前言
在当今大数据和人工智能的时代,大型视觉语言模型(LVLM)已成为解锁复杂视觉和语言任务的关键。然而,随着这些模型能力的不断增强,其对计算资源的需求也水涨船高,导致训练和推理成本急剧上升。北京大学和中山大学的研究者针对这一挑战,提出了一种名为MoE-Tuning的创新训练策略,该策略通过实现模型的稀疏化来平衡性能提升与计算成本之间的矛盾。

技术创新
MoE-Tuning策略的核心思想是在模型中引入所谓的"专家"(Experts),并通过路由算法在给定时刻仅激活其中的一小部分,从而使得模型在保持参数数量巨大的同时,实际计算成本得以控制。这一策略的成功应用,催生了MoE-LLaVA框架——一种新型的稀疏大型视觉语言模型,它在模型设计上采用了Mixture of Experts(MoE)架构,使得模型在执行任务时能够更加灵活高效。
-
Huggingface模型下载:https://huggingface.co/collections/LanguageBind/moe-llava-model-65b607bf2524ac36e733874c
-
AI快站模型免费加速下载:https://aifasthub.com/models/LanguageBind
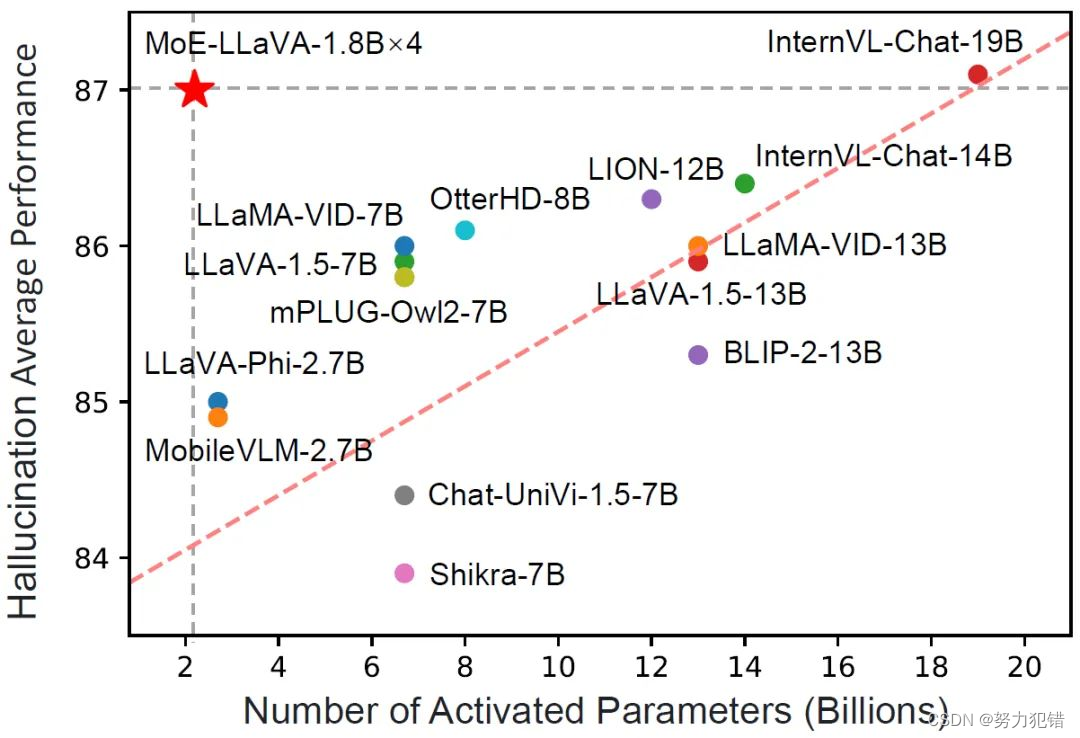
MoE-LLaVA模型通过精妙的设计,仅需3B个稀疏激活参数便能实现与7B参数的LLaVA-1.5模型相媲美,甚至在某些视觉理解任务上超越13B参数的LLaVA-1.5模型。这一显著成就,不仅在技术上展示了稀疏模型的强大潜力,也为未来多模态学习系统的研究和开发提供了新的方向和灵感。
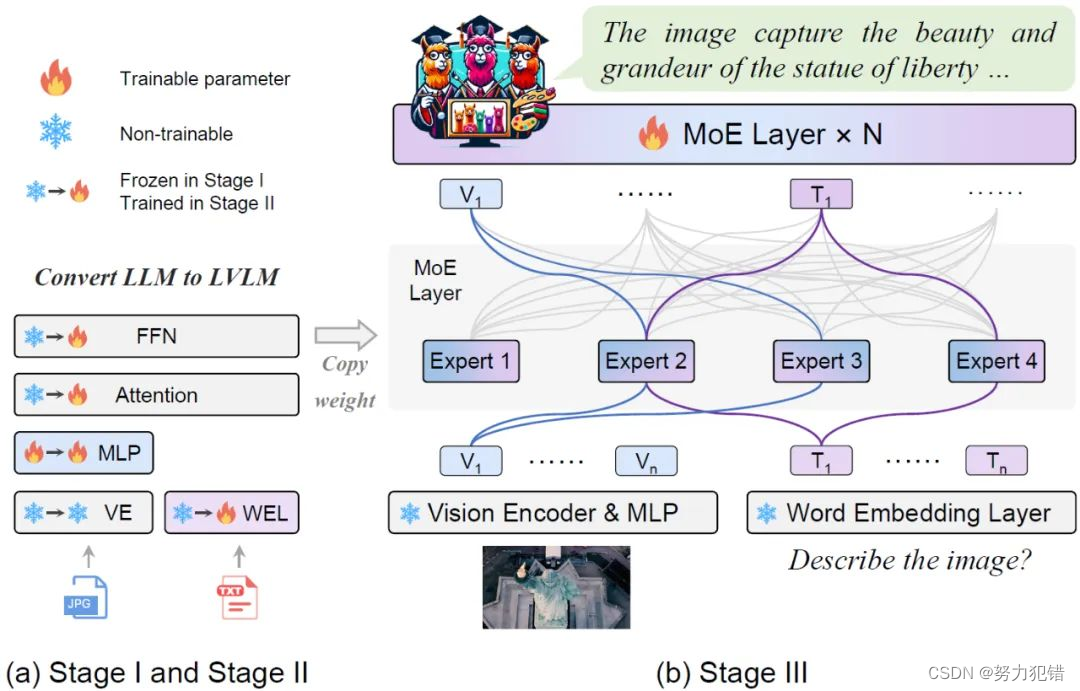
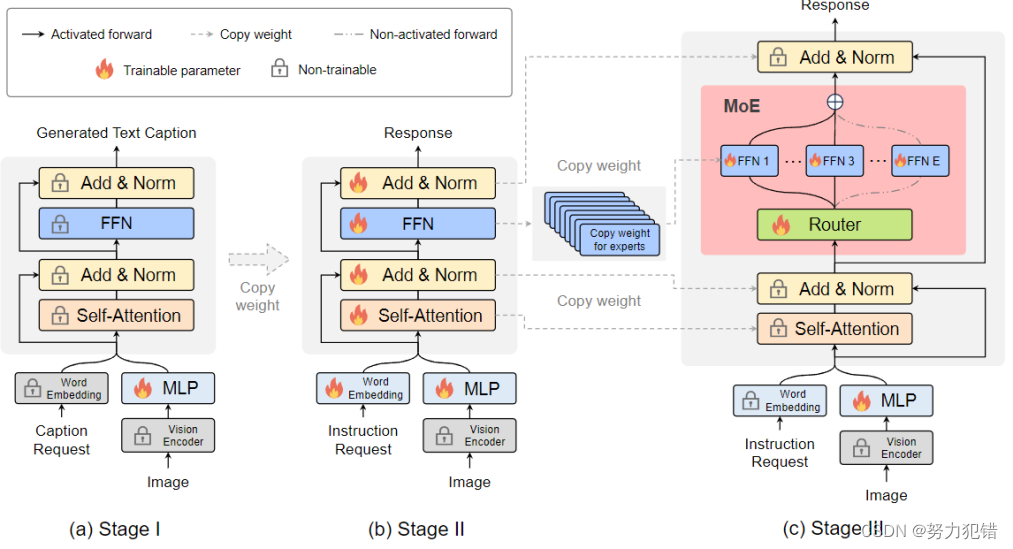
MoE-LLaVA模型的训练采用了三阶段策略,首先通过视觉编码器处理输入图片,将视觉token与文本token结合,并通过MLP将视觉token映射到LLM的输入域,从而让LLM获得描述图片和理解图片语义的能力。随后,通过引入复杂的多模态指令数据,进一步提升模型的多模态理解能力。最终,通过复制FFN作为专家集合的初始化权重,并利用router计算token与专家的匹配度,实现了模型的稀疏化。
