CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
2023.03.06—2023.03.12
Top Papers
Subjects: cs.CL
1.Larger language models do in-context learning differently

标题:更大的语言模型以不同的方式进行上下文学习
作者:Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen
文章链接:https://arxiv.org/abs/2303.01037
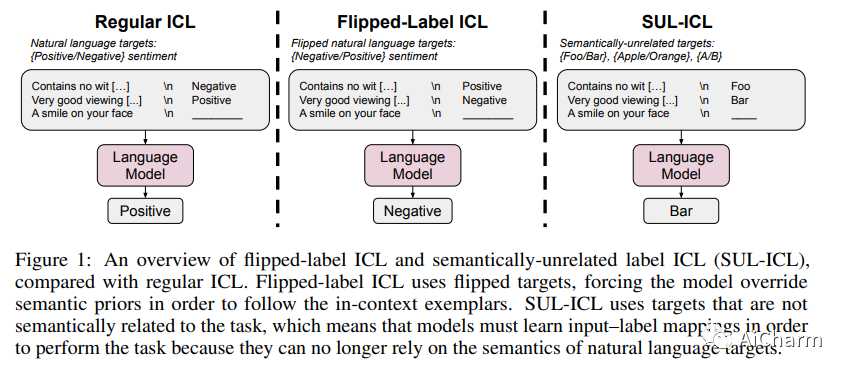


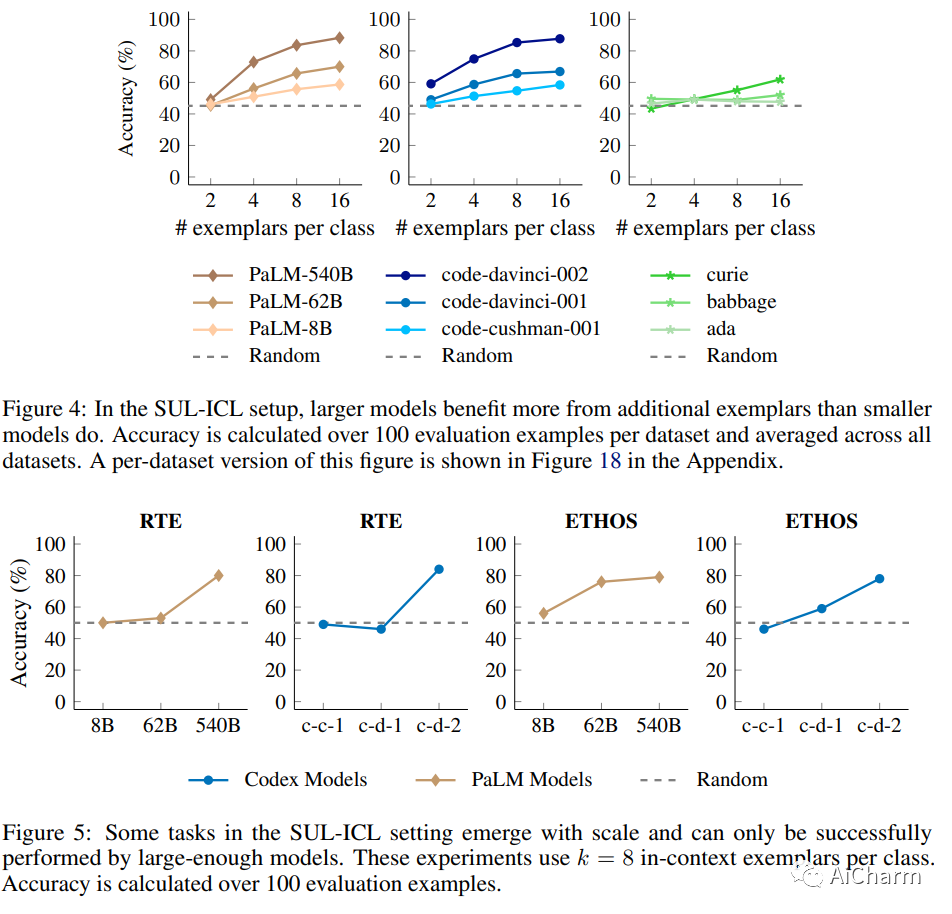
我们研究了语言模型中的上下文学习 (ICL) 如何受到语义先验与输入标签映射的影响。我们研究了两种设置——带有翻转标签的 ICL 和带有语义无关标签的 ICL——跨越各种模型系列(GPT-3、InstructGPT、Codex、PaLM 和 Flan-PaLM)。首先,带有翻转标签的 ICL 实验表明,覆盖语义先验是模型规模的一种新兴能力。虽然小型语言模型忽略上下文中呈现的翻转标签,因此主要依赖于预训练的语义先验,但大型模型可以在呈现与先验相矛盾的上下文范例时覆盖语义先验,尽管更大的模型可能拥有更强的语义先验。我们接下来研究语义无关标签 ICL (SUL-ICL),其中标签与其输入在语义上无关(例如,foo/bar 而不是负/正),从而迫使语言模型学习中所示的输入-标签映射-上下文范例以执行任务。进行 SUL-ICL 的能力也主要随着规模而出现,足够大的语言模型甚至可以在 SUL-ICL 设置中执行线性分类。最后,我们评估了指令调整模型,发现指令调整加强了语义先验的使用和学习输入标签映射的能力,但更多的是前者。

