原理参考这篇文章, 这里是原始文章
import torch.nn as nn
import torch
import math
from torch.autograd import Variable# 词嵌入
class Embeddings(nn.Module):# dim:词嵌入的维度,vocab:词表的大小def __init__(self, dim, vocab) -> None:super(Embeddings,self).__init__()# 获取一个词嵌入对象lutself.lut = nn.Embedding(vocab,dim)self.dim = dimdef forward(self,x):return self.lut(x)*math.sqrt(self.dim)# 位置编码器
class PositionalEncoding(nn.Module):def __init__(self,dim,dropout,max_len=5000):"""位置编码器类的初始化dim: 词嵌入维度dropout: 置0比率max_len: 每个句子的最大长度"""super(PositionalEncoding,self).__init__()# 实例化预定义的Dropout层,并将dropout传入其中self.dropout = nn.Dropout(p=dropout)#初始化一个位置编码矩阵,他是一个0矩阵,矩阵的大小 是max_len*dim,这是需要构建的最终的位置形状,只是现在全为0,后面需要进行填充中pe = torch.zeros(max_len,dim)# 初始化一个绝对位置矩阵,词汇的绝对位置就是他的索引# unsqueeze 拓展维度,使其维度为max_len x 1position = torch.arange(0,max_len).unsqueeze(1)# 有了上面的绝对位置了,也就是多少行,后续,需要把每行的对应的位置embeding填充# 因此需要构建一个512维度的矩阵,而这个矩阵又是由sin和cos进行组合而成,因此可以分别考虑div_term = torch.exp(torch.arange(0,dim,2)*-(math.log(10000.0)/dim)) # shape是1*dim/2,间隔为2的目的是2k和2k+1pe[:,0::2] = torch.sin(position*div_term) # ‘:’所有的行,‘::’pe[:,1::2] = torch.cos(position*div_term)# 为了和输入的 emberding 维度相同,需要进行维度扩展pe = pe.unsqueeze(0)self.register_buffer("pe",pe)def forward(self,x):# "x 是文本的emberding"# 相加之前,需要做一些适配的工作,虽然默认句子的长度是max_len=5000,但是实际上很少有句子能达到这个值,因此需要进行一些适配# x 的维度是三维的,第二个维度就是句子的长度即token的数量,第三个维度是每个token的向量x = x+self.pe[:,:x.size(1)]return self.dropout(x)# embedding = nn.Embedding(10,3,padding_idx=0)
# input1 = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
# print(embedding(input1))# input1 = torch.LongTensor([[0,2,0,6]])
# print(embedding)
# print(embedding(input1))
# dim = 512
# vocab =1000# x = Variable(torch.LongTensor([[100,2,321,508],[321,234,456,324]]))
# emb = Embeddings(dim,vocab)
# embr =emb(x)
# print("embr: ", embr)
# print(embr.shape)import matplotlib.pyplot as plt
import numpy as npplt.figure(figsize=(15,5)) # 创建一张15 x 5 大小的画布#实例化PositionalEncoding的对象,输入参数是20,0
pe = PositionalEncoding(20,0) # 位置向量的维度是20,dropout是0input = Variable(torch.zeros(1,100,20)) # 创建一个1*100*20的向量,100是句子的token,20是每个touken的向量维度y = pe(input)# 画图
plt.plot(np.arange(100),y[0,:,4:10].data.numpy())
plt.legend(["dim "+str(x)for x in [4,5,6,7,8,9,10]])plt.show()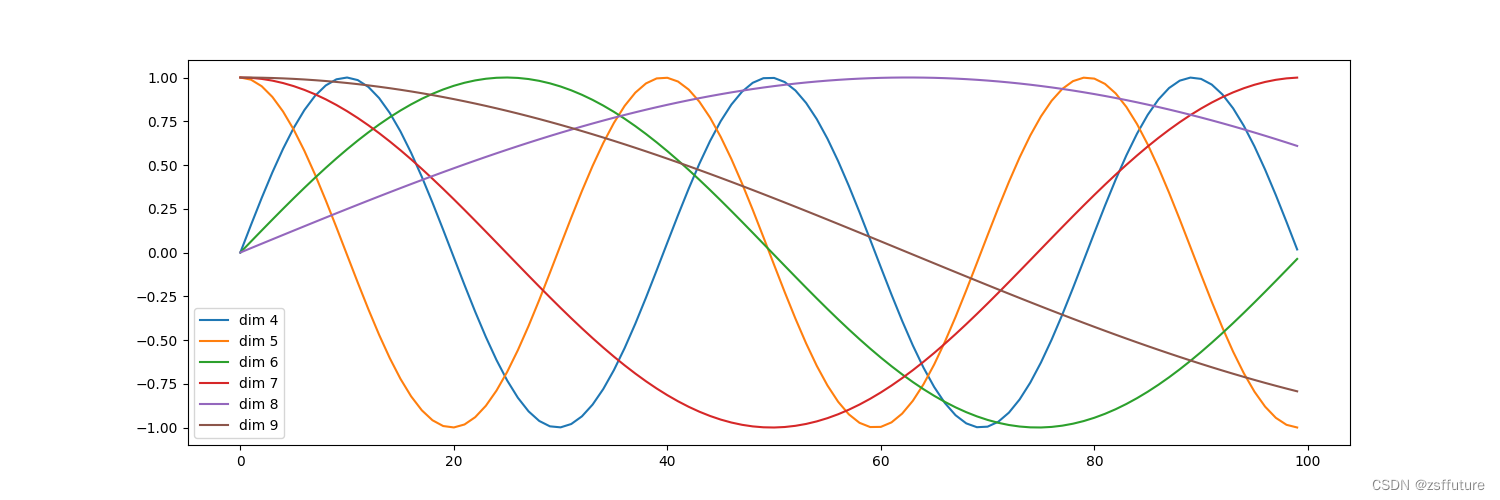
引入位置编码的原理和实现上面都很清楚,我这里只想解释一下这副图,横坐标0到100,相当于一个句子的100个token,正常来说我们可以画每个token 的维度图即20维,因此大家可以想想20个正余弦图,这里只画了6个维度,但是可以说明问题,假如我们以第60个token举例子 ,那么这个token对应的20维的向量都画上去后,直接在60位置上画个竖直线则可以说明这个位置的位置编码信息,加入有个单词在第60的位置出现一次,在第80的位置出现一次,正常来说这两个位置的单词都是一样的,如果没有位置编码,那么他们的向量也是一样的,但是加上位置编码就不一样了,因此更有利于模型学习同一个单词出现在不同位置代表的意义是不一样的,因此这可以很好的把位置信息编码进去




![[Mac软件]Adobe Substance 3D Stager 2.1.4 3D场景搭建工具](https://img-blog.csdnimg.cn/img_convert/43e1e340d57b052e19205822f8611f47.png)
![绝对路径拼接漏洞 [NISACTF 2022]babyupload](https://img-blog.csdnimg.cn/direct/ed2e7968bfce4f2ca8e100d9a8b54379.png)