提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 安装
- 官网 ;[https://clickhouse.com/docs/zh/getting-started/install](https://clickhouse.com/docs/zh/getting-started/install)
- 1.rpm 安装包下载
- 2.单节点安装
- 3.目录介绍
- 4.启动&停止服务
- 分布式安装
- 1.搭建步骤
- 2. 配置项的解释:
- 3.启动
- yum 安装
- 1. 添加官方存储库
- 2. 安装 clickhouse server 和 client
- 3 小结
- 客户端命令行参数
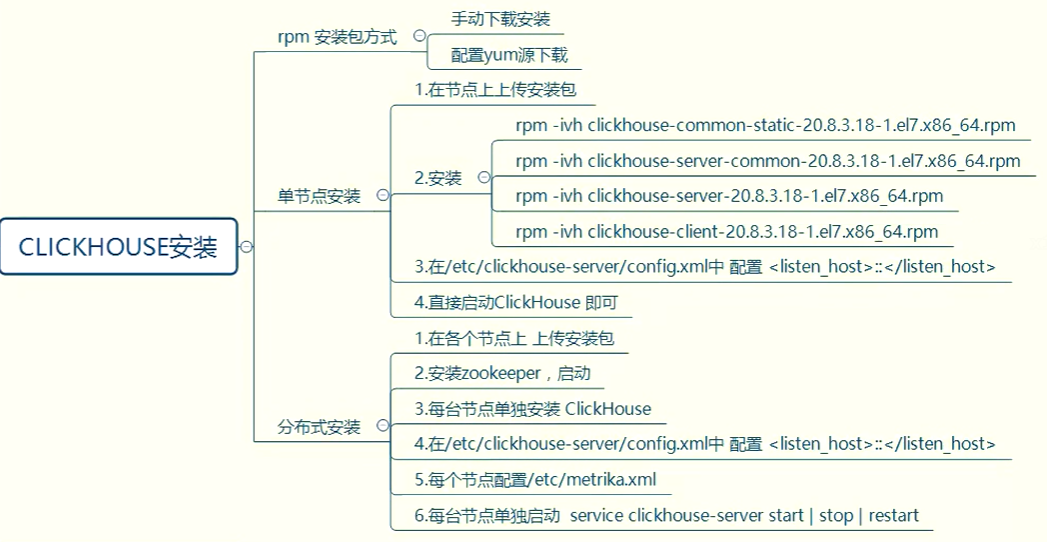
安装
- 在 官 网 中 可 以 看 到ClickHouse 可以基于多种方式安装,rpm 安装、tgz 安装包安装、docker 镜像安装、
源码编译安装等
官网 ;https://clickhouse.com/docs/zh/getting-started/install

在 官 网 中 可 以 看 到ClickHouse 可以基于多种方式安装,rpm 安装、tgz 安装包安装、docker 镜像安装、源码编译安装等
1.rpm 安装包下载
ClickHouse rpm 安 装 包 查 询 地 址为:https://packagecloud.io/Altinity/clickhouse,这里需要在 linux 中使用wget 命令下载对应的 clickHouse 版本。
