一、概述
Stream Load是StarRocks常见的数据导入方式,用户通过发送HTTP请求将本地文件或数据流导入至StarRocks中,该导入方式不依赖其他组件。
Stream Load作是一种同步导入方式,可以直接通过请求的返回值判断导入是否成功,无法手动取消Stream Load任务,在超时或者导入错误后会被系统自动取消。
Stream Load支持csv和json两种数据文件格式,适用于数据文件数量较少且单个文件的大小不超过10GB 的场景。Stream Load支持在导入过程中做数据转换、以及通过 upsert和delete 操作实现数据变更。
二、 Stream Load原理
2.1 流程图
Stream Load本质上是一个HTTP的PUT请求 ,执行流程如下:
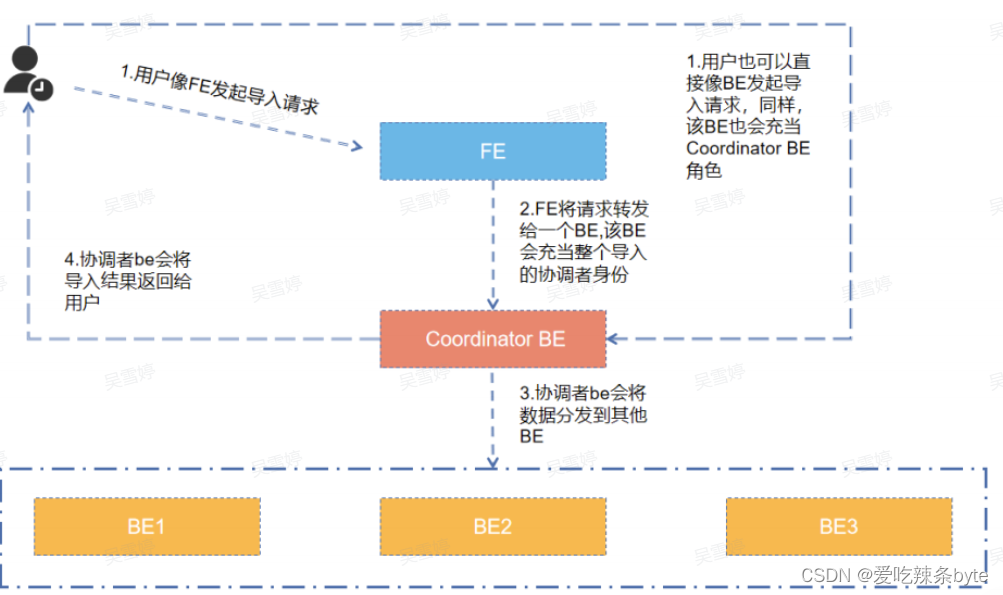
2.2 流程详解
(1)用户发起导入请求,该请求可以直接发往FE,由FE将请求转发给某个BE,由该BE充当协调者的角色,也可以由用户自己在导入请求时指定某个BE为协调者角色,发起导入请求。
ps:如果把导入作业请求发送给 FE,FE 会通过轮询机制选定由哪一个 BE 来接收请求,从而实现 StarRocks 集群内的负载均衡。因此,推荐您把导入作业请求发送给 FE。
(2)协调者在收到导入请求后,会把数据分发到其他BE数据节点,当集群内一份数据有两个数据节点完成数据写入后,就标志着这次导入事务成功,剩余的一份数据会由剩下的节点从这两个副本中去同步数据。
(3)导入数据成功后,协调者会将导入任务的状态返回给用户。
2.3 注意事项
(1)请求直接发往FE时,FE 会通过 HTTP 重定向 (Redirect) 指令将请求转发给某一个 BE。需要注意重定向过程中,可能会由于网络波动问题造成导入任务的失败。
(2) Stream Load导入作业的系统参数配置:
streaming_load_max_mb:代表单个源数据文件的大小上限,默认文件大小上限为 10 GB
建议一次导入的数据量不要超过 10 GB,否则失败重试的代价过大。源文件较大,可以拆分为多个Stream Load任务并行的方式(手动指定不同的协调者BE)来提高Stream Load导入任务的导入性能。如果确实无法拆分,可以适当调大该参数的取值,从而提高数据文件的大小上限。
ps :如果调大该参数的取值,需要重启 BE 才能生效,系统性能可能会受影响,失败重试时的代价也会增加。
2.4 应用案例
Stream Load对本地csv和json两种数据格式的导入案例,见文章
第3.2章:StarRocks数据导入--Stream Load_starrocks stream load-CSDN博客
参考文章:
第3.2章:StarRocks数据导入--Stream Load_starrocks stream load-CSDN博客
从本地文件系统导入 | StarRocks
Docs
如何基于 Apache Doris 构建简易高效的用户行为分析平台?|解决方案
Apache Doris 2.0 如何实现导入性能提升 2-8 倍