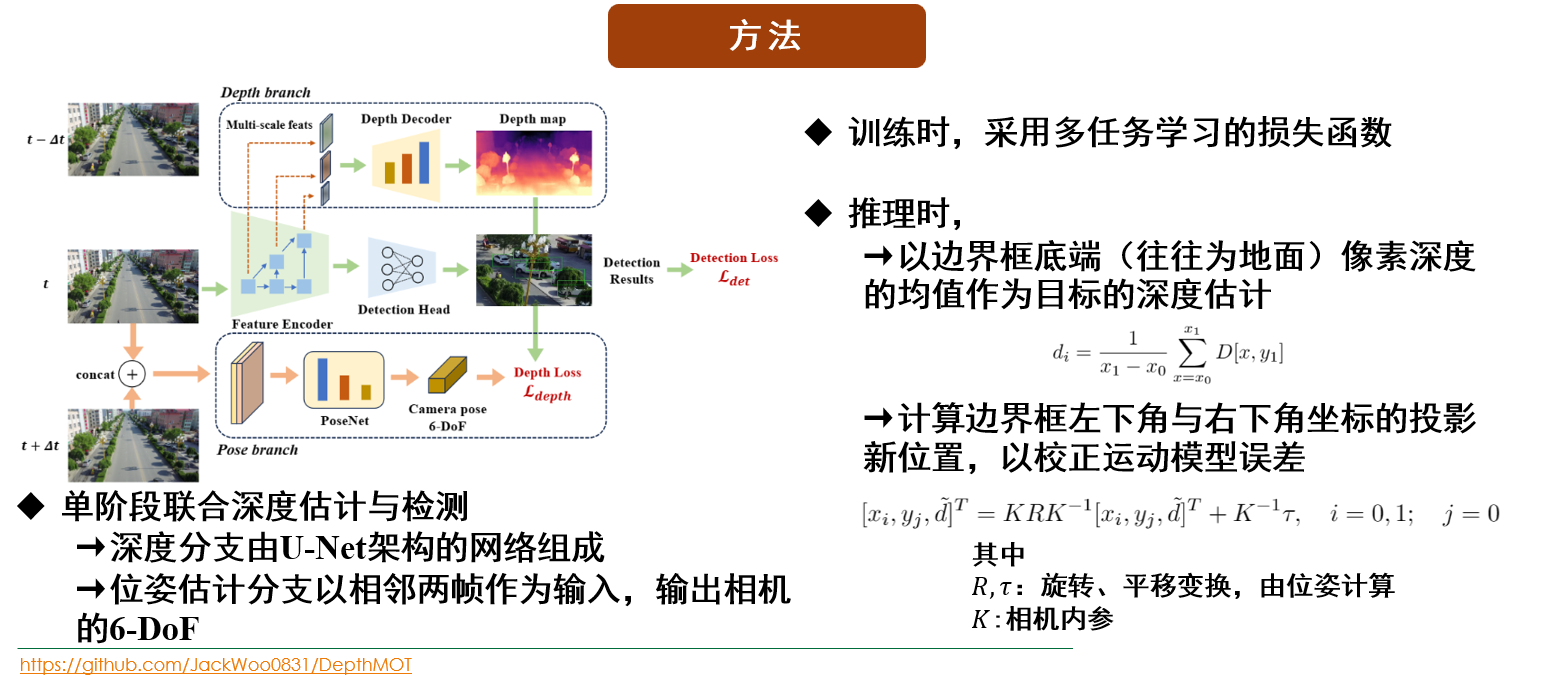
去年10月开始到年底,做了一个小工作,就是将自监督单目深度估计与MOT结合,目的是充分利用深度信息解决遮挡问题,并且在估计深度的同时可以估计相机位姿,这是可以计算出相邻两帧像素的映射。这在视角较大变化下比较有用。
在无人机数据集上(VisDrone和UAVDT)表明,方法是比较有效的。
希望这个工作能给大家一些参考和启发吧!如果有改进的建议,非常欢迎大家提出。
项目地址:https://github.com/JackWoo0831/DepthMOT,欢迎大家star!
