目录
- 前言
- 一、原理
- 单体架构
- 高可用架构
- 二、初始化
- 1.配置yum源
- 2.关掉防火墙
- 3.关掉selinux
- 4. 修改内核参数
- 5.关掉swap交换分区
- 三、安装master节点
- 1. 安装container
- 2.启动master服务
- 四、安装node节点
- 五、卸载
- 六、总结
前言
各位小伙伴们,大家好,小涛又来了,今天澳同学又来挑刺 提问了

温馨提示:老规矩,我们先简单了解原理,实操部分请从
第二节开始阅读
一、原理
下面我们来看看原理
官网:https://www.rancher.cn/k3s/
文档:https://docs.k3s.io/zh/
K3s 适用于以下场景:
- 边缘计算
- 物联网-IoT
- CI:持续集成
- Development:开发
- ARM
- 嵌入K8S
由于运行 K3s 所需的资源相对较少,所以 K3s 也适用于开发和测试场景。
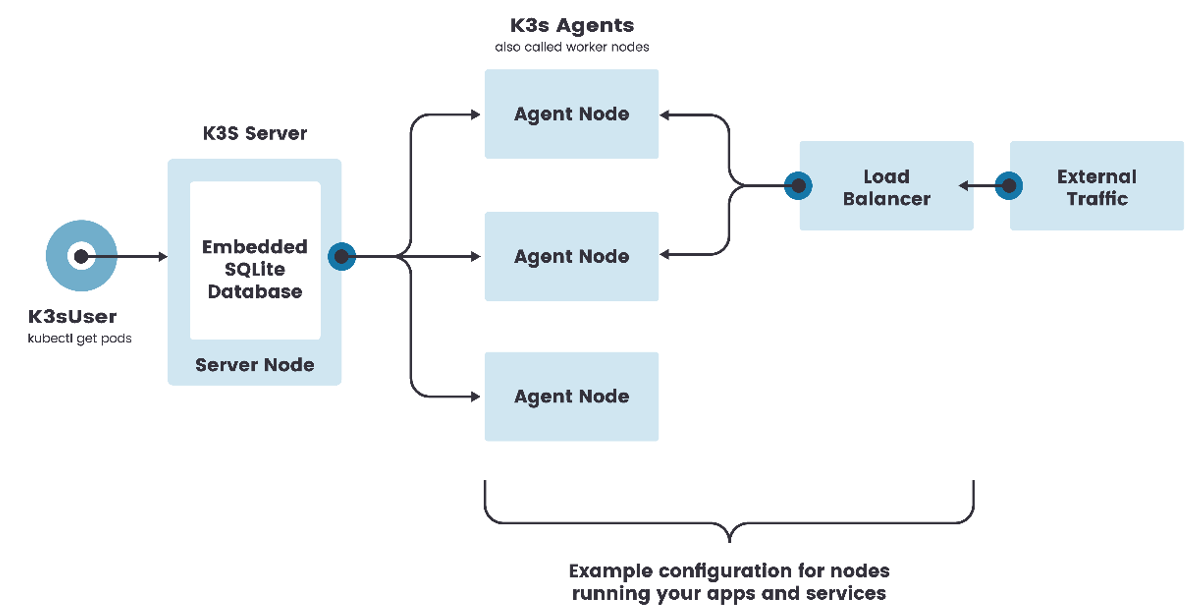
单体架构
-
k3s server节点是运行k3s server命令的机器,而k3s Agent 节点是运行k3s agent命令的机器
-
单点架构只有一个控制节点(在 K3s 里叫做Server node,相当于 K8s 的 master节点),而且K3s的数据存储使用 SQLite 并内置在了控制节点上
-
在这种配置中,每个 agent 节点都注册到同一个 server 节点。K3s 用户可以通过调用server节点上的K3s API来操作Kubernetes资源。
高可用架构
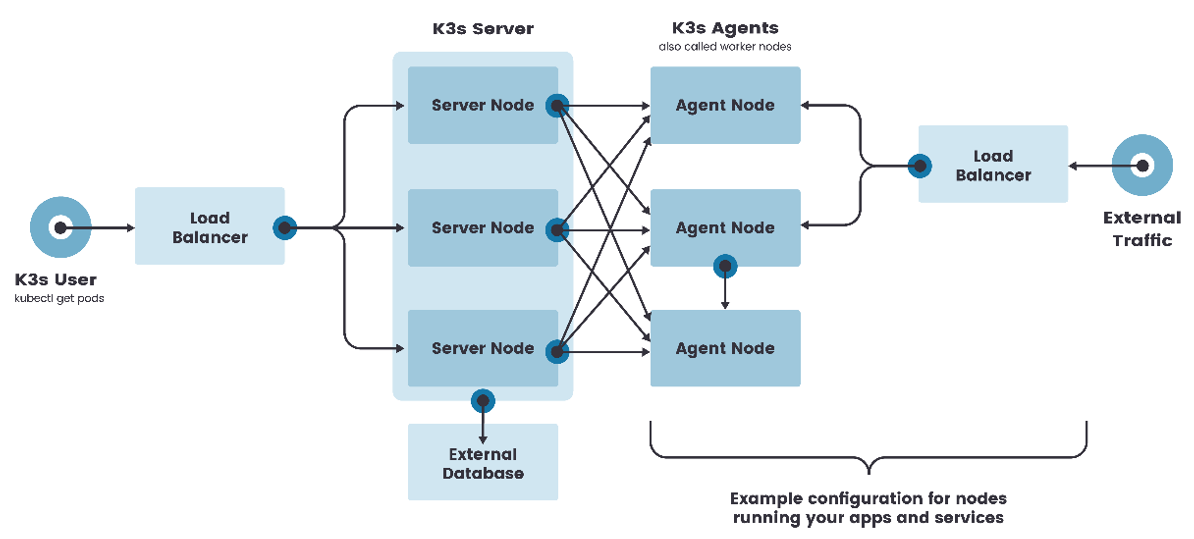
虽然单节点 k3s 集群可以满足各种用例,但对于 Kubernetes control-plane 的正常运行至关重要需要在高可用配置中运行 K3s。
一个高可用 K3s 集群由以下几个部分组成:
- K3s Server 节点:两个或者更多的server节点将为 Kubernetes API 提供服务并运行其他 control-plane 服务
- 外部数据库:外部数据存储(与单节点 k3s 设置中使用的嵌入式 SQLite 数据存储相反)【不安装在内部集群中】
二、初始化
和K8S的前期工作一样,进行如下操作
1.配置yum源
#配置国内安装docker和containerd的阿里云的repo源
$ yum install yum-utils
$ yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo#================================================
# 配置安装k8s组件需要的阿里云的repo源
cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF#================================================
$ yum install lrzsz vim-enhanced
2.关掉防火墙
#每个节点都执行
systemctl stop firewalld ; systemctl disable firewalld# 查看是否已关闭
systemctl status firewalld
systemctl is-enabled firewalld

