【力扣hot100】刷题笔记Day10
前言
- 一鼓作气把链表给刷完!!中等题困难题冲冲冲啊啊啊!
25. K 个一组翻转链表 - 力扣(LeetCode)
-
模拟
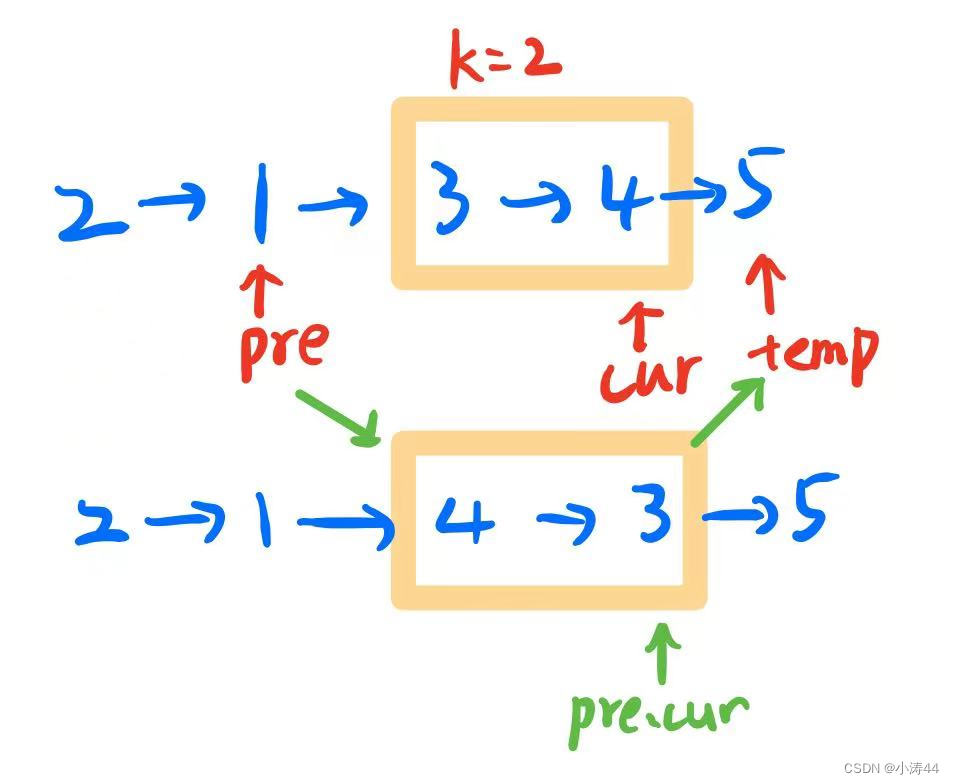
-
class Solution:def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:# 翻转链表前k项def reverse(head, k):pre, cur = None, headwhile cur and k:temp = cur.nextcur.next = prepre = curcur = tempk -= 1return pre, head # pre为头,head为尾dummy = ListNode(0, head)pre = cur = dummycount = k # 用于重复计数while cur.next and count:count -= 1cur = cur.nextif count == 0:temp = cur.next # 存一下段后节点pre.next, cur = reverse(pre.next, k) # 连接段前+翻转cur.next = temp # 连上段后节点pre = cur # 更新pre指针count = k # 恢复count继续遍历return dummy.next
138. 随机链表的复制 - 力扣(LeetCode)
- 路飞的题解真是太强啦!!优雅清晰简洁
-
哈希表
-
"""
