文章目录
- 底层结构概述
- 扩容机制
- 浅拷贝与深拷贝
- 插入和删除的效率
- 浅谈VS和g++的优化
- 总结
底层结构概述
string可以帮助我们很好地管理字符串,但是你真的了解她吗?事实上,string的设计是非常复杂的,拥有上百个接口,但最常用的就那几个。如果不了解string的底层,就很难优雅地写出高效的代码!
要想高效地管理一个string类,至少需要3个成员变量,分别是:
char* _str;
size_t _size;
size_t _capacity;
比如要存储字符串"abcde",那么_str指向了a,_size=5表示有5个有效字符(不包括’\0’),_capacity=8表示当前空间最多存储8个字符(实际上是9个,因为有’\0’)。此时,_str就是c_str的返回值,_size就是size的返回值,_capacity就是capacity的返回值;堆区上的空间总大小是9个字节,最多保存除了’\0’之外的8个字符,换句话说,当前再插入3个字符,空间就满了,需要扩容。
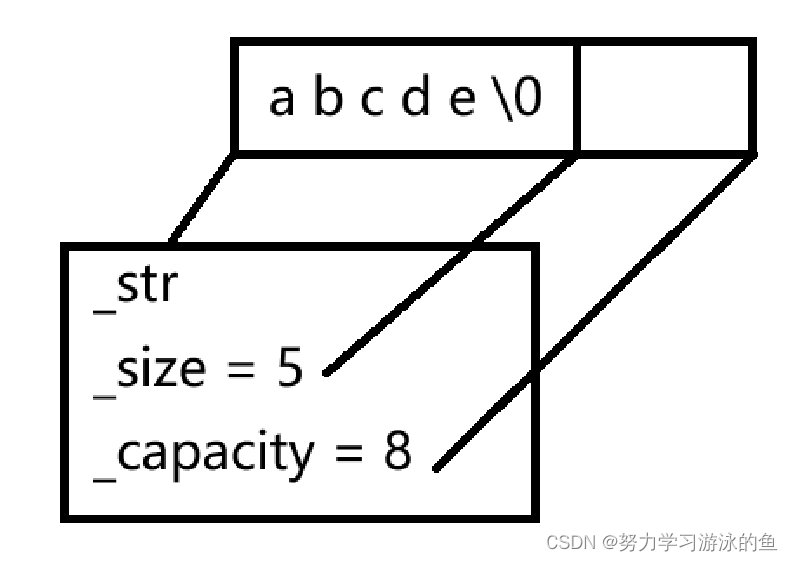
扩容机制
_str指向的空间是动态开辟出来的,当容量不够用时,会扩容。扩容的步骤是:
- 申请新空间。
- 把旧空间的数据拷贝到新空间中。
- 释放旧空间。
设想一下,当字符串很长时,第2步的拷贝代价就会非常大。所以,我们要想方设法地减少甚至避免扩容!
假设我们要反复地插入字符,插入100次,容量会怎么变化呢?
#include <iostream>
#include <string>
using namespace std;int main()
{string s;size_t capacity = s.capacity();cout << "init: capacity = " << capacity << endl;for (size_t i = 0; i < 100; i++){s.push_back('x');if (s.capacity() != capacity){capacity = s.capacity();cout << "new: capacity = " << capacity << endl;}}return 0;
}
VS2022运行结果:

可以观察到,一开始容量是15,第一次扩容为原来容量的2倍,后面每次扩容都为原来容量的1.5倍。
g++运行结果:
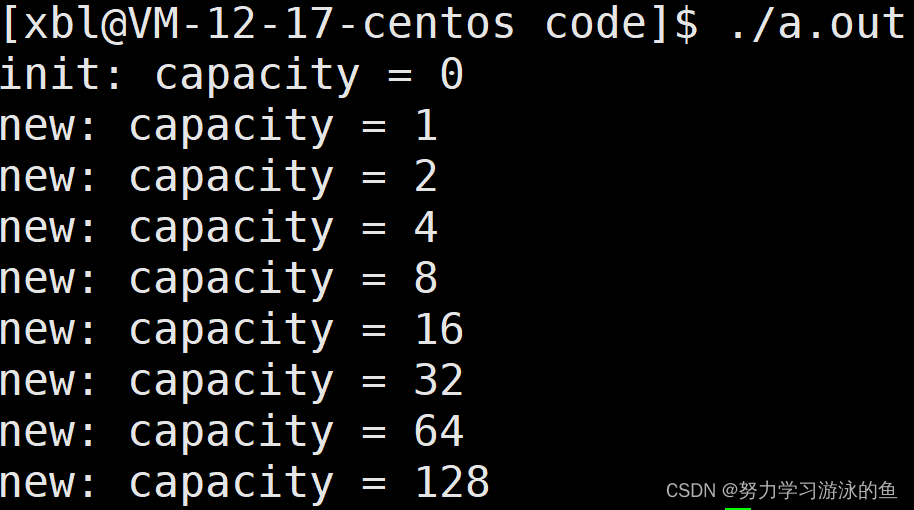
可以观察到,每次扩容都是原来容量的2倍。
如果我们能提前知晓,即将插入100个字符,就可以调用reserve,提前保留足够的空间,从而避免扩容的消耗!