3.关掉selinux
#每个节点都执行
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config#修改selinux配置文件之后,重启机器,selinux配置才能永久生效,
#查看是否已生效
$ getenforce
#如果显示Disabled说明selinux已经关闭

4. 修改内核参数
$ modprobe br_netfilter
$ cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF#加载文件
$ sysctl -p /etc/sysctl.d/k8s.conf
问题1:sysctl是做什么的?
在运行时配置内核参数
-p 从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载
问题2:为什么要执行modprobe br_netfilter?
修改/etc/sysctl.d/k8s.conf文件,增加如下三行参数:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
如果 sysctl -p /etc/sysctl.d/k8s.conf出现报错:
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
# 解决方法:
$ modprobe br_netfilter
问题3:为什么开启net.bridge.bridge-nf-call-iptables内核参数?
在centos下安装docker,执行docker info出现如下警告:
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
解决办法:
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
问题4:为什么要开启net.ipv4.ip_forward = 1参数?
kubeadm初始化k8s如果报错:
 就表示没有开启ip_forward,需要开启。
就表示没有开启ip_forward,需要开启。
net.ipv4.ip_forward是数据包转发:
- 出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
- 要让Linux系统具有路由转发功能,需要配置一个Linux的内核参数net.ipv4.ip_forward。这个参数指定了Linux系统当前对路由转发功能的支持情况;其值为0时表示禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
5.关掉swap交换分区
备注:在安装k8s里,swap交换分区必须关闭,但有一次做测试的时候,没关,发现也能安装k3s【建议大家最好给关闭】
#每个节点都执行
#临时关闭
$ swapoff -a#永久关闭:注释swap挂载,给swap这行开头加一下注释
$ vim /etc/fstab #给swap这行开头加一下注释#
#/dev/mapper/centos-swap swap swap defaults 0 0
澳同学:为什么要关闭swap交换分区?
小涛:swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定–ignore-preflight-errors=Swap来解决。
