写在前面
本文记录es的零碎知识点,包括但不限于概念,集群方式,等。
1:词项查询 VS 全文查询
词项查询:查询的内容不做分词处理,输入的什么查询什么。
全文查询:查询的内容会做分词处理,生成多个词项,然后对每个词项分别查询,所有的查询结果汇总在一起,作为最终的结果。
具体参考这里 。
2:Query Context VS Filter Context
Query Context:算分的上下文。
Filter Context:不算分的上下文。
3:copy_to
使用copy_to,如下:

测试:
# 1:先删除索引,因为前面创建过了
DELETE users
# 2:创建索引,并指定firstName的null_value
PUT users
{"mappings": {"properties": {"firstName": {"type": "text","copy_to": "fullName"},"lastName": {"type": "text","copy_to": "fullName"}}}
}
# 3:创建新数据
POST users/_create/1
{"firstName": "jack","lastName": "james"
}
# 4:搜索在fulleName中包含jack或者是包含james的,可以正常搜索到
GET users/_search?q=fullName:(jack james)
{"profile": "true"
}
4:常见分词器
4.1:中文分词器
ik 。
icu 。
pinyin 分词为拼音
配置:
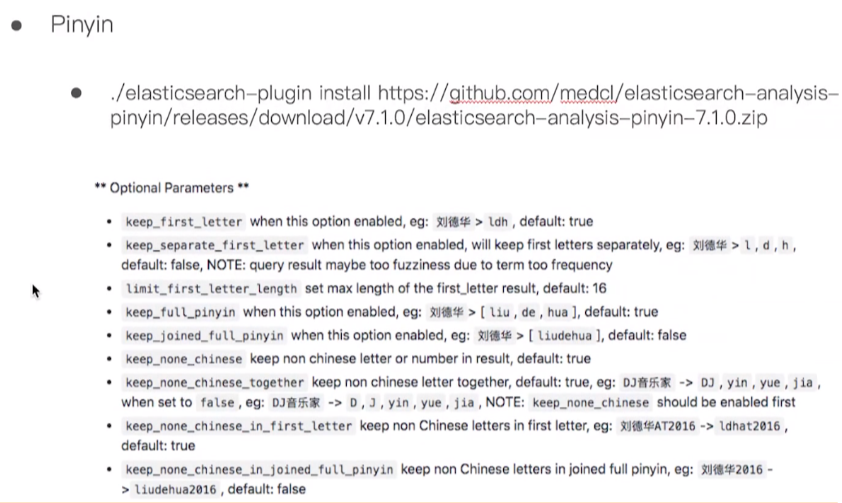
例子:
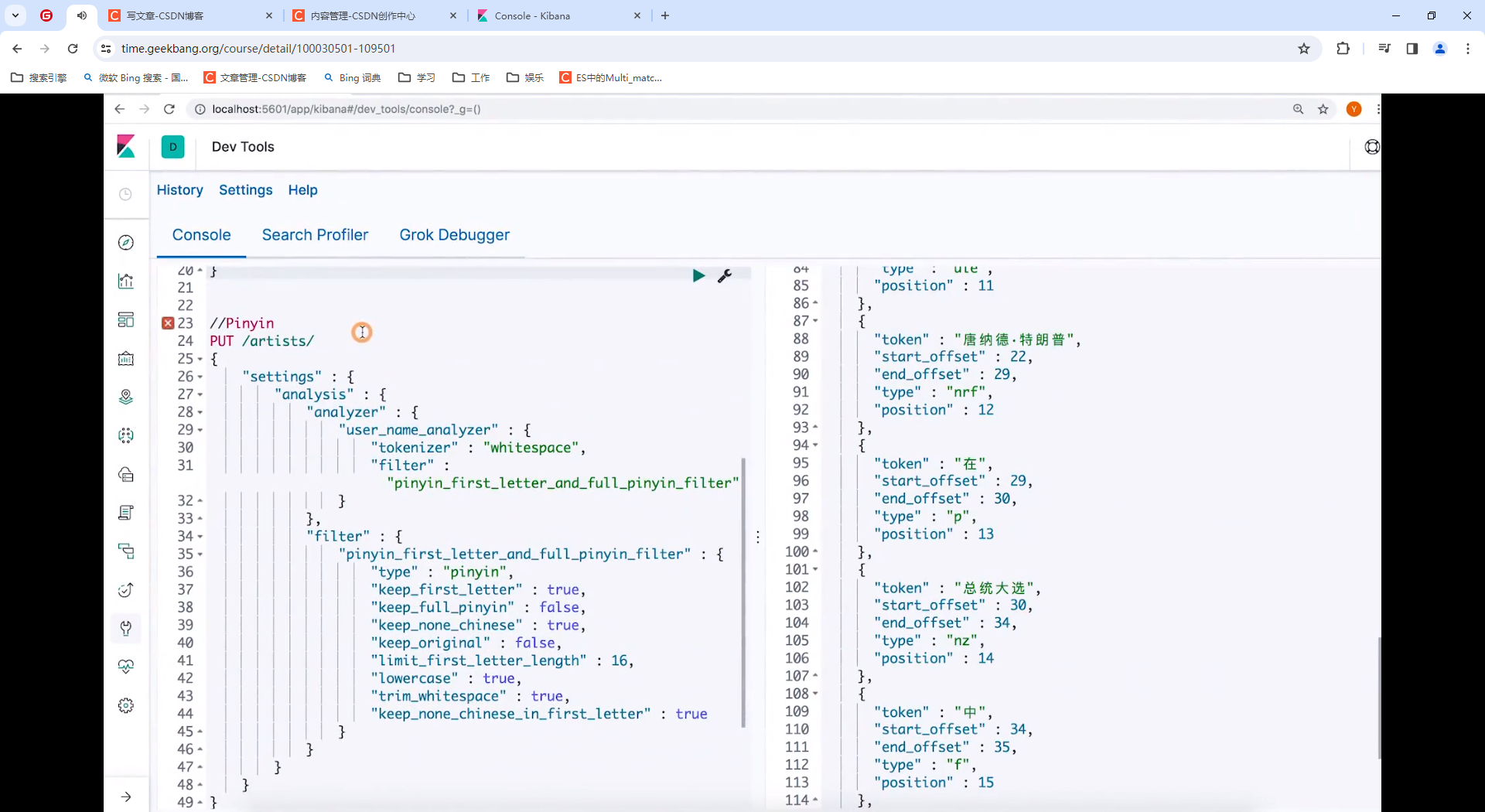