上榜理由
该论文声称,具有语义无关标签的上下文学习随着规模而出现。您可以在下图中看到“当使用语义无关目标或 NL 目标时,小型模型的性能下降幅度大于大型模型。”
论文中有许多很酷的结果:指令调整的 LM 在学习输入标签映射方面比仅预训练的 LM 表现更好。通常,更大的模型和每个类的更多范例会产生更好的结果。
有了规模,LLM 可以在提供足够多的翻转标签时覆盖语义先验;当用语义无关的目标替换目标时,这些模型也能表现良好。
2.Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages

标题:Google USM:扩展超过 100 种语言的自动语音识别
作者:Yu Zhang, Wei Han, James Qin, Yongqiang Wang, Ankur Bapna, Zhehuai Chen
文章链接:https://arxiv.org/abs/2303.01037



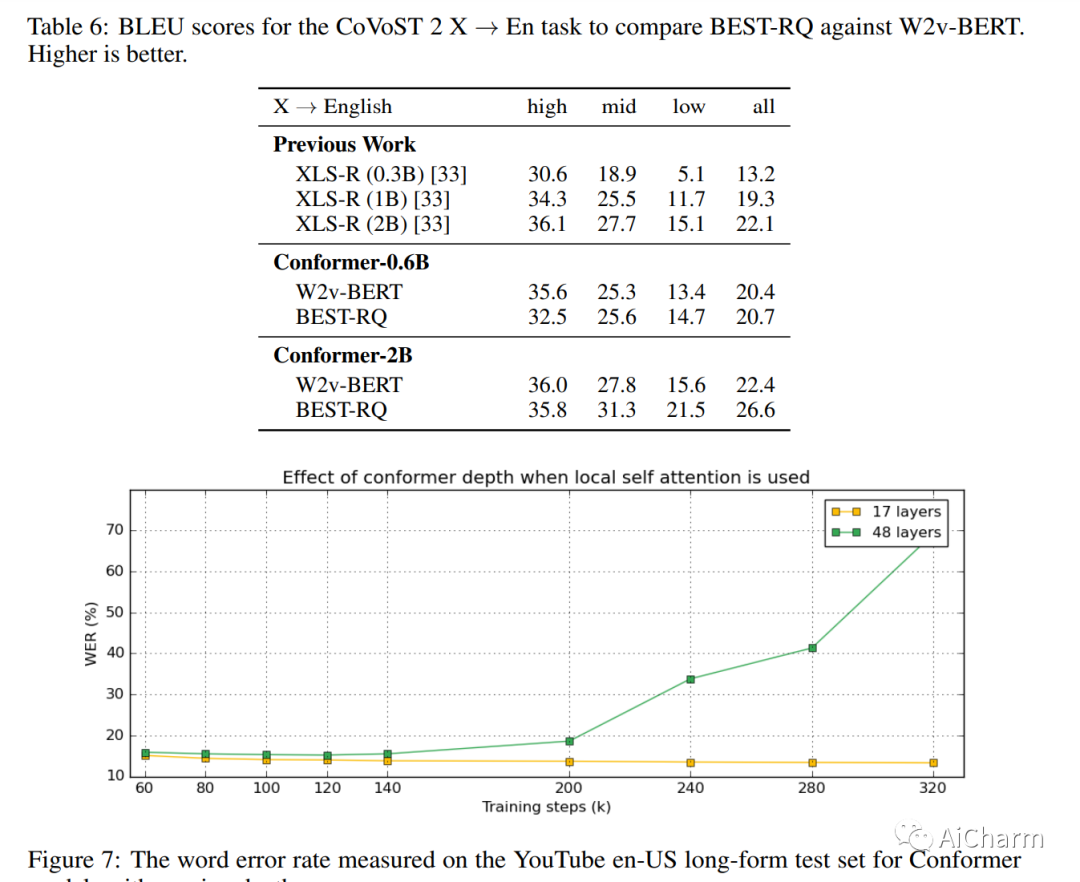
我们介绍了通用语音模型 (USM),这是一个单一的大型模型,可在 100 多种语言中执行自动语音识别 (ASR)。这是通过在跨越 300 多种语言的 1200 万 (M) 小时的大型未标记多语言数据集上对模型的编码器进行预训练,并在较小的标记数据集上进行微调来实现的。我们使用具有随机投影量化和语音文本模态匹配的多语言预训练来实现下游多语言 ASR 和语音到文本翻译任务的最先进性能。我们还证明,尽管使用的标记训练集的大小是 Whisper 模型所用训练集的 1/7,但我们的模型在跨多种语言的域内和域外语音识别任务上表现出相当或更好的性能。
3.More than you've asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models

