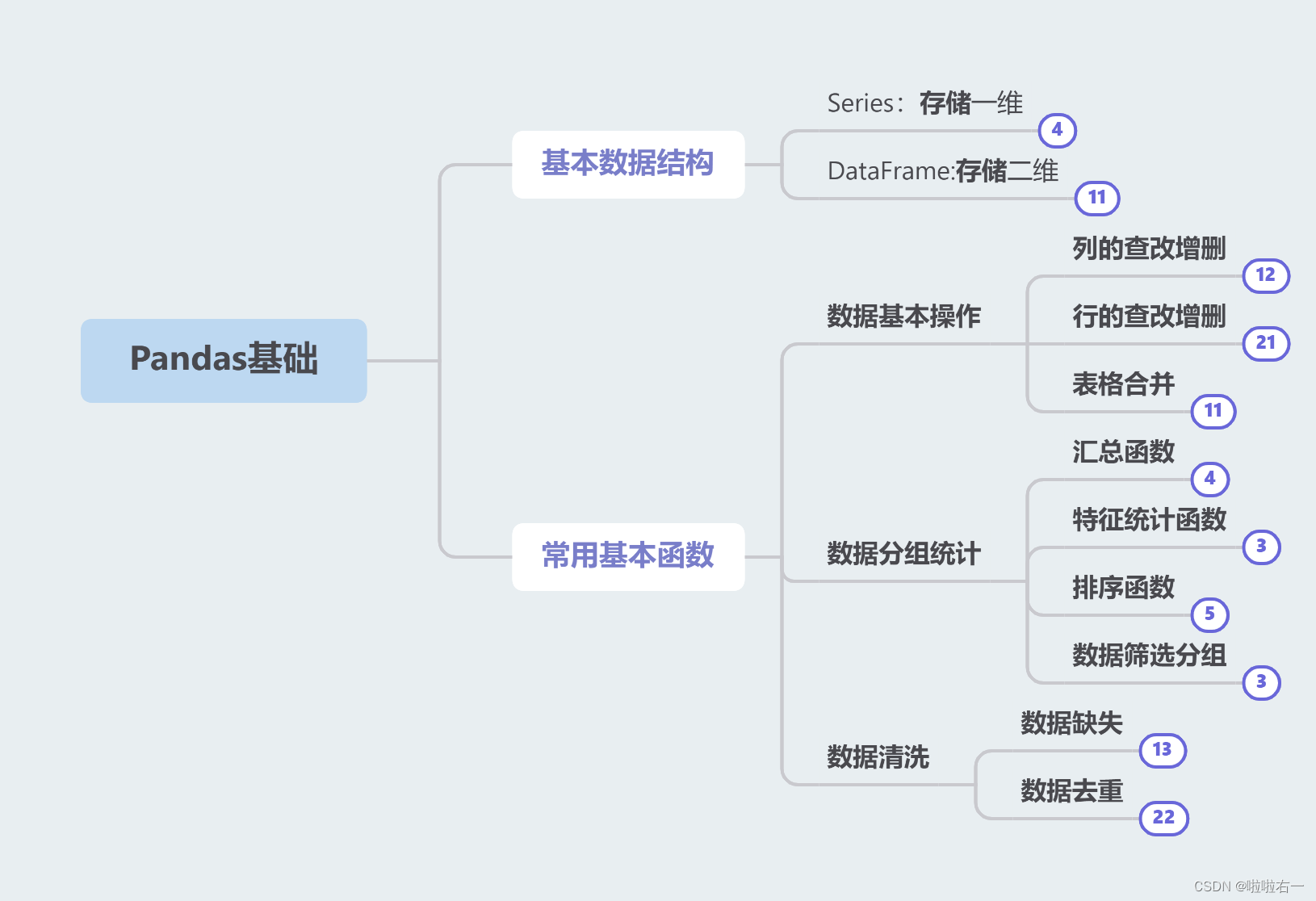
文章目录
- 📚基本数据结构
- 🐇Series:存储一维
- 🐇DataFrame:存储二维
- 🐇Series和DataFrame的关系
- 📚常用基本函数
- 🐇数据基本操作
- 🥕列的查改增删
- 👀查看列
- 👀修改列
- 👀新增列
- 👀删除列
- 🥕行的查改增删
- 👀查看行
- 👀修改行
- 👀新增行
- 👀删除行
- 🥕表格合并
- 🐇数据分组统计
- 🥕汇总函数
- 🥕特征统计函数
- 🥕排序函数
- 🥕数据筛选分组
- 🐇数据清洗
- 🥕数据缺失
- 👀 删除缺失数据行
- 👀为缺失数据赋值
- 🥕数据去重
- 👀唯一值函数
- 👀apply方法
- 👀替换函数
- 📚小结
Pandas库是基于Numpy构建的,用于处理如为数据添加标签、处理缺失值、分组等更灵活的数据任务
📚基本数据结构
🐇Series:存储一维
- Series一般由四个部分组成,分别是序列的值data、索引index、存储类型dtype、序列的名字name。其中,索引也可以指定它的名字,默认为空。
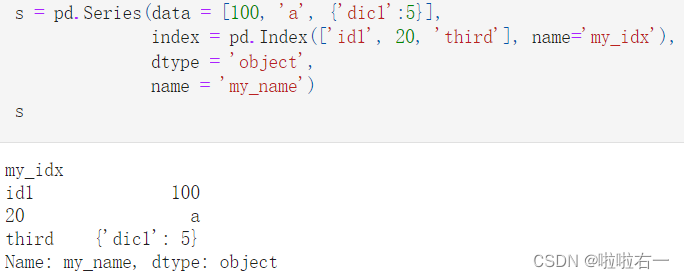
object代表了一种混合类型,正如上面的例子中存储了整数、字符串以及Python的字典数据结构。此外,目前pandas把纯字符串序列也默认认为是一种object类型的序列,但它也可以用string类型存储
- 存储后的属性可用
.的方式获取