#include <iostream>
#include <string>
using namespace std;int main()
{string s;// 提前开空间,从而避免扩容的消耗!s.reserve(100);size_t capacity = s.capacity();cout << "init: capacity = " << capacity << endl;for (size_t i = 0; i < 100; i++){s.push_back('x');if (s.capacity() != capacity){capacity = s.capacity();cout << "new: capacity = " << capacity << endl;}}return 0;
}
VS2022运行结果:

g++运行结果:

浅拷贝与深拷贝
string是如何拷贝的呢?
如果不写拷贝构造函数,编译器会生成默认的拷贝构造函数,对内置类型按照字节拷贝,这种拷贝称作浅拷贝!
举个例子,有一个string s1的结构如下:
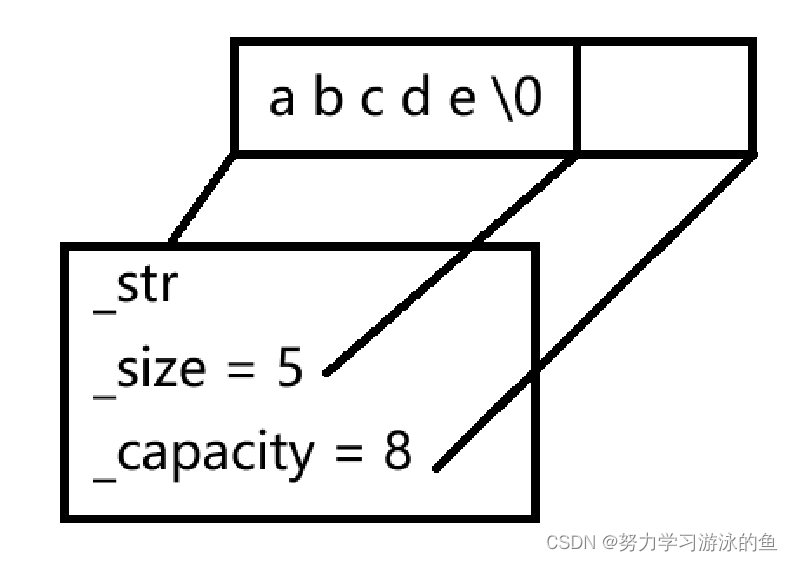
此时来了另一个string s2,把s1的_str,_size和_capacity都拷贝过去,此时两个string的_str就指向了同一块空间!
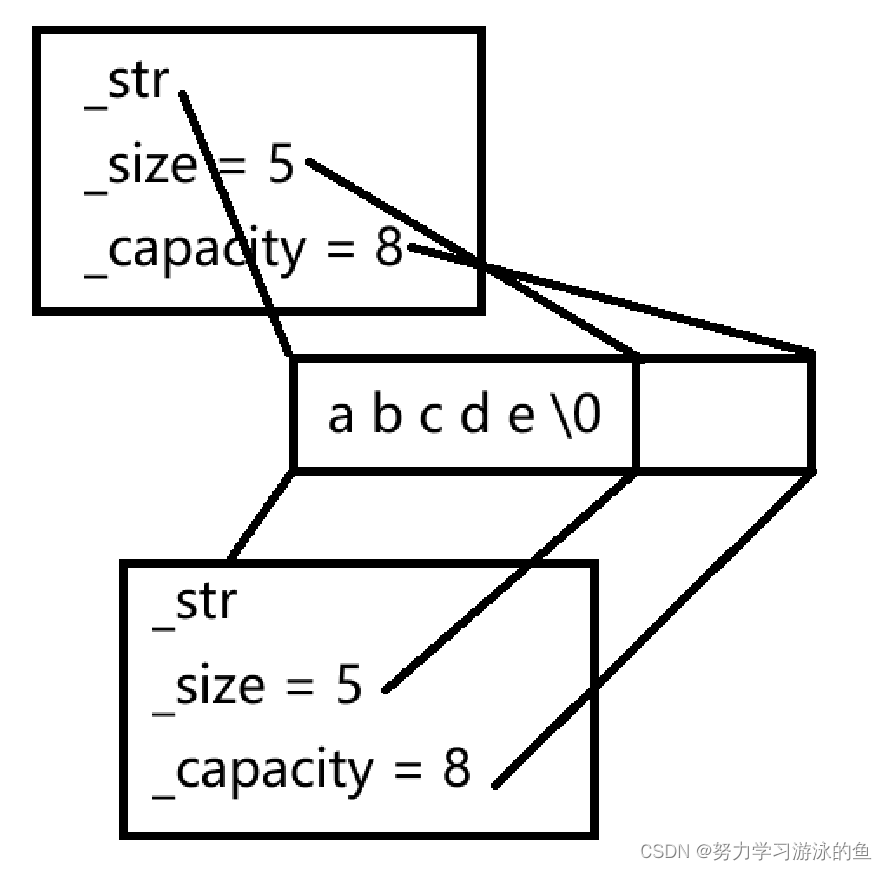
此时,如果我们修改其中一个string,另一个string也会同时被修改!更可怕的是,当对象的生命周期结束时,会调用析构函数,由于两个string中的_str存储的是同一个地址,这个地址就会被delete两次,从而导致进程崩溃!
