第四章:字符串与正则表达式
4.1字符串
最早的字符串编码是美国标准信息交换码ASCII,仅对10个数字、26个大写英文字母、26个小写英文字母及一些其他符号进行了编码。ASCII码采用1个字节来对字符进行编码,最多只能表示256个符号。
随着信息技术的发展和信息技术的需要,各国的文字都需要进行编码,不同的应用领域和场合对字符串编码的要求有不同,于是又分别设计了多种不同的编码格式,常见的主要有UTF-8、UTF-16、UTF-32、GB2312、GBK、CP936、base64、CP437等等。
GB2312是我国定制的中文编码,使用1个字节表示英语,2个字节表示中文;GBK是GB
2312的扩充,而CP936是微软在GBK基础上开发的编码方式。GB2312、GBK和CP936都是使用2个字节表示中文。
UTF-8对全世界所有国家需要用到的字符进行了编码,以1个字节表示英语字符(兼容ASCII),以3个字节表示中文,还有些语言的符号使用2个字节(例如俄语和希腊语符号)或4个字节。
不同编码格式之间相差很大,采用不同的编码格式意味着不同的表示和存储形式,把同一字符存入文件时,写入的内容可能不同,在试图理解其内容时必须了解编码规则并进行正确的解码。如果解码方法不正确就无法还原信息,从这个角度来讲,字符串编也就具有加密的效果。
python 3.x 完全支持中文字符,默认使用UTF8编码格式,无论是一个数字、英文字母,还是汉字,都按一个字符对待和处理。
>s='中国山东烟台'
>len(s) #字符串长度,或者包含的字符个数
6>s='中国山东烟台ABCDE' #中文与英文字符同样对待,都算一个字符
>len(s)
11>姓名='张三' #使用中文作为变量名
>print(姓名) #输出变量的值
张三
在python中,字符串属于不可变序列(有序序列)类型,除了支持序列通用方法(包括分片操作)以外,还支持特有的字符串操作方法。
>testString='good'
>id(testString)
2377223672624>testString[0]='b' #不可变指的是,不能通过下标的方式改变字符串中的某个元素值
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
testString[0]='b'
TypeError: 'str' object does not support item assignment>testString='well'
>id(testString)
2377223676080
元组和字符串:不能改变其中的元素值
python字符串驻留机制:对于短字符串,将其赋值给对多个不同的对象时,内存中只有一个副本,多个对象共享该副本。长字符串不遵守驻留机制。
4.1.1字符串格式化
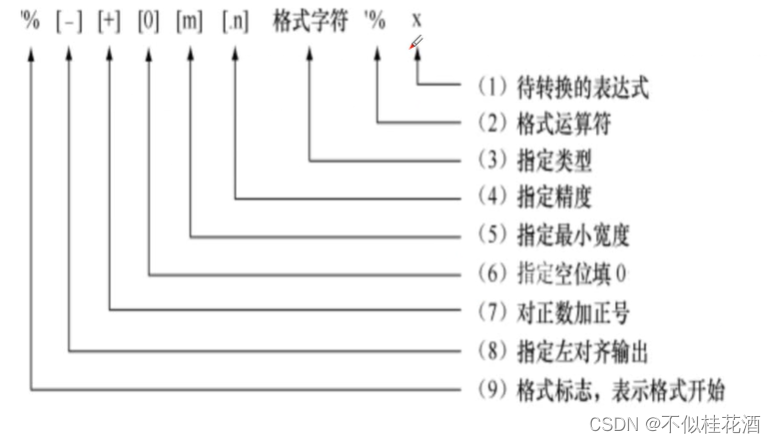
常用格式字符
>x=1235
>so="%o"%x #%o八进制数
>so
'2323'>sh="%x"%x # #%x十六进制数
>sh
'4d3'>se="%e"%x
>se
'1.235000e+03'#ord:返回单个字符的ASCII值
#chr:输入整数返回对应的ASCII符号
>chr(ord("3")+1)
'4'
>"%s"%65 #%s转换成字符串
'65'>"%s"%65333
'65333'>"%d"%"555" #%d转换成整数
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
"%d"%"555"
TypeError: %d format: a real number is required, not str
>int('555') #eval相同
555>'%s'%[1,2,3]
'[1, 2, 3]'>str((1,2,3))
'(1, 2, 3)'>str([1,2,3])
'[1, 2, 3]'
使用format方法进行格式化
>print("The number {0:,} in hex is:{0:#x},the number {1} in oct is {1:#o}".format(5555,55))
The number 5,555 in hex is:0x15b3,the number 55 in oct is 0o67>print("The number {1:,} in hex is:{1:#x},the number {0} in oct is {0:#o}".format(5555,55))
The number 55 in hex is:0x37,the number 5555 in oct is 0o12663>print("my name is {name},my age is {age},and my QQ is {qq}".format(name="Dong Fuguo",age=37,qq='306467355'))
my name is Dong Fuguo,my age is 37,and my QQ is 306467355>position=(5,8,13)
>print("X:{0[0]};Y:{0[1]};Z:{0[2]}".format(position))
X:5;Y:8;Z:13
weather=[("Monday","rain"),("Tuesday","sunny"),("Aednesday","sunny"),("Thursday","rain"),("Firday","Cloudy")]
formatter="Weather of '{0[0]}' is '{0[1]}'".format
#map:把一个函数映射到一个序列上。
for item in map(formatter,weather):print(item)#第二种输出方式
for item in weather:print(formatter(item))
从python3.6开始支持一种新的字符串格式化方式,官方叫做Formatted String Literals,其含义与字符串对象的format()方法类似,但形式更加简洁。
>name='Dong'
>age=39
>f'My name is {name},and I am {age} years old.'