选择一台服务器创建/software 目录并进入此目录,在当前目录下执行如下命令下载 ClickHouse 需要的 rpm 安装包,这里只需要下载以下四个 rpm 安装包即可
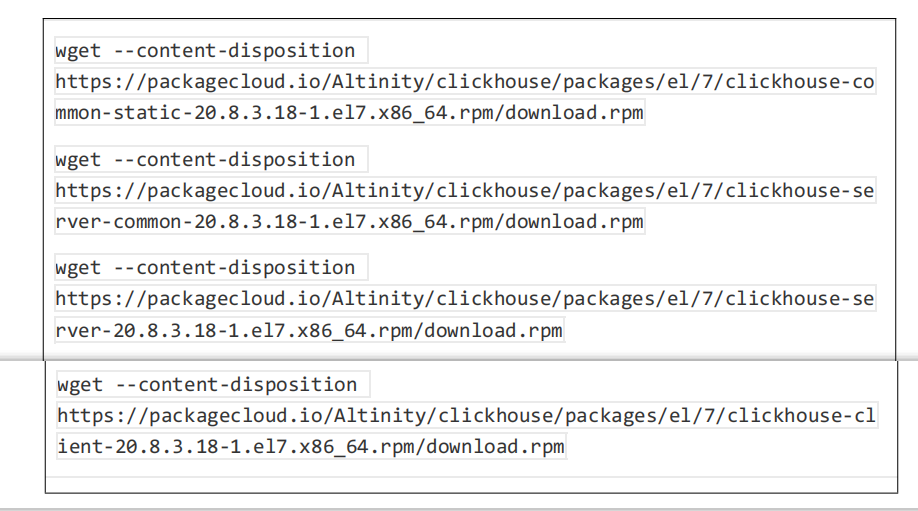
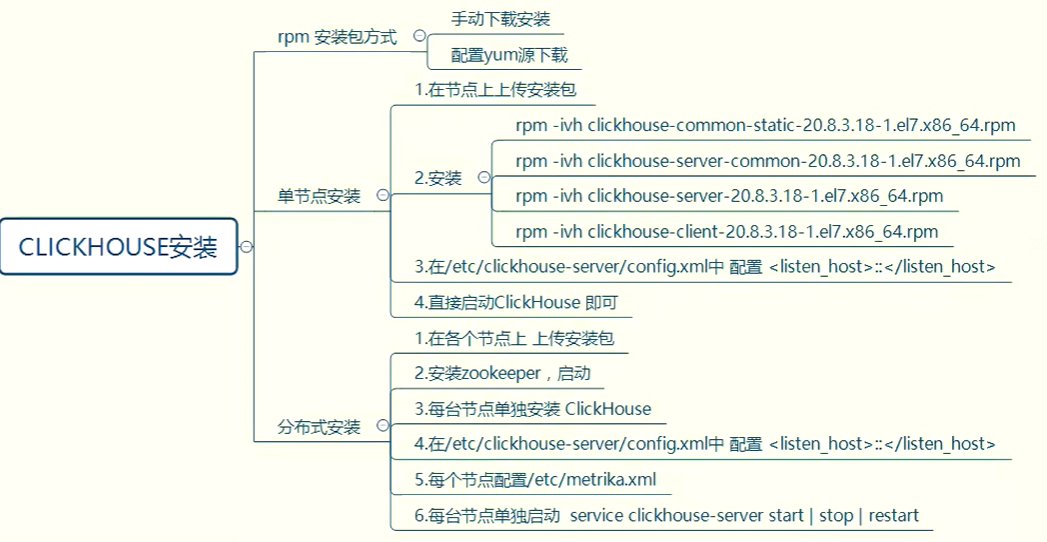
2.单节点安装
选择一台服务器,将下载好的 clickHouse 安装包直接安装即可,安装顺序如下
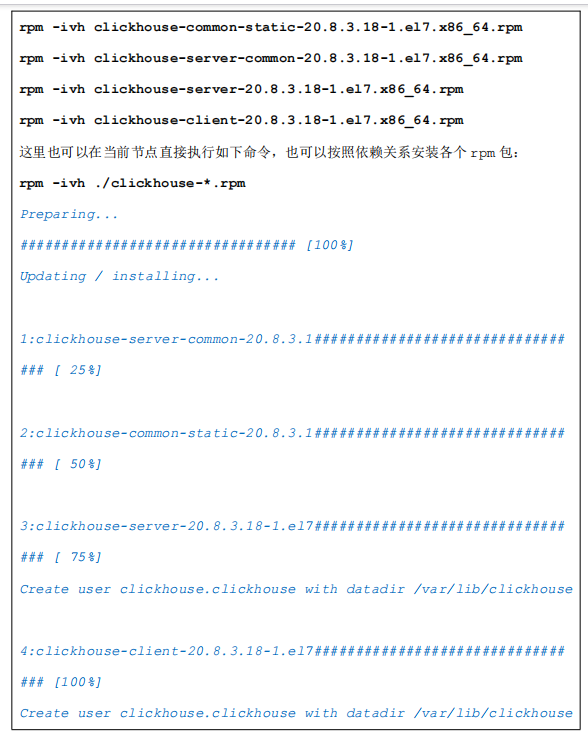
3.目录介绍
安装完成之后会生成如下对应的目录,每个目录的介绍如下:
-
/etc/clickhouse-server : 服务端的配置文件目录,包括全局配置 config.xml 和用户配置
users.xml。 -
/var/lib/clickhouse : 默认的数据存储目录,通常会修改,将数据保存到大容
量磁盘路径中。 -
/var/log/cilckhouse-server : 默认保存日志的目录,通常会修改,将数据保
存到大容量磁盘路径中。 -
在/usr/bin 下会有可执行文件:
clickhouse:主程序可执行文件
clickhouse-server:一个指向 clickhouse 可执行文件的软连接,供服务端启动使用。
clickhouse-client:一个指向 clickhouse 可执行文件的软连接,供客户端启动使用。
4.启动&停止服务
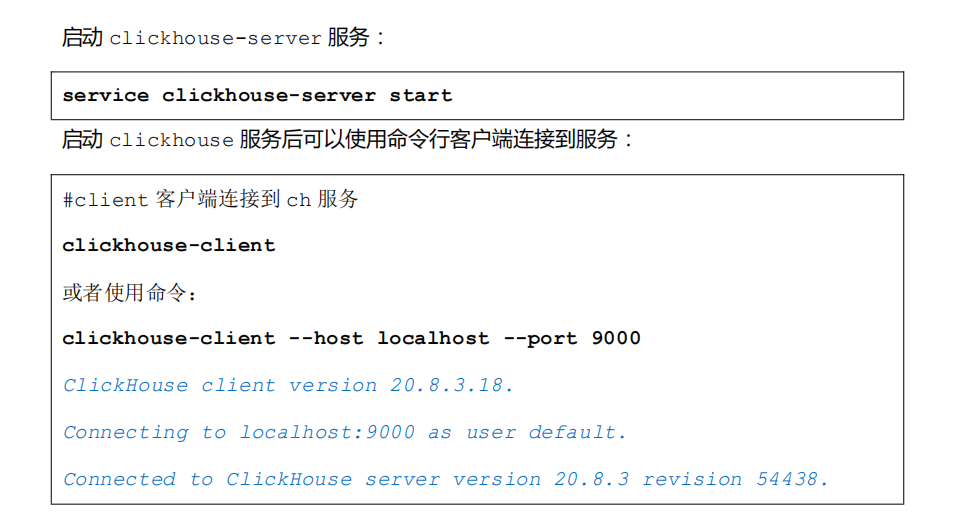


分布式安装
1.搭建步骤
Clickhouse 支持分布式搭建,搭建步骤如下:
