本文主角:
∇ θ J ( θ ) ∝ ∑ s ∈ S μ π θ ( s ) ∑ a ∈ A Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) \nabla_{\theta}J(\theta) \propto \sum_{s \in \mathcal{S}} \mu^{\pi_{\theta}}(s) \sum_{a \in \mathcal{A}} Q^{\pi_{\theta}}(s, a) \nabla_{\theta}\pi_{\theta}(a|s) ∇θJ(θ)∝∑s∈Sμπθ(s)∑a∈AQπθ(s,a)∇θπθ(a∣s)
这个公式是策略梯度定理的表述,它表明一个策略的性能梯度(即优化目标函数 J ( θ ) J(\theta) J(θ)的梯度)与在该策略下各状态的访问频率 μ π θ ( s ) \mu^{\pi_{\theta}}(s) μπθ(s),以及在这些状态下,采取不同动作的价值 Q π θ ( s , a ) Q^{\pi_{\theta}}(s, a) Qπθ(s,a)和采取这些动作的策略概率的梯度 ∇ θ π θ ( a ∣ s ) \nabla_{\theta}\pi_{\theta}(a|s) ∇θπθ(a∣s)的乘积之和成正比。
在强化学习中,这个公式是用来指导如何调整策略参数 θ \theta θ,以便最大化长期奖励。通过梯度上升算法,我们可以改善策略,使得在高价值 Q Q Q下采取的动作更加频繁,从而提高整体策略的期望回报。
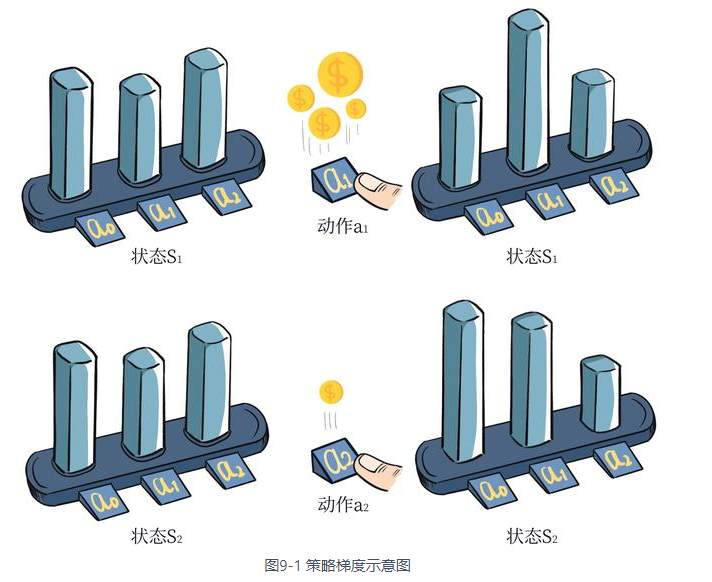
下面是完整推导:
-
定义状态值函数的梯度:
∇ θ V π ( s ) = ∇ θ ( ∑ a ∈ A π ( a ∣ s ) Q π ( s , a ) ) \nabla_{\theta}V^{\pi}(s) = \nabla_{\theta}\left(\sum_{a \in A} \pi(a|s)Q^{\pi}(s, a)\right) ∇θVπ(s)=∇θ(∑a∈Aπ(a∣s)Qπ(s,a))
这一步基于状态值函数 V π ( s ) V^{\pi}(s) Vπ(s)的定义,即给定策略 π \pi π下,在状态 s s s采取所有可能动作 a a a的期望回报的总和。这里, π ( a ∣ s ) \pi(a|s) π(a∣s)是在状态 s s s下选择动作 a a a的策略概率,而 Q π ( s , a ) Q^{\pi}(s, a) Qπ(s,a)是执行动作 a a a并遵循策略 π \pi π的期望回报。 -
应用梯度和乘积规则:
= ∑ a ∈ A ( ∇ θ π ( a ∣ s ) Q π ( s , a ) + π ( a ∣ s ) ∇ θ Q π ( s , a ) ) = \sum_{a \in A}\left(\nabla_{\theta}\pi(a|s)Q^{\pi}(s, a) + \pi(a|s)\nabla_{\theta}Q^{\pi}(s, a)\right) =∑a∈A(∇θπ(a∣s)Qπ(s,a)+π(a∣s)∇θQπ(s,a))
这一步通过应用梯度运算符和乘积规则( ∇ ( x y ) = x ∇ y + y ∇ x \nabla(xy) = x\nabla y + y\nabla x ∇(xy)=x∇y+y∇x)来分解每个项。第一项考虑了策略 π ( a ∣ s ) \pi(a|s) π(a∣s)对参数 θ \theta θ的直接依赖,而第二项考虑了行为值函数 Q π ( s , a ) Q^{\pi}(s, a) Qπ(s,a)对 θ \theta θ的依赖。 -
