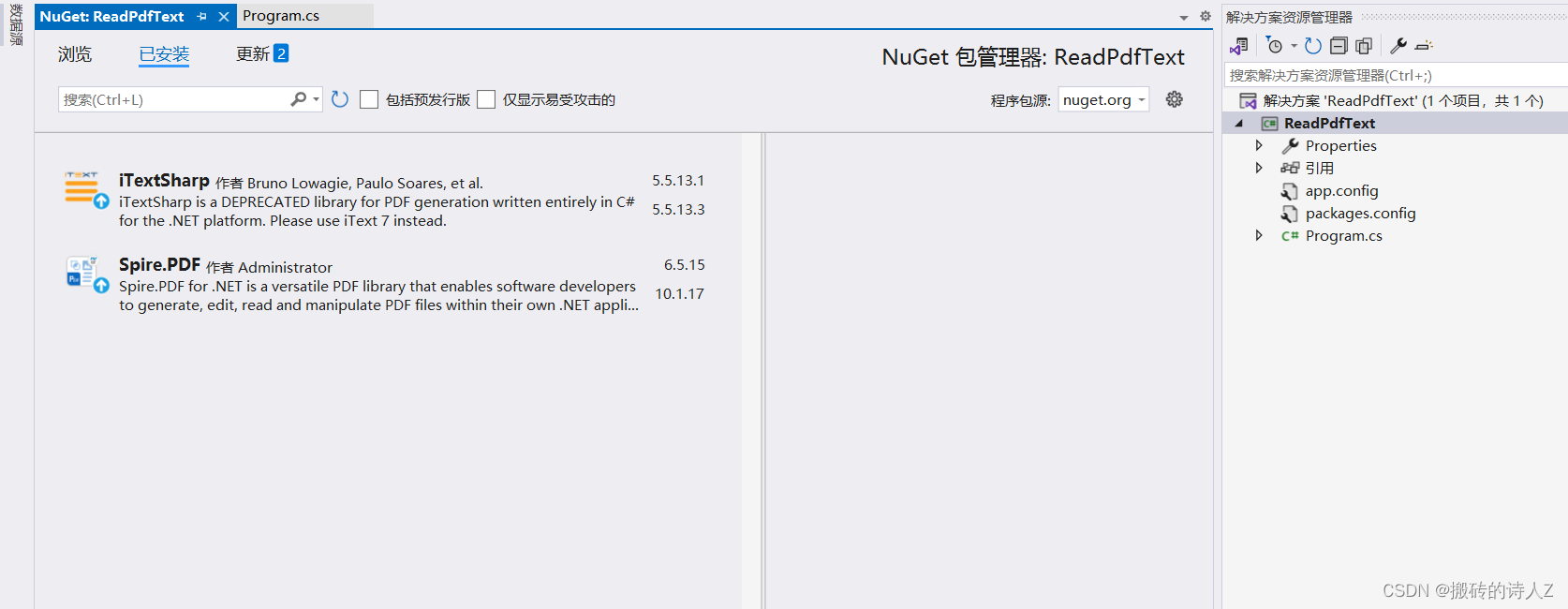
先安装如下包
using iTextSharp.text.pdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;namespace ReadPdfText
{class Program{static void Main(string[] args){string path = "0017_审判流程管理信息表2.pdf";var text = ReadPFD2(path);Console.WriteLine(text);Console.ReadKey();}public static string OnCreated(string filepath){try{string pdffilename = filepath;PdfReader pdfReader = new PdfReader(pdffilename);int numberOfPages = pdfReader.NumberOfPages;string text = string.Empty;for (int i = 1; i <= numberOfPages; ++i){iTextSharp.text.pdf.parser.ITextExtractionStrategy strategy = new iTextSharp.text.pdf.parser.SimpleTextExtractionStrategy();text += iTextSharp.text.pdf.parser.PdfTextExtractor.GetTextFromPage(pdfReader, i, strategy);}pdfReader.Close();return text;}catch (Exception ex){throw ex;//StreamWriter wlog = File.AppendText(System.AppDomain.CurrentDomain.SetupInformation.ApplicationBase + "\\mylog.log");//wlog.WriteLine("出错文件:" + ex.FullPath + "原因:" + ex.ToString());//wlog.Flush();//wlog.Close(); return null;}}public static string ReadPFD2(string path){// string path = path;// @"D:\ydfile\d4bab8ff-26ff-4ddf-a602-872f6988db86_.pdf";string text = string.Empty;try{string pdffilename = path;StringBuilder buffer = new StringBuilder();//Create a pdf document.using (Spire.Pdf.PdfDocument doc = new Spire.Pdf.PdfDocument()){// Load the PDF Documentdoc.LoadFromFile(pdffilename);// String for hold the extracted textforeach (Spire.Pdf.PdfPageBase page in doc.Pages){buffer.Append(page.ExtractText());}doc.Close();}//save texttext = buffer.ToString();return text;}catch (Exception ex){//DHC.EAS.Common.LogInfo.Debug("读取PDF文件返回=" + text);//DHC.EAS.Common.LogInfo.Debug("读取PDF文件错误", ex);return null;}}}
}