📕参考:ysu老师课件+西瓜书
1.决策树的基本概念

【决策树】:决策树是一种描述对样本数据进行分类的树形结构模型,由节点和有向边组成。其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
理解:它是一个树状结构,其中每个节点代表一个特征属性的判断,每个分支代表这个判断的结果,而每个叶节点(叶子)代表一种类别或回归值。
关于决策树要掌握的概念:
根节点(Root Node): 包含整个数据集,并通过某个特征属性进行判断。
分支(Branch): 从根节点出发的每个路径,代表在某个特征属性上的判断结果。
内部节点(Internal Node): 在决策路径上的非叶节点,表示对某个特征属性的判断。
叶节点(Leaf Node): 在决策路径上的末端节点,表示最终的类别或回归值。
决策树的优缺点:
优点:
易于理解和解释: 决策树的图形化表示使得结果容易理解,可以可视化地表示整个决策过程。
无需特征缩放: 不需要对特征进行标准化或归一化。
处理混合数据类型: 可以处理既有连续型特征又有离散型特征的数据。
能够捕捉特征之间的相互关系: 可以捕捉特征之间的非线性关系。
缺点:
过拟合(Overfitting): 在处理复杂问题时容易生成过于复杂的树,导致在训练数据上表现良好但在未知数据上泛化能力差。
对噪声敏感: 对数据中的噪声和异常值较为敏感。
不稳定性: 数据的小变化可能导致生成完全不同的树。
2.决策树的生成过程
决策树模型涉及到三个关键过程:
一是特征变量的选择,根据某个指标(如信息增益、基尼指数等)选择当前最佳的特征属性作为判断依据。
二是决策树的生成,常用的决策树算法有ID3、C4.5、CART等算法;
三是决策树的剪枝,通过剪枝来避免过拟合,提升对数据的预测效果。
2.1 特征变量的选择
最常用的三种特征选择策略:信息增益、信息增益比、Gini指数
2.1.1 信息增益
首先引入【信息量】。
消息中所包含的信息量大小与该消息所表示的事件出现的概率相关,如果一个消息所表示的事件是必然事件(发生概率100%),则该消息所包含的信息量为0;如果一个消息表示的不可能事件(发生概率极低),则该消息的信息量为无穷大。
比如:某同事跑过来和你说:“小王,明早太阳会从东方升起”。(概率为1,信息量为0)
信息量应该随着概率单调递减:某事件的概率越大,则信息量越小。
再引入【信息熵】。
“信息熵”用来表示信息不确定性的一种度量。熵越高表示越混乱,熵越低表示越有序。
(类比高中学的分子状态混乱程度,熵越大越混乱)
再引入【信息增益】。
“信息增益”表示在知道某个特征之后使得不确定性减少的程度(知道某个特征前的熵与知道某个特征之后的熵之差)。
根据某个变量将样本数据分割为多个子集,分割前与分割后样本数据的熵之差为信息增益,信息增益越高,表示该变量对样本数据的分类效果越好。
2.1.2 信息增益比
再引入【信息增益比】
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,因此通过引入了【信息增益比】来解决该问题。
比如:以user_id为特征变量,由于每个人的user_id是唯一的,在每个user_id下可以完美地进行准确分类,但是这种情况显然是无意义的。

注:只有在不同变量分裂出不同个数子节点的情况下,信息增益比才会起作用。如果每个变量允许分裂相同个数的子节点,那么信息增益比并不起作用。
2.1.3 Gini指数
Gini指数也是衡量随机变量不纯度的一种方法,Gini指数越小,则表示变量纯度越高,Gini指数越大,表示变量纯度越低。