标题:超出您的要求:对应用程序集成大型语言模型的新型快速注入威胁的综合分析
作者:Parker Riley, Timothy Dozat, Jan A. Botha, Xavier Garcia, Dan Garrette, Jason Riesa, Orhan Firat, Noah Constant
文章链接:https://arxiv.org/abs/2302.12173v1
项目代码:https://github.com/greshake/lm-safety




我们目前正在见证大型语言模型 (LLM) 功能的巨大进步。它们已经在实践中被采用并集成到许多系统中,包括集成开发环境 (IDE) 和搜索引擎。当前 LLM 的功能可以通过自然语言提示进行调整,而它们确切的内部功能仍然隐含且不可评估。这种特性使它们甚至可以适应看不见的任务,也可能使它们容易受到有针对性的对抗性提示的影响。最近,引入了几种使用提示注入 (PI) 攻击来错位 LLM 的方法。在此类攻击中,对手可以提示 LLM 生成恶意内容或覆盖原始指令和采用的过滤方案。最近的工作表明,这些攻击很难缓解,因为最先进的 LLM 是遵循指令的。到目前为止,这些攻击假设对手直接提示 LLM。在这项工作中,我们展示了通过检索和 API 调用功能(所谓的应用程序集成 LLM)增强 LLM 会引发一组全新的攻击向量。这些 LLM 可能会处理从 Web 检索到的有毒内容,这些内容包含由对手预先注入和选择的恶意提示。我们证明攻击者可以间接执行此类 PI 攻击。基于这一重要见解,我们系统地分析了应用程序集成 LLM 所产生的威胁格局,并讨论了各种新的攻击向量。为了证明我们攻击的实际可行性,我们在合成应用程序中实施了拟议攻击的具体演示。总之,我们的工作要求对当前的缓解技术进行紧急评估,并调查是否需要新技术来保护 LLM 免受这些威胁。
Subjects: cs.CV
1.Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
标题:Visual ChatGPT:使用 Visual Foundation 模型交谈、绘图和编辑
作者:Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
文章链接:https://t.co/0nYSa7CupY
项目代码:https://github.com/microsoft/visual-chatgpt



