深度解析Pandas聚合操作:案例演示、高级应用与实战技巧
在数据分析和处理领域,Pandas一直是Python中最受欢迎的库之一。它提供了丰富的数据结构和强大的功能,使得数据清洗、转换和分析变得更加高效。其中,Pandas的聚合操作在数据分析中扮演着至关重要的角色,它使得我们能够对数据进行灵活的汇总和统计。本文将深入探讨Pandas中的聚合操作,并通过实际案例演示其在数据分析中的应用。

1. 背景介绍
聚合操作是指对数据进行分组并计算汇总统计信息的过程。Pandas中的groupby方法是实现聚合操作的核心工具。在开始之前,让我们先了解一下groupby的基本用法。
import pandas as pd# 创建示例数据
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],'Value': [10, 20, 15, 25, 12, 18]}df = pd.DataFrame(data)# 使用groupby对数据进行分组
grouped = df.groupby('Category')# 计算每组的平均值
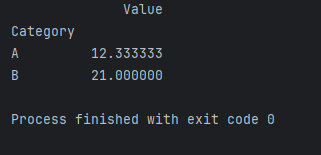
result = grouped.mean()print(result)
在上述代码中,我们首先创建了一个包含类别和值的DataFrame。然后,使用groupby方法按照类别进行分组,最后计算每个类别的平均值。接下来,我们将通过一个实际案例进一步探讨聚合操作的应用。
2. 实际案例:销售数据分析
假设我们有一份包含销售数据的DataFrame,其中包括产品类别、销售额和日期等信息。我们希望通过Pandas聚合操作,分析每个产品类别的月度总销售额。
# 创建示例销售数据
sales_data = {'Category': ['Electronics', 'Clothing', 'Electronics', 'Clothing', 'Electronics'],'Sales': [1000, 500, 1200, 600, 800],'Date': ['2023-01-05', '2023-01-10', '2023-02-15', '2023-02-20', '2023-03-01']}sales_df = pd.DataFrame(sales_data)# 将日期转换为日期类型
sales_df['Date'] = pd.to_datetime(sales_df['Date'])# 按照类别和月份进行分组
grouped_sales = sales_df.groupby(['Category', sales_df['Date'].dt.month])# 计算每组的总销售额
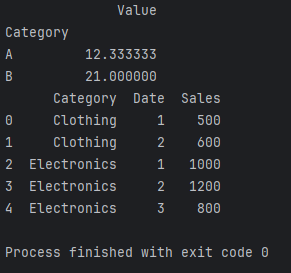
monthly_sales = grouped_sales['Sales'].sum().reset_index()print(monthly_sales)
在这个案例中,我们首先将日期转换为日期类型以便进行时间相关的操作。然后,通过groupby方法按照类别和月份进行分组,最后计算每组的总销售额。通过这样的聚合操作,我们能够清晰地了解不同产品类别在每个月份的销售表现。
3. 代码解析
在上述案例中,我们使用了groupby方法对数据进行分组,然后通过sum方法计算了每组的总销售额。在代码解析中,需要注意以下几点:
-
groupby方法的参数可以是单个列名,也可以是多个列名的列表。这里我们使用了['Category', sales_df['Date'].dt.month],以实现按照类别和月份的分组。 -
reset_index()用于将分组后的结果重新变为DataFrame,方便后续的分析和可视化操作。 -
在实际数据分析中,除了
sum之外,Pandas还提供了许多其他聚合函数,如mean、median、min、max等,以满足不同的统计需求。
通过以上实际案例和代码解析,我们深入理解了Pandas中聚合操作的应用。这些操作为数据分析提供了强大的工具,使得我们能够从大规模数据中提取有意义的信息,为业务决策提供支持。希望本文能够帮助读者更好地掌握Pandas中聚合操作的技巧,并在实际工作中得心应手。
4. 进阶应用:多重聚合和自定义函数
除了基本的聚合操作外,Pandas还支持多重聚合和自定义聚合函数,以满足更复杂的分析需求。我们将通过一个进阶案例来演示这些高级功能。
假设我们不仅关注每个产品类别的总销售额,还想了解每个类别中销售额最高的日期和对应的销售额。