行为值函数的梯度展开:
= ∑ a ∈ A ( ∇ θ π ( a ∣ s ) Q π ( s , a ) + π ( a ∣ s ) ∇ θ ∑ s ′ , r P ( s ′ , r ∣ s , a ) ( r + γ V π ( s ′ ) ) ) = \sum_{a \in A}\left(\nabla_{\theta}\pi(a|s)Q^{\pi}(s, a) + \pi(a|s)\nabla_{\theta}\sum_{s', r}P(s', r|s, a)\left(r + \gamma V^{\pi}(s')\right)\right) =∑a∈A(∇θπ(a∣s)Qπ(s,a)+π(a∣s)∇θ∑s′,rP(s′,r∣s,a)(r+γVπ(s′)))
这里将 Q π ( s , a ) Q^{\pi}(s, a) Qπ(s,a)按其定义展开,即为给定状态 s s s和动作 a a a后的即时奖励 r r r加上折扣后的未来奖励的期望值。梯度作用于整个表达式,注意到 r r r和 γ \gamma γ是常数,梯度只作用于 V π ( s ′ ) V^{\pi}(s') Vπ(s′)。 -
简化即时奖励的影响:
= ∑ a ∈ A ( ∇ θ π ( a ∣ s ) Q π ( s , a ) + γ π ( a ∣ s ) ∑ s ′ , r P ( s ′ , r ∣ s , a ) ∇ θ V π ( s ′ ) ) = \sum_{a \in A}\left(\nabla_{\theta}\pi(a|s)Q^{\pi}(s, a) + \gamma\pi(a|s)\sum_{s', r}P(s', r|s, a)\nabla_{\theta}V^{\pi}(s')\right) =∑a∈A(∇θπ(a∣s)Qπ(s,a)+γπ(a∣s)∑s′,rP(s′,r∣s,a)∇θVπ(s′))
在这一步中,即时奖励 r r r被省略,因为它不依赖于 θ \theta θ,因此其梯度为零。只有未来奖励的部分,即 γ V π ( s ′ ) \gamma V^{\pi}(s') γVπ(s′),对 θ \theta θ有依赖,因此梯度只作用于这部分。 -
进一步简化概率项:
= ∑ a ∈ A ( ∇ θ π ( a ∣ s ) Q π ( s , a ) + γ π ( a ∣ s ) ∑ s ′ P ( s ′ ∣ s , a ) ∇ θ V π ( s ′ ) ) = \sum_{a \in A}\left(\nabla_{\theta}\pi(a|s)Q^{\pi}(s, a) + \gamma\pi(a|s)\sum_{s'}P(s'|s, a)\nabla_{\theta}V^{\pi}(s')\right) =∑a∈A(∇θπ(a∣s)Qπ(s,a)+γπ(a∣s)∑s′P(s′∣s,a)∇θVπ(s′))
- 从策略梯度的定义开始:
∇ θ V π ( s ) = ϕ ( s ) + γ ∑ a π ( a ∣ s ) ∑ s ′ P ( s ′ ∣ s , a ) ∇ θ V π ( s ′ ) \nabla_{\theta}V^{\pi}(s) = \phi(s) + \gamma\sum_{a} \pi(a|s)\sum_{s'}P(s'|s, a)\nabla_{\theta}V^{\pi}(s') ∇θVπ(s)=ϕ(s)+γ∑aπ(a∣s)∑s′P(s′∣s,a)∇θVπ(s′)