研究动机与方法

以下是项目的README
DepthMOT
Abstract:
Accurately distinguishing each object is a fundamental goal of Multi-object tracking (MOT) algorithms. However, achieving this goal
still remains challenging, primarily due to: (i) For crowded scenes with occluded objects, the high overlap of object bounding boxes leads to
confusion among closely located objects. Nevertheless, humans naturally perceive the depth of elements in a scene when observing 2D videos. Inspired
by this, even though the bounding boxes of objects are close on the camera plane, we can differentiate them in the depth dimension, thereby
establishing a 3D perception of the objects. (ii) For videos with rapidly irregular camera motion, abrupt changes in object positions can result in
ID switches. However, if the camera pose are known, we can compensate for the errors in linear motion models. In this paper, we propose DepthMOT, which achieves: (i) detecting and estimating scene depth map end-to-end, (ii) compensating the irregular camera motion by camera pose estimation. Extensive experiments demonstrate the superior performance of DepthMOT in VisDrone-MOT and UAVDT datasets.
Model Introduction
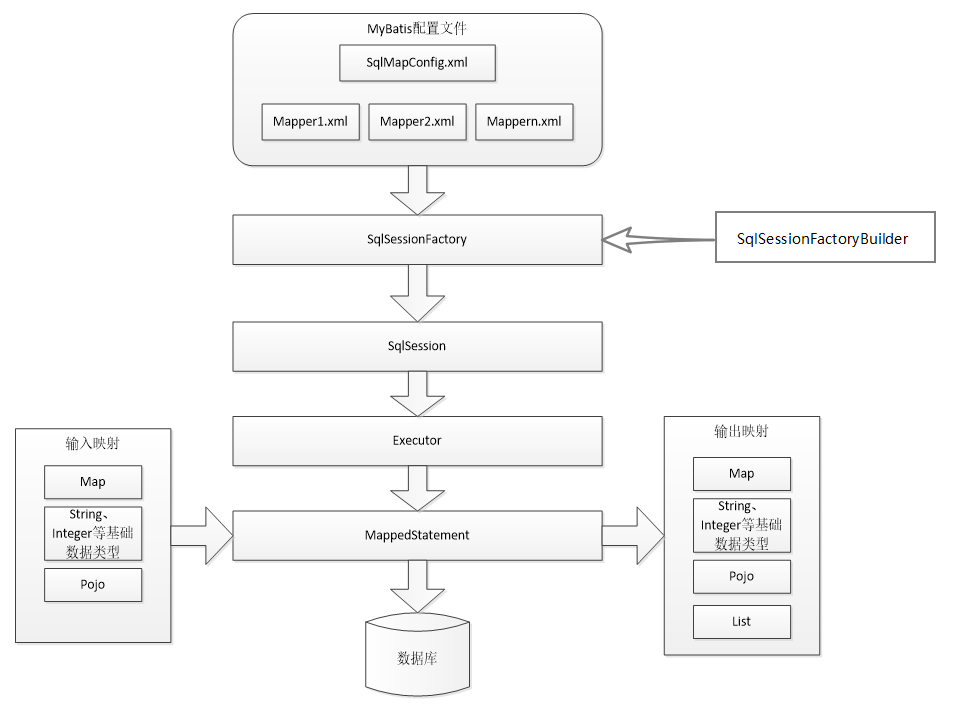
We intergrate part of monodepth2 and FairMOT to estimate the depth of objects and compensate irregular camera motions. Many thanks to their outstanding works! Below are the motivation and paradigm of DepthMOT.
Installation
Please refer to FairMOT to config virtual environment and prepare data.
For VisDrone, UAVDT, KITTI datasets, the data conversion code are available at src/dataset_tools
Model Zoo
Pretrained model
FairMOT pretrain (COCO) + monodepth2 pretrain (KITTI):
BaiduYun, code: us93
VisDrone:
BaiduYun, code: alse
Training
All traning scripts are in ./experiments
Training visdrone:
sh experiments/train_visdrone.shTraining uavdt:
sh experiments/train_uavdt.sh
Training kitti:
sh experiments/train_kitti.sh
Note that if training kitti, it’s recommended to modify the input resolution to (1280, 384) in
line 32, src/train.py:
dataset = Dataset(opt, dataset_root, trainset_paths, (1280, 384), augment=False, transforms=transforms)
Testing
Similarly to training, for testing, you need to run:
sh experiments/test_{dataset_name}.sh
Performance
| Dataset | HOTA | MOTA | IDF1 |
|---|---|---|---|
| VisDrone | 42.44 | 37.04 | 54.02 |
| UAVDT | 66.44 | 62.28 | 78.13 |
Results on KITTI is somehow inferior. Better results are obtaining.