-
加减乘除

Pandas数据对齐
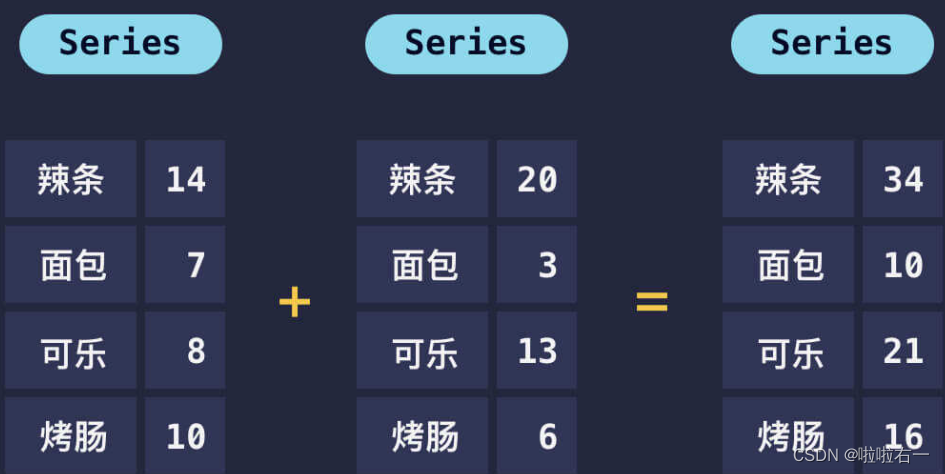
⭐️数据标签相同
⭐️数据标签不同
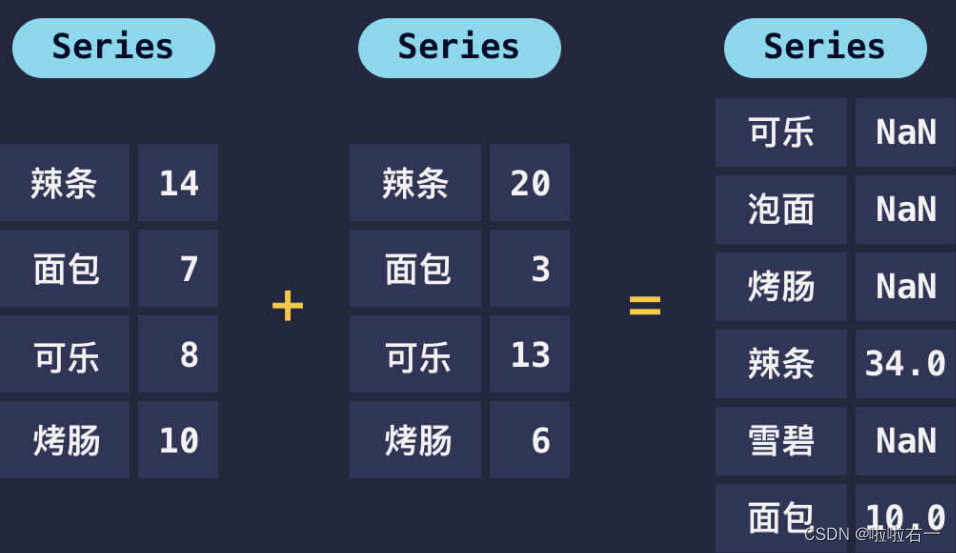
import pandas as pd s1 = pd.Series({'辣条': 14, '面包': 7, '可乐': 8, '烤肠': 10}) s2 = pd.Series({'辣条': 20, '面包': 3, '雪碧': 13, '泡面': 6}) print(s1.add(s2, fill_value=0)) # fill_value=0,就当值不存在默认为0 ''' 可乐 8.0 泡面 6.0 烤肠 10.0 辣条 34.0 雪碧 13.0 面包 10.0 '''
🐇DataFrame:存储二维
- 相关属性定义