- HanLP
安装参考pinyin ,下载参考下图:

5:相关性,相关文档,precision,recall
- 相关性
1:需要找到的文档都找到了?
2:找到了多少错误的文档??
3:找到的文档评分高低是否符合预期???
- 相关文档
应该找到的文档。 - precision,recall
如果找到的文档我们标记为positive,没有找到的文档标记为negative,然后我们用true来表示找到的该找到的,没找到的不该找到的,用false来表示没找到的该找到的,找到的不该找到的绕啊!!!,则我们可以得到下图:
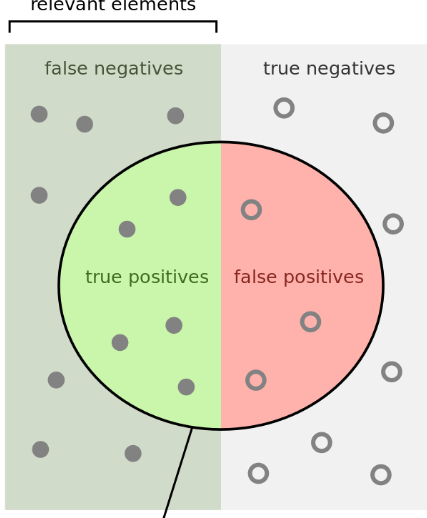
precision就是:返回的文档中相关文档数/返回的文档数
recall就是:返回的相关文档/总相关文档
如下图:
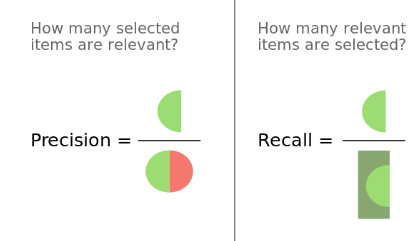
一般搜索时尽量提高recall值是我们的目标。
写在后面
参考文章列表
Elasticsearch:理解搜索中的 precision 及 recall 。