该大于或等于4096。
-
Port(number):用于发送封装数据包的 UDP 端口。 在Linux上,默认值为内核默认值,目前为8472,但在Windows上,必须为4789。
-
GBP(Boolean):Group Based Policy,启用基于VXLAN组的策略。默认为false。Windows不支持GBP。
-
DirectRouting(Boolean):直接路由的意思,当主机位于同一个局域网时,则采用静态路由的方式进行Pod间通信,类似于host-gw的工作方式。当主机在不同的子网中时,则采用Vxlan隧道方式通信。该配置默认值为false。Windows不支持该功能。
-
MacPrefix(String):仅用于Windows,设置Mac前缀。默认为OE-2A。
2.1.7.2 配置Flannel工作模式为HOST-GW相关配置项
Host GateWay,主机网关。
Type(string): host-gw,设置Flannel工作模式为"host-gw"。
2.1.7.3 配置Flannel工作模式为UDP相关配置项
仅当主机不支持VxLAN和host-gw模式的时候才建议使用该模式。
Type(string): udp,设置Flannel工作模式为"udp"。
Port(number):设置发送封装数据包要使用的UDP端口。默认为8285.
2.1.8 安装Flannel网络插件
参考文档:GitHub - flannel-io/flannel: flannel is a network fabric for containers, designed for Kubernetes
当前主机环境:
- 主机系统版本:CentOS Linux release 7.6.1810 (Core)
- Kubernetes版本:v1.23.0
安装要求:无
2.1.8.1 下载清单文件
Kubernetes v1.17+:
[root@k8s-master01 ~]# wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml -O flannel.yml
Kubernetes v1.6~v1.15:
[root@k8s-master01 ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/k8s-manifests/kube-flannel-legacy.yml -O flannel-legacy.yml2.1.8.2 配置Flannel
Flannel默认使用的Pod子网(CIDR)是"10.244.0.0/16",如果你在初始化集群的时候设置的Pod子网为其他网段,则这边需要修改为相同的子网。
Flannel默认使用的后端机制为VXLAN。配置后端可以参考"https://github.com/flannel-io/flannel/blob/master/Documentation/backends.md"文档。
[root@k8s-master01 ~]# vim flannel.yml
...
kind: ConfigMap
apiVersion: v1
metadata:name: kube-flannel-cfgnamespace: kube-systemlabels:tier: nodeapp: flannel
data:cni-conf.json: |{"name": "cbr0","cniVersion": "0.3.1","type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}}net-conf.json: |{"Network": "10.244.0.0/16","Backend": {"Type": "vxlan"}}
...
2.1.8.3 使用清单文件安装Flannel
[root@k8s-master01 ~]# kubectl apply -f flannel.yaml2.1.9 Flannel使用注意事项
- 子网段选择:Flannel 默认使用 10.244.0.0/16 作为容器网络的子网段。如果集群网络已经使用了该子网段或其他冲突的子网段,需要在 Flannel 配置中明确指定不同的子网段,以避免冲突。
# flannel-config.yamlapiVersion: v1
kind: ConfigMap
metadata:name: kube-flannel-cfgnamespace: kube-system