- DataFrame在Series的基础上增加了列索引,一个数据框可以由二维的data与行列索引来构造
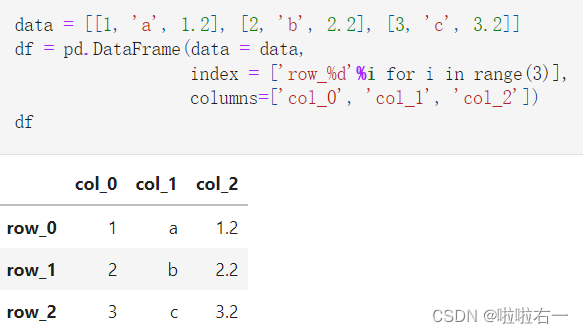
- 但一般而言,更多的时候会采用从列索引名到数据的映射来构造数据框,同时再加上行索引
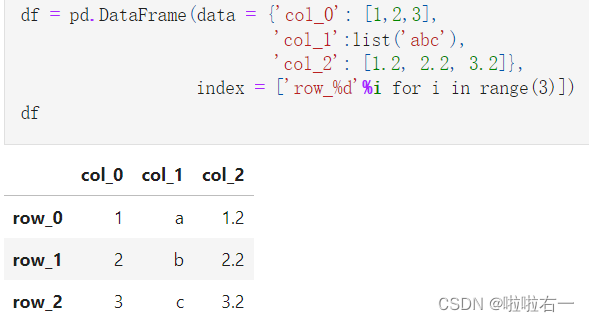
- 由于这种映射关系,在DataFrame中可以用[col_name]与[col_list]来取出相应的列与由多个列组成的表

- 与Series类似,在数据框中同样可以取出相应的属性
- 通过
.T可以把DataFrame进行转置

- 由于这种映射关系,在DataFrame中可以用[col_name]与[col_list]来取出相应的列与由多个列组成的表
🐇Series和DataFrame的关系
-
按行分
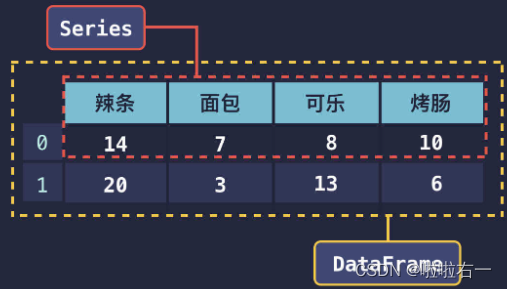
-
按列分
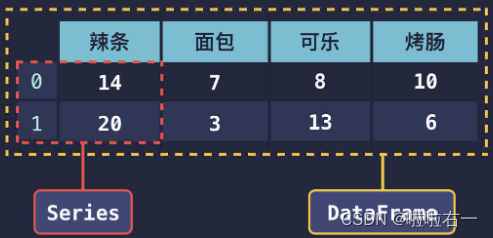
📚常用基本函数
🐇数据基本操作
🥕列的查改增删
👀查看列
print(df['可乐']):一列
print(df['可乐','辣条']):多列
👀修改列
df['可乐'] = [18, 23]:和字典修改值的地方类似,直接对已有列重新赋值即可
👀新增列
df['糖果'] = [3, 5]:对表格中不存在的列直接赋值即可
👀删除列
df.drop('面包', axis=1, inplace=True):drop() 方法

🥕行的查改增删
👀查看行
print(df.loc[0])
查看第一行,注意,loc 并不是一个方法,而是类似于字典。所以我们使用的是 [] 而不是 (),这里千万不要用错。这样我们就能得到第一行的数据
⭐️如果在构建表格时像下面这样单独设置了索引,同样也可以用对应的索引值来获取表格行的数据
import pandas as pd
data = {'辣条': [14, 20],'面包': [7, 3],'可乐': [8, 13],'烤肠': [10, 6]
}
df = pd.DataFrame(data, index=['2020-01-01', '2020-01-02'])
print(df.loc['2020-01-01'])
⭐️除了第一个参数索引外,还支持第二个参数列名。即同时基于行和列获取指定的数据,例print(df.loc[0, '辣条']),是获取行为 0 且列为辣条的数据
⭐️同时,行和列还支持分片的写法,需要注意的是,这里的分片和 Python 中列表的分片不太一样,这里的分片结果是前后都包含的,而列表分片只包含前面不包含后面。除此之外,二者都可以通过省略冒号前后的内容来实现全选
# 行分片
print(df.loc[0:1, '辣条'])
# 列分片
print(df.loc[0, '辣条':'可乐'])
# 同时分片
print(df.loc[0:1, '辣条':'可乐'])
⭐️同时也支持布尔索引来进行数据的筛选

