需求:如何从众多数据源中快速处理数据

现实生产架构多源异构,需要一个强有力的工具(抽象)统一数据查询/分析
这也是presto/trino从诞生之初便贴数据湖查询工具 tag的原因,presto生来为此
生产环境的困境
1.数据源众多,没有一个统一的视角来处理/生产数据
2.很多系统查询/计算性能堪忧
presto的能力
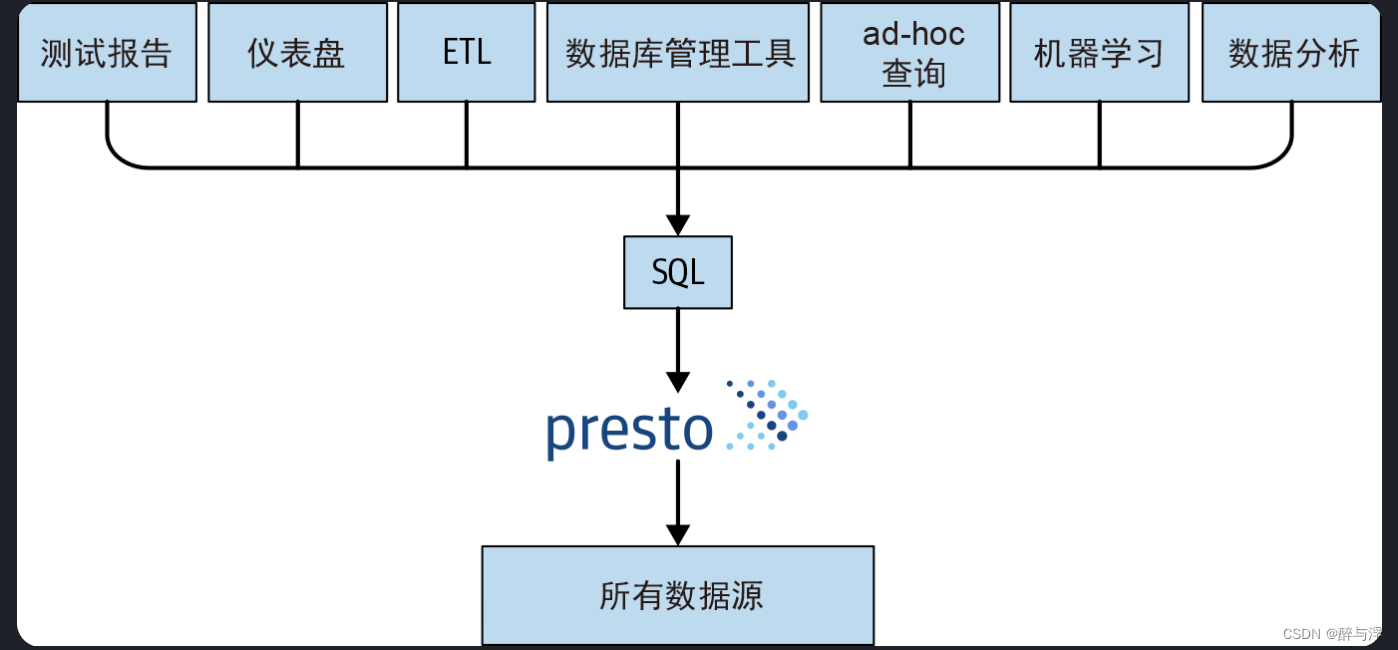
1.不同系统联邦查询,众多插件支持多种数据源
2.并行计算,横向扩展集群
presto优势
Presto 是一个开源的分布式 SQL 查询引擎,它是为了高效查询不同系统和各种规模(从 GB 级到 PB 级)的数据源而从头开始设计和编写的一套系统。

性能和规模
Presto相比于hive能快速查询TB甚至PB级数据。而用户只要写标准SQL即可使用这一能力(OLAP分析)。
Presto 内存并行处理、跨集群节点管线执行、多线程执行模型(以充分利用所有 CPU 核心)、高效的扁平内存数据结构(以最小化 Java 的垃圾回收)和 Java 字节码生成等技术来提升性能。
Presto本身结构决定他能快速,轻易实现水平扩展。
sql-on-anything
prsto使用原地查询,可以直接查询生产系统中的存储系统,且支持大量数据源。
用户只要使用一套sql即可查询海量存储系统,甚至可以跨存储系统查询。
对象存储系统包括 Amazon Web Services(AWS)提供的 Simple Storage Service(S3)、Microsoft Azure Blob Storage、Google Cloud Storage 和 S3 兼容的存储系统(如 MinIO 和 Ceph)。Presto 可以查询传统的 RDBMS,如 Microsoft SQL Server、PostgreSQL、MySQL、Oracle、Teradata 和 Amazon Redshift,还可以查询 NoSQL 数据库系统,如 Apache Cassandra、Apache Kafka、MongoDB 和 Elasticsearch。Presto 几乎可以查询任何东西,是一个真正的 SQL-on-Anything 系统。
存算分离
presto不存储数据,只进行计算。使用presto构成的系统可以独立扩展存储的数据存储层和presto计算层。
presto集群支持动态扩缩容。
Presto使用场景
- 区别于生产系统的快速查询
- 单一sql语法的访问节点
- 联邦查询
- 成为任何上游工具的数据入口
基础概念
Presto 使你可以使用 SQL 访问外部数据源,如关系数据库、键值存储和对象存储等。理解以下 Presto 概念非常重要。
connector
使 Presto 适配一个数据源。每一个 catalog 对应于一个特定的连接器。
catalog
定义连接到一个数据源的细节。它包含了 schema 并配置了一个连接器来使用。
schema
组织表的一种方式。catalog 和 schema 一起定义了一个集合的表,这些表可以查询。类似于"库"
表
表是无序的行的集合。这些行内容被组织成带有数据类型的有名称的列。