data:cni-conf.json: |{"cniVersion": "0.3.1","name": "cbr0","type": "flannel","delegate": {"forceAddress": false,"isDefaultGateway": true}}net-conf.json: |{"Network": "192.168.0.0/16", # 替换为你想要的子网段"Backend": {"Type": "vxlan"}}-
容器网络策略:默认情况下,Flannel 允许集群中的所有容器互相通信,没有访问控制。如果需要在容器之间实现细粒度的访问控制,你可以使用 Kubernetes 的网络策略(Network Policy)功能。
-
多网络插件支持:在一些复杂场景下,可能需要同时使用多个网络插件,例如 Calico 和 Flannel 结合使用。在这种情况下,你需要确保它们能够协同工作,并避免冲突。
-
高可用性和故障恢复:Flannel 可能会受到底层网络和 etcd 的影响,因此在生产环境中需要确保高可用性和故障恢复机制,以保证网络的稳定性。
2.1.10 完全卸载Flannel网络插件
想要完全的从主机上移除Flannel,除了需要删除已运行的Pod之外,还需要删除主机中相关的创建虚拟网卡设备和相关CNI配置文件。
2.1.10.1 基于安装清单删除Flannel创建的资源对象
在任一Master节点上操作:
[root@k8s-master01 ~]# kubectl delete -f flannel.yml
2.1.10.2 移除虚拟网卡
在所有主机上操作:
[root@k8s-master01 ~]# ifconfig cni0 down
[root@k8s-master01 ~]# ip link delete cni0
[root@k8s-master01 ~]# ifconfig flannel.1 down
[root@k8s-master01 ~]# ip link delete flannel.1
2.1.10.3 删除Flannel相关CNI配置文件
[root@k8s-master01 ~]# rm -rf /var/lib/cni/
[root@k8s-master01 ~]# rm -rf /etc/cni/net.d/*
2.1.10.4 重启kubelet服务
[root@k8s-master01 ~]# systemctl restart kubelet
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady control-plane,master 3h56m v1.23.0
k8s-master02 NotReady control-plane,master 3h55m v1.23.0
k8s-master03 NotReady control-plane,master 3h55m v1.23.0
k8s-node01 NotReady <none> 3h52m v1.23.02.2 Calico插件
2.2.1 概述
参考文档:Calico Documentation | Calico Documentation
Calico是一款广泛采用、久经考验的开源网络和网络安全解决方案,适用于Kubernetes、虚拟机和裸机工作负载。与Flannel对比,Calico除了支持基本网络功能的实现之外,它还支持全套Kubernetes网络策略功能,以及在其之上扩展网络策略。
2.2.2 Calico组件
Calico主要由以下组件组成:
-
CNI Plugin
-
Calico Node
-
Calico Controller
-
Calico Typha(可选的扩展组件)
2.2.2.1 CNI Plugin
CNI网络插件,Calico通过CNI网络插件与kubelet关联,从而实现Pod网络
2.2.2.2 Calico Node
Calico节点代理是运行在每个节点上的代理程序,负责管理节点路由信息、策略规则和创建Calico虚拟网络设备。
Calico Node主要由以下子模块程序组成:
- Felix,Calico代理程序。运行在每个节点上的守护进程,它主要负责管理节点上网络接口、为节点创建路由信息和ACL规则、以及报告当前节点网络的健康状态给控制器等工作。
- BIRD-BGP客户端,BIRD是一个项目的简称,全称为BIRD Internet Routing Daemon,BIRD是一个类UNIX系统下旨在开发一个功能齐全的IP路由守护进程,它是一个路由软件,可以实现多种路由协议,如BGP、OSPF、RIP等。在Calico中,BIRD是一个BGP客户端,用于使用BGP协议广播给其他主机动态的学习路由规则。更多了解BIRD可参考:https://bird.network.cz/。