'My name is Dong,and I am 39 years old.'>width=10 #宽度
>precision=4 #精度
>value=11/3 #计算的值
>f'result:{value:{width}.{precision}}'
'result: 3.667'
4.1.2字符串常用方法
find()、rfind()
find()和rfind方法分别用来查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次出现和最后一次出现的位置,如果不存在则返回-1;
index()、rindex()
index()和rindex()方法用来返回一个字符串在另一个字符串指定范围中首次和最后一次出现的位置,如果不存在则抛出异常;
count()
count()方法用来返回一个字符串在另一个字符串中出现的次数。
>s="apple,peach,banana,peach,pear"
>s.find("peach") #在s字符串中查找peach出现的位置(下标)
6>s.find("peach",7) #从s字符串下标为7的位置开始找peach
19
>s.find("peach",7,20) #从s字符串下标从7开始到20结束的区间找peach
-1>s.rfind('p') #从右向左找
25>s.index('p') #查找p在字符串中第一次出现的位置
1
>s.index('pe')
6
>s.index('pear')
25
>s.index('ppp')
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
s.index('ppp')
ValueError: substring not found
>s.count('p')
5
>s.count('pp')
1
>s.count('ppp')
0
split()、rsplit()
split()和rsplit()方法分别用来以指定字符串为分隔符,将字符串左端和右端开始将其分割成多个字符串,并返回包含分隔结果的列表;
partition()、rpartition()
partition()和rpartition()用来以指定字符串为分隔符将原字符分割为3部分,即分隔符前的字符串、分隔符字符串、分隔符后的字符串,如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串。
>s="apple,peach,banana,pear"
>li=s.split(",")
>li
['apple', 'peach', 'banana', 'pear'] #输出列表>s.partition(',')
('apple', ',', 'peach,banana,pear')
>s.rpartition(',')
('apple,peach,banana', ',', 'pear')
>s.partition('banana')
('apple,peach,', 'banana', ',pear')>s="2014-10-31"
>t=s.split("-") #遇到-号就分隔
>print(t)
['2014', '10', '31']
>print(list(map(int,t)))
[2014, 10, 31]
对于split()和rsplit()方法,如果不指定分隔符,则字符串中的人任何空白符号(包括空格、换行符、制表符等等;多个算一个)都将被认为是分隔符,返回包含最终分割结果的列表。
>s='hello world \n\n My name is Dong'
>s.split()
['hello', 'world', 'My', 'name', 'is', 'Dong']>s='\n\nhello world \n\n\n My name is Dong '
>s.split()
['hello', 'world', 'My', 'name', 'is', 'Dong']>s='\n\nhello\t\t world \n\n\n my name\t is Dong '
>s.split()
['hello', 'world', 'my', 'name', 'is', 'Dong']
split()和rsplit()方法还允许指定最大分隔次数
>s='\n\nhello\t\t world \n\n\n My name is Dong '
>s.split(None,1) #None表示不指定分隔符,使用任意空白字符作为分隔符;最大只分隔一次
['hello', 'world \n\n\n My name is Dong ']
>s.rsplit(None,1) #从右往左,分隔一次
['\n\nhello\t\t world \n\n\n My name is', 'Dong']>s.split(None,2) #从左往右,分隔两次
['hello', 'world', 'My name is Dong ']
>s.rsplit(None,2) #从右往左,分隔两次
['\n\nhello\t\t world \n\n\n My name', 'is', 'Dong']>s.split(maxsplit=6) #指定最大分隔次数为6次
['hello', 'world', 'My', 'name', 'is', 'Dong']
>s.split(maxsplit=100) #指定最大分隔次数为100次
['hello', 'world', 'My', 'name', 'is', 'Dong']
调用split()方法并且不传递任何参数时,将使用空白字符作为分隔符,把连续多个空白字符看作一个;明确传递参数指定split()使用分隔符时,情况略有不同。
>'a,,,bb,,cc'.split(',')
