数据库管理150期 2024-02-12
- 数据库管理-第150期 Oracle Vector DB & AI-02(20240212)
- 1 LLM
- 2 LLM面临的挑战
- 3 RAG
- 4 向量数据库+LLM
- 总结
数据库管理-第150期 Oracle Vector DB & AI-02(20240212)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Associate: Database(Oracle与MySQL)
网思科技 DBA总监
10年数据库行业经验,现主要从事数据库服务工作
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP、认证技术专家,ITPUB认证专家,OCM讲师
圈内拥有“总监”、“保安”、“国产数据库最大敌人”等称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸;CSDN:胖头鱼的鱼缸(尹海文);墨天轮:胖头鱼的鱼缸;ITPUB:yhw1809。
除授权转载并标明出处外,均为“非法”抄袭。
本来这一期是昨天要写的,但是昨天睡了很久,加上薛首席携老婆孩子来成都旅游,出去接待了一下,因此没有写。

首席还是那么帅气,今天继续,讲讲LLM。
1 LLM
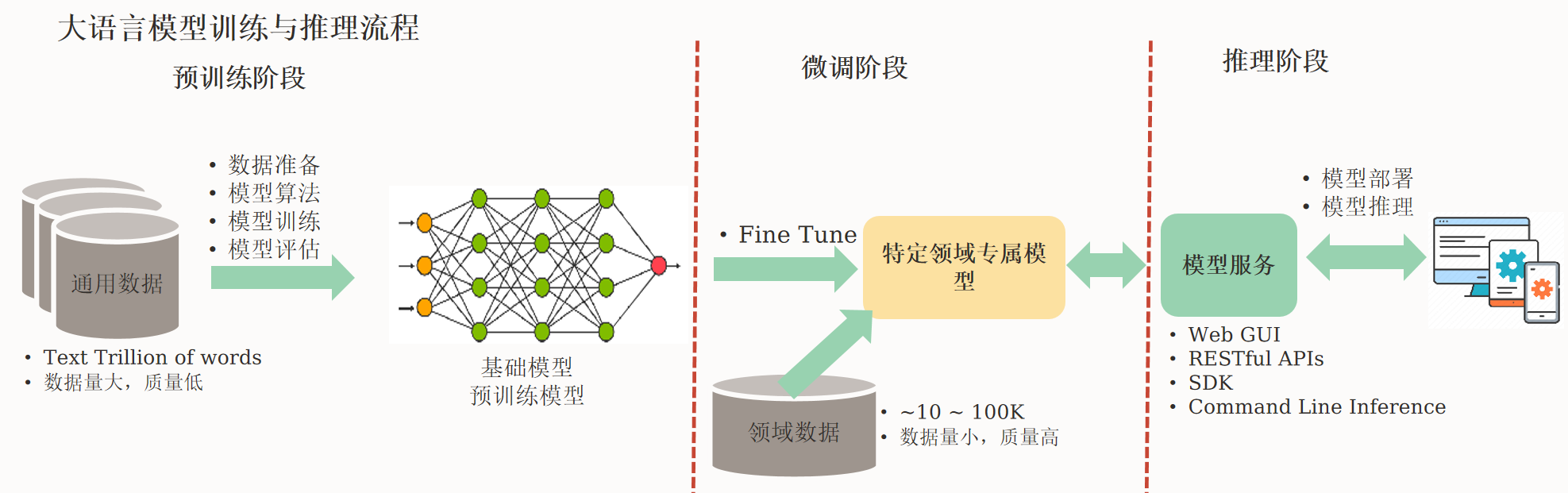
Large Language Model,大语言模型,是生成式AI的一个类型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,单一模型可以执行广泛的任务,包括词法分析、文本分类、命名实体识别、关键词提取、翻译、情感分析、摘要、对话、写作文、写代码等。
2 LLM面临的挑战
大预言模型面临的最大挑战即是幻觉(hallucinations)和过时信息,LLM训练集来自互联网的通用数据,基于某个时间点的数据快照。因此会出现以下一些问题:
- 结果正确性不可控:提示不精准或不完善(即互联网通用数据中存在大量不精准甚是是错的的内容)
- 结果是过时的信息:模型更新成本高(即LLM训练出结果即过时,因为互联网通用数据是实时变化的)
- 结果是通用信息:难以与企业或某领域特定专业数据相关(一些特殊专用场景无法使用通用信息里匹配,需要专业信息加持)
3 RAG
Retrieval-Augmented Generation,检索式增强生成方法,从企业专业知识库中检索与请求最相关的信息,并与用户请求捆绑一起作为提示,发送给LLM以获得响应。
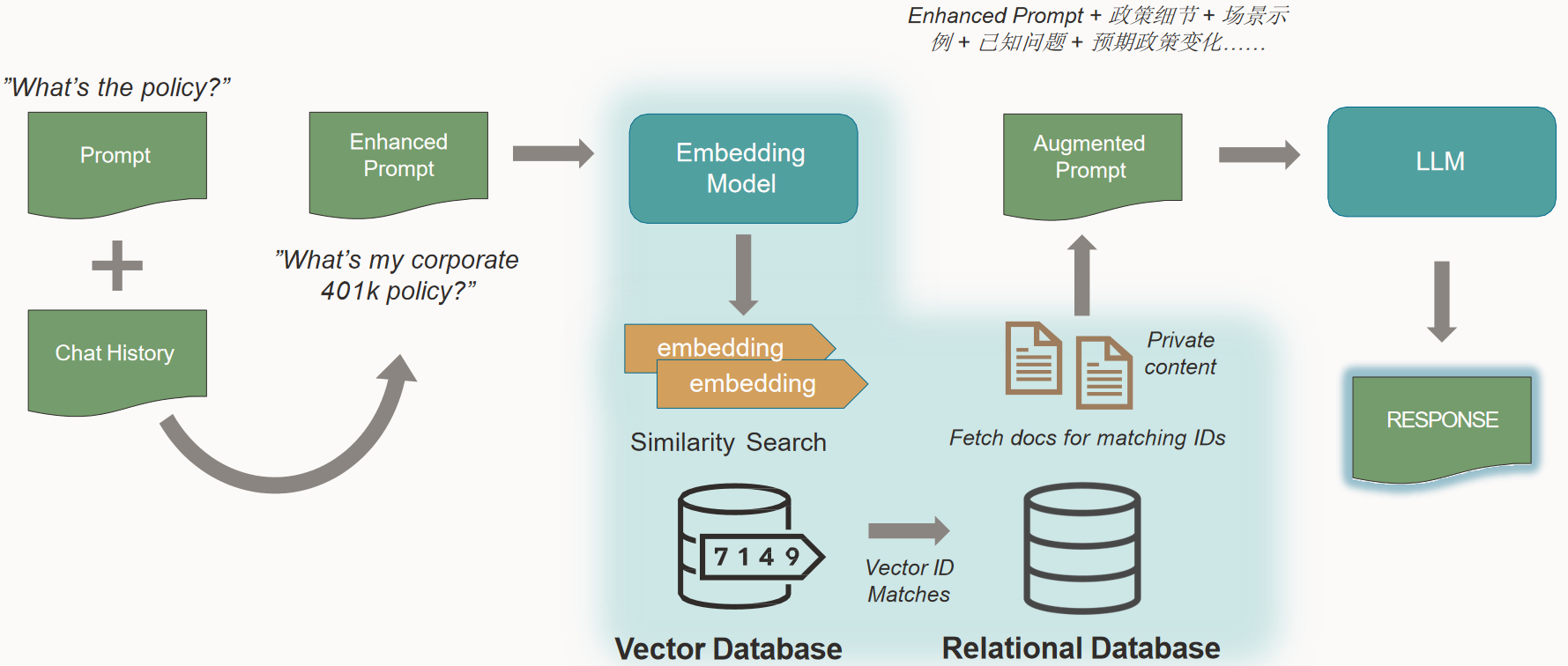
同时,包括AI聊天等功能,也可以创建专用的知识库,来增加聊天的能力,比如更强的上下文理解能力,或者更平稳柔和倾向于人类的语言沟通。
4 向量数据库+LLM
RAG让LLM不用重新训练就能够获取最新的信息,基于RAG产生更可靠更专业的输出。实施RAG需要向量数据库等技术,这些技术可以快速嵌入新数据,快速搜索数据并输入给LLM。
- 幻觉问题:向量数据库可以为LLM创建一个长期记忆的数据库,为LLM提供可靠的信息源。LLM以此信息作为基础,从而减少模型产生幻觉的可能性。
- 专业领域:通过将权威、可信的信息转换为向量,并将它们加载到向量数据库中。用企业相关特定内容增强提示,以使LLM产生更专业的答案。
- 令牌(Token)限制:通过使用最相关的内容避免超出 LLM 令牌限制。(访问安全)
- 数据安全:避免使用敏感的私域客户数据进行LLM训练和微调。
- 知识更新:向量数据库作为LLM的实时更新的知识库。
- 成本:比微调LLM便宜,微调LLM更新模型费用可能很高。
- 缓存:缓存以前的 LLM 提示/回答以提高性能并降低成本。
总结
本期简单讲解了一下LLM的相关信息,下一期将正式进入Oracle Vector DB的相关内容。
老规矩,知道写了些啥。


![[计算机网络]---网络编程套接字](https://img-blog.csdnimg.cn/direct/9ba6711f9d244203bf22160cc92332a5.png)