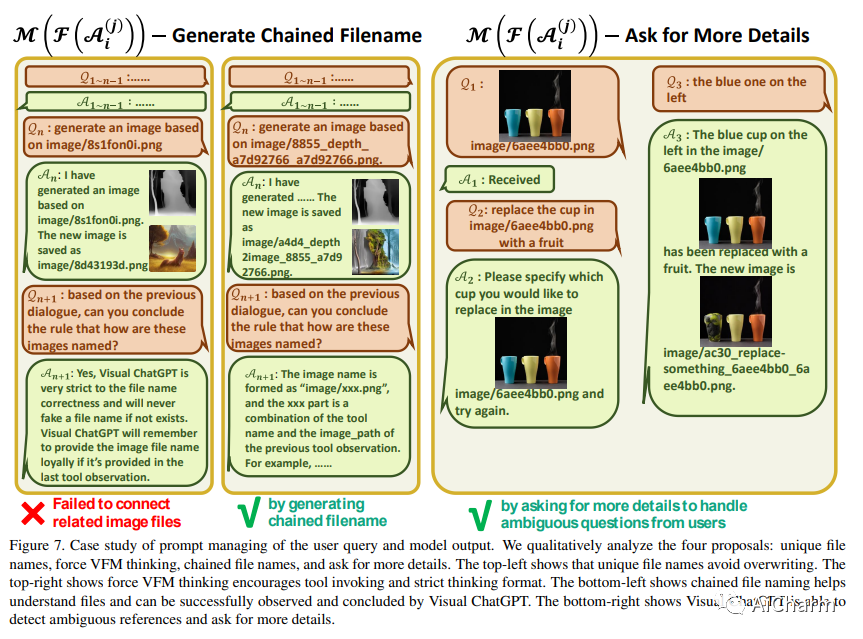
ChatGPT 正在吸引跨领域的兴趣,因为它提供了一种语言界面,具有跨多个领域的卓越对话能力和推理能力。然而,由于 ChatGPT 是用语言训练的,它目前无法处理或生成来自视觉世界的图像。同时,Visual Foundation Models,如 Visual Transformers 或 Stable Diffusion,虽然表现出强大的视觉理解和生成能力,但它们只是特定任务的专家,具有一轮固定的输入和输出。为此,我们构建了一个名为 \textbf{Visual ChatGPT} 的系统,结合了不同的视觉基础模型,使用户能够通过以下方式与 ChatGPT 进行交互:1)不仅发送和接收语言,还发送和接收图像 2)提供复杂的视觉问题或视觉编辑需要多个 AI 模型多步骤协作的指令。3) 提供反馈并要求更正结果。我们设计了一系列提示将视觉模型信息注入 ChatGPT,考虑到多个输入/输出的模型和需要视觉反馈的模型。实验表明,Visual ChatGPT 打开了借助 Visual Foundation Models 研究 ChatGPT 视觉角色的大门。
上榜理由
构建一个名为 Visual ChatGPT 的系统,结合不同的视觉基础模型,使用户能够通过以下方式与 ChatGPT 进行交互:1)不仅发送和接收语言,还发送和接收图像 2)提供需要多个 AI 协作的复杂视觉问题或视觉编辑指令具有多步骤的模型。3)提供反馈并要求更正结果。
它使用 ChatGPT 作为中央通信枢纽,并插入许多黑盒视觉模型,例如 Stable Diffusion、pix2pix 和 ControlNet。结果是一个多模态会话人工智能,它既能理解又能生成图像,具有零可训练参数。
2.GigaGAN: Large-scale GAN for Text-to-Image Synthesis(CVPR 2023)

标题:GigaGAN:用于文本到图像合成的大规模 GAN
作者:Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, Taesung Park
文章链接:https://arxiv.org/abs/2303.05511
项目代码:https://mingukkang.github.io/GigaGAN/
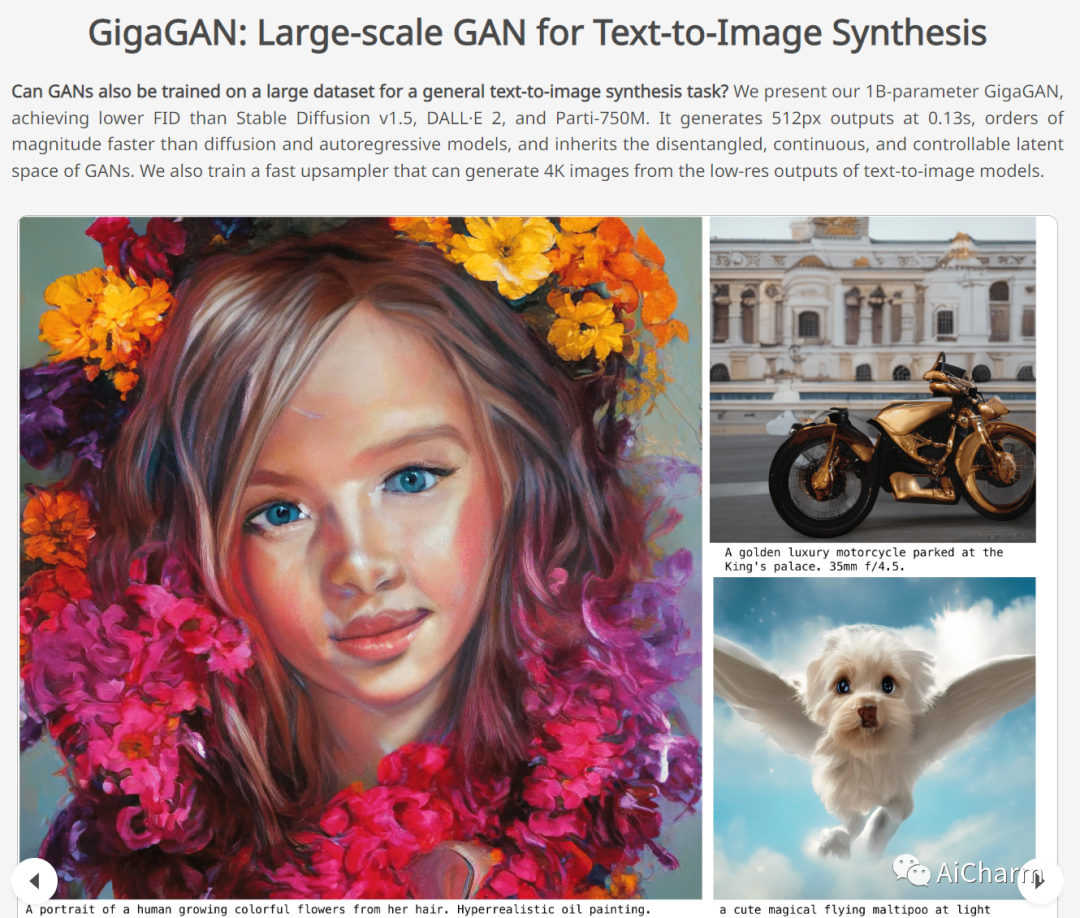