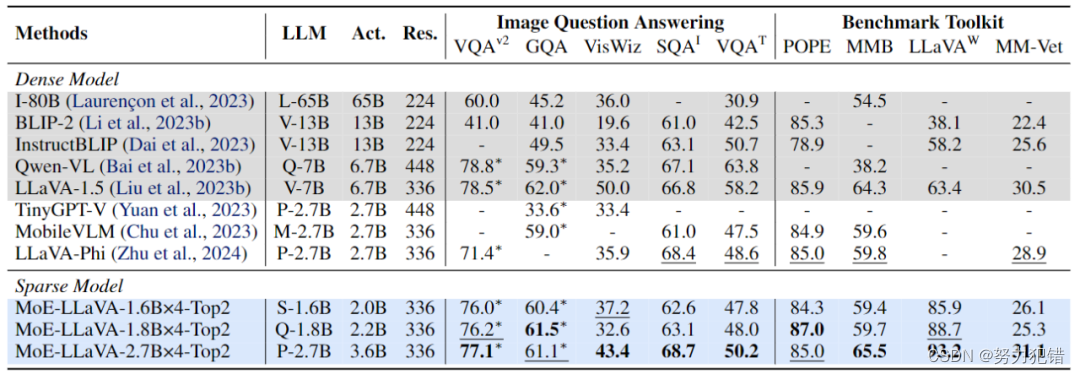
性能表现
在众多基准测试中,MoE-LLaVA模型展现出了其卓越的视觉理解能力,尤其是在减少对象幻觉方面的表现尤为突出。这些成果不仅证明了MoE-LLaVA在技术上的先进性,也展现了其在实际应用中巨大的潜力。
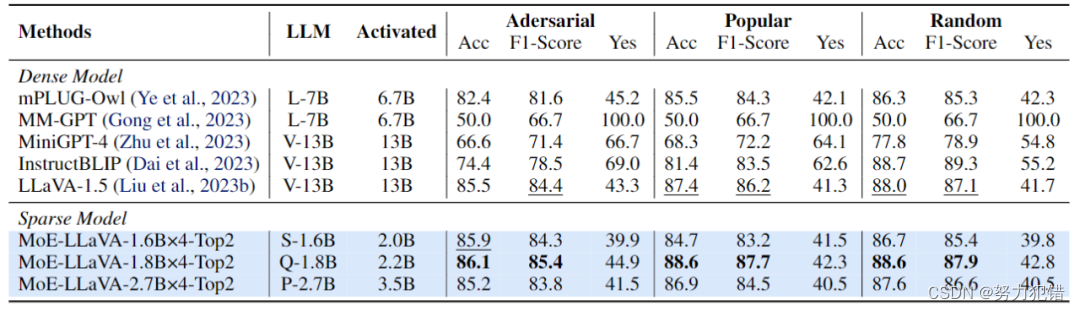
结论
总之,MoE-LLaVA模型的开发和成功应用,为解决大型模型所面临的训练和推理成本高昂问题提供了一条切实可行的路径。通过稀疏化技术的创新应用,MoE-LLaVA不仅在性能上取得了令人瞩目的成就,更为未来的AI研究和应用开辟了新的可能性,标志着多模态AI领域的一个重要进步。
模型下载
Huggingface模型下载
https://huggingface.co/collections/LanguageBind/moe-llava-model-65b607bf2524ac36e733874c
AI快站模型免费加速下载
https://aifasthub.com/models/LanguageBind