# Definition for a Node.
class Node:def __init__(self, x: int, next: 'Node' = None, random: 'Node' = None):self.val = int(x)self.next = nextself.random = random
"""class Solution:def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':if not head: return Nonedic = {}# 1. 复制各节点,并建立 “原节点 -> 新节点” 的 Map 映射cur = headwhile cur:dic[cur] = Node(cur.val)cur = cur.next# 2. 构建新节点的 next 和 random 指向cur = headwhile cur:dic[cur].next = dic.get(cur.next)dic[cur].random = dic.get(cur.random)cur = cur.next# 3. 返回新链表的头节点 return dic[head]
-
拼接 + 拆分
-
class Solution:def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':if not head: return Nonedic = {}# 1. 复制各节点,并构建拼接链表cur = headwhile cur:temp = Node(cur.val)temp.next = cur.nextcur.next = tempcur = temp.next# 2. 构建各新节点的 random 指向cur = headwhile cur:if cur.random:cur.next.random = cur.random.nextcur = cur.next.next# 3. 拆分两链表cur = newhead = head.nextpre = headwhile cur.next:pre.next = pre.next.nextcur.next = cur.next.nextpre = pre.nextcur = cur.nextpre.next = None # 单独处理原链表尾节点return newhead # 返回新链表头节点
148. 排序链表 - 力扣(LeetCode)
-
归并排序(顶到底递归)
- 参考路飞题解
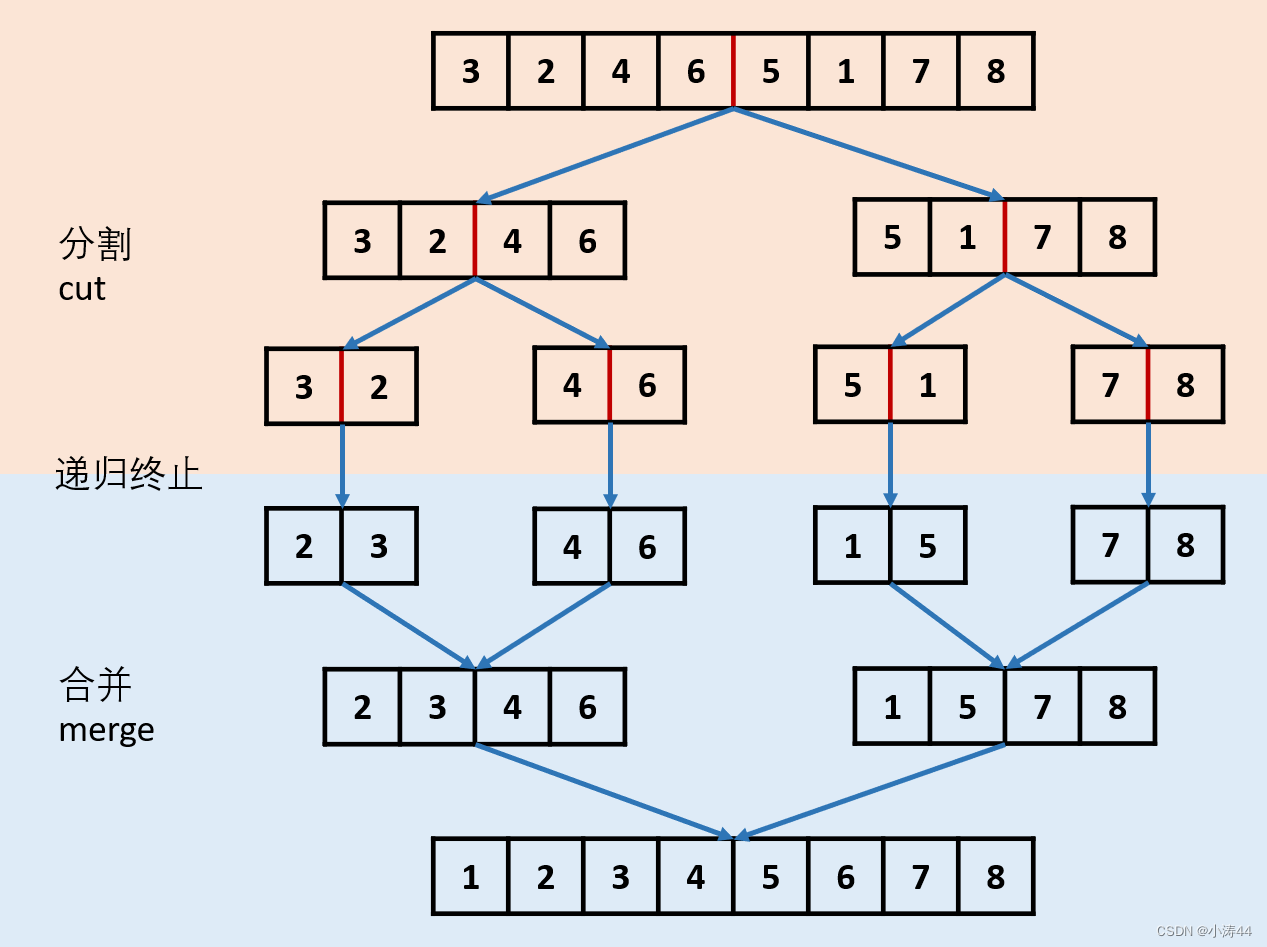
-
class Solution:def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:if not head or not head.next: return head# 快慢指针分割链表slow, fast = head, head.nextwhile fast and fast.next:fast, slow = fast.next.next, slow.nextmid = slow.next # 右半部分的头节点slow.next = None # 断开两部分# 递归进行归并排序left = self.sortList(head)right = self.sortList(mid)# 合并左右两个链表dummy = cur = ListNode(0)while left and right: # 根据大小依次插入新链表if left.val < right.val:cur.next = leftleft = left.nextelse:cur.next = rightright = right.nextcur = cur.nextcur.next = left if left else right # 接上剩下的return dummy.next