['a', '', '', 'bb', '', 'cc']>'a\t\t\tbb\t\tccc'.split('\t')
['a', '', '', 'bb', '', 'ccc']
>'a\t\tbb\t\tccc'.split()
['a', 'bb', 'ccc']
partition()和rpartition()方法以指定字符串为分隔符将原字符串分隔为3部分,即分隔符之前的字符串、分隔符字符串和分隔符之后的字符串。
>s="apple,peach,banana,pear"
>s.partition(',')
('apple', ',', 'peach,banana,pear')
>s.rpartition(',')
('apple,peach,banana', ',', 'pear')>s.partition('banana')
('apple,peach,', 'banana', ',pear')
>s.partition('banana')
('apple,peach,', 'banana', ',pear')>'abababab'.partition('a')
('', 'a', 'bababab')
>'abababab'.rpartition('a')
('ababab', 'a', 'b')
join()
字符串连接join()
>li=["apple","peach","banana","pear"]
>sep="," #指定分隔符
>s=sep.join(li) #使用分隔符的方法join,就可以将列表中的字符串连接起来
>s
'apple,peach,banana,pear'
+
不推荐使用+运算符连接字符串,优先使用join()方法
#+运算符连接字符串
import timeitstrlist=['This is a long string that will not keep in memory.' for n in range(10000)]def use_join():return "".join(strlist)
def use_plus():result=""for strtemp in strlist:result=result+strtempreturn result#上面的测试代码
if__name__=='__main__':times=1000#从__main__中导入并调用use_joinjointimer=timeit.Timer('use_join()','from import use_join')print("time for join:",jointimer.timeit(number=times))plustimer=timeit.Timer('use_plus()','from __main__ import use_plus')print('time for plus:',plustimer.timeit(number=times))timeit模块还支持下面代码演示的用法,从运行结果可以看出当需要对大量数据进行类型转换时,内置函数map()可以提供非常高的效率。
#执行的语句,执行的次数
>timeit.timeit('"-".join(str(n) for n in range(100))',number=10000)
0.09980920003727078
>timeit.timeit('"-".join([str(n) for n in range(100)])',number=10000)
0.07888470002217218
>timeit.timeit('"-".join(map(str,range(100)))',number=10000)
0.06950240000151098
lower()、upper()、capitalize(0、title()、swapcase()
#返回的都是新字符串,并不是在原来的字符串上进行修改
>s="What is Your Name?"
>s.lower() #返回小写字符串
'what is your name?'>s.upper() #返回大写字符串
'WHAT IS YOUR NAME?'>s.capitalize() #字符串首字符大写
'What is your name?'>s.title() #每个但单词的首字母大写
'What Is Your Name?'>s.swapcase() #大小写互换
'wHAT IS yOUR nAME?'
replace()
查找替换replace(),类似于“查找与替换”功能
#实际是返回一个新字符串
>s="中国,中国"
>s
'中国,中国'>s2=s.replace("中国","中华人民共和国") #s中查找所有的中国,并全部替换
>s2
'中华人民共和国,中华人民共和国'
敏感词替换
测试用户输入的是否是敏感词,如果有敏感词的话就把敏感词替换为3个星号***。
>words=('测试','非法','暴力','话')
>text='这句话里含有非法内容'
>for word in words:
if word in text:
text=text.replace(word,'***') #这句话中的所有查到的这个词全部替换
>text
'这句***里含有***内容'
maketrans()、translate()
字符串对象的maketrans()、方法用来生成字符映射表,而translate()方法用来根据映射表中定义的对应关系转换字符串并替换其中的字符,使用这两个方法的组合可以同时处理多个不同的字符,replace()方法则无法满足这一要求。
#创建映射表,将字符“abcdef123”一一对应转换为“uvwxyz@#$”
>table=''.maketrans('abcdef123','uvwxyz@#$')
>s="Python is a greate programming language. I like it!"