理解:
Gini指数表示在样本集合中随机抽取两个样本,其类别不一致的概率。因此Gini指数越小,分类越纯。
2.2 决策树的生成
常用的决策树算法有:ID3、C4.5、CART
先介绍决策树生成时的三个【终止条件】:
- 当前节点包含的样本全部属于同一类别
- 当前节点已经没有样本,不能再继续划分
- 所有特征已经使用完毕
2.2.1 ID3——信息增益
ID3(Iterative Dichotomiser 3)是一种基于信息增益的决策树生成算法。
其主要步骤包括:
计算信息熵: 对每个特征计算数据集的信息熵,用于度量数据的不确定性。
计算信息增益: 对每个特征计算信息增益,选择信息增益最大的特征作为当前节点的划分特征。
划分数据集: 使用选择的最佳特征对数据集进行划分,生成相应的子集。
递归生成子树: 对每个子集递归地应用上述步骤,生成子树。
停止条件: 在递归生成子树的过程中,设置停止条件,例如树的深度达到预定值、节点包含的样本数小于某个阈值等。
【专业描述】

2.2.2 C4.5——信息增益比
C4.5算法整体上与ID3算法非常相似,不同之处是C4.5以信息增益比为准则来选择分枝变量。
2.2.3 CART——Gini指数
CART(Classification and Regression Trees)是一种基于Gini指数的决策树生成算法,可用于分类和回归任务。
其主要步骤包括:
计算Gini指数: 对每个特征计算数据集的Gini指数,用于度量数据的不纯度。
选择最小Gini指数的特征: 选择Gini指数最小的特征作为当前节点的划分特征。
划分数据集: 使用选择的最佳特征对数据集进行划分,生成相应的子集。
递归生成子树: 对每个子集递归地应用上述步骤,生成子树。
停止条件: 在递归生成子树的过程中,设置停止条件,例如树的深度达到预定值、节点包含的样本数小于某个阈值等。
【专业描述】