- BIRD-Route Reflector(可扩展的组件),BGP客户端在每个节点上运行,其随着节点数量越来越多,一个BGP客户端需要连接更多数量的其他BGP客户端,其网络连接的数量非常多且网络会变得复杂。在节点之外,允许将BIRD程序配置成"Route Reflector"路由反射器工作方式,BGP客户端可以直接连接到"Route Reflector"路由反射器,而不是很多数量的其他BGP客户端,从而减少网络连接的数量,以提高BGP网络的性能。
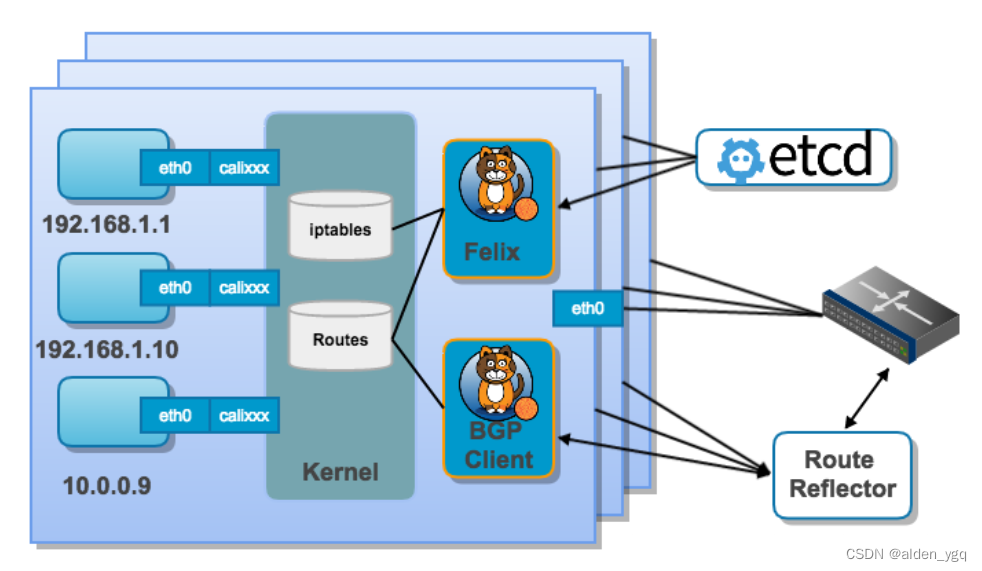
2.2.2.3 Calico Controller
Calico网络策略控制器。允许创建"NetworkPolicy"资源对象,并根据资源对象里面对网络策略定义,在对应节点主机上创建针对于Pod流出或流入流量的IPtables规则。
2.2.2.4 Calico Typha(可选的扩展组件)
Typha是Calico的一个扩展组件,用于Calico通过Typha直接与Etcd通信,而不是通过kube-apiserver。通常当K8S的规模超过50个节点的时候推荐启用它,以降低kube-apiserver的负载。每个Pod/calico-typha可承载100~200个Calico节点的连接请求,最多不要超过200个。
2.2.3 Calico网络实现
Calico支持两种类型网络工作模式(后端机制):
- 如果物理主机在同一2层网络中,则建议采用使用BGP动态路由通信方式;
- 如果物理主机是跨子网通信的话,可能由于到达目标主机的跳数太多导致性能下降,所以建议使用覆盖网络模式。
2.2.3.1 动态路由模式(dynamic routing)
采用BGP动态路由协议自动学习来自其他AS自治系统上的路由条目,即其他节点主机上的路由条目。
类似于Flannel的Host-GW模式,不过它没有不能跨子网的限制。
想要更多了解BGP动态路由技术,可以参考其他网络资料,这里就不过多的阐述了。
2.2.3.2 覆盖网络模式(overlay network)
采用IPIP或VXLAN协议封装底层网络,然后通过上层物理覆盖网络通信。
将底层的Pod网络源目IP+数据封装到上层物理网络源目IP的数据包中,由同一个网络的物理主机通过直连路由完成数据包的传输和解封装,以实现底层Pod网络通信。
Calico对于覆盖网络的工作模式有:
- IPIP,使用IPIP封装协议。当IPIP启用的时候不允许启用VXLAN。
- VXLAN,使用VXLAN封装协议。当VXLAN启用的时候不允许启用IPIP。
- IPIPCrossSubnet,当物理主机是跨子网的情况下才使用IPIP覆盖网络通信方式,正常情况下使用BGP路由模式。
- VXLANCrossSubnet,当物理主机是跨子网的情况下才使用VXLAN覆盖网络通信方式,正常情况下使用BGP路由模式。
- None,不使用IPIP或VXLAN覆盖网络模式。
IPIP比VxLAN的数据包头更小,但安全性较差。
虚接口:IPIP默认创建的三层虚接口通常叫"tunl0",而VXLAN默认创建的三层虚接口叫"vxlan.calico"。三层虚接口通常负责数据包的封装和解封装工作。
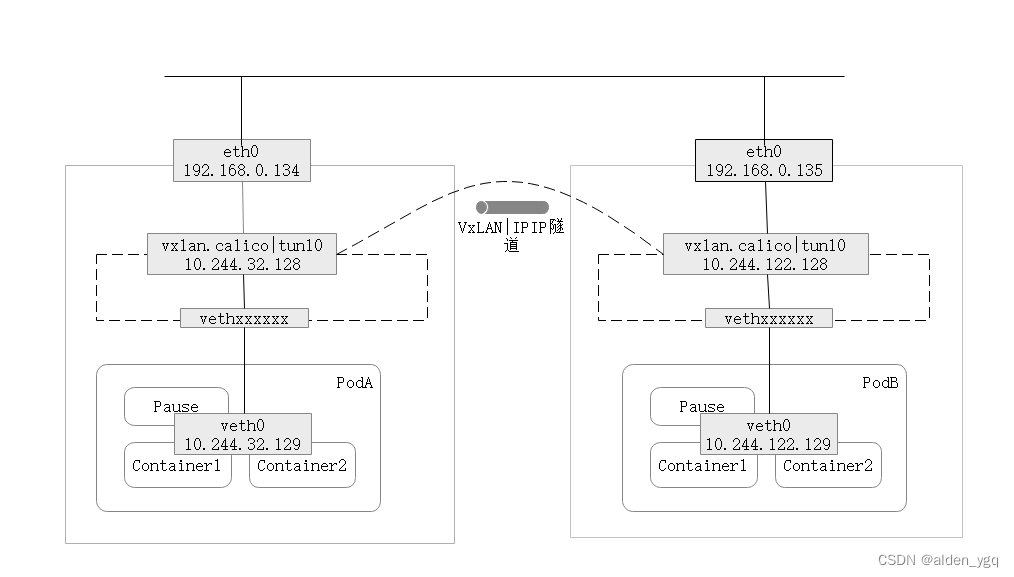
2.2.4 Calico对CIDR子网的划分
CIDR,Classless Inter-Domain Routing,无类别域间路由,在Kubernetes中指基于CIDR的网络划分方案,为Pod分配的子网范围(如:10.244.0.0/12)。
通常默认情况下,PodIP地址范围(--pod-network-cidr)为10.244.0.0/16,它拥有16^2=256*256=65536个地址(包括网络地址+广播地址)可拆分成独立子网。
Calico为每个节点都会创建一个独立子网,即从CIDR大的地址池中划分较小范围的地址池给到每个节点。
Calico可以通过修改配置blockSize块大小来设置每个节点分配的独立子网的范围池大小。这边默认值IPV4=26,IPV6=122。
二进制掩码26(11111111 11111111 11111111 11000000)转换成十进制掩码即=255.255.255.192,即每个节点的子网可以有64个IP地址,减去广播地址和网络地址,可为Pod分配的有效IP地址有62个。
2.2.5 Calico网络策略
Calico使用IPtables实现网络策略功能,在Kubernetes中可以创建"NetworkPolicy"资源对象传给Calico的控制器,由Calico Node根据NetworkPolicy定义的规则在相关节点上创建对应的IPtables规则,以实现对Pod出入口网络流量的安全策略限制。
2.2.6 安装Calico
Calico有两种安装方式:
- 使用calico.yaml清单文件安装