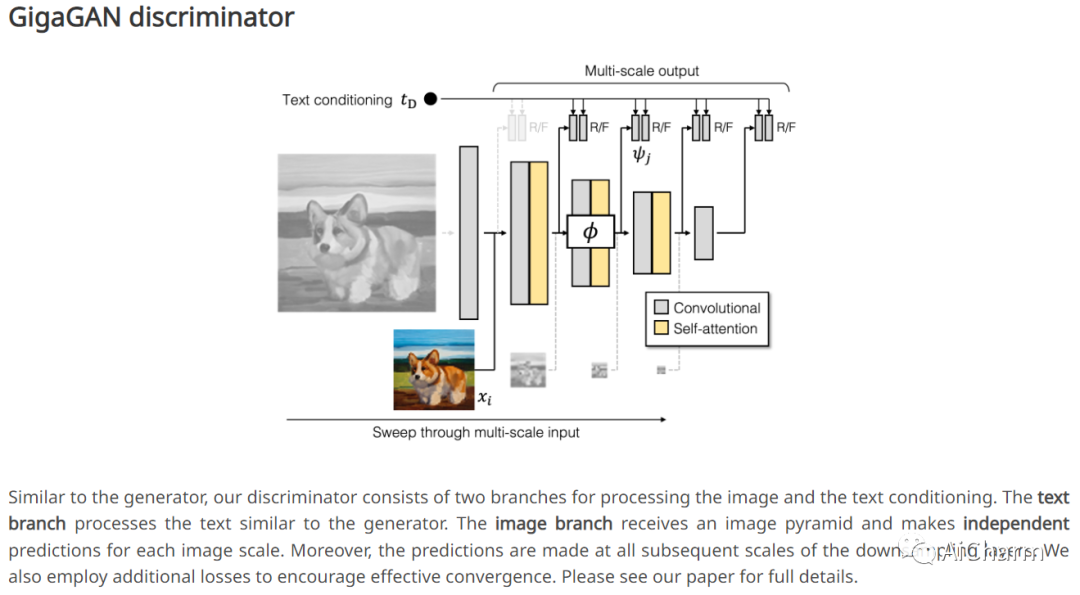
最近文本到图像合成的成功席卷了世界,并俘获了公众的想象力。从技术的角度来看,它也标志着设计生成图像模型的首选架构发生了巨大变化。GAN 曾经是事实上的选择,采用 StyleGAN 等技术。借助 DALL-E 2,自回归和扩散模型一夜之间成为大规模生成模型的新标准。这种快速转变提出了一个基本问题:我们能否扩大 GAN 以从像 LAION 这样的大型数据集中获益?我们发现,天真地增加 StyleGAN 架构的容量会很快变得不稳定。我们介绍了 GigaGAN,这是一种远远超过此限制的新 GAN 架构,展示了 GAN 作为文本到图像合成的可行选择。GigaGAN 具有三大优势。首先,它在推理时间上快了几个数量级,合成一张 512 像素的图像仅需 0.13 秒。其次,它可以在 3.66 秒内合成高分辨率图像,例如 16 兆像素。最后,GigaGAN 支持各种潜在空间编辑应用,例如潜在插值、样式混合和向量算术运算。
3.Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models

标题:使用文本到图像扩散模型的开放词汇全景分割
作者:Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, Shalini De Mello
文章链接:https://arxiv.org/abs/2303.04803
项目代码:https://jerryxu.net/ODISE/


