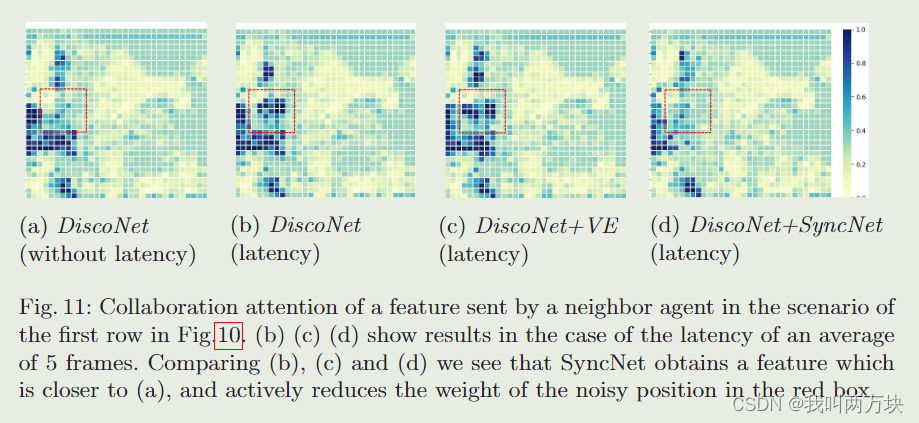
探索大型语言模型的上下文理解能力
在自然语言处理( Natural Language Processing,NLP)领域,理解上下文是把握人类语言的关键。近年来,大语言模型(LLMs)在展示对语言的理解方面取得了令人瞩目的成就。然而,尽管LLMs在各种NLP领域的评估中表现出色,对它们理解上下文特征的语言能力的探究却相对有限。本文介绍了一个通过适配现有数据集来评估生成模型的上下文理解基准。该基准包括四个不同的任务和九个数据集,所有任务都设计了旨在评估模型理解上下文能力的提示。首先,评估在上下文学习预训练场景下LLMs的表现。实验结果表明,预训练的密集模型在理解更微妙的上下文特征方面存在困难,尤其是与最新的微调模型相比。其次,随着LLMs压缩在研究和实际应用中的重要性日益增加,评估了在上下文学习设置下量化模型的上下文理解能力。我们发现,3位后训练量化导致我们基准上的性能不同程度的降低。我们对这些场景进行了广泛的分析,以支持实验结果。
论文标题:
Can Large Language Models Understand Context?
论文链接:
https://arxiv.org/pdf/2402.00858.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!
评估大语言模型上下文理解能力的方法
观察最近发布的LLMs,如OPT、LLaMA和GPT-4,只在有限的基准上进行了评估,并且存在一个显著的缺点:它们忽略了评估中包含与话语相关的数据集,因此限制了对它们语言理解能力的全面评估。为了提供全面的评估,许多基准和数据集涉及了语言理解的各个方面,包括常识知识和诸如情感分析、自然语言推理、摘要、文本分类等语言能力。尽管这些基准需要上下文信息来有效地处理任务,但没有一个基准专门针对需要深入上下文理解的任务。
研究方法:构建上下文理解基准
1. 选择适合生成模型的数据集
本文通过适配现有数据集来构建一个上下文理解基准,以评估生成模型。该基准包括四项不同的任务和九个数据集,所有这些都设计了用于评估模型上下文理解能力的提示。
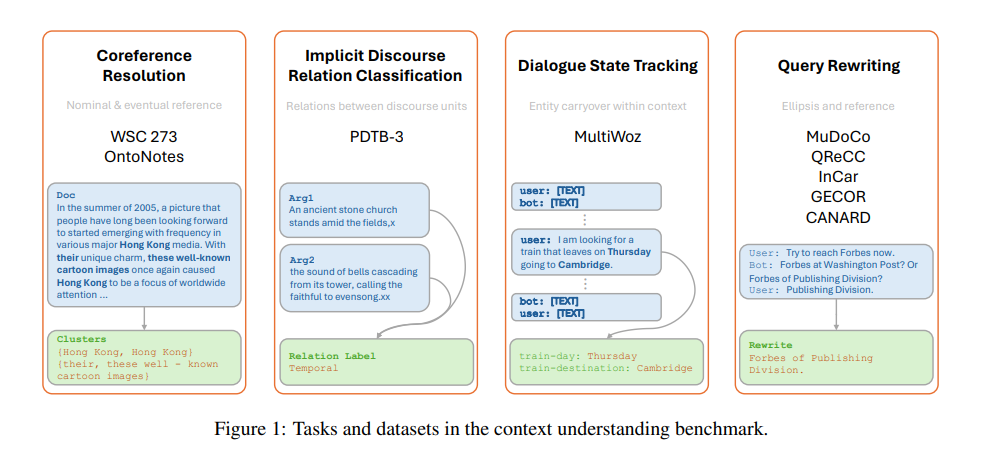
2. 设计评估大型语言模型的四项任务
-
核心指代消解:核心指代消解任务有助于实现对文本整体意义的连贯理解,因此在深入语言模型的核心指代关系和文档内上下文细微差别的能力方面起着关键作用。选择了两个核心指代数据集:WSC273和OntoNotes 5.0。
-