为了解决这个问题,string必须实现深拷贝!也就是说,我们需要重新申请一块空间,把"abcde"拷贝过去,让s2的_str指向新的空间!
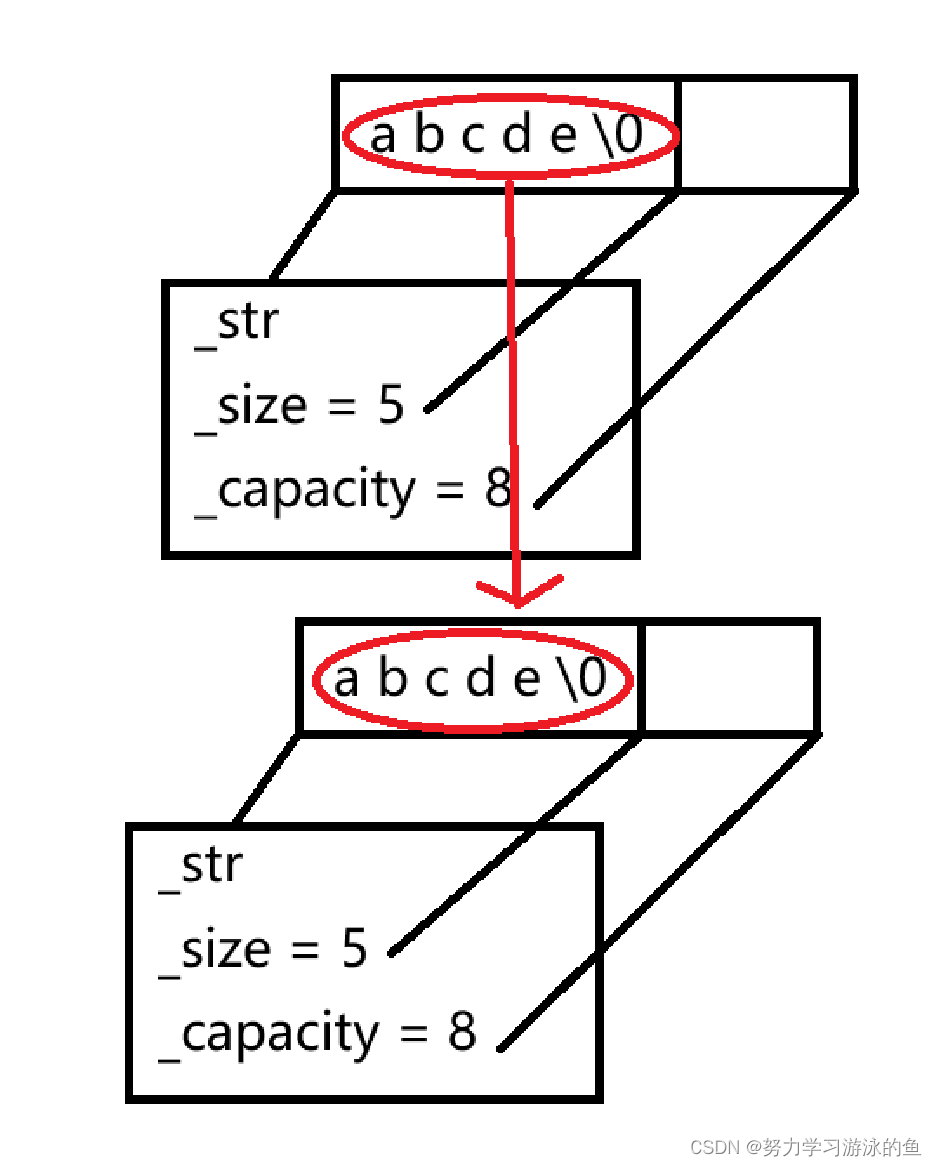
这样,修改其中一个string就不会影响另一个string,而且两个string的_str指向不同的空间,不会出现同一块空间释放两次的问题了!
插入和删除的效率
如果要在字符串尾部插入一个字符,底层是如何实现的呢?只需要在_str[_size]的位置插入字符,再让_size++,最后再填一个’\0’即可!