三、安装master节点
1. 安装container
#在 master 和 node 上安装containerd
$ yum install containerd -y#启动containerd
$ systemctl start containerd
2.启动master服务
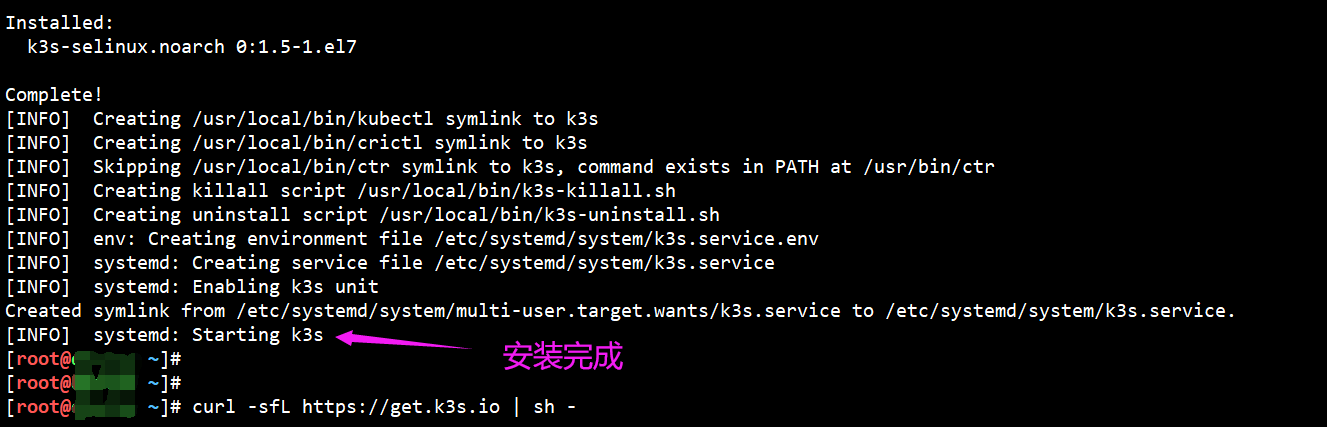
#我们可以用如下方法:安装速度会更快
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh -#在 master 上操作:【本次实验用这种方式执行】
$ curl -sfL https://get.k3s.io | sh -
#看到如下,说明k3s已经启动了:
#验证安装是否成功【这两种方法都一样】
$ k3s kubectl get node
$ kubectl get node$ kubectl get pods -n kube-system
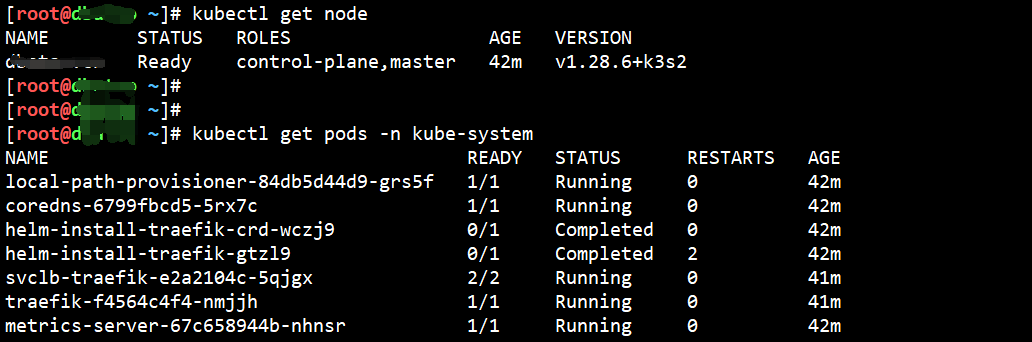
我们再对比一下安全前后的内存
很直观的发现,内存只用了大约 512MB 左右,真的很轻量!!

四、安装node节点
在安装好master节点后,我们继续安装node节点
#获取join token
#添加node节点。需要一个join token。Join token存在于master节点的文件系统上
$ cat /var/lib/rancher/k3s/server/node-token#获取到一串token:[记住这个token]

#在 node 上执行如下,把work节点加入k3s:
ssh node01
curl -sfL https://get.k3s.io | K3S_URL=https://<master01_IP>:6443 K3S_TOKEN=<刚才cat 的那一串全部粘贴进来> sh -#如果太慢,使用下面这个方法可加速[本次实验用的这个方法]
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=https://<master01_IP:6443> K3S_TOKEN=<刚才cat 的那一串全部粘贴进来> sh -#验证work节点是否加入集群:
#在 master节点
$ systemctl status k3s-agent
$ kubectl get nodes
大功告成,接下来可以愉快的使用容器了😉
注意哦,k3s的所有操作跟k8s无区别,但是学习还是以k8s为主,之后再扩展k3s
五、卸载
下面是如何进行干净的卸载K3S,这一步可忽略
#在server节点执行:
/usr/local/bin/k3s-uninstall.sh#在agent节点执行:
/usr/local/bin/k3s-agent-uninstall.sh
六、总结
澳同学:原来如此,那k3s和k8s如何选择呢?
小涛:k8s虽然相对“重”一些,但更稳重,比较适合云计算场景;而k3s比较轻量,适宜用边缘计算场景
澳同学:不错,下回再给你出个难题
小涛:行行行,尽管提问,相互学习,俺可是有cka、cks的运维小哥了😊
澳同学:可以嘛,晚上请你🍗
小涛:谢谢大佬~
各位小伙伴们,咱们下篇文章再见了~