⭐️除了比较常用的 loc 之外,我们还能使用 iloc。用法和 loc 大体一样,区别在于 loc 使用的参数是索引,而 iloc 的参数是位置,即第几行。因此,在不指定索引的情况下,loc 和 iloc 的效果是一样的。但当单独指定了索引,我们想获取前 3 行数据时可以像下面这样,注意,iloc 的分片和 Python 的列表分片一样,要和 loc 的分片规则区分开来。
import pandas as pd
data = {'辣条': [14, 20, 12, 15, 17],'面包': [7, 3, 8, 3, 9],'可乐': [8, 13, 23, 12, 19],'烤肠': [10, 6, 21, 24, 18]
}
df = pd.DataFrame(data, index=['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04', '2020-01-05'])
print(df.iloc[:3]) # :3 表示 0、1、2 前三个
👀修改行
直接赋值即可
⭐️赋值为一个数字。df.loc[0] = 1 # 第一行都改成 1
⭐️赋值为长度和列数相等列表。
# 按顺序修改成 1 2 3 4
df.loc[0] = [1, 2, 3, 4]
⭐️也可以使用例如 df.loc[0, '辣条'] = 23 定位到行和列来修改特定的数据
👀新增行
⭐️对表格中不存在的行直接赋值就能添加新的列了
# 添加第三行,全为 1
df.loc[2] = 1
# 添加第四行,分别为 1 2 3 4
df.loc[3] = [1, 2, 3, 4]
#和新增列道理一样的
⭐️在新增行时,是不能使用 iloc 传入索引的
👀删除行
删除行和删除列一样,都是使用 drop() 方法。删除列的使用传入了 axis=1 表示对列进行删除,axis 默认为 0,因此删除行时省略 axis 参数即可
🥕表格合并
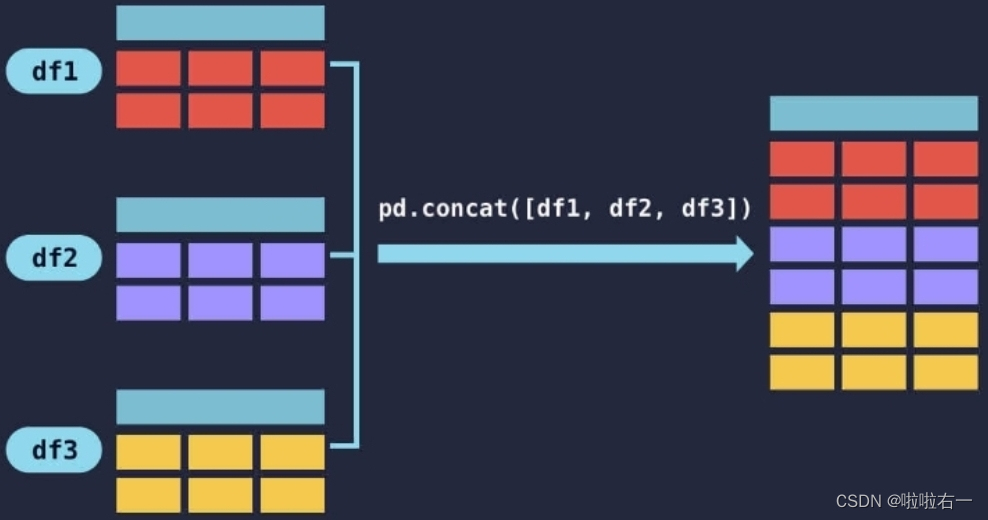
⭐️纵向合并:pd.concat([df1, df2])
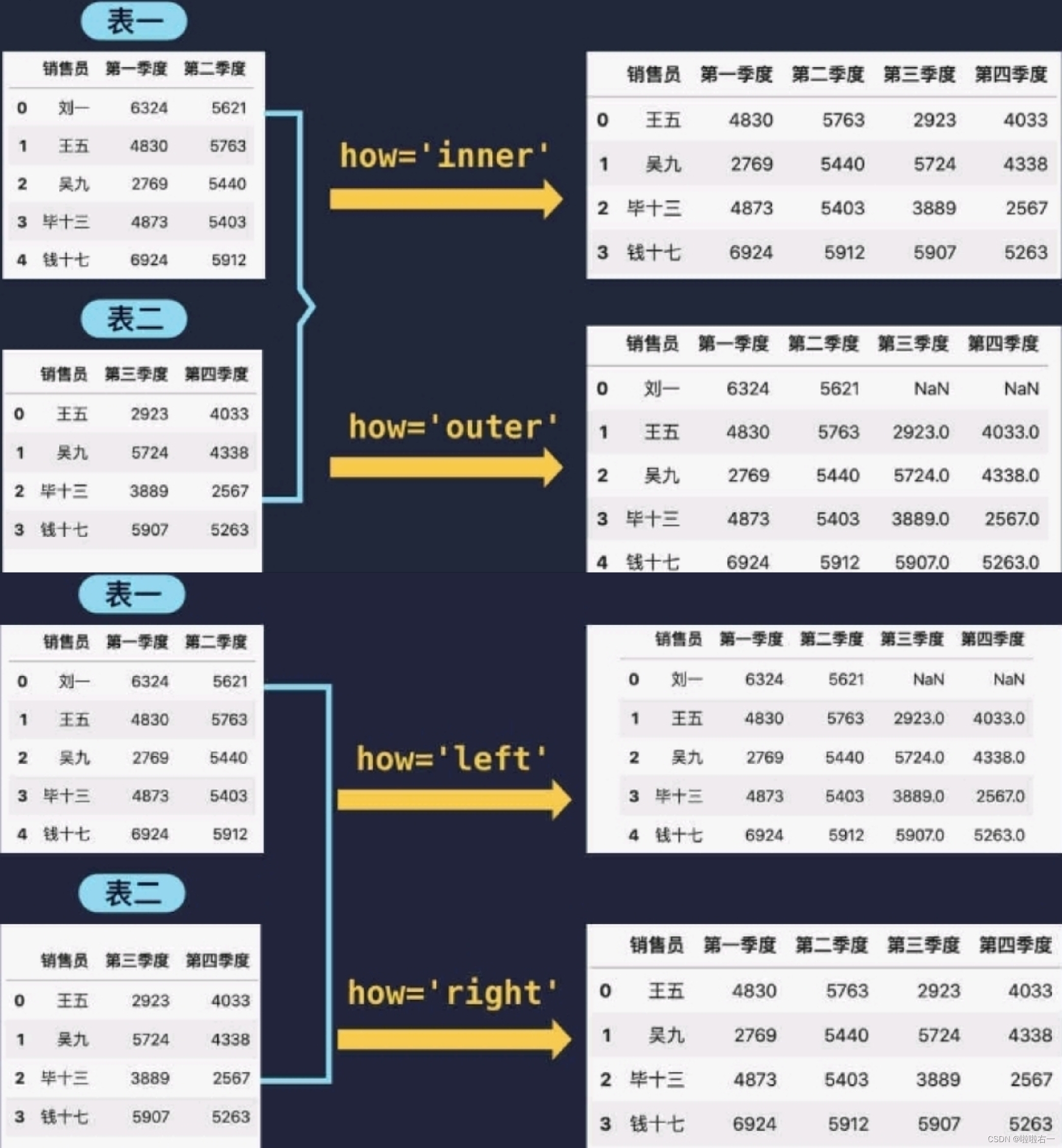
⭐️横向合并:pd.merge(表一, 表二,on=‘用于合并的列名',how=‘合并方式')