- 使用Tigera Calico Operator安装Calico(官方最新指导)
Tigera Calico Operator,Calico操作员是一款用于管理Calico安装、升级的管理工具,它用于管理Calico的安装生命周期。从Calico-v3.15版本官方开始使用此工具。
Calico安装要求:
- x86-64, arm64, ppc64le, or s390x processor
- 2个CPU
- 2GB运行内存
- 10GB硬盘空间
- RedHat Enterprise Linux 7.x+, CentOS 7.x+, Ubuntu 16.04+, or Debian 9.x+
- 确保Calico可以管理主机上的cali和tunl接口。
2.2.6.1 使用calico.yaml清单文件安装Calico
参考文档:Quickstart for Calico on Kubernetes
当前主机环境:
- 主机系统:CentOS Linux release 7.6.1810 (Core)
- Kubernetes版本:v1.23.0
Calico版本:v3.23.0
其他提示:默认的calico.yaml清单文件无需手动配置Pod子网范围(如果需要,可通过CALICO_IPV4POOL_CIDR指定),默认使用kube-controller-manager的"--cluster-cidr"启动项的值,即kubeadm init时指定的"--pod-network-cidr"或清单文件中使用"podSubnet"的值。
2.2.6.1.1 安装
2.2.6.1.1.1 配置Docker镜像加速
镜像加速由阿里云"容器加速器"提供。
由于安装清单中所使用的镜像来源于国外站点,所以需要配置为国内镜像源才能正常下载镜像到国内主机。
创建配置文件"/etc/docker/daemon.json",并写入以下内容:
# mkdir -p /etc/docker
# cat /etc/docker/daemon.json <<EOF
{"registry-mirrors": ["https://7mimmp7p.mirror.aliyuncs.com","https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn"],"exec-opts": ["native.cgroupdriver=systemd"],"log-driver": "json-file","log-opts": {"max-size": "100m"},"storage-driver": "overlay2","storage-opts": ["overlay2.override_kernel_check=true"]
}
EOF
重启docker服务即可:
# sudo systemctl daemon-reload
# sudo systemctl restart docker2.2.6.1.1.2 配置NetworkManager
如果主机系统使用NetworkManager来管理网络的话,则需要配置NetworkManager,以允许Calico管理接口。
NetworkManger操作默认网络命名空间接口的路由表,这可能会干扰Calico代理正确路由的能力。
在所有主机上操作:
# cat > /etc/NetworkManager/conf.d/calico.conf <<EOF
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*;interface-name:vxlan.calico;interface-name:wireguard.cali
EOF
2.2.6.1.1.3 下载calico.yaml
# wget https://docs.projectcalico.org/v3.23/manifests/calico.yaml --no-check-certificate
2.2.6.1.1.4 修改calico.yaml
由于默认的Calico清单文件中所使用的镜像来源于docker.io国外镜像源,上面配置了Docker镜像加速,应删除docker.io前缀以使镜像从国内镜像加速站点下载。
# cat calico.yaml |grep 'image:'image: docker.io/calico/cni:v3.23.0image: docker.io/calico/cni:v3.23.0image: docker.io/calico/node:v3.23.0image: docker.io/calico/kube-controllers:v3.23.0
# sed -i 's#docker.io/##g' calico.yaml
# cat calico.yaml |grep 'image:'image: calico/cni:v3.23.0image: calico/cni:v3.23.0image: calico/node:v3.23.0image: calico/kube-controllers:v3.23.0
2.2.6.1.1.5 应用calico.yaml