对话状态跟踪:对话状态跟踪(Dialogue State Tracking,DST)是任务导向对话(Task-Oriented Dialogue,TOD)建模领域的一个重要任务,对话代理需要跟踪用户在对话过程中提供的关键信息。使用了MultiWOZ v2.2数据集进行测试。

-
隐含话语关系分类:隐含话语关系分类任务要求模型正确识别两个话语单元(EDUs)之间的关系。PDTB3语料库将话语关系分类为四种类别:时间、条件、比较和扩展。
-
查询重写:查询重写任务要求模型将用户在对话中的最后一句话重写为一个无需对话上下文即可理解的独立完整话语。包括了五个QR数据集:MuDoCo、QReCC、InCar、GECOR和CANARD。

实验设计:评估不同大小模型的上下文理解
1. 使用多种模型进行实验
为了评估不同大小模型在上下文理解任务中的表现,我们采用了多种模型进行实验。这些模型包括小型模型(如OPT系列中的125M至2.7B参数模型)、中型模型(LLaMA系列中的7B至65B参数模型)以及大型模型(如GPT-3.5-turbo)。我们在实验中采用了不同的设置,包括零次学习(zero-shot)、一次学习(one-shot)、五次学习(5-shot)、八次学习(8-shot)和十次学习(10-shot),以测试模型在不同情境下的表现。
2. 实验设置和评估指标
实验的设置包括四项不同的任务和九个数据集,每个任务都设计了专门的提示(prompts)以适应生成模型的评估。这些任务包括共指消解(Coreference Resolution)、对话状态跟踪(Dialogue State Tracking)、隐含话语关系分类(Implicit Discourse Relation Classification)和查询重写(Query Rewriting)。我们使用了官方的评估指标,如CoNLL F1分数、准确率(accuracy)、BLEU和ROUGE分数来评估模型的表现。
实验结果:大型模型在上下文理解任务中的表现
1. 不同模型在各项任务中的表现对比
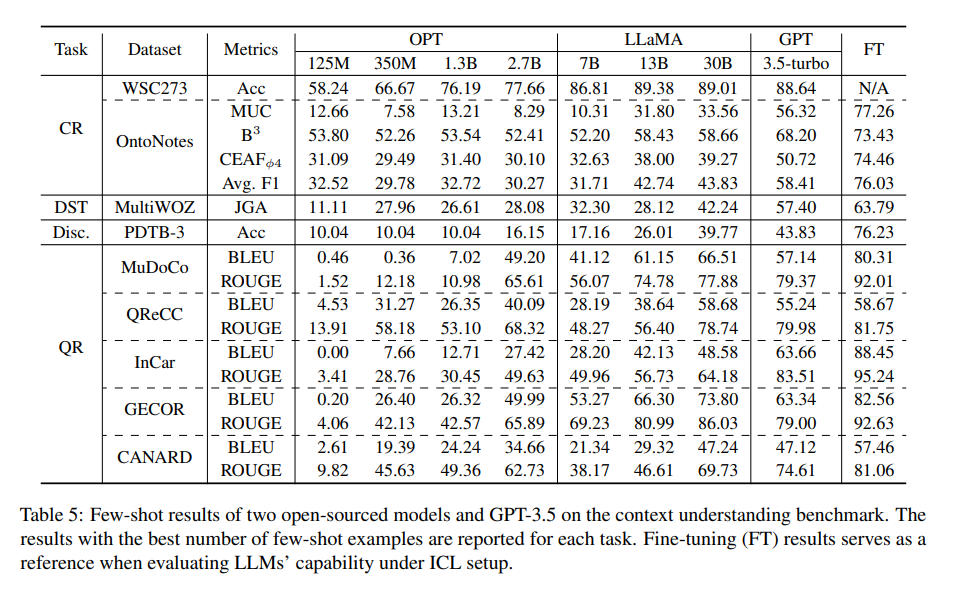
实验结果显示,随着模型大小的增加,模型的性能也有所提高。
-
在共指消解任务中,大型模型在WSC273数据集上表现出色,表明它们能够有效处理简单的共指关系。然而,在处理文档级别的复杂共指链时,性能显著下降。
-
在对话状态跟踪任务中,OPT和LLaMA模型远远落后于GPT-3.5,表明这些模型在提取对话中的关键信息方面存在困难。
-
在隐含话语关系分类任务中,当模型大小超过7B时,分数有所提高,但即使是表现最好的GPT模型,其性能也远低于最先进的微调模型。
-