🐇数据分组统计
🥕汇总函数

一篇info,describe详解
🥕特征统计函数

🥕排序函数

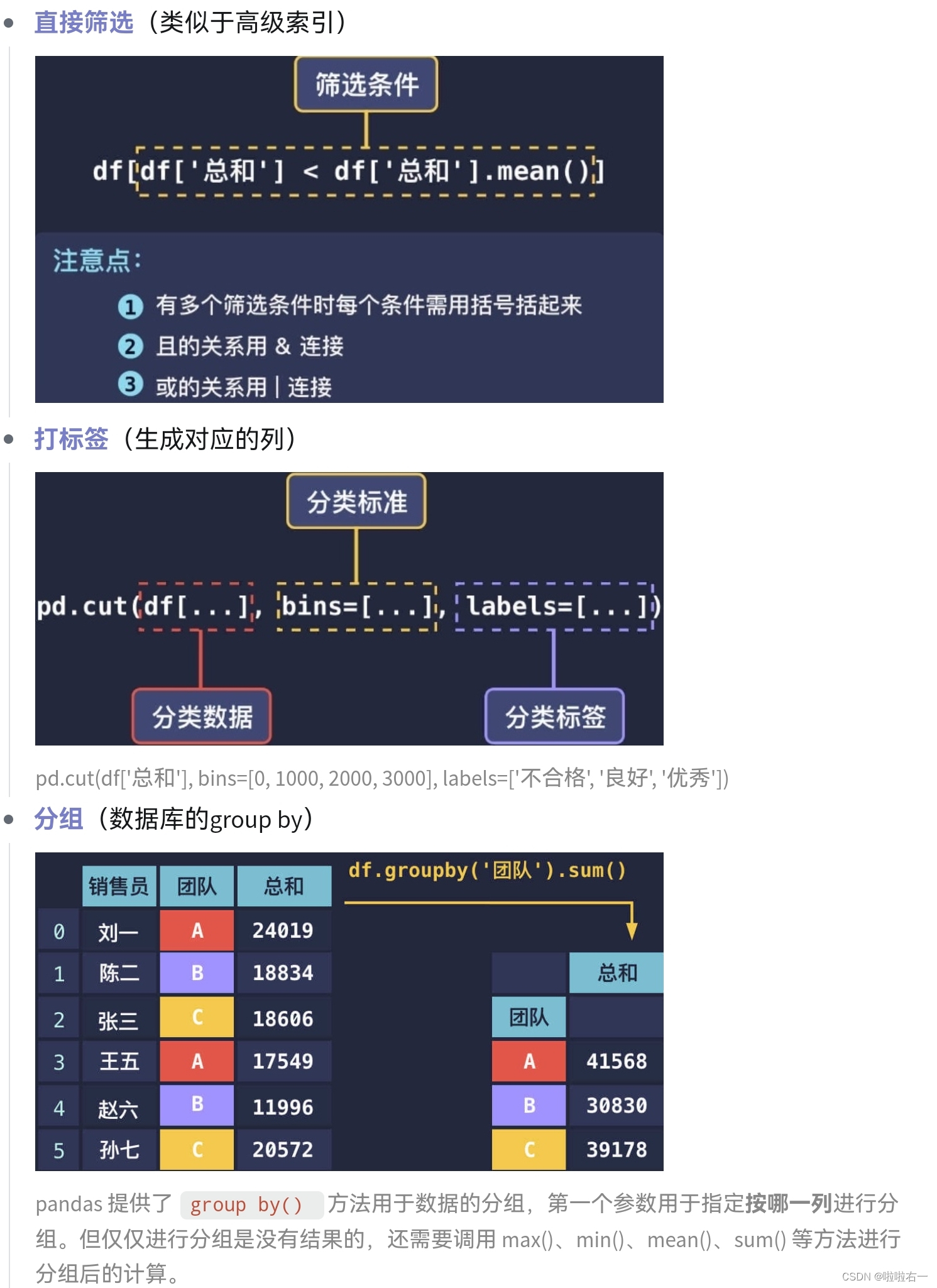
🥕数据筛选分组
🐇数据清洗
🥕数据缺失

👀 删除缺失数据行

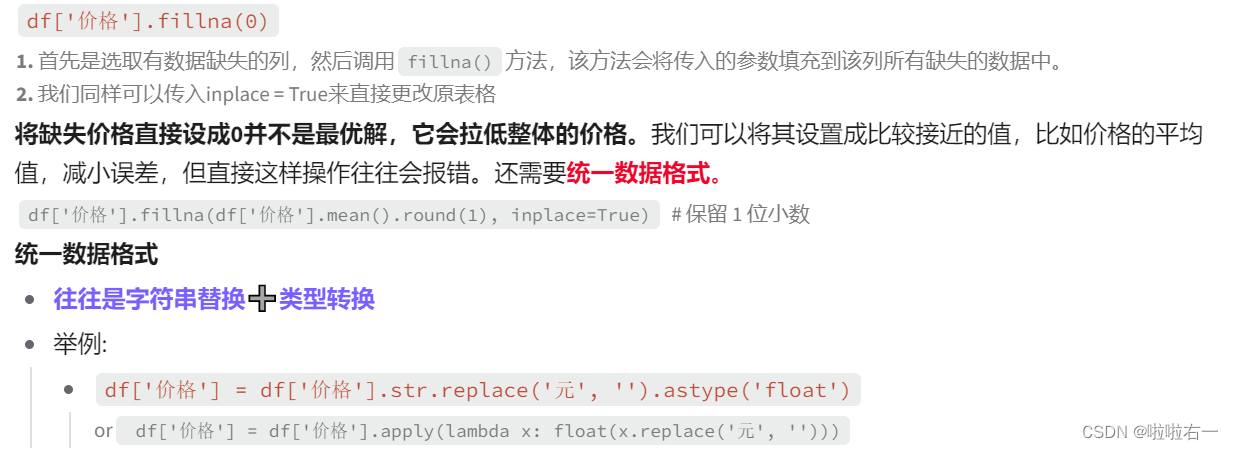
👀为缺失数据赋值
🥕数据去重