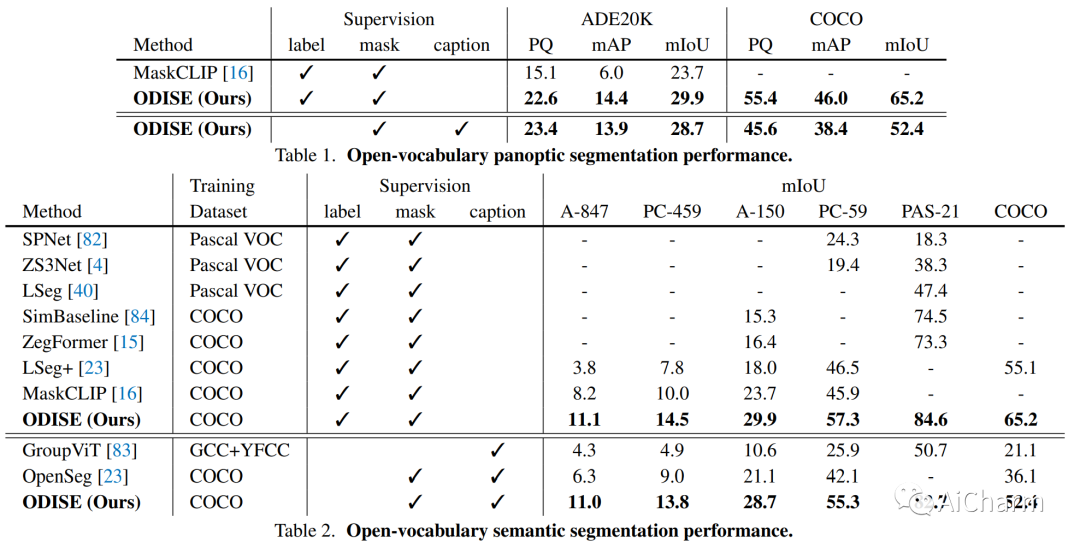
我们提出了 ODISE:基于开放词汇扩散的全景分割,它统一了预训练的文本图像扩散和判别模型来执行开放词汇全景分割。文本到图像的扩散模型显示了生成具有多种开放式词汇语言描述的高质量图像的卓越能力。这表明它们的内部表示空间与现实世界中的开放概念高度相关。另一方面,像 CLIP 这样的文本图像判别模型擅长将图像分类为开放式词汇标签。我们建议利用这两个模型的冻结表示来执行野外任何类别的全景分割。我们的方法在开放词汇全景和语义分割任务上的表现都优于以前的最先进技术。特别是,仅通过 COCO 训练,我们的方法在 ADE20K 数据集上实现了 23.4 PQ 和 30.0 mIoU,与之前的最新技术相比有 8.3 PQ 和 7.9 mIoU 的绝对改进。
4.A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT

标题:AI 生成内容 (AIGC) 综述:从 GAN 到 ChatGPT 的生成 AI 历史
作者:Yihan Cao, Siyu Li, Yixin Liu, Zhiling Yan, Yutong Dai, Philip S. Yu, Lichao Sun
文章链接:https://arxiv.org/abs/2302.04761