在查询重写任务中,小型和大型模型之间的差距非常大,例如OPT-125M甚至无法完成重写任务。
2. 模型压缩技术对上下文理解的影响
我们还评估了模型压缩技术对上下文理解的影响。3位后训练量化(3-bit post-training quantization)显示在我们的基准测试中导致不同程度的性能降低。然而,量化的30B LLaMA模型在所有任务中一致且显著地优于7B密集模型,尽管使用了3位量化。这表明在理解话语方面,更大的模型规模的好处超过了量化的影响。这一发现对于在磁盘和运行时约束的实际应用中部署大型语言模型非常有益。
深入分析:查询重写任务的案例研究
1. OPT与LLaMA模型在查询重写任务中的对比
在查询重写任务中,OPT和LLaMA模型的表现并不一致。
-
LLaMA在其他任务中通常表现更好,但在查询重写任务中,当模型大小约为7B时,OPT模型的表现显著优于LLaMA,尤其是在五个查询重写数据集上。
-
随着模型规模的增大至30B,LLaMA的表现开始超越OPT。
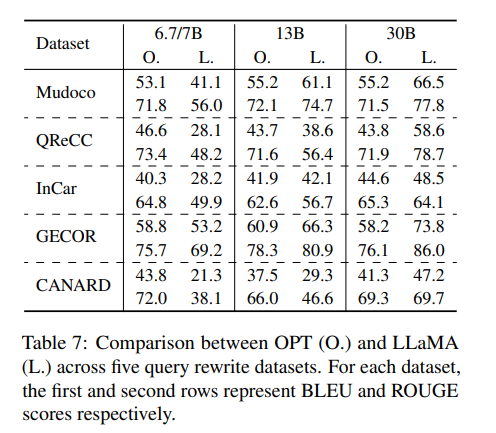
这表明在不同规模的模型或不同任务集上,两个模型家族的整体优劣并不明显。
2. 稠密模型与量化模型的性能比较
在查询重写任务中,稠密模型与量化模型的性能存在差异。
-
稠密的30B LLaMA模型在五个数据集上的错误数量显著少于7B稠密模型。然而,3比特的量化模型在重复错误方面的数量与7B稠密模型相似,这表明量化降低了模型理解上下文的能力。
-
在语言建模错误方面,30B稠密模型也显著优于7B稠密模型,而量化模型在这方面的错误略多于30B稠密模型,但远少于7B稠密模型。这说明3比特量化在保持模型的上下文学习能力方面是有效的。
结论:大语言模型在上下文理解方面的挑战与潜力
1. 大语言模型上下文理解能力的现状
大语言模型在上下文理解任务中的表现表明,挑战依然是存在的。尽管在某些任务中,如简单的共指消解任务,较大的模型表现出了较好的性能,但在文档级共指消解和对话状态跟踪等复杂任务中,它们的性能显著下降。此外,量化技术虽然能够在减少模型大小的同时保持一定的性能,但在理解上下文方面的能力有所下降。
2. 未来研究方向和实际应用的展望
未来的研究可以探索如何提高LLMs在上下文理解方面的性能,特别是在量化模型上。此外,研究可以扩展到多语言数据集和针对特定语言优化的模型,以更全面地评估LLMs的上下文理解能力。在实际应用方面,量化模型的研究为在资源受限的环境中部署大型模型提供了可能性,这对于实时语言处理应用尤为重要。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!