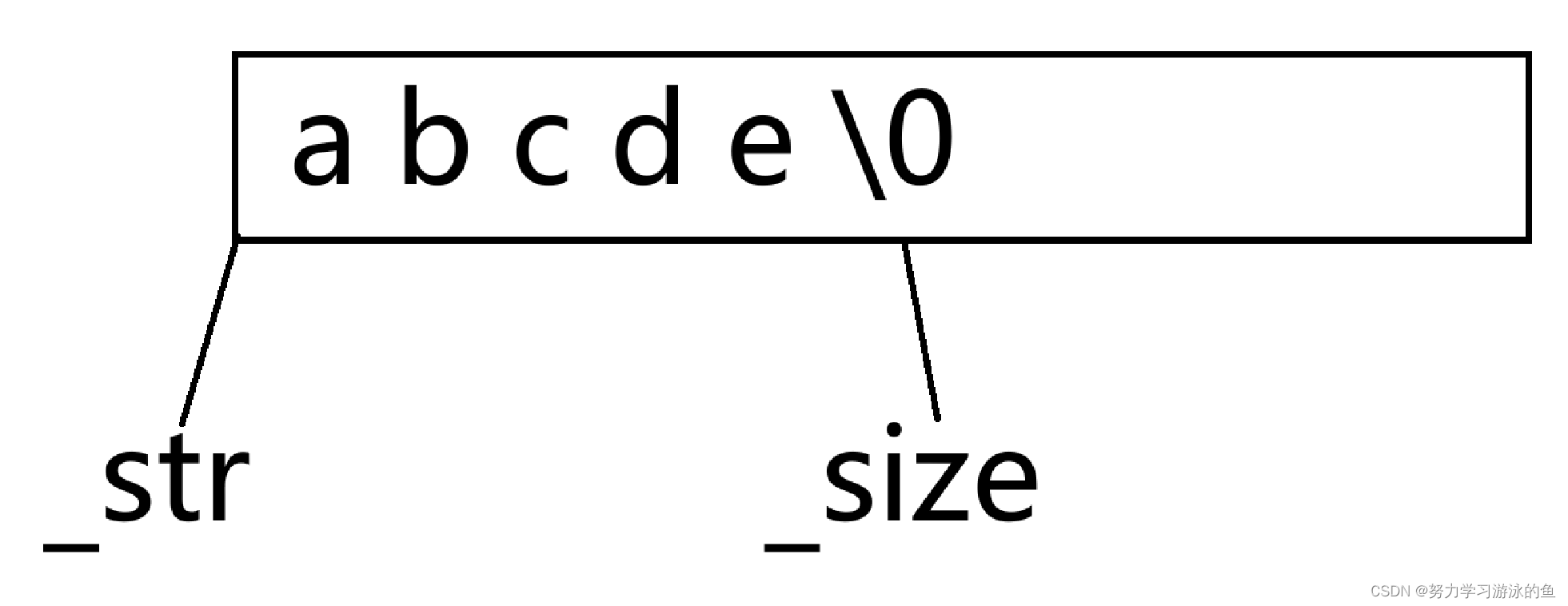
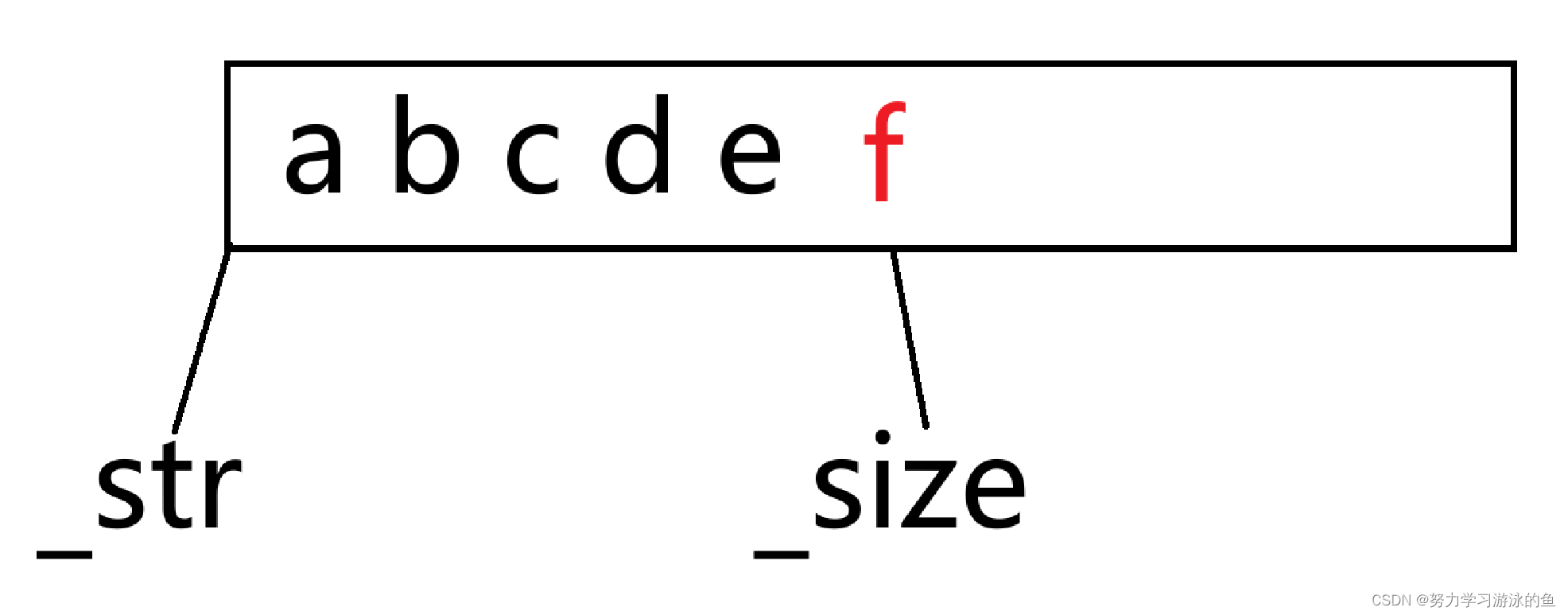
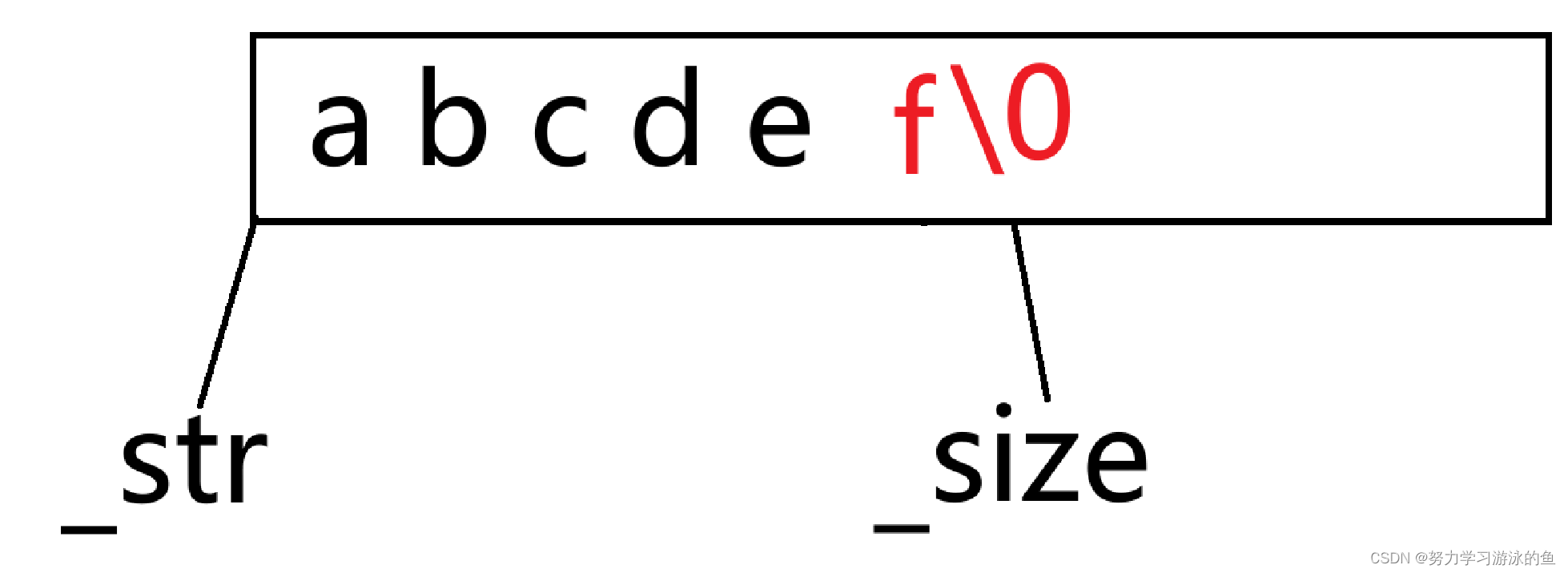
当然,如果插入前,_size==_capacity,说明空间不够用了,要扩容!扩容的逻辑前面讲过,这里不再重复。
但是如果要在中间插入一个字符呢?甚至在头部插入呢?就要先挪动数据腾出空间,才能插入!
