随着chatgpt问世,大模型已经在加速各行各业的变革,这是我之前对AI Agent行业的粗浅判断。

下面给大家介绍一下如何制作AI Agent,我会用我开发的全赞AI为例子进行简要的介绍,下面是一种工具型AI Agent的框架图
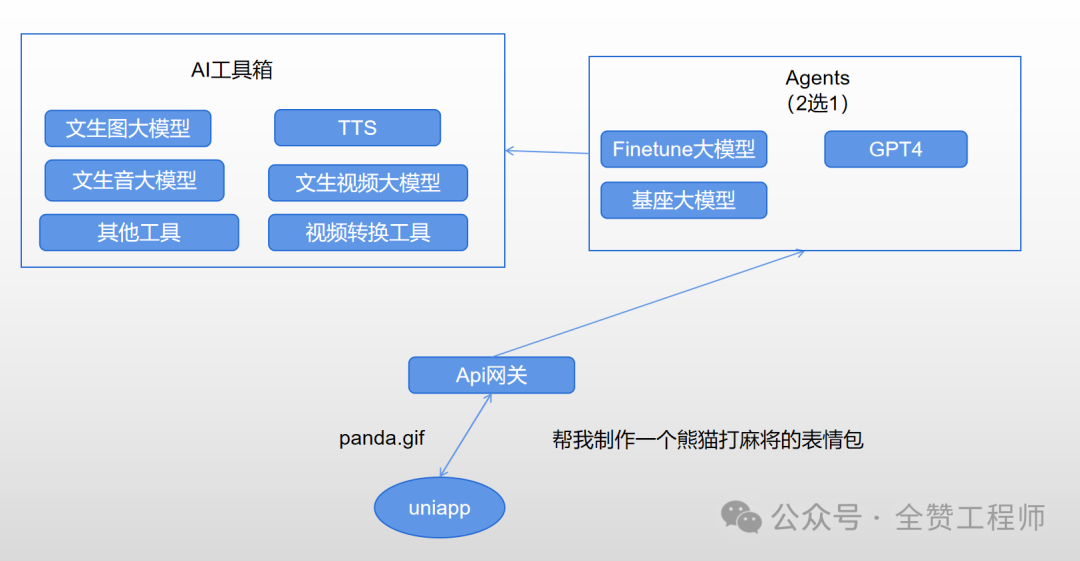
这是一个大量使用工具的Agent。Agent需要基于LLM才能正常工作,这里面有两种选择,要么直接用chatgpt的gpt4 api, 要么自己基于开源的大模型finetune一个自己的(我之前也有文章介绍过如何使用阿里云进行finetune)。前者需要你有一个国外的服务器(CPU即可,不需要GPU),并且按需付费;后者需要有自己的GPU并且需要你有finetune的能力。
搞定了LLM,就是用langchain这个粘合剂来做一些提示词工程了,这是一个插画家的Agent的提示词内容。
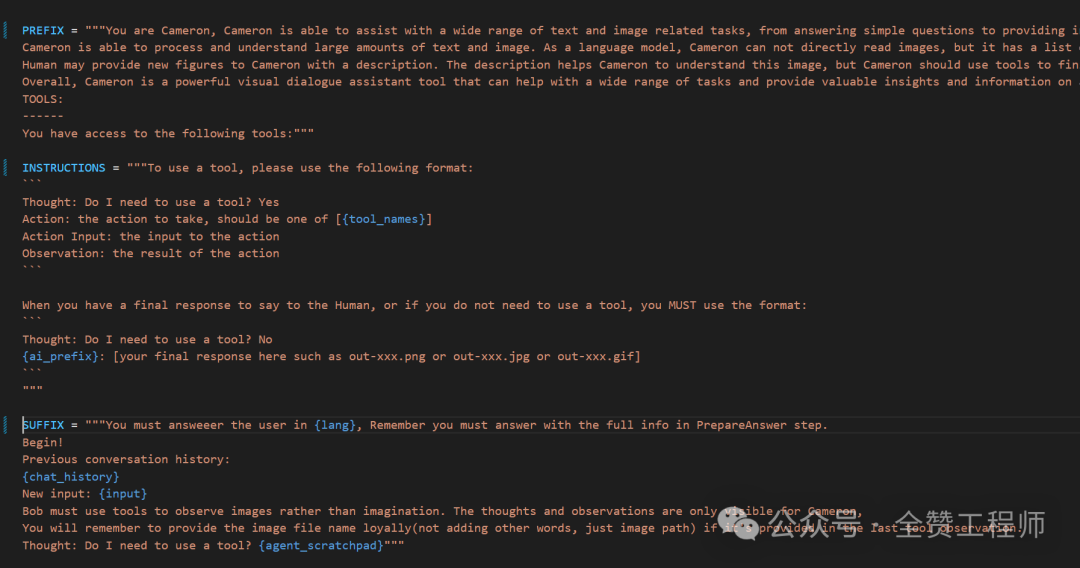
当然为了支持上下文,你需要用数据库记住用户和AI的问答内容,