-
归并排序(底到顶合并)
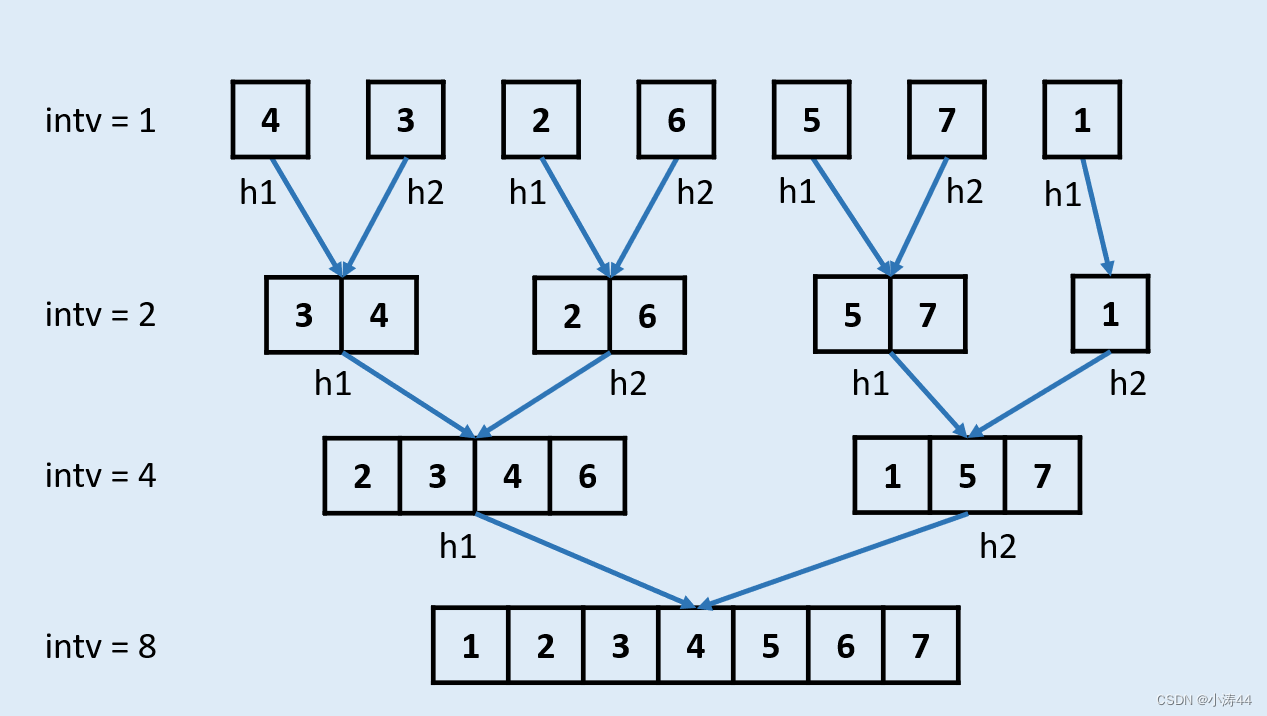
-
class Solution:def sortList(self, head: ListNode) -> ListNode:# 合并两个有序链表def merge(head1, head2):dummy = cur = ListNode(0)while head1 and head2:if head1.val < head2.val:cur.next = head1head1 = head1.nextelse:cur.next = head2head2 = head2.nextcur = cur.nextcur.next = head1 if head1 else head2return dummy.next# 如果只有一个节点直接返回headif not head: return head# 统计链表长度lenth = 0cur = headwhile cur:cur = cur.nextlenth += 1# 开始循环合并dummy = ListNode(0, head)sublenth = 1while sublenth < lenth:pre, cur = dummy, dummy.nextwhile cur:head1 = curfor i in range(1, sublenth):if cur.next:cur = cur.nextelse:break # 如果还没找到head2说明不用合并,下一轮head2 = cur.nextif not head2: break # 空就不合并了cur.next = None # 断开第一段后cur = head2for i in range(1, sublenth):if cur.next:cur = cur.nextelse:breaktemp = cur.next cur.next = None # 断开第二段后cur = tempmerged = merge(head1, head2) # 合并pre.next = mergedwhile pre.next:pre = pre.next # pre更新到合并后链表的最后pre.next = temp # 重新连接第二段后# 下一轮合并sublenth *= 2return dummy.next
23. 合并 K 个升序链表 - 力扣(LeetCode)
-
依次合并
-
class Solution:def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:# 合并两个有序链表def merge(head1, head2):dummy = cur = ListNode(0)while head1 and head2:if head1.val < head2.val:cur.next = head1head1 = head1.nextelse:cur.next = head2head2 = head2.nextcur = cur.nextcur.next = head1 if head1 else head2return dummy.nextlenth = len(lists)if lenth == 0:return None# 每遍历一个链表就合并掉dummyhead = ListNode(0)for i in range(0, len(lists)):dummyhead.next = merge(dummyhead.next, lists[i])return dummyhead.next