👀唯一值函数
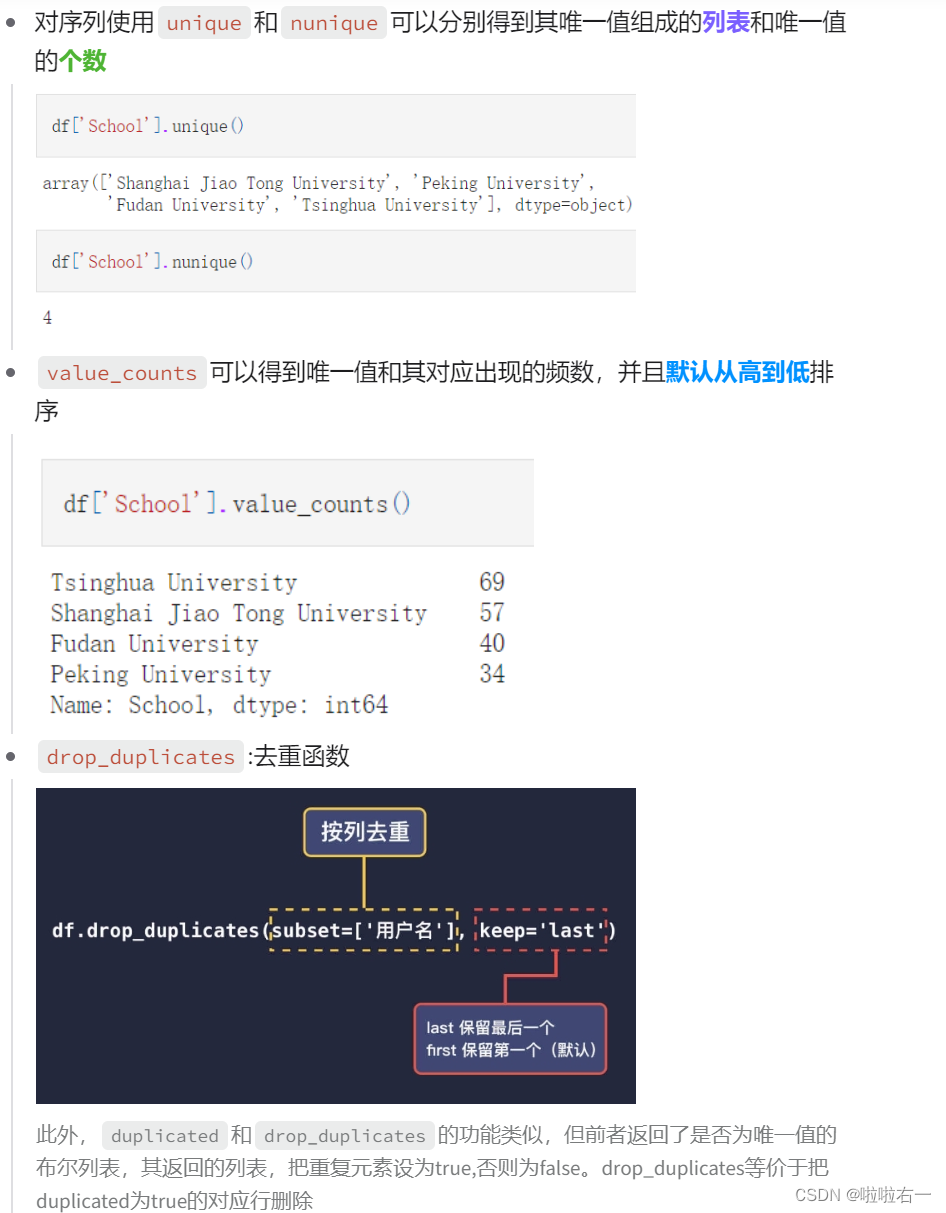 drop_duplicates() 详解博客
drop_duplicates() 详解博客
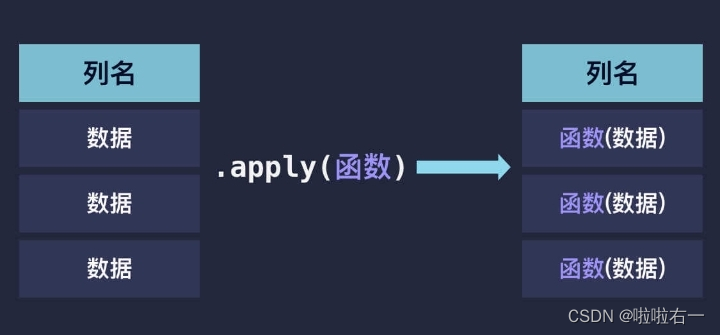
👀apply方法
apply方法补充
匿名函数补充
和普通函数对比理解