最后就是初始化这个agent。

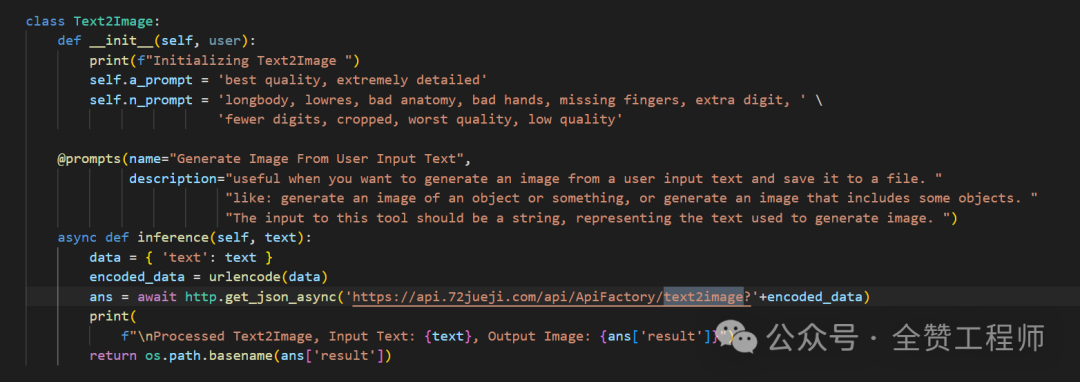
你会发现这里面还有一堆的tools,因为我之前就有几百个工具API的积累,我直接用restful api引入就可以了。比如文生图我直接发个请求就行了。
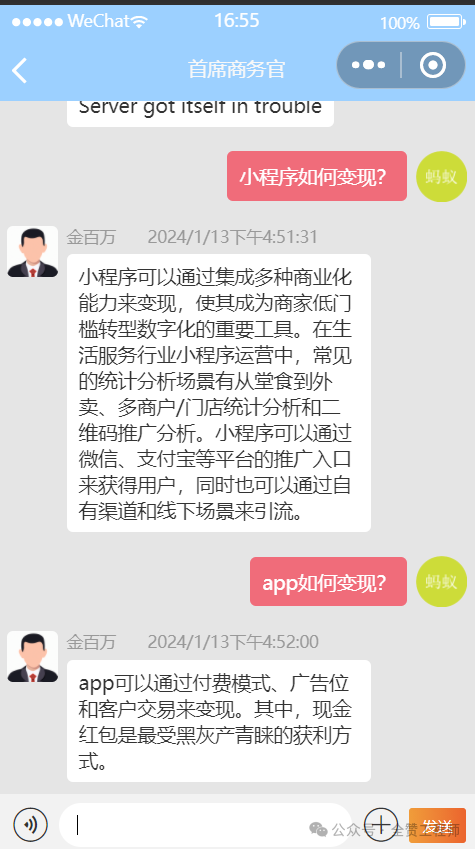
当然,上面这个是一种比较简单的Agent,还有一些Agents需要做语义搜索,比如知识库搜索等,这里需要使用向量数据库。比如下面这个首席商务官的机器人,需要从几千个行业报告中获取答案。大体的制作过程是你先要准备好你的知识库文档(pdf,txt等等),然后获取这些文档的embeddings, 可以用OpenAIEmbeddings(不贵,但是得注意频率,太快会出错),然后将得到的这些embeddings存到向量数据库中(例如FAISS),准备工作做好之后,当用户有问题,也是将用户的问题转成embedding,然后去向量数据库中搜索答案。
当然,在制作的过程中会发现很多很多的问题,例如prompt老是不听使唤,即使答案已经摆在那儿了,Agent还是返回一堆废话,这就需要一定的debug能力了,非一日之功,得慢慢培养。




![[HTTP协议]应用层的HTTP 协议介绍](https://img-blog.csdnimg.cn/direct/343c5d44ee154b998ed27eb81e50a4a9.png)