这里, ϕ ( s ) = ∑ a ∈ A ∇ θ π θ ( a ∣ s ) Q π θ ( s , a ) \phi(s)= \sum_{a \in A} \nabla_{\theta}\pi_{\theta}(a|s)Q^{\pi_{\theta}}(s, a) ϕ(s)=∑a∈A∇θπθ(a∣s)Qπθ(s,a)代表了状态 s s s的特征向量,它是策略梯度的一部分。接着,考虑了在当前策略下,从状态 s s s采取动作 a a a转移到状态 s ′ s' s′的概率,以及从状态 s ′ s' s′开始并遵循策略 π \pi π的状态值函数的梯度。 - 展开状态值函数的梯度:
∇ θ V π ( s ) = ϕ ( s ) + γ ∑ s ′ d π ( s → s ′ , 1 ) ∇ θ V π ( s ′ ) \nabla_{\theta}V^{\pi}(s) = \phi(s) + \gamma\sum_{s'} d^{\pi}(s \rightarrow s', 1)\nabla_{\theta}V^{\pi}(s') ∇θVπ(s)=ϕ(s)+γ∑s′dπ(s→s′,1)∇θVπ(s′)
d π ( s → s ′ , 1 ) d^{\pi}(s \rightarrow s', 1) dπ(s→s′,1)表示在一步转移中从状态 s s s到状态 s ′ s' s′的折扣后的状态转移概率。它是一个概率分布,考虑了所有可能的动作。 - 递归地展开状态值函数的梯度:
∇ θ V π ( s ) = ϕ ( s ) + γ ∑ s ′ d π ( s → s ′ , 1 ) ϕ ( s ′ ) + γ 2 ∑ s ′ ′ d π ( s → s ′ ′ , 2 ) ∇ θ V π ( s ′ ′ ) \nabla_{\theta}V^{\pi}(s) = \phi(s) + \gamma\sum_{s'} d^{\pi}(s \rightarrow s', 1)\phi(s') + \gamma^2\sum_{s''} d^{\pi}(s \rightarrow s'', 2)\nabla_{\theta}V^{\pi}(s'') ∇θVπ(s)=ϕ(s)+γ∑s′dπ(s→s′,1)ϕ(s′)+γ2∑s′′dπ(s→s′′,2)∇θVπ(s′′)
这一步递归地应用了上一步的逻辑,但这次是对两步转移后的状态 s ′ ′ s'' s′′。这表明每一步都会增加一个更深层次的期望和一个更高的折扣因子 γ \gamma γ。 - 继续无限递归:
∇ θ V π ( s ) = ϕ ( s ) + γ ∑ s ′ d π ( s → s ′ , 1 ) ϕ ( s ′ ) + γ 2 ∑ s ′ ′ d π ( s → s ′ ′ , 2 ) ϕ ( s ′ ′ ) + … \nabla_{\theta}V^{\pi}(s) = \phi(s) + \gamma\sum_{s'} d^{\pi}(s \rightarrow s', 1)\phi(s') + \gamma^2\sum_{s''} d^{\pi}(s \rightarrow s'', 2)\phi(s'') + \ldots ∇θVπ(s)=ϕ(s)+γ∑s′dπ(s→s′,1)ϕ(s′)+γ2∑s′′dπ(s→s′′,2)ϕ(s′′)+…
推导继续进行,考虑到所有可能的未来状态和它们对应的特征向量,乘以它们的转移概率和适当的折扣因子。 - 总结为无限和:
∇ θ V π ( s ) = ∑ x ∈ S ∑ k = 0 ∞ γ k d π ( s → x , k ) ϕ ( x ) \nabla_{\theta}V^{\pi}(s) = \sum_{x \in S}\sum_{k=0}^{\infty}\gamma^k d^{\pi}(s \rightarrow x, k)\phi(x) ∇θVπ(s)=∑x∈S∑k=0∞γkdπ(s→x,k)ϕ(x)