>s.translate(table)
'Python is u gryuty progrumming lunguugy. I liky it!' #按照映射表进行替换
凯撒加密
>import string #导入模块
>def kaisa(s,k):
lower=string.ascii_lowercase #模块中的.ascii_lowercase,所有的小写字母
upper=string.ascii_uppercase #所有的大写字母
before=string.ascii_letters #所有的英文字母
after=lower[k:]+lower[:k]+upper[k:]+upper[:k] #大小写字母分别围城一圈,在第k位置分割
table=''.maketrans(before,after)
return s.translate(table)>s="Python is a greate programming language. I like it!"
>kaisa(s,3)
'Sbwkrq lv d juhdwh surjudpplqj odqjxdjh. L olnh lw!'
strip()、rstrip()、lstrip()
strip():删除两边的空白字符;删除指定字符。
rstrip():删除字符串左边的空白字符或指定字符。
lstrip():删除字符串右边的空白字符或指定字符。
>s=" abc "
>s2=s.strip() #不带任何参数,strip()删除空白字符
>s2
'abc'>'\n\nhello world \n\n'.strip() #删除空白字符
'hello world'>"aaaassddf".strip("a") #删除指定字符
'ssddf'
>"aaaassddf".strip("af") #两边所有的a和f
'ssdd'>"aaaassaaddf".strip("a")
'ssaaddf'>"aaaassddfaaa".rstrip("a") #删除字符串右端指定的字符
'aaaassddf'>"aaaassddfaaa".lstrip("a") #删除字符串左端指定的字符
'ssddfaaa'
这三个函数的参数指定的字符串并不作为一个整体对待,而是在原字符串的两侧、右侧、左侧删除参数字符串中包含的所有字符,一层一层地从外往里扒
#不是在原来的字符串中删,是返回一个新字符串(字符串是不可变的)
>"aabbccddeeeffg".strip("af") #字母f不在字符串两侧,所以不删除
'bbccddeeeffg'>"aabbccddeeeffg".strip("gaf")
'bbccddeee'>"aabbccddeeeffg".strip("gbaef")
'ccdd'>"aabbccddeeeffg".strip("gbaefcd")
''
eval()
内置函数eval()
>eval("3+4") #对字符串求值
7
>a=3
>b=5
>eval("a+b") #对表达式求值
8
>import math
>eval('help(math.sqrt)') #相当于'help(math.sqrt)
Help on built-in function sqrt in module math:sqrt(x, /)
Return the square root of x.>eval('math.sqrt(3)')
1.7320508075688772
>eval('aa')
Traceback (most recent call last):
File "<pyshell#57>", line 1, in <module>
eval('aa')
File "<string>", line 1, in <module>
NameError: name 'aa' is not defined. Did you mean: 'a'?
eval()函数是非常危险的,可以执行任意的表达式
>a=input("Please input:")
#导入模块,调用方法,指定程序
Please input:__import__('os').startfile(r'C:\\Windows\notepad.exe')>eval(a)
eval(__import__('os').system('md testtest')) #md创建文件
Traceback (most recent call last):
File "<pyshell#60>", line 1, in <module>
eval(__import__('os').system('md testtest'))
TypeError: eval() arg 1 must be a string, bytes or code object
in:成员测试运算符
成员判断,关键字in
列表、元组、字符串、map、range效率低,时间复杂度是线性的,需要从头到尾扫描一遍这个在不在里面;字典和集合不存在这个情况,时间复杂度是常级的
>"a" in "abcde" #测试
True>"ab" in "abcde"
True
>"ac" in "abcde"
False
>"j" in "abcde"
False
序列重复:*
python字符串支持与整数的乘法运算,表示序列重复,也就是字符串内容的重复。(字典和集合不行)
>'abcd'*3
'abcdabcdabcd'
startswith()、endswith()
s.startswith(t)、s.endswith(t),判断字符串是否以指定字符串开始或结束。
>s='Beautiful is better than ugly.'