# kubectl apply -f calico.yaml
Pod-Calico在"kube-system"名称空间下创建并运行起来:
# kubectl get pod -n kube-system |grep calico
calico-kube-controllers-77d9858799-c267f 1/1 Running 0 92s
calico-node-6jw5q 1/1 Running 0 92s
calico-node-krrn6 1/1 Running 0 92s
calico-node-mgk2g 1/1 Running 0 92s
calico-node-wr2pv 1/1 Running 0 92s2.2.6.1.2 Calico清单详解-calico.yaml
参考文档:Customize the manifests
calico.yaml清单文件主要用于运行calico-node和calico-kube-controllers服务,其清单安装以下Kubernetes资源:
- 使用DaemonSet在每个主机上安装calico/node容器;
- 使用DaemonSet在每个主机上安装Calico CNI二进制文件和网络配置;
- 使用Deployment运行calico/kube-controller;
- Secert/calico-etcd-secrets提供可选的Calico连接到etcd的TLS密钥信息;
- ConfigMap/calico-config提供安装Calico时的配置参数。
在calico.yaml清单文件中,Calico默认的工作模式是IPIP。
在安装Calico之前配置Calico通常有以下项:
2.2.6.1.2.1.配置PodIP范围(PodCIDR)
要更改用于Pod的默认IP范围,请修改calico.yaml清单文件中"CALICO_IPV4POOL_CIDR"部分。
kind: DaemonSet
apiVersion: apps/v1
metadata:name: calico-nodenamespace: kube-systemlabels:k8s-app: calico-node
spec:template:spec:containers:- name: calico-nodeimage: calico/node:v3.14.2env:...# - name: CALICO_IPV4POOL_CIDR# value: "192.168.0.0/16"...
CALICO_IPV4POOL_CIDR参数用来设置PodIP范围。用于设置安装Calico时要创建的默认IPv4池,PodIP将从该范围中选择。
此配置参数需要在Calico安装前完成修改,完成后修改此值将再无效。
- 默认情况下calico.yaml中"CALICO_IPV4POOL_CIDR"是注释的,如果kube-controller-manager的"--cluster-cidr"不存在任何值的话,则通常取默认值"192.168.0.0/16,172.16.0.0/16,..,172.31.0.0/16"。
- 当使用kubeadm时,PodIP的范围应该与kubeadm init的清单文件中的"podSubnet"字段或者"--pod-network-cidr"选项填写的值相同。
2.2.6.1.2.2 配置IPIP(默认)
默认情况下,calico.yaml清单启用跨子网所使用的封装协议是IPIP。
当集群的节点都处于同一个2层网络中时,我们期望修改Calico的工作模式为BGP或其他时,可以设置"CALICO_IPV4POOL_IPIP"的"value: Never"以禁用IPIP。默认IPIP是启用的"value: Always"。
kind: DaemonSet
apiVersion: apps/v1
metadata:name: calico-nodenamespace: kube-systemlabels:k8s-app: calico-node
spec:template:spec:containers:- name: calico-nodeimage: calico/node:v3.14.2env:...# Enable IPIP- name: CALICO_IPV4POOL_IPIPvalue: "Always"...