-
分治合并
-
class Solution:def mergeKLists(self, lists: List[ListNode]) -> ListNode:# 如果输入为空,直接返回空if not lists:return # 获取链表列表的长度n = len(lists)# 调用递归函数进行合并return self.merge(lists, 0, n-1)def merge(self, lists, left, right):# 当左右指针相等时,表示只有一个链表,直接返回该链表if left == right:return lists[left]# 计算中间位置mid = left + (right - left) // 2# 递归地合并左半部分和右半部分的链表l1 = self.merge(lists, left, mid)l2 = self.merge(lists, mid+1, right)# 调用合并两个有序链表的函数return self.mergeTwoLists(l1, l2)def mergeTwoLists(self, l1, l2):# 若其中一个链表为空,则直接返回另一个链表if not l1:return l2if not l2:return l1# 比较两个链表头结点的大小,选择较小的作为新链表的头结点if l1.val < l2.val:l1.next = self.mergeTwoLists(l1.next, l2)return l1else:l2.next = self.mergeTwoLists(l1, l2.next)return l2
-
最小堆
-
"""
假设有3个有序链表分别是:1->4->5, 1->3->4, 2->6。
初始时,最小堆为空。我们依次将(1,0),(1,1),(2,2)加入最小堆。
然后不断弹出最小值(1,0),(1,1),(2,2),加入到结果链表中,
并将对应链表的下一个节点值和索引加入最小堆,直到最小堆为空。
最终得到的合并后的链表为1->1->2->3->4->4->5->6
"""
class Solution:def mergeKLists(self, lists: List[ListNode]) -> ListNode:import heapq# 创建虚拟节点dummy = ListNode(0)p = dummyhead = []# 遍历链表数组for i in range(len(lists)):if lists[i] :# 将每个链表的头结点值和索引加入到最小堆中heapq.heappush(head, (lists[i].val, i))lists[i] = lists[i].nextwhile head:# 弹出最小堆中的值和对应的索引val, idx = heapq.heappop(head)# 创建新节点并连接到结果链表上p.next = ListNode(val)p = p.next# 如果该链表还有剩余节点,则将下一个节点的值和索引加入到最小堆中if lists[idx]:heapq.heappush(head, (lists[idx].val, idx))lists[idx] = lists[idx].next# 返回合并后的链表return dummy.next