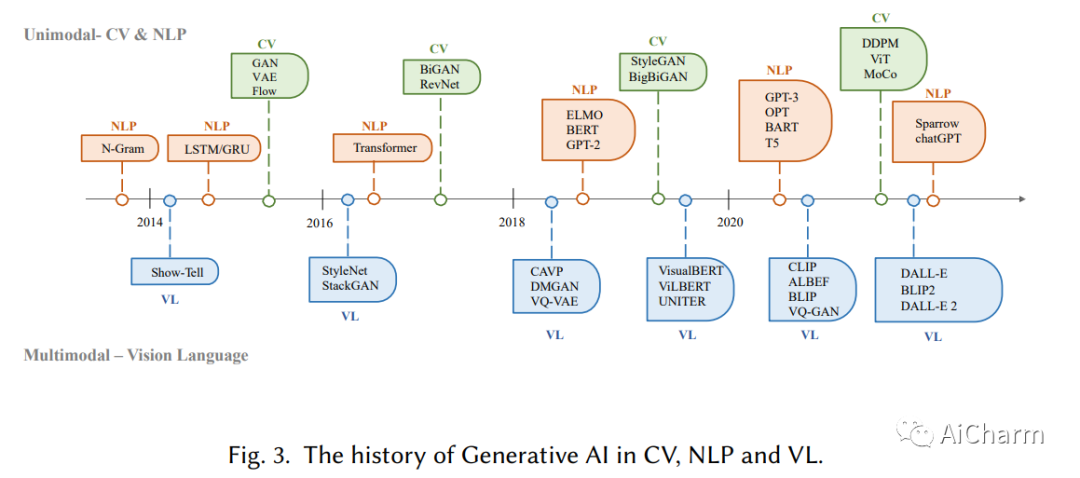


最近,ChatGPT 与 DALL-E-2 和 Codex 一起受到了社会的广泛关注。因此,许多人对相关资源产生了兴趣,并试图揭开其出色表现背后的背景和秘密。实际上,ChatGPT 和其他生成式人工智能 (GAI) 技术属于人工智能生成内容 (AIGC) 的范畴,涉及通过人工智能模型创建数字内容,例如图像、音乐和自然语言。AIGC 的目标是使内容创建过程更加高效和易于访问,从而能够以更快的速度制作高质量的内容。AIGC是通过从人类提供的指令中提取和理解意图信息,并根据其知识和意图信息生成内容来实现的。近年来,大型模型在 AIGC 中变得越来越重要,因为它们提供了更好的意图提取,从而改进了生成结果。随着数据的增长和模型的规模,模型可以学习的分布变得更加全面和接近现实,从而导致更真实和高质量的内容生成。本调查全面回顾了生成模型的历史、基本组件、AIGC 从单模态交互和多模态交互的最新进展。我们从单峰性的角度介绍了文本和图像的生成任务和相关模型。我们从多模态的角度来介绍上述模态之间的交叉应用。最后,我们讨论了 AIGC 中存在的开放性问题和未来的挑战。
Notable Papers
1.Consistency Models
标题:一致性模型
文章链接:https://arxiv.org/abs/2302.12253


摘要:
扩散模型在图像、音频和视频生成方面取得了重大突破,但它们依赖于迭代生成过程,导致采样速度缓慢并限制了它们在实时应用中的潜力。为了克服这个限制,我们提出了一致性模型,这是一个新的生成模型家族,无需对抗训练即可实现高样本质量。它们通过设计支持快速一步生成,同时仍然允许几步采样以用计算换取样本质量。它们还支持零镜头数据编辑,例如图像修复、着色和超分辨率,而无需对这些任务进行明确的培训。一致性模型可以作为提取预训练扩散模型的一种方式进行训练,也可以作为独立的生成模型进行训练。通过广泛的实验,我们证明它们在一步生成和几步生成中优于现有的扩散模型蒸馏技术。例如,我们在 CIFAR-10 上实现了新的最先进的 FID 3.55,在 ImageNet 64x64 上实现了 6.20 的一步生成。当作为独立的生成模型进行训练时,一致性模型在 CIFAR-10、ImageNet 64x64 和 LSUN 256x256 等标准基准测试中的表现也优于单步、非对抗性生成模型。
2.Word-As-Image for Semantic Typography
标题:语义排版的文字图像
文章链接:https://arxiv.org/abs/2302.12238