CALICO_IPV4POOL_IPIP参数用来设置Calico覆盖网络IPV4池所要使用的封装协议为IPIP。
可设置的值:
- Always,永久启用。
- CrossSubnet,当物理主机是跨子网通信的话才启用,如果物理主机在同一2层网络中则使用BGP动态路由通信方式。
- Never,从不启用,即禁用。
如果该项的值设置为"Never"以外的值,则不应设置"CALICO_IPV4POOL_VXLAN"。
Calico覆盖网络支持IPIP、VXLAN两种协议,仅能启用其中一种。
VXLAN协议禁止启用由"CALICO_IPV4POOL_VXLAN"项控制。
2.2.6.1.2.3 切换IPIP为VXLAN
默认情况下,Calico清单启用IPIP封装。如果期望Calico使用VXLAN封装模式,则需要在安装时候做以下操作:
1)将"CALICO_IPV4POOL_IPIP "设置为"Never",将"CALICO_IPV4POOL_VXLAN"设置为"Always".
kind: DaemonSet
apiVersion: apps/v1
metadata:name: calico-nodenamespace: kube-systemlabels:k8s-app: calico-node
spec:template:spec:containers:- name: calico-nodeimage: calico/node:v3.14.2env:...# Enable IPIP- name: CALICO_IPV4POOL_IPIPvalue: "Never"- name: CALICO_IPV4POOL_VXLANvalue: "Always"...
2)如果只想集群仅使用基于VXLAN协议的覆盖网络模式,用不到BGP动态路由模式的话,即为了节省一点资源,可以选择完全禁用Calico基于BGP的网络:
- 将"calico_backend: "bird""修改为"calico_backend: "vxlan"",这将禁用BIRD。
- 从calico/node的readiness/liveness检查中去掉"- -bird-ready"和"- -bird-live"。
livenessProbe:exec:command:- /bin/calico-node- -felix-live# - -bird-livereadinessProbe:exec:command:- /bin/calico-node# - -bird-ready- -felix-ready
CALICO_IPV4POOL_VXLAN参数用于设置Calico覆盖网络IPV4池所要使用的封装协议为VXLAN。
可设置的值:
- Always,永久启用。
- CrossSubnet,当物理主机是跨子网通信的话才启用,如果物理主机在同一2层网络中则使用BGP动态路由通信方式。
- Never,从不启用,即禁用。
如果该项的值设置为"Never"以外的值,则不应设置"CALICO_IPV4POOL_VXLAN"。
Calico覆盖网络支持IPIP、VXLAN两种协议,仅能启用其中一种。
VXLAN协议禁止启用由"CALICO_IPV4POOL_VXLAN"项控制。
2.2.6.1.2.4 其他配置项
在清单文件的开始有ConfigMap描述Calico的配置内容,其重要的配置项解读如下:
kind: ConfigMap
apiVersion: v1
metadata:name: calico-confignamespace: kube-system
data:typha_service_name: "none"calico_backend: "bird"veth_mtu: "1440"cni_network_config: |-{"name": "k8s-pod-network","cniVersion": "0.3.1","plugins": [{"type": "calico","log_level": "info","datastore_type": "kubernetes","nodename": "__KUBERNETES_NODE_NAME__","mtu": __CNI_MTU__,"ipam": {"type": "calico-ipam"},"policy": {"type": "k8s"},"kubernetes": {"kubeconfig": "__KUBECONFIG_FILEPATH__"}},{"type": "portmap","snat": true,"capabilities": {"portMappings": true}},{"type": "bandwidth","capabilities": {"bandwidth": true}}]}
- typha_service_name: "none",Typha是Calico的一个扩展组件,用于Calico通过Typha直接与Etcd通信,而不是通过kube-apiserver。通常当K8S的规模超过50个节点的时候推荐启用它,以降低kube-apiserver的负载。支持值:
- none,关闭Typha功能。
- calico_typha,启用Typha功能。
- calico_backend: "bird",用于设置Calico使用的后端机制。支持值:
- bird,开启BIRD功能,根据Calico-Node的配置来决定主机的网络实现是采用BGP路由模式还是IPIP、VXLAN覆盖网络模式。
- vxlan,纯VXLAN模式,仅能够使用VXLAN协议的覆盖网络模式。
- veth_mtu: "0",用于设置虚拟接口"calicoxxxxx"的MTU值,默认情况下MTU是自动检测的,不需要显示的设置此字段。可以通过提供一个非零值来设置它。MTU(Maximum Transmission Unit)最大传输单元,网络设备一次发送数据包大小,单位为Byte,MTU值约小则传输速率约高,此值应由系统设置的最合理的值,通常不需要手动设置,最大值为1500。
- cni_network_config,在每个节点上都要安装的CNI网络插件配置。保持默认就好。
2.2.6.2 使用Tigera Calico Operator安装Calico
这种是官方文档最新指导的安装方式。
Tigera Calico Operator通常会安装最新版本的Calico版本,并使用最新的功能。
2.2.6.2.1 安装
2.2.6.2.1.1 配置NetworkManager
如果主机系统使用NetworkManager来管理网络的话,则需要配置NetworkManager,以允许Calico管理接口。