最后一步是将所有无限递归的项总结为一个无限序列和。这里 d π ( s → x , k ) d^{\pi}(s \rightarrow x, k) dπ(s→x,k)是从状态 s s s到状态 x x x在 k k k步内的折扣后的转移概率。这个无限和形式的期望值是对状态值函数的梯度的完整描述。
-
目标函数的梯度:
∇ θ J ( θ ) = ∇ θ E s 0 [ V π θ ( s 0 ) ] \nabla_{\theta}J(\theta) = \nabla_{\theta} \mathbb{E}_{s_0}[V^{\pi_{\theta}}(s_0)] ∇θJ(θ)=∇θEs0[Vπθ(s0)]
这一步定义了目标函数 J ( θ ) J(\theta) J(θ)作为初始状态 s 0 s_0 s0下的状态值函数 V π θ ( s 0 ) V^{\pi_{\theta}}(s_0) Vπθ(s0)的期望值的梯度。 -
引入状态转移概率:
= ∑ s E s 0 [ ∑ k = 0 ∞ γ k d π θ ( s 0 → s , k ) ] ϕ ( s ) = \sum_s \mathbb{E}_{s_0} \left[ \sum_{k=0}^{\infty} \gamma^k d^{\pi_{\theta}}(s_0 \rightarrow s, k) \right] \phi(s) =∑sEs0[∑k=0∞γkdπθ(s0→s,k)]ϕ(s)
此处,将目标函数中的期望展开,包含从初始状态 s 0 s_0 s0到任意状态 s s s的折扣转移概率 d π θ ( s 0 → s , k ) d^{\pi_{\theta}}(s_0 \rightarrow s, k) dπθ(s0→s,k),乘以状态 s s s的特征向量 ϕ ( s ) \phi(s) ϕ(s)。每个状态的特征向量与它被访问的概率加权求和。 -
引入状态分布 η ( s ) \eta(s) η(s):
= ∑ s η ( s ) ϕ ( s ) = \sum_s \eta(s) \phi(s) =∑sη(s)ϕ(s)
这里, η ( s ) \eta(s) η(s)是在策略 π θ \pi_{\theta} πθ下访问状态 s s s的稳态分布。它是从任何初始状态出发,经过无限步骤后到达状态 s s s的概率。 -
状态分布的规范化:
∝ ∑ s η ( s ) ∑ s ′ η ( s ′ ) ϕ ( s ) \propto \sum_s \frac{\eta(s)}{\sum_{s'} \eta(s')} \phi(s) ∝∑s∑s′η(s′)η(s)ϕ(s)
这一步表明状态分布被规范化了,使得所有状态的分布之和为1。这是为了将状态分布转化为概率分布。 -
使用 η ( s ) \eta(s) η(s)的定义:
= ∑ s μ ( s ) ∑ a Q π θ ( s , a ) ∇ θ π θ ( a ∣ s ) = \sum_s \mu(s) \sum_a Q^{\pi_{\theta}}(s, a) \nabla_{\theta} \pi_{\theta}(a|s) =∑sμ(s)∑aQπθ(s,a)∇θπθ(a∣s)
最终,我们得到了策略梯度定理的标准形式。这里 μ ( s ) \mu(s) μ(s)代表状态 s s s在策略 π θ \pi_{\theta} πθ下的访问频率,而 Q π θ ( s , a ) Q^{\pi_{\theta}}(s, a) Qπθ(s,a)是在状态 s s s下采取动作 a a a的行为值函数。梯度 ∇ θ π θ ( a ∣ s ) \nabla_{\theta} \pi_{\theta}(a|s) ∇θπθ(a∣s)表示策略对参数的依赖性。