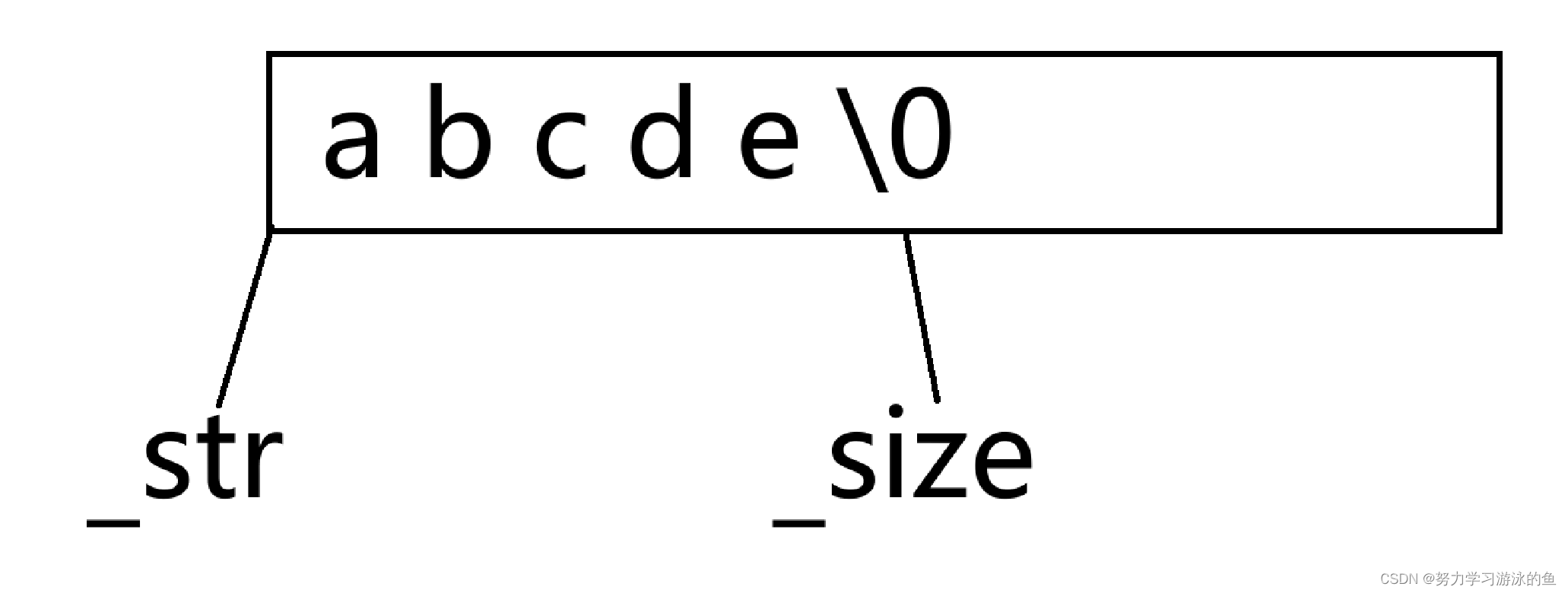
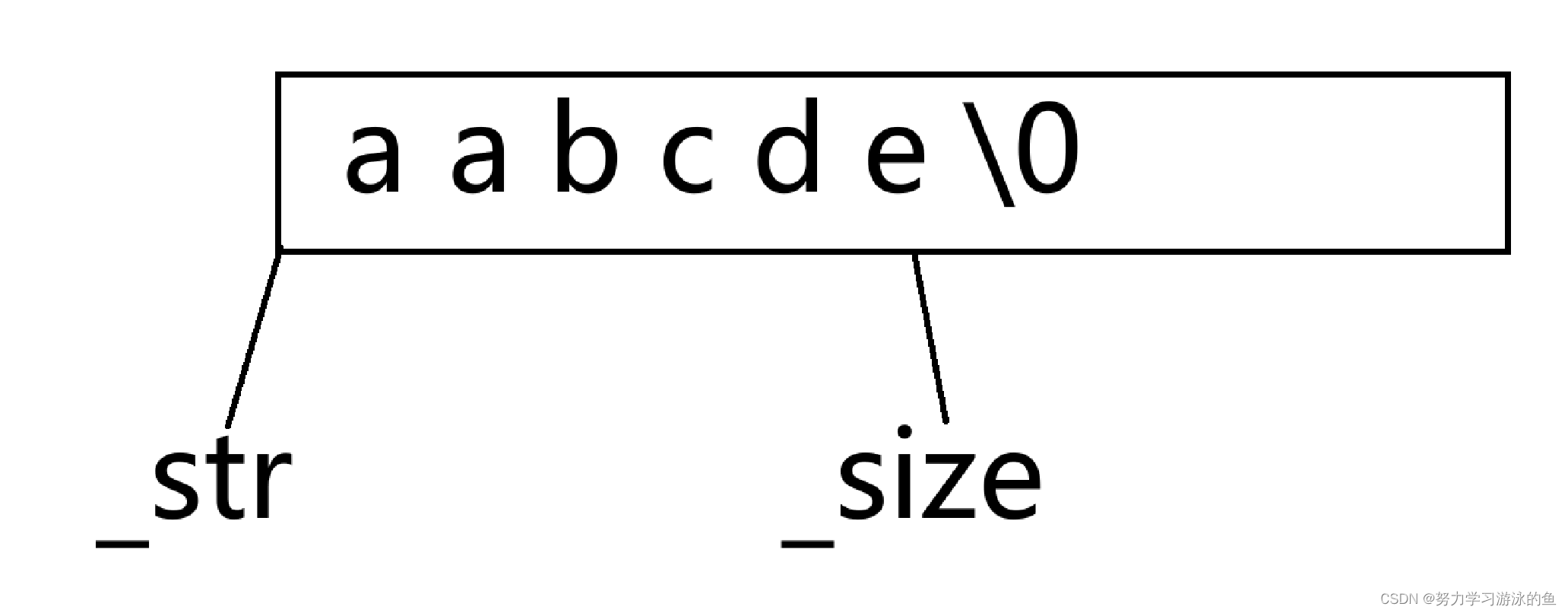
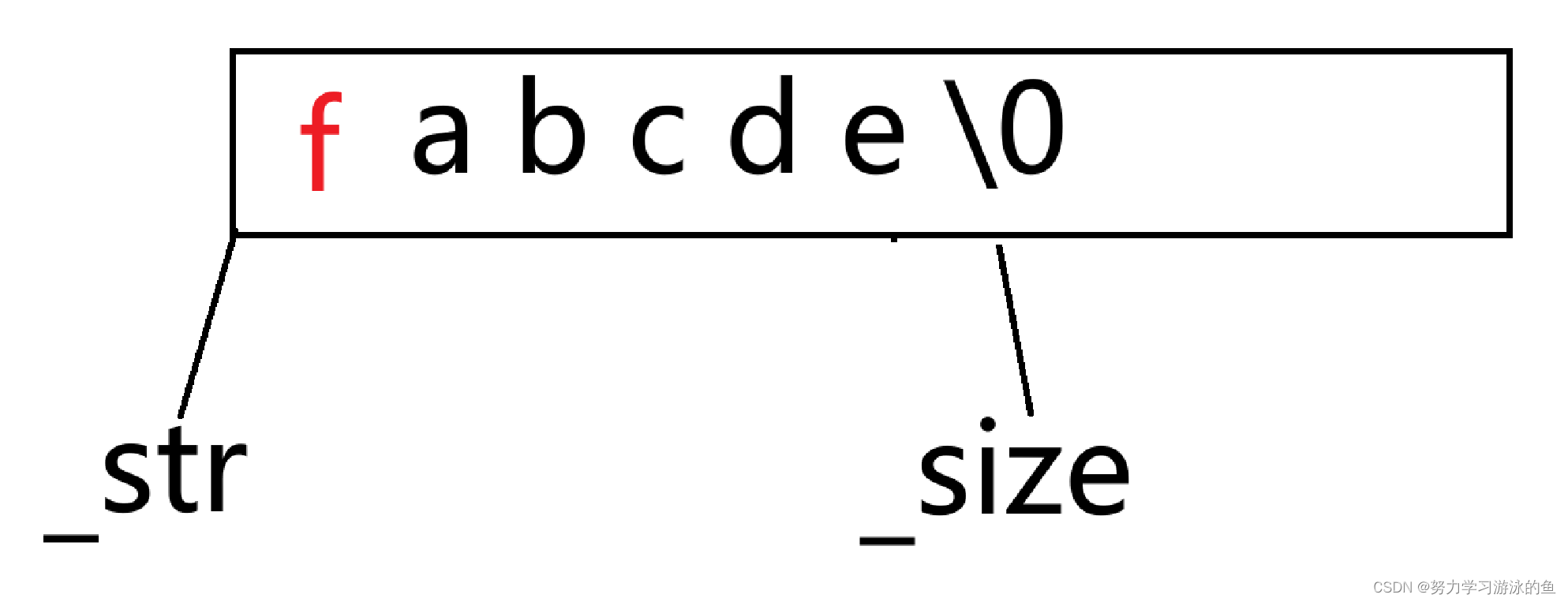
比起在尾部插入数据,多出了挪动数据的消耗,所以应尽可能地少在string的头部或中间插入数据!
同理,如果要删除头部或中间的数据,也要挪动数据覆盖删除,所以应尽可能地避免删除头部或中间的数据!
浅谈VS和g++的优化
VS2022的X86环境下,一个string类对象的大小是28字节;X64环境下,大小是40个字节。32位环境下,char*大小是4字节,size_t大小是4字节,那么_str,_size,_capacity的总大小是12字节;64位环境下,char*大小是8字节,size_t大小是8字节,那么_str,_size,_capacity的总大小是24字节。那么,剩下还有16字节去哪了呢?