- 选择三台 clickhouse 节点,在每台节点上安装 clickhouse 需要的安装包
这里选择 node1、node2,node3 三台节点,分别按照 clickhouse 单节点安装方式
在每台节点上安装 clickhouse。 - 安装 zookeeper 集群并启动。
搭建 Clickhouse 集群时,需要使用 Zookeeper 去实现集群副本之间的同步,所以
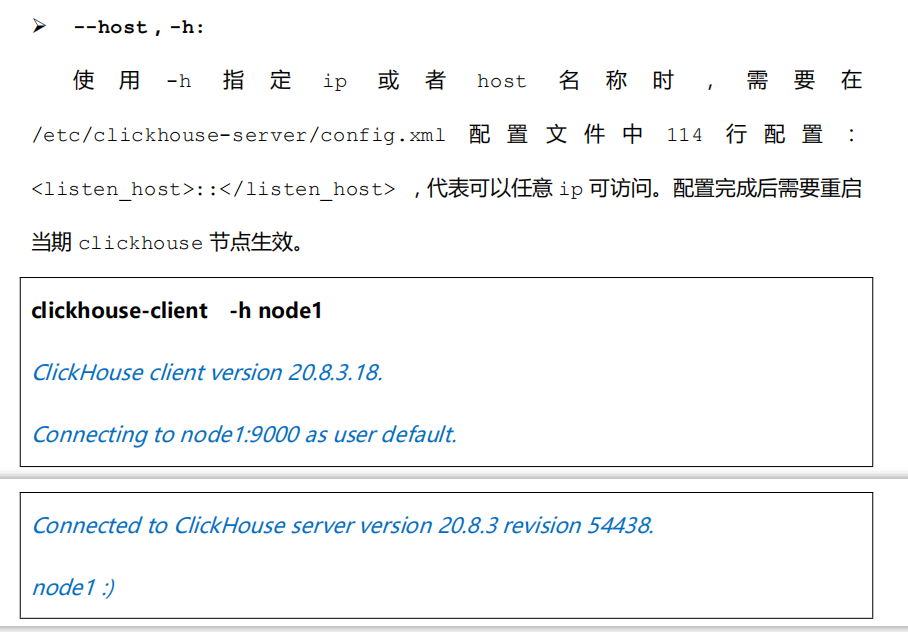
这里需要 zookeeper 集群,zookeeper 集群安装后可忽略此步骤。 - 配置外网可访问在每台 clickhouse 节点中配置/etc/clickhouse-server/config.xml 文件第114 行<listen_host>,如下:

- 在每台节点/etc/目录下创建 metrika.xml 文件,写入以下内容
在 node1、node2、node3 节点上/etc/下配置 metrika.xml 文件:vim /etc/metrika.xml:
<yandex><clickhouse_remote_servers><clickhouse_cluster_3shards_1replicas><shard><internal_replication>true</internal_replication><replica><host>node1</host><port>9000</port></replica></shard><shard><replica><internal_replication>true</internal_replication><host>node2</host