146. LRU 缓存 - 力扣(LeetCode)
-
哈希 + 双向链表
- 借用灵神题解的图,really good
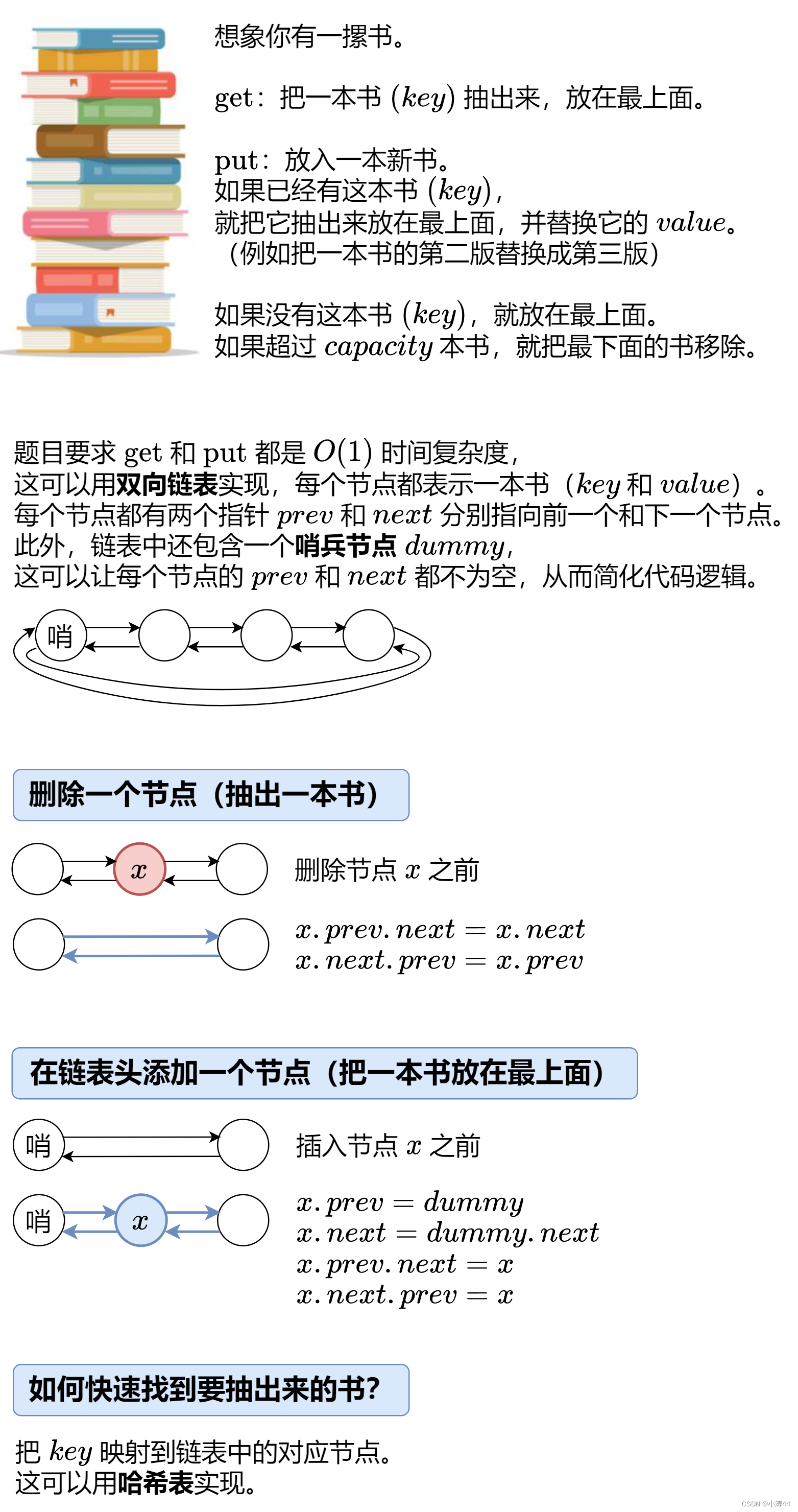
-
class Node:# 提高访问属性的速度,并节省内存__slots__ = 'prev', 'next', 'key', 'value'def __init__(self, key=0, value=0):# self.prev = None# self.next = Noneself.key = keyself.value = valueclass LRUCache:def __init__(self, capacity: int):self.capacity = capacityself.dummy = Node() # 哨兵节点self.dummy.prev = self.dummyself.dummy.next = self.dummyself.key_to_node = dict()def get_node(self, key: int) -> Optional[Node]:if key not in self.key_to_node: # 没有这本书return Nonenode = self.key_to_node[key] # 有这本书self.remove(node) # 把这本书抽出来self.push_front(node) # 放在最上面return nodedef get(self, key: int) -> int:node = self.get_node(key)return node.value if node else -1def put(self, key: int, value: int) -> None:node = self.get_node(key)if node: # 有这本书node.value = value # 更新 valuereturnself.key_to_node[key] = node = Node(key, value) # 新书self.push_front(node) # 放在最上面if len(self.key_to_node) > self.capacity: # 书太多了back_node = self.dummy.prevdel self.key_to_node[back_node.key]self.remove(back_node) # 去掉最后一本书# 删除一个节点(抽出一本书)def remove(self, x: Node) -> None:x.prev.next = x.nextx.next.prev = x.prev# 在链表头添加一个节点(把一本书放在最上面)def push_front(self, x: Node) -> None:x.prev = self.dummyx.next = self.dummy.nextx.prev.next = xx.next.prev = x# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
后言
- 链表终于结束了!后面这几道真是难到我了,基本都是CV写出来的,还是得多沉淀啊 !休息一下,晚上干点活了,不然新学期要被老板骂骂
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/263612.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!