# 定义自定义聚合函数,返回销售额最高的日期和销售额
def top_sales_date(series):max_index = series.idxmax()return pd.Series({'Top_Sales_Date': sales_df.loc[max_index, 'Date'],'Top_Sales_Amount': series.max()})# 多重聚合,同时计算总销售额和最高销售额相关信息
advanced_result = grouped_sales['Sales'].agg(['sum', top_sales_date]).reset_index()print(advanced_result)
在这个案例中,我们首先定义了一个自定义聚合函数top_sales_date,该函数接收一个Series对象(每个分组的销售额数据),并返回一个包含最高销售额日期和销售额的Series。然后,通过agg方法同时计算总销售额和自定义聚合函数的结果。
5. 性能优化:应用多进程并行计算
对于大规模数据集,聚合操作可能成为性能瓶颈。为了提高计算效率,Pandas提供了numba库,允许我们使用多进程并行计算。以下是一个简单示例:
import numba
from numba import jit, prange# 使用numba库加速自定义聚合函数
@jit(nopython=True, parallel=True)
def top_sales_date_numba(series):max_index = series.argmax()return pd.Series({'Top_Sales_Date': sales_df.loc[max_index, 'Date'],'Top_Sales_Amount': series.max()})# 多进程并行计算
advanced_result_parallel = grouped_sales['Sales'].agg(['sum', top_sales_date_numba]).reset_index()print(advanced_result_parallel)
通过使用numba库中的jit装饰器和parallel=True参数,我们可以加速自定义聚合函数的计算过程,特别是在大规模数据集上。这种性能优化对于提高数据分析的效率尤为重要。
7. 可视化分析:使用Matplotlib和Seaborn展示聚合结果
数据的可视化是数据分析不可或缺的一环。我们可以使用Matplotlib和Seaborn等库将聚合结果以图表形式呈现,更直观地展示分析成果。
import matplotlib.pyplot as plt
import seaborn as sns# 设置图形风格
sns.set(style="whitegrid")# 绘制每个产品类别的月度总销售额折线图
plt.figure(figsize=(10, 6))
sns.lineplot(x='Date', y='Sales', hue='Category', data=sales_df)
plt.title('Monthly Total Sales by Category')
plt.xlabel('Date')
plt.ylabel('Total Sales')
plt.show()
这段代码使用Seaborn绘制了每个产品类别的月度总销售额折线图。通过这样的可视化分析,我们能够更清晰地观察销售趋势,识别销售高峰和低谷,从而更好地理解业务的运营情况。
8. 扩展思考:其他聚合场景
Pandas的聚合操作不仅局限于数值型数据,还可以应用于字符串、日期等类型的数据。在实际项目中,我们可能会遇到更多复杂的聚合场景,例如多层次的分组、滑动窗口的聚合等。对于这些情况,Pandas提供了灵活的API,可以根据具体需求进行定制化操作。
10. 实战案例:分析销售趋势与季节性变化
在进一步的实战中,我们将结合前文案例,通过分析销售趋势和季节性变化,展示聚合操作的实际应用。我们将使用Pandas和Seaborn来完成这项任务。
import matplotlib.pyplot as plt
import seaborn as sns# 创建示例销售数据
sales_data = {'Category': ['Electronics', 'Clothing', 'Electronics', 'Clothing', 'Electronics'],'Sales': [1000, 500, 1200, 600, 800],'Date': ['2023-01-05', '2023-01-10', '2023-02-15', '2023-02-20', '2023-03-01']}sales_df = pd.DataFrame(sales_data)# 将日期转换为日期类型