注意:
CART是一种二叉树,即将所有问题看做二元分类问题。
由于CART是二叉树,在遇到连续变量或者多元分类变量时,存在寻找最优切分点的情况。
【补充】
CART的缺点
二元划分: CART算法每次划分只能选择一个特征的一个切分点进行二元划分,这可能导致树的结构相对较深,对某些问题可能不够简洁。
贪婪算法: CART是一种贪婪算法,它在每一步选择最优划分,但这并不一定会导致全局最优的决策树。有时候,全局最优的决策树需要考虑多步划分的组合,而CART只考虑当前最优的一步。
对于不平衡数据集的处理: 在处理不平衡数据集时,CART可能会偏向那些具有较多样本的类别,导致对于少数类的划分不够精细。
非平滑性: CART生成的树是非平滑的,对于输入空间的微小变化可能产生较大的输出变化,这使得CART对于输入空间的局部变化较为敏感。
两种决策的对比
信息增益(ID3): 用于分类问题,通过选择能够最大程度降低不确定性的特征。
基尼不纯度(CART): 适用于分类和回归问题,通过选择能够最小化不纯度的特征。
2.3 决策树的剪枝
决策树的剪枝是为了防止过拟合,即过度依赖训练数据而导致在未知数据上表现不佳。
剪枝通过修剪决策树的一部分来达到简化模型的目的。
剪枝分为预剪枝(Pre-pruning)和后剪枝(Post-pruning)两种类型。
2.3.1 预剪枝
在决策树生成的过程中,在每次划分节点之前,通过一些预定的规则判断是否继续划分。若当前结点的划分不能使决策树泛化性能提升,则停止划分并将当前结点记为叶结点,其类别标记为训练样例数最多的类别。
预剪枝的一些常见条件包括:
- 树的深度限制: 设置树的最大深度,防止树过于复杂。
- 节点样本数量限制: 当节点中的样本数量小于某个阈值时停止划分。
- 信息增益或基尼不纯度阈值: 当划分节点后的信息增益或基尼不纯度低于设定的阈值时停止划分。
预剪枝的优缺点
优点:
- 降低过拟合风险
- 显著减少训练时间和测试时间开销
缺点:
- 欠拟合风险:有些分支的当前划分虽然不能提升泛化性能,但在其基础上进行的后续划分却有可能导致性能显著提高。预剪枝基于“贪心”本质禁止这些分支展开,带来了欠拟合风险
2.3.2 后剪枝
在决策树生成完成后,通过递归地从底部向上对节点进行判断,决定是否剪枝。
具体过程如下:
从叶子节点开始: 递归地向上考察每个叶子节点。
计算剪枝前后的性能: 对于每个叶子节点,计算剪枝前后在验证集上的性能差异。
剪枝决策: 如果剪枝可以提高性能(如准确率、F1分数等),则进行剪枝,将该节点变为叶子节点。
重复: 重复上述过程,直到找到合适的剪枝点或不再发生性能提升。
后剪枝相对于预剪枝更为灵活,因为它在生成完整的树之后才进行剪枝决策,可以更准确地评估每个子树的性能。
后剪枝的优缺点:
优点:
- 后剪枝比预剪枝保留了更多的分支,欠拟合风险小,泛化性能往往优于预剪枝决策树
缺点
- 训练时间开销大:后剪枝过程是在生成完全决策树之后进行的,需要自底向上对所有非叶结点逐一考察
3.代码实践
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_text
from sklearn import tree
import matplotlib.pyplot as plt# 加载示例数据集(鸢尾花数据集)
iris = load_iris()
X = iris.data
y = iris.target# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树模型
clf = DecisionTreeClassifier()# 训练模型
clf.fit(X_train, y_train)# 使用模型进行预测
y_pred = clf.predict(X_test)# 输出模型的准确率
accuracy = clf.score(X_test, y_test)
print(f"Model Accuracy: {accuracy:.2f}")# 输出决策树的规则
tree_rules = export_text(clf, feature_names=iris.feature_names)
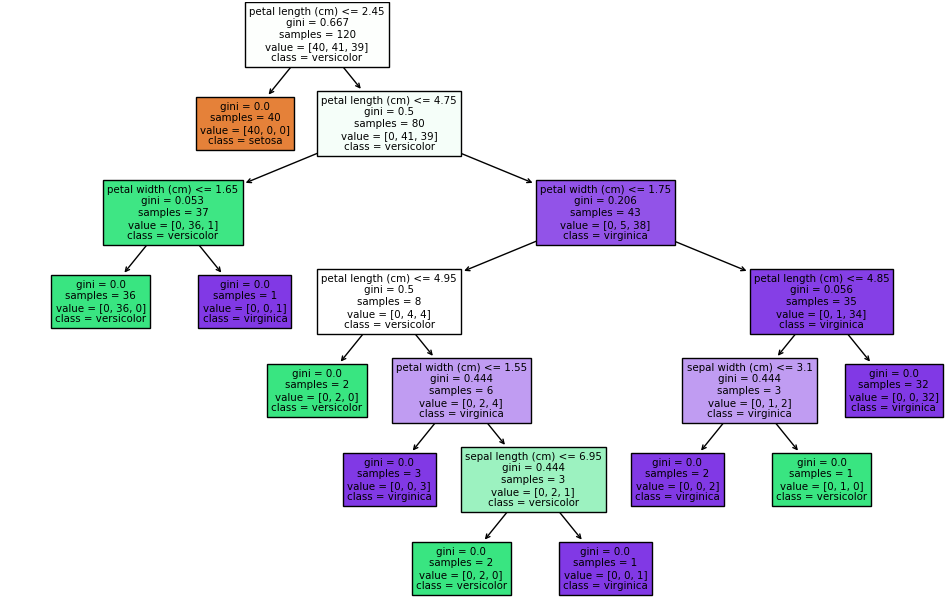
print("Decision Tree Rules:\n", tree_rules)# 可视化决策树
fig, ax = plt.subplots(figsize=(12, 8))
tree.plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, ax=ax)
plt.show()