摘要:
文字即图像是一种语义排版技术,其中文字插图呈现了文字含义的可视化,同时还保留了其可读性。我们提出了一种自动创建文字图像插图的方法。这项任务非常具有挑战性,因为它需要对单词的语义理解以及关于在何处以及如何以视觉上令人愉悦和清晰的方式描述这些语义的创造性想法。我们依靠最近大型预训练语言视觉模型的卓越能力来直观地提炼文本概念。我们的目标是清晰传达语义的简单、简洁、黑白设计。我们刻意不改变字母的颜色或质地,也不使用装饰。我们的方法在预训练的稳定扩散模型的指导下优化每个字母的轮廓以传达所需的概念。我们合并了额外的损失条款,以确保文本的易读性和字体样式的保留。我们在众多示例中展示了高质量和引人入胜的结果,并与其他技术进行了比较。
3.Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
标题:提示、生成,然后缓存:基础模型的级联使强大的小样本学习者成为可能
文章链接:https://arxiv.org/abs/2303.02151
项目代码:https://github.com/ZrrSkywalker/CaFo
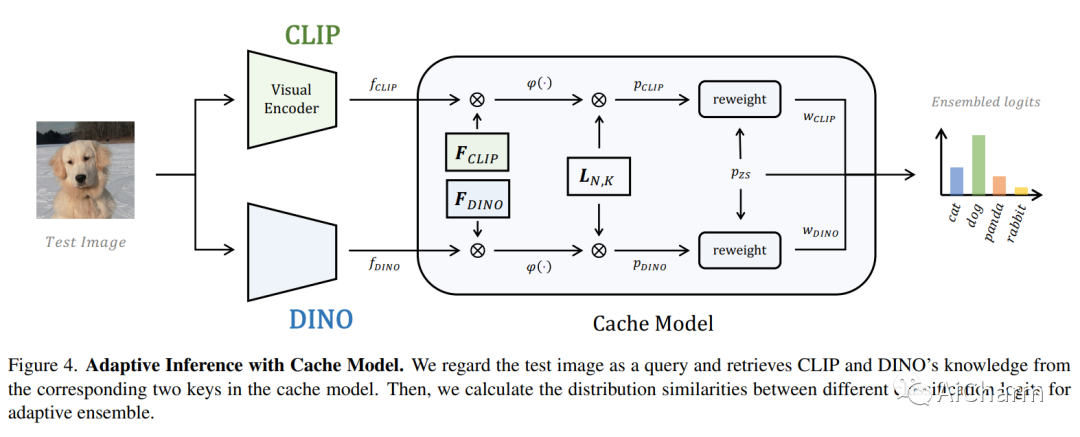
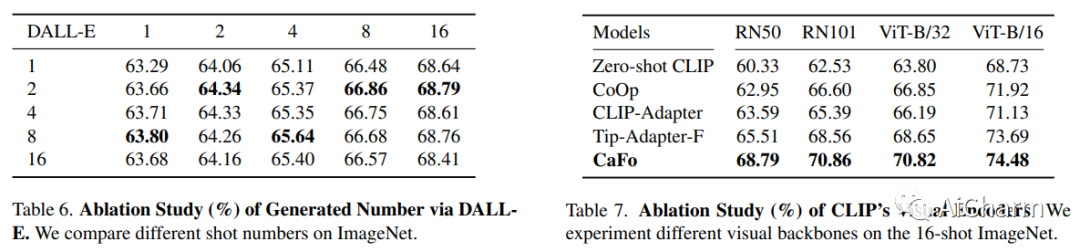
摘要:
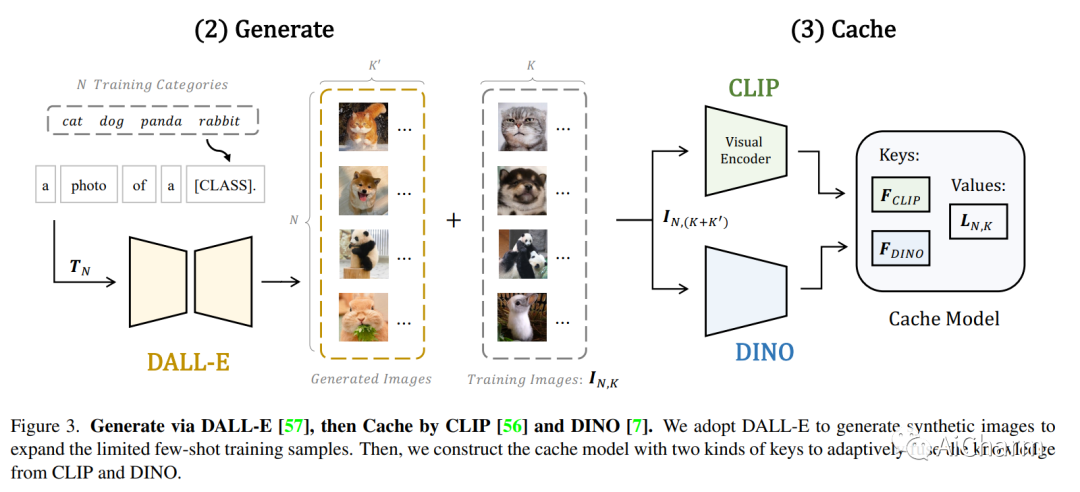
低数据条件下的视觉识别需要深度神经网络从有限的训练样本中学习广义表示。最近,基于 CLIP 的方法已经显示出有前途的小样本性能,这得益于对比语言图像预训练。然后我们质疑,是否可以级联更多样化的预训练知识以进一步协助少镜头表示学习。在本文中,我们提出了 CaFo,这是一个级联的基础模型,它结合了各种预训练范式的各种先验知识,以实现更好的少样本学习。我们的 CaFo 结合了 CLIP 的语言对比知识、DINO 的视觉对比知识、DALL-E 的视觉生成知识和 GPT-3 的语言生成知识。具体来说,CaFo 的工作原理是“提示、生成,然后缓存”。首先,我们利用 GPT-3 生成文本输入,以提示具有丰富下游语言语义的 CLIP。然后,我们通过 DALL-E 生成合成图像,以在没有任何人力的情况下扩展小样本训练数据。最后,我们引入了一个可学习的缓存模型来自适应地混合来自 CLIP 和 DINO 的预测。通过这样的合作,CaFo 可以充分发挥不同预训练方法的潜力,并将它们统一起来,以执行最先进的小样本分类。
更多Ai资讯:公主号AiCharm