>s.startswith('Be') #检测整个字符串
True
>s.startswith('Be',5) #从下标为5的位置开始找
False
>s.startswith('Be',0,5) #起始位置, 0-5之间找
True
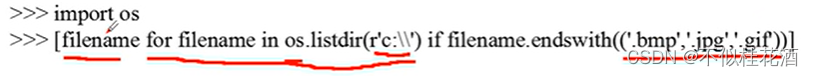
os是python的一个标准库,其中它有一个函数listdir,指定路径;C盘根目录下所有这个三个类型结尾的图片
center()、ljust()、rjust(),返回指定宽度的新字符串,原字符串居中、左对齐或右对齐出现在新字符串中,如果指定宽度大于字符串长度,则使用指定的字符(默认为空格)进行填充。
>'Hello world!'.center(20) #生成具有20个字符宽度的字符串,原来的字符串居中
' Hello world! '
>'Hello world!'.center(20,'=') #居中对齐,以字符=进行填充
'====Hello world!===='
>'Hello world!'.ljust(20,'=') #左对齐
'Hello world!========'
>'Hello world!'.rjust(20,'=') #右对齐
'========Hello world!'
zfill()
zfill()返回指定宽度的字符串,在左侧以字符0进行填充。
>'abc'.zfill(5) #生成一个新字符串,字符串有5个字符;在左侧填充数字字符0
'00abc'
>'abc'.zfill(2) #指定宽度小于字符串长度,返回字符串本身
'abc'
>'abc'.zfill(20)
'00000000000000000abc'
islnum()、isalpha()、isdigit()
islnum()、isalpha()、isdigit()、isdecinmal()、isnumeric()、isspace()、isupper()、islower(),用来测试字符串是否为数字或字母、是否为字母、是否为数字字符、是否为空白字符、是否为大写字母以及是否为小写字母。
>'1234abcd'.isalnum() #测试字符串是否为字母或数字
True
>'1234abcd'.isalpha() #测试字符串是否只包含英文字母;全部为英文字母时,返回True
False
>'1234abcd'.isdigit() #测试字符串是否只包含数字
False
>'abcd'.isalpha()
True
>'1234.0'.isdigit() #isdigit() :主要测试的是整数
False
isdigit()、isdecinmal()、isnumeric()
都是测试字符串是否为数字
>'1234'.isdigit()
True
>'九'.isnumeric() #.isnumeric()方法支持汉字数字
True
>'九'.isdigit()
False
>'九'.isdecimal()
False
>'IVIIIX'.isdecimal()
False
>'IVIIIX'.isdigit()
False
>'IVIIIX'.isnumeric() #.isnumeric() 方法支持罗马数字
True
除了字符串对象提供的方法以外,很多python内置函数也可以对字符串进行操作,例如:
>x='Hello world.'
>len(x) #字符串长度
12
>max(x) #最大字符
'w'
>min(x)
' '
>list(zip(x,x)) #zip()也可以用作于字符串
[('H', 'H'), ('e', 'e'), ('l', 'l'), ('l', 'l'), ('o', 'o'), (' ', ' '), ('w', 'w'), ('o', 'o'), ('r', 'r'), ('l', 'l'), ('d', 'd'), ('.', '.')]
isspace()
是否为空白字符(空格、换行符、制表符)
isupper()、islower()
是否为大写字母;是否为小写字母
切片
字典,集合,无序,不支持下标操作。具有惰性求值特点的也不支持下标操作。
切片也适用于字符串,但仅限于读取其中的元素,不支持字符串修改。
支持下标操作,支持随机访问,列表(可变)、元组、字符串(不可变)
>'Explicit is better than implicit.'[:8]
'Explicit'
>'Explicit is better than implicit.'[9:23]
'is better than'
compress()、decompress()
python标准库zlib中提供的compress()和decompress()函数可以用于数据的压缩和解压缩,在压缩字符串之前需要先编码为字节码。
>import zlib
>x='Python程序设计系列图书,董付国编著,清华大学出版社'.encode() #字符串转化为字节串,默认UTF-8
>len(x) #UTF-8:英文占1个字节,中文一个占3个字节
72
>y=zlib.compress(x) #压缩
>len(y) #长度更大了,字符串没有什么重复的信息
83
>x=('Python系列图书'*3).encode()
>len(x)
54>y=zlib.compress(x) #信息重复度越高,压缩比越大
>len(y)
30
>z=zlib.decompress(y) #解压缩
>len(z)
54
>z.decode() #解码
'Python系列图书Python系列图书Python系列图书'>x=['董付国']*8 #x是一个列表,不能直接压缩,先转换,然后编码
>y=str(x).encode()
>len(y)
104
>z=zlib.compress(y)
>len(z)
26
>zlib.decompress(z).decode()
"['董付国', '董付国', '董付国', '董付国', '董付国', '董付国', '董付国', '董付国']"
4.1.3字符串常量