NetworkManger操作默认网络命名空间接口的路由表,这可能会干扰Calico代理正确路由的能力。
在所有主机上操作:
# cat > /etc/NetworkManager/conf.d/calico.conf <<EOF
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*;interface-name:vxlan.calico;interface-name:wireguard.cali
EOF
2.2.6.2.1.2 使用tigera-operator.yaml清单文件安装Tigera Calico operator
参考文档:GitHub - tigera/operator: Kubernetes operator for installing Calico and Calico Enterprise
tigera-operator.yaml清单文件用于安装Tigera Calico operator。
operator的镜像来源于quay.io。
# wget https://projectcalico.docs.tigera.io/manifests/tigera-operator.yaml -O calico-tigera-operator.yaml --no-check-certificate
# cat calico-tigera-operator.yaml |grep 'image:'image: quay.io/tigera/operator:v1.27.0
# kubectl apply -f calico-tigera-operator.yaml
# kubectl get pod -n tigera-operator -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tigera-operator-566769dc67-mrnhs 1/1 Running 0 5m39s 192.168.124.132 k8s-node01 <none> <none>
2.2.6.2.1.3 下载并配置custom-resources.yaml清单文件
custom-resources.yaml用于自定义通过Tigera Calico operator安装和配置Calico,它会创建由operator实现的Installation资源对象。
在自定义Calico之前可以通过"Installation reference | Calico Documentation"先了解安装配置。
注:这边需要修改一下Pod分配子网范围(CIDR),该地址需要与kubeadm初始化集群时的"podSubnet"字段或"--pod-network-cidr"参数中填写的值相同。
# wget https://projectcalico.docs.tigera.io/manifests/custom-resources.yaml -O calico-custom-resources.yaml --no-check-certificate
# vim calico-custom-resources.yaml
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:name: default
spec:# Configures Calico networking.calicoNetwork:# Note: The ipPools section cannot be modified post-install.ipPools:- blockSize: 26cidr: 10.244.0.0/16encapsulation: VXLANCrossSubnetnatOutgoing: EnablednodeSelector: all()
2.2.6.2.1.4 应用custom-resources.yaml清单文件
# kubectl apply -f calico-custom-resources.yaml
2.2.6.2.1.5 查看Calico是否运行
Tigera Calico Operator会自动创建一个名叫"calico-system"的名称空间来运行Calico。
# kubectl get namespace
NAME STATUS AGE
calico-system Active 3m10s
default Active 5m55s
kube-node-lease Active 5m57s
kube-public Active 5m57s
kube-system Active 5m57s
tigera-operator Active 3m20s
# kubectl get pod -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-7dfc6fb85-ktww2 0/1 Pending 0 8m33s
calico-node-2t4dp 0/1 Init:ImagePullBackOff 0 8m34s
calico-node-mmflx 0/1 Init:ImagePullBackOff 0 8m34s
calico-node-r94tt 0/1 Init:ImagePullBackOff 0 8m34s
calico-node-w7plh 0/1 Init:ImagePullBackOff 0 7m36s
calico-typha-5fb57458cc-g89qp 0/1 ImagePullBackOff 0 8m34s
calico-typha-5fb57458cc-t5xcm 0/1 ImagePullBackOff 0 8m28s
# kubectl describe pod calico-kube-controllers-7dfc6fb85-ktww2 -n calico-systemNormal BackOff 69s (x2 over 3m41s) kubelet Back-off pulling image "docker.io/calico/pod2daemon-flexvol:v3.23.0"Warning Failed 69s (x2 over 3m41s) kubelet Error: ImagePullBackOff
可以看到所有Calico相关的Pod由于在国内环境下都无法正常下载由docker.io提供的镜像:
# kubectl describe pod -n calico-system |grep 'Events' -A 10 |grep -Eo '"docker.io/calico/.*"' |sort |uniq
"docker.io/calico/cni:v3.23.0"