><port>9000</port></replica></shard><shard><internal_replication>true</internal_replication><replica><host>node3</host><port>9000</port></replica></shard></clickhouse_cluster_3shards_1replicas></clickhouse_remote_servers><zookeeper-servers><node index="1"><host>node3</host><port>2181</port></node><node index="2"><host>node4</host><port>2181</port></node><node index="3"><host>node5</host><port>2181</port></node></zookeeper-servers><macros><replica>01</replica></macros><networks><ip>::/0</ip></networks><clickhouse_compression><case><min_part_size>10000000000</min_part_size><min_part_size_ratio>0.01</min_part_size_ratio><method>lz4</method></case></clickhouse_compression>
</yandex>
2. 配置项的解释:


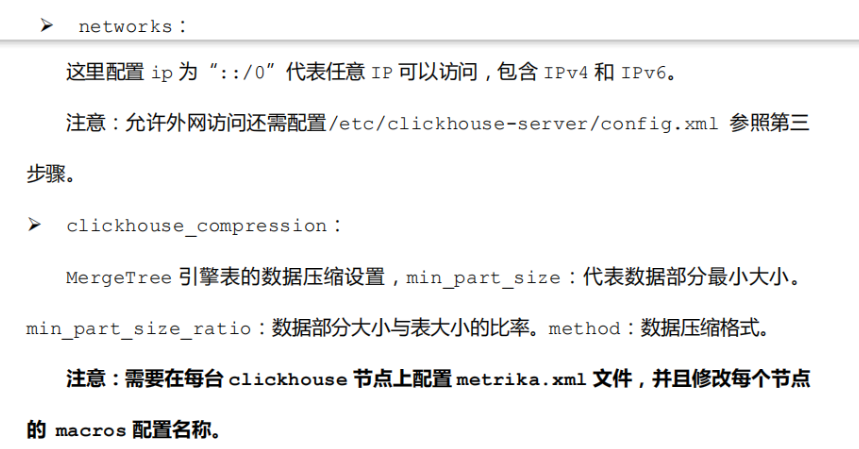