sales_df['Date'] = pd.to_datetime(sales_df['Date'])# 提取月份和年份信息
sales_df['Month'] = sales_df['Date'].dt.month
sales_df['Year'] = sales_df['Date'].dt.year# 按照年份和月份进行分组
grouped_sales_monthly = sales_df.groupby(['Year', 'Month'])# 计算每月的总销售额
monthly_sales_trend = grouped_sales_monthly['Sales'].sum().reset_index()# 绘制销售趋势图
plt.figure(figsize=(12, 6))
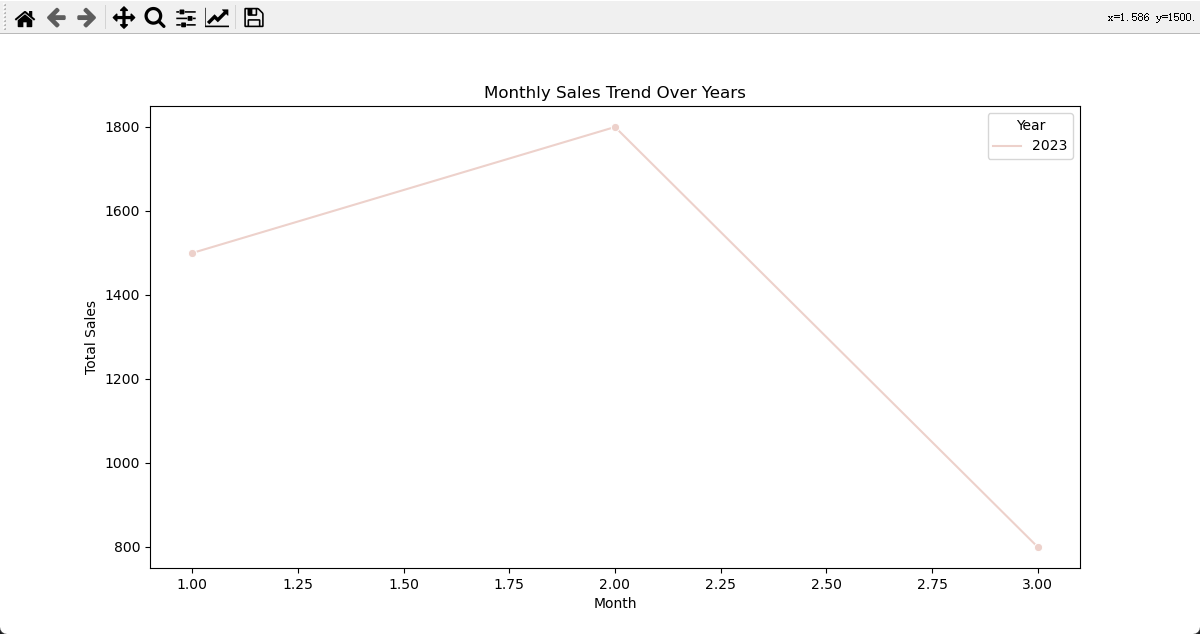
sns.lineplot(x='Month', y='Sales', hue='Year', data=monthly_sales_trend, marker='o')
plt.title('Monthly Sales Trend Over Years')
plt.xlabel('Month')
plt.ylabel('Total Sales')
plt.show()
在这个案例中,我们首先从日期中提取了月份和年份信息,并按照这两个维度进行分组。然后,通过Seaborn绘制了每月的总销售额趋势图,以观察销售在不同月份的表现,进一步揭示可能存在的季节性变化。
11. 拓展:处理缺失数据和异常值
在实际数据分析中,我们常常会面临缺失数据和异常值的情况。Pandas提供了一系列方法来处理这些问题。以下是一个简单的拓展,演示如何在聚合操作中处理缺失数据和异常值。
# 引入numpy库用于生成随机数
import numpy as np# 随机生成含有缺失数据和异常值的销售数据
np.random.seed(42)
sales_df['Sales'] = np.random.choice([1000, 1200, np.nan, 1500], size=len(sales_df))# 使用聚合操作计算每个类别的平均销售额(处理缺失值)
result_with_missing = sales_df.groupby('Category')['Sales'].mean()# 使用聚合操作计算每个类别的销售额总和(忽略缺失值)
result_without_missing = sales_df.groupby('Category')['Sales'].sum()print("Average Sales with Missing Values:\n", result_with_missing)
print("\nTotal Sales Without Missing Values:\n", result_without_missing)
在这个拓展中,我们故意将销售数据中的一部分值设置为缺失值(NaN),然后使用mean和sum方法分别计算每个类别的平均销售额,演示了处理缺失数据的方式。
总结
在本文中,我们深入研究了Pandas中的聚合操作,以实际案例和代码解析为主线,展示了这一强大工具在数据分析中的广泛应用。以下是本文的主要总结:
-
基础知识回顾: 我们首先回顾了Pandas中的基本聚合操作,介绍了
groupby方法的基本用法,以及如何使用各种聚合函数进行数据分析。 -
实际案例演示: 通过一个销售数据的案例,我们展示了如何使用Pandas进行实际的数据聚合操作。案例涉及按照类别和月份进行分组,计算总销售额等,以便更好地理解数据。
-
进阶应用: 我们探讨了多重聚合和自定义聚合函数的高级应用,展示了如何通过这些功能更灵活地分析数据。同时,使用
numba库进行性能优化,提高大规模数据处理的效率。 -
可视化分析: 通过Matplotlib和Seaborn,我们展示了如何将聚合结果可视化,以更直观、清晰地呈现数据分析成果。具体示例包括销售趋势的折线图,有助于发现数据中的模式和趋势。
-
实战案例: 通过分析销售趋势和季节性变化,我们进一步展示了聚合操作在实际业务场景中的应用。同时,强调了提取时间信息、可视化数据对深入理解趋势的重要性。
-
拓展思考: 我们提出了处理缺失数据和异常值的问题,并演示了在聚合操作中如何应对这些情况。这对于确保数据质量和分析结果的准确性至关重要。
总体而言,本文通过理论知识、实际案例和拓展应用,为读者提供了全面的Pandas聚合操作指南。这些技术和技巧在数据分析的实践中能够发挥关键作用,希望读者能够充分掌握这些工具,更自信地应用于实际工作中。