- pandas 的 apply() 函数可以作用于 Series 或者整个 DataFrame,功能也是自动遍历整个 Series 或者 DataFrame, 对每一个元素运行指定的函数。
format_price = lambda x: float(x.replace('元', ''))df['价格'] = df['价格'].apply(format_price)
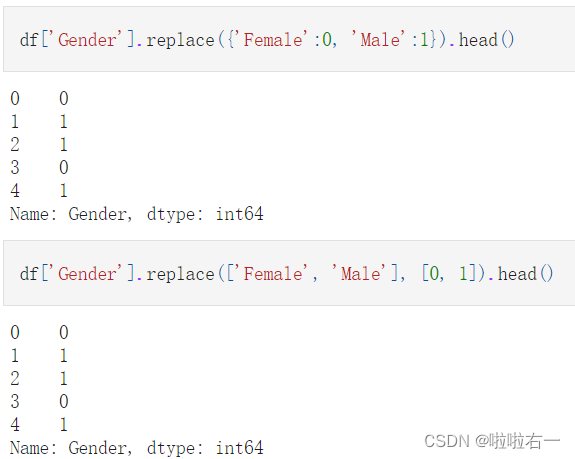
👀替换函数
⭐️映射替换replace
- 可以通过字典构造,或者传入两个列表来进行替换
- 一种特殊的方向替换,指定method参数为
ffill则为用前面一个最近的未被替换的值进行替换,bfill则使用后面最近的未被替换的值进行替换
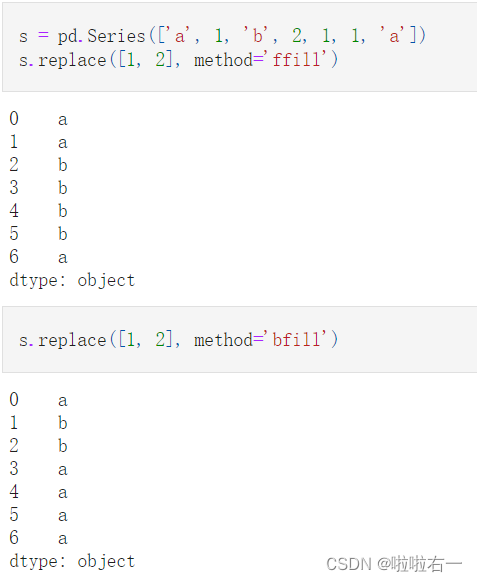
要被换的是1和2,然后用什么去换,就看是ffill和bfill,看取前边的还是取后边的
⭐️逻辑替换
- 逻辑替换包括了
where和mask,这两个函数完全对称
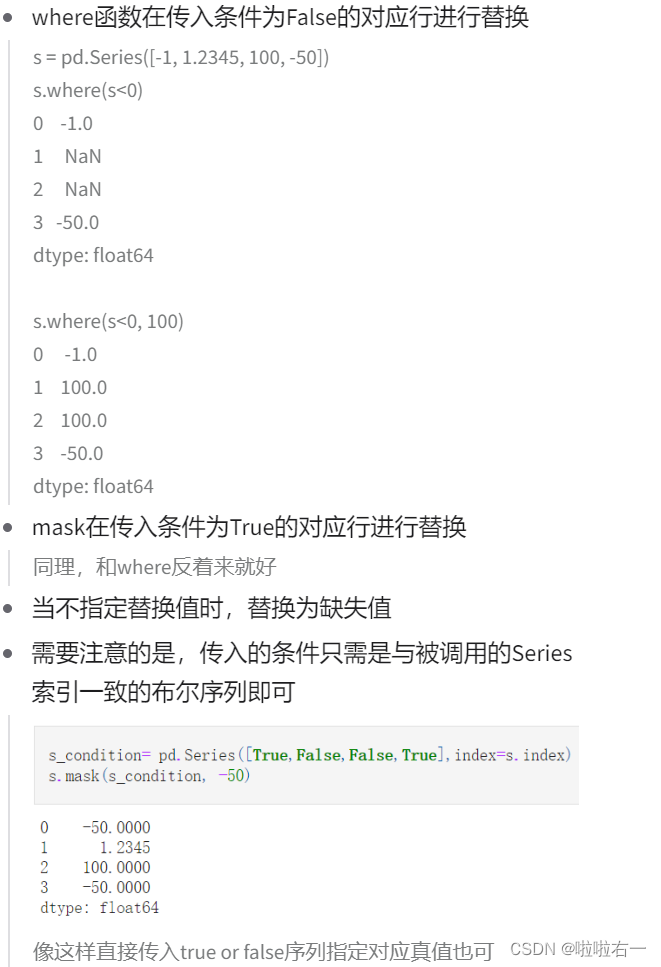
⭐️数值替换

Data.clip函数详解博客
📚小结
⭐️【补充】文件的读取和写入