python标准库string中定义数字字符、标点符号、英文字母、大写字母、小写字母等常量。
>import string
>string.digits #.digits常量包含了所有数字字符
'0123456789'
>string.punctuation #.punctuation是一些标点符号
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
>string.ascii_letters #.ascii_letters:所有的英语字母大写+所有的英语字母小写
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
>string.ascii_lowercase #.ascii_lowercase:所有小写字母
'abcdefghijklmnopqrstuvwxyz'
>string.ascii_uppercase #.ascii_uppercase:所有大写字母
'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
随机密码生成原理
>import string
>x=string.digits+string.ascii_letters+string.punctuation #数字+大小写字母+标点符号
>x
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'>import random
''.join([random.choice(x) for i in range(8)]) #生成的密码长度8
'EaJ)h"N<'
''.join([random.choice(x) for i in range(8)])
'?^0Y:3/<'
''.join([random.choice(x) for i in range(8)])
"'vP-&-0w"
''.join([random.choice(x) for i in range(8)])
']\\aXjIRL'
4.1.4可变字符串
在python中,字符串属于不可变对象,不支持原地修改,如果需要修改其中的值,只能重新创建一个新的字符串对象。然而,如果其中确实需要一个支持原地修改的unicode数据对象,可以使用io.StringIO对象或array模块(数组)。
>import io #导入io模块
>s="Hello,world"
>sio=io.StringIO(s) #以字符串为参数,创建一个StringIO对象
>sio.getvalue() #创建好的对象有一个方法是.getvalue(),查看里面你的内容是什么
'Hello,world'>sio.seek(7) #.seek:找到字符串下标为7的位置
7
>sio.write("there!") #在位置7的位置写there!
6 #返回的是我们成功的写入了几个字符>sio.getvalue()
'Hello,wthere!'
>import array #数组,array模块#array模块中有一个array类
>a=array.array('u',s) #首先创建一个数组对象,初始化(类型,原始数据)
>print(a)
array('u', 'Hello,world') #a是array对象>a[0]='y' #数组是可变的,直接修改
>print(a)
array('u', 'yello,world')>a.tounicode() #生成unicode字符串
'yello,world'
4.1.5字符串应用案例精选
例4-1
编写函数实现字符串加密和解密,循环使用指定密钥,采用简单的异或运算法。
#编写函数实现字符串加密和解密,循环使用指定密钥,采用简单的异或运算法。
#异或:A^B^B=A;1^1=0^0=0;1^0=0^1=1
def crypt(source,key): #传入的参数(明文,密钥)#itertool标准库中有cycle类from itertools import cycleresult='' #空字符串temp=cycle(key) #对密钥创建一个cycle对象,首尾相接;可迭代的对象for ch in source:#对明文每个,ord(ch):首先算出ascii码#ord(next(temp))获取cycle可迭代对象的下一个字符,算出ascii码#两个数字才能进行异或运算,两个字符不行#chr:数字变字符result=result+chr(ord(ch)^ord(next(temp)))return resultsource='Shandong Institute of Business and Technology'
key='Dong FuGuo'print('Before Encrypted:'+source)
encrypted=crypt(source,key)
print('After Encrypted:'+encrypted)
decrypted=crypt(encrypted,key)
print('After Decrypted:'+decrypted)
例4-2
编写程序,生成大量随机信息,这在需要获取大量数据来测试或演示软件功能的时候非常有用,不仅能真实展示软件功能或算法,还可以避免泄露真实数据或是引起不必要的争议。
P32、33、34、35、36
Python字符串与正则表达式1:字符串编码与格式化_哔哩哔哩_bilibili
Python字符串与正则表达式2:字符串方法1_哔哩哔哩_bilibili
Python字符串与正则表达式3:字符串方法2_哔哩哔哩_bilibili
Python字符串与正则表达式4:字符串方法3_哔哩哔哩_bilibili







![[Angular 基础] - 自定义指令,深入学习 directive](https://img-blog.csdnimg.cn/direct/83bec61bd0c1408db7e060b7fddd1d6e.gif#pic_center)