观察一下监视窗口:
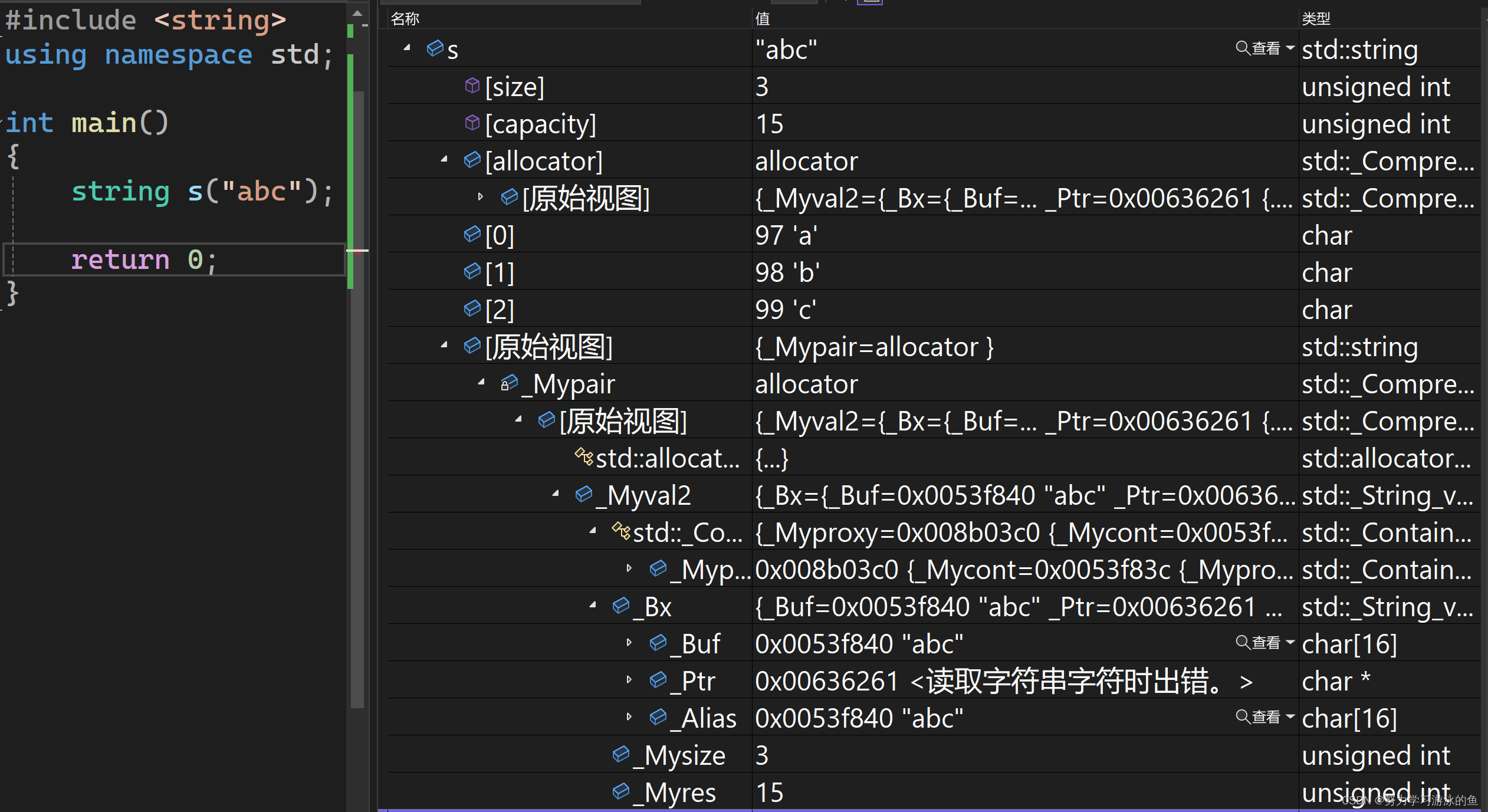
注意到有一个char[16]类型的数组_Buf。也就是说,VS在栈区上也申请了一块空间,长度是16个字节,当字符串的size<=15时,就存储在这个数组中;当size>15时,才会存储到堆区,这是为了减少堆区的内存碎片,因为字符串的长度一般不会超过15。
g++的X86环境下,一个string对象的大小是4字节;X64环境下,大小是8字节。这是由于底层只存储了一个指针,指针指向的空间中,存储了引用计数,_size和_capacity,以及C-string的数据。
这个引用计数又是啥玩意呢?这是g++对string做的优化,实现了写时拷贝(Copy On Write),创建对象时,把引用计数cnt初始化成1,拷贝的时候,cnt++。这样析构的时候,如果cnt不是1,就cnt--;如果cnt是1,再释放空间。当要对对象写入数据时,再进行深拷贝。这样极大地提升了拷贝的效率!
总结
- string的底层可以理解为一个指针和两个无符号整形变量,分别代表了c_str,size和capacity的返回值。
- 扩容是有代价的,尽可能使用reserve减少甚至避免扩容。
- string底层实现了深拷贝。
- 尽可能少地在string头部或者中间插入、删除数据。
- VS和g++对string做了一些优化。







![[职场] 会计学专业学什么 #其他#知识分享#职场发展](https://img-blog.csdnimg.cn/img_convert/8b7b90170669d1244af867a4e03cf6d5.jpeg)




![[office] Excel2019函数MAXIFS怎么使用?Excel2019函数MAXIFS使用教程 #知识分享#微信#经验分享](https://img-blog.csdnimg.cn/img_convert/358b3daf7ce7e4ef6c937fed9fb7529b.jpeg)