【Unity】unity3D 调用LoadSceneAsync 场景切换后比较暗 部门材质丢失



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/2647.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

R5天气识别学习笔记
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 LSTM-天气识别预测 雨天百分比数据预处理模型训练结果可视化个人总结 import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyp…

SpringMVC (1)
目录
1. 什么是Spring Web MVC
1.1 MVC的定义
1.2 什么是Spring MVC
1.3 Spring Boot
1.3.1 创建一个Spring Boot项目
1.3.2 Spring Boot和Spring MVC之间的关系
2. 学习Spring MVC
2.1 SpringBoot 启动类
2.2 建立连接 1. 什么是Spring Web MVC
1.1 MVC的定义 MVC 是…

【混合开发】CefSharp+Vue 解决Cookie问题
问题表现
使用Element-admin架构搭建Vue前端项目,在与CefSharp搭配时,出现无法使用cookie的问题。
无法将token存入cookiecookie无法被读取
如下图,Cookies下显示file://。 正常的Cookies显示,Cookies显示为http://域名&#x…

jmeter事务控制器-勾选Generate Parent Sample
1、打开jmeter工具,添加线程组,添加逻辑控制器-事务控制器 2、在事务控制器,勾选Generate parent sample:生成父样本;说明勾选后,事务控制器会作为父节点,其下面的请求作为子节点 3、执行&#…

【Linux】进程间通信IPC
目录
进程间通信 IPC
1. 进程间通信方式
2. 无名管道
2.1 特点
2.2 函数接口
2.3 注意事项
3. 有名管道
3.1 特点
3.2 函数接口
3.3 注意事项
3.4 有名管道和无名管道的区别
4. 信号
4.1概念
4.2信号的响应方式
4.3 信号种类
4.4 函数接口
4.4.1 信号发送和挂…
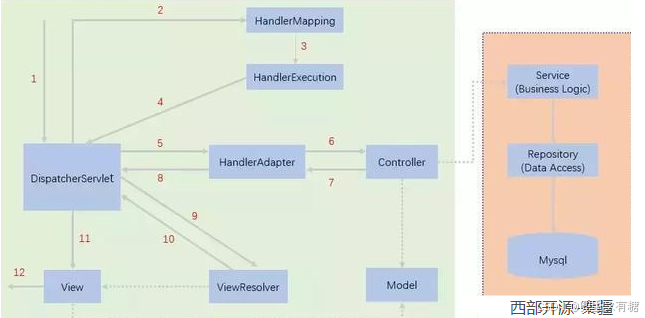
SpringMVC——原理简介
狂神SSM笔记
DispatcherServlet——SpringMVC 的核心
SpringMVC 围绕DispatcherServlet设计。 DispatcherServlet的作用是将请求分发到不同的处理器(即不同的Servlet)。根据请求的url,分配到对应的Servlet接口。 当发起请求时被前置的控制…

openssl s_server源码剥离
初级代码游戏的专栏介绍与文章目录-CSDN博客
我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。
这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。
源码指引:github源…

算法库里的heap算法,仿函数和模版进阶(续)
文章目录 算法库里面的heap仿函数模版非类型模版参数array特化函数模版的特化类模版的特化 分离编译 算法库里面的heap
sort_heap是算法库里的函数,前提要求是堆才能排序is_heap判断是否是堆make_heap建堆算法
int main()
{int a[5] { 10,19,27,39,19 };std::vec…

具身导航如何利用取之不尽的网络视频资源!RoomTour3D:基于几何感知的视频-指令训练调优
作者:Mingfei Han, Liang Ma, Kamila Zhumakhanova, Ekaterina Radionova, Jingyi Zhang, Xiaojun Chang, Xiaodan Liang, Ivan Laptev 单位:穆罕默德本扎耶德人工智能大学计算机视觉系,中山大学深圳校区,悉尼科技大学ReLER实验室…

解决报错:未定义标识符 “M_PI“
问题: 使用C编译,已经用#include <cmath>包含了头文件,但是在使用M_PI时依旧报错说未定义 原因: 在某些编译器中,<cmath> 库中的 M_PI 是一个条件宏,需要 _USE_MATH_DEFINES 宏被定义才能使用。…

TensorFlow深度学习实战(5)——神经网络性能优化技术详解
TensorFlow深度学习实战(5)——神经网络性能优化技术详解 0. 前言1. 识别 MNIST 手写数字1.1 MNIST 数据集1.2 独热编码1.3 定义神经网络1.4 训练神经网络 2. 构建深度神经网络3. 添加 Dropout 提高模型泛化能力4. 不同优化器对模型性能的影响5. 训练 ep…

代码随想录算法训练营day31
代码随想录算法训练营
—day31 文章目录 代码随想录算法训练营前言一、 56. 合并区间二、738. 单调递增的数字三、968.监控二叉树总结 前言
今天是算法营的第31天,希望自己能够坚持下来! 今日任务: ● 56. 合并区间 ● 738.单调递增的数字 …

通过maven命令上传jar包至nexus v3.7.1
1 nexus和maven的简介
1.1 nexus
Nexus是由Sonatype公司开发的一款强大的制品仓库管理软件,主要用于搭建和管理各种类型的仓库,包括Maven、NuGet、npm等。Nexus支持多种仓库类型,如代理仓库(代理互联网中的中央仓库…

level(三) filterblock
filterblock用于确定某个key是否存在于某个datablock中,在插入一个key到datablock中时也会插入一个key到filterblock中,filterblock中会记录所有的key,并通过布隆过滤器来确定一个key是否存于这个datablock中。下面来看下filterblock的代码&a…

优化 Vue项目中 app.js 文件过大,初始化加载过慢、带宽占用过大等问题
已亲测,绝对有效,底部有改善前后对比图证明。
1.服务器 nginx 增加配置
#开启gzip压缩
gzip on;
#设置gzip压缩级别,2级是性价比最高的
gzip_comp_level 2;
#设置动态gzip压缩的文件类型
gzip_types text/plain text/css text/javascript a…

浅谈云计算16 | 存储虚拟化技术
存储虚拟化技术 一、块级存储虚拟化基础2.1 LUN 解析2.1.1 LUN 概念阐释2.1.2 LUN 功能特性 2.2 Thick LUN与Thin LUN2.2.1 Thick LUN特性剖析2.2.2 Thin LUN特性剖析 三、块级存储虚拟化技术实现3.1 基于主机的实现方式3.1.1 原理阐述3.1.2 优缺点评估 3.2 基于存储设备的实现…

手摸手实战前端项目CI CD
由于图片和格式解析问题,为了更好阅读体验可前往 阅读原文 CI/CD 是 持续集成(Continuous Integration) 和 持续交付/部署(Continuous Delivery/Continuous Deployment) 的缩写,是现代软件开发中的一种自动…

【EI 会议征稿通知】第七届机器人与智能制造技术国际会议 (ISRIMT 2025)
第七届机器人与智能制造技术国际会议 (ISRIMT 2025)
2025 7th International Symposium on Robotics & Intelligent Manufacturing Technology
会议主要围绕“机器人”、“智能制造技术” 等研究领域展开讨论,旨在为机器人与智能制造技术等领域的专家学者、工…


基于go语言的驾考系统设计与实现
在Internet时代,Internet信息技术已广泛应用于各个领域。 对人们的生活以及学习产生了较大的影响。通过信息技术建立的驾照考试管理系统,利用系统对驾照考试进行统一的管理,能够提驾照考试管理的工作效率,具有重要的现实意义。
本…