前言
由于 ChatGPT 和 GPT4 兴起,如何让人人都用上这种大模型,是目前 AI 领域最活跃的事情。当下开源的 LLM(Large language model)非常多,可谓是百模大战。面对诸多开源本地模型,根据自己的需求,选择适合自己的基座模型和参数量很重要。选择完后需要对训练数据进行预处理,往往这一步就难住很多同学,无从下手,更别说 training。
然后再对模型进行 finetuning 来更好满足自己的下游任务。那么对于如果要训练一个专家模型。预训练也是必不可缺的工作。不管是预训练还是 finetuning(微调),无论选用何种方案,都避免不了训练中产生的灾难性遗忘问题,那么怎么减少和避免这种情况的发生,也是本文想讲的一个重点。对于推理,在 GPU 资源不富裕的情况,如何最小化的利用内存,提升推理效率,也是可以讨论的内容。

模型选择
先看一下最好的模型有哪些,以下数据是最新 LLM 排行,来自 UC 伯克利 [1]


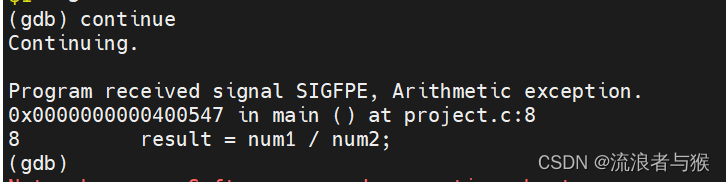


![【蓝桥杯冲冲冲】[NOIP2017 提高组] 宝藏](https://img-blog.csdnimg.cn/img_convert/0133354571d6164ee90cda7abb9e9549.png)