"docker.io/calico/kube-controllers:v3.23.0"
"docker.io/calico/node:v3.23.0"
"docker.io/calico/pod2daemon-flexvol:v3.23.0"
"docker.io/calico/typha:v3.23.0"
尝试手动从quay.io下载镜像。quay.io是一个公共镜像仓库。
所有主机上操作:
# docker pull quay.io/calico/cni:v3.23.0
# docker pull quay.io/calico/kube-controllers:v3.23.0
# docker pull quay.io/calico/node:v3.23.0
# docker pull quay.io/calico/pod2daemon-flexvol:v3.23.0
# docker pull quay.io/calico/typha:v3.23.0
这个时候发现Calico相关Pod都已正常运行了:
# kubectl get pod -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-7dfc6fb85-vbn6q 1/1 Running 0 64m
calico-node-29h89 1/1 Running 0 64m
calico-node-9c54r 1/1 Running 1 (10m ago) 64m
calico-node-ntzvt 1/1 Running 0 64m
calico-node-s5bz9 1/1 Running 0 64m
calico-typha-5dd57768f4-79clk 1/1 Running 1 (10m ago) 27m
calico-typha-5dd57768f4-dk9ph 1/1 Running 0 64m2.2.6.2.2 Calico清单详解-custom-resources.yaml
custom-resources.yaml清单文件通过Tigera Calico Operator安装Calico的自定义清单文件。
在安装Calico之前,我们可以通过修改该清单的内容自定义配置Calico。
参考文档:Installation reference | Calico Documentation
# This section includes base Calico installation configuration.
# For more information, see: https://projectcalico.docs.tigera.io/v3.23/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:name: default
spec:# Configures Calico networking.calicoNetwork:# Note: The ipPools section cannot be modified post-install.ipPools:- blockSize: 26cidr: 10.244.0.0/16encapsulation: VXLANCrossSubnetnatOutgoing: EnablednodeSelector: all()---# This section configures the Calico API server.
# For more information, see: https://projectcalico.docs.tigera.io/v3.23/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:name: default
spec: {}
- spec.calicoNetwork:配置Calico网络。
- spec.calicoNetwork.bgp:开启或禁用BGP路由功能。支持值:Enabled, Disabled。
- spec.calicoNetwork.ipPools:IPPool,为由节点筛选器指定节点上创建Pod分配的单个或多个地址池,以及要使用的Pod网络的实现方法。
- spec.calicoNetwork.ipPools.blockSize(int32):块大小,子网划分技术,指从CIDR(如:10.244.0.0/16)里面为每个节点拆分一个独立的子网块范围大小(如:10.244.32.128/26)。默认IPV4=26,IPV6=122。二进制掩码26转换成十进制掩码即=255.255.255.192,即每个节点的子网可以有64个IP地址,减去广播地址和网络地址,可为Pod分配的有效IP地址有62个。
- spec.calicoNetwork.ipPools.cidr(string):Pod网络IP范围。
- spec.calicoNetwork.ipPools.encapsulation:设置Pod网络要使用的封装协议类型,支持:
-
IPIP,使用IPIP封装协议。
-
VXLAN,使用VXLAN封装协议。
-
IPIPCrossSubnet,当物理主机是跨子网的情况下才使用IPIP覆盖网络通信方式,正常情况下使用BGP路由模式。
-
VXLANCrossSubnet,当物理主机是跨子网的情况下才使用VXLAN覆盖网络通信方式,正常情况下使用BGP路由模式。
-
None,不使用IPIP或VXLAN封装。
-
- spec.calicoNetwork.ipPools.natOutgoing:NAT传出,对传出的流量启用或禁用NAT功能。支持值:Enabled, Disabled。
- spec.calicoNetwork.ipPools.nodeSelector(string):节点选择器,使用它选择该IPPool池会影响那些节点的Pod。默认值为"all()",保持默认就好。
2.2.7 完全卸载Calico网络插件
1)删除安装清单中的所有资源对象
任一台Master上操作:
# kubectl delete -f calico.yaml
2)删除tunl0虚拟网卡
如果使用了IPIP覆盖网络模式,则Calico会在每台主机上创建一块名叫tunl0的虚拟网卡设备。
在所有主机上操作:
# modprobe -r ipip
3)删除Calico相关CNI配置文件
在所有主机上操作:
# rm -rf /var/lib/cni/ && rm -rf /etc/cni/net.d/*
4)重启kubelet服务
在所有主机上操作:
# systemctl restart kubelet