目录
1. 什么是Spring Web MVC
1.1 MVC的定义
1.2 什么是Spring MVC
1.3 Spring Boot
1.3.1 创建一个Spring Boot项目
1.3.2 Spring Boot和Spring MVC之间的关系
2. 学习Spring MVC
2.1 SpringBoot 启动类
2.2 建立连接

1. 什么是Spring Web MVC
1.1 MVC的定义
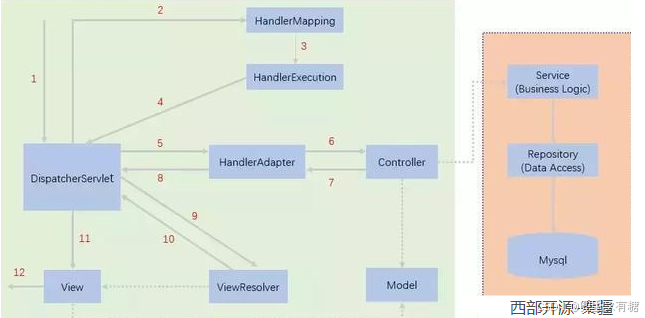
MVC 是 Model View Controller 的缩写,它是软件⼯程中的⼀种软件架构设计模式,它把软件系统分为模型、视图和控制器三个基本部分

- View(视图) 指在应⽤程序中专⻔⽤来与浏览器进⾏交互,展⽰数据的资源
- Model(模型) 是应⽤程序的主体部分,⽤来处理程序中数据逻辑的部分
- Controller(控制器)可以理解为⼀个分发器,⽤来决定对于视图发来的请求,需要⽤哪⼀个模型来处理,以及处理完后需要跳回到哪⼀个视图。即⽤来连接视图和模型
总而言之,MVC 是⼀种架构设计模式, 可以理解为是一种设计思想。
1.2 什么是Spring MVC
MVC 是⼀种架构设计模式, 也是⼀种思想。而 Spring MVC 是对 MVC 思想的具体实现。除此之外, Spring MVC还是⼀个Web框架。
总结来说,Spring MVC 是⼀个实现了 MVC 模式的 Web 框架
所以, Spring MVC主要关注有两个点:
- MVC(一种架构设计模式)
- Web框架(Spring MVC 的全程就是 Spring Web MVC)
1.3 Spring Boot
1.3.1 创建一个Spring Boot项目
创建一个Spring Boot项目:

点击Next之后,此处勾选的Spring Web框架其实就是Spring MVC框架:

可以看到,Spring Web的介绍是:
Build web, including RESTful, applications using Spring MVC. Uses Apache Tomcat as the default embedded container
1.3.2 Spring Boot和Spring MVC之间的关系
SpringBoot是2014年发布的, Spring 是2004年发布的, 在2014年发布之前, Spring MVC框架也能使用其他方法实现,只不过不是使用SpringBoot。
也就是说,Spring Boot 只是实现Spring MVC的其中⼀种⽅式⽽已.
Spring Boot 可以添加很多依赖, 借助这些依赖实现不同的功能. Spring Boot 通过添加Spring Web
MVC框架, 来实现web功能.
打一个比方:
厨房可以⽤来做饭, 但真实实现做饭功能的是⽕以及各种做饭相关的⻝材和⼯具.厨房就好⽐是SpringBoot, 厨房可以装柜⼦, 实现收纳功能, 装燃⽓灶等, 实现做饭功能.做饭这个事, 就是MVC, 在⼏千年前, 有⽕有⻝材就可以实现做饭
2. 学习Spring MVC
当用户在浏览器中输⼊了 url 之后,我们的 Spring MVC 项⽬就可以感知到用户的请求, 并给予响应.
主要分以下三个⽅⾯:
- 建立连接:将用户(浏览器)和 Java 程序连接起来,也就是访问⼀个地址能够调用到我们的 Spring 程序
- 请求: ⽤⼾请求的时候会带⼀些参数,在程序中要想办法获取到参数, 所以请求这块主要是获取参数的功能
- 响应: 执⾏了业务逻辑之后,要把程序执⾏的结果返回给用户, 也就是响应
2.1 SpringBoot 启动类
@SpringBootApplication 是 SpringBoot 启动类的注解:

运行这个启动类的 main 方法就可以运行 Spring Boot 项目了:

2.2 建立连接
在 Spring MVC 中使⽤ @RequestMapping 来实现 URL 路由映射 ,也就是浏览器连接程序的作用
利用 @requestMapping 写第一个程序:输出Hello World:
@RequestMapping("user")
@RestController
public class UserController {@RequestMapping("m1")public String r1(){return "Hello world";}
} 重新启动项⽬,访问 http://127.0.0.1:8080/r1 最终效果如下:

对于 http://127.0.0.1:8080/user/m1 这个网址的解释:
① 127.0.0.1是本机的IP地址
② 8080是端口号
为什么要用8080这个端口号?
因为SpringBoot 内置了Tomcat服务器
(常⻅的Web服务器有: Apache,Nginx, IIS, Tomcat, Jboss等 )
Tocmat默认端⼝号是8080, 所以我们程序访问时的端⼝号也是8080

完
如果哪里有疑问的话欢迎来评论区指出和讨论,如果觉得文章有价值的话就请给我点个关注还有免费的收藏和赞吧,谢谢大家!