3.启动
在每台节点上启动 clickhouse 服务
- 首先启动 zookeeper 集群,然后分别在 node1、node2、node3 节点上启动clickhouse
服务,这里每台节点和单节点启动一样。启动之后,clickhouse 集群配置完成
service clickhouse-server start
检查集群配置是否完成
- 在 node1、node2、node3 任意一台节点进入 clickhouse 客户端,查询集群配置:

yum 安装
以上介绍 clickhouse 安装方式是下载好 rpm 包之后进行安装,我们也可以自己配置clickhouse 的 yum 源,直接使用 yum 命令进行安装,不过这个过程是从外网直接下载clickhouse 安装包之后自动进行安装。配置如下:
1. 添加官方存储库
选择需要安装 clickhouse 的节点执行如下命令,添加 clickhouse 的官方 yum 源:
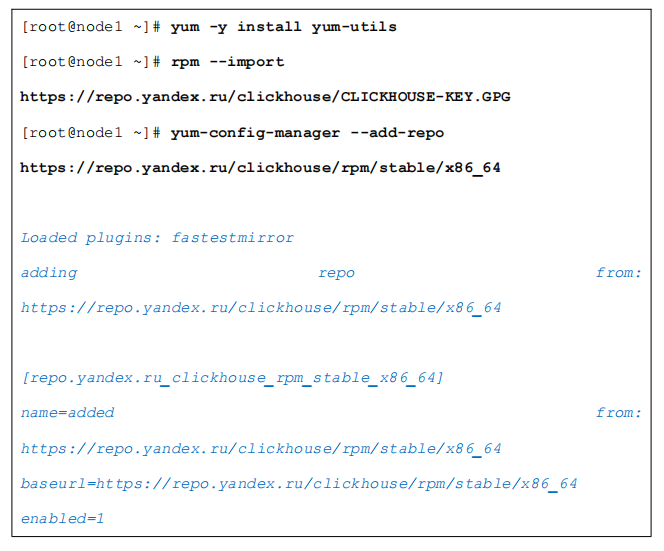
2. 安装 clickhouse server 和 client

3 小结
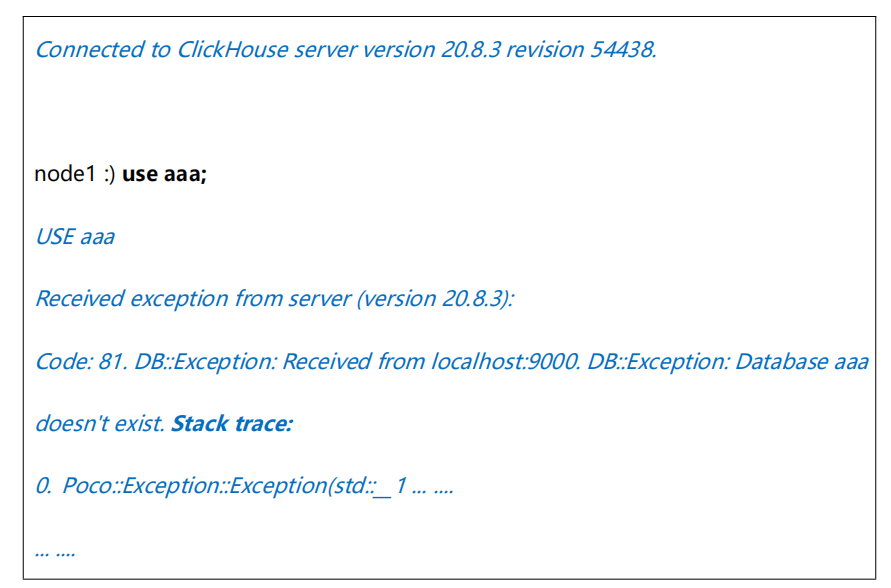
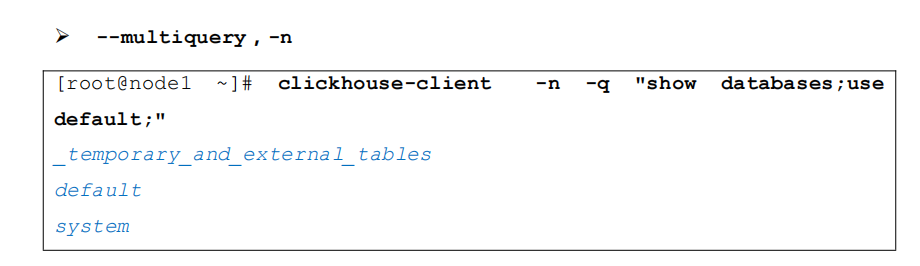
客户端命令行参数
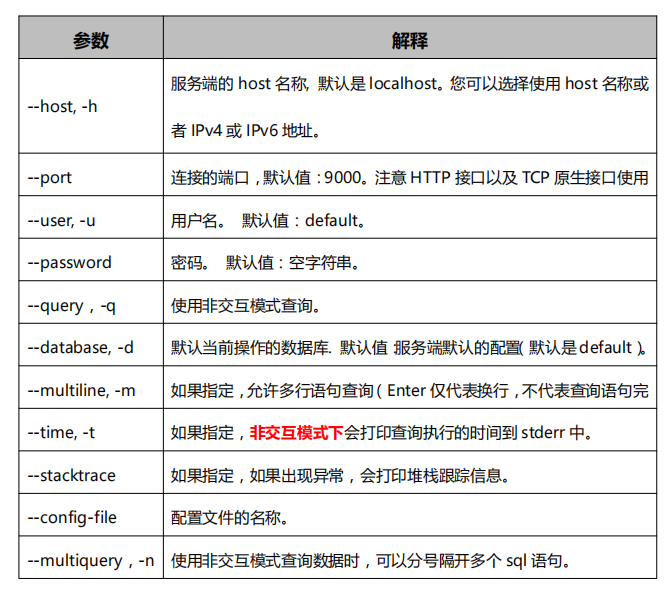
我们可以通过 clickhouse client 来连接启动的 clickhouse 服务,连接服务时,
- 我们可以指定以下参数,这里指定的参数会覆盖默认值和配置文件中的配置。