1、前言
机器学习在分类中已经非常成熟,受限于本人的专业能力与认知,所以本论文/课题是我在机器学习领域的初步探索,在关键的算法和代码部分其实我也一知半解,所以我重点讲述机器学习应用的过程,及探讨如何增强自己论文的叙事性,以及如何利用ChatGPT来帮助自己论文写作。
有纰漏请指出,转载请说明。
学习交流请发邮件 1280253714@qq.com
先上几个有趣的网站:
根据图像生成声音
Imaginary Soundscape

CNN EXPLAINER——形象具体地解释CNN的原理
CNN Explainer

B站up主DR_CAN
期刊审稿人手把手教你写一篇SCI论文 (1)_事实汇总【论文写作】_哔哩哔哩_bilibili
2、机器学习的步骤
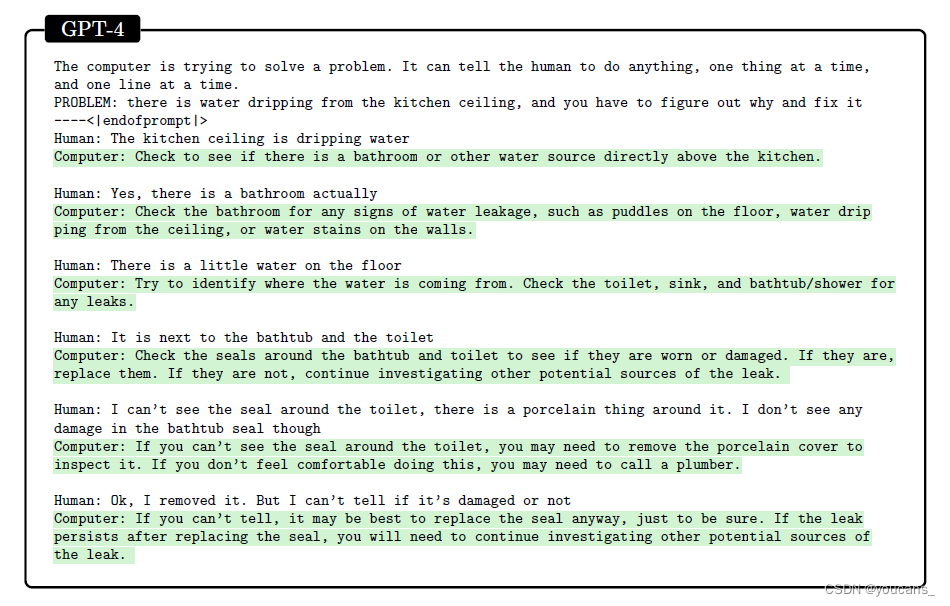
这是我在ChatGPT上找到的,基本上很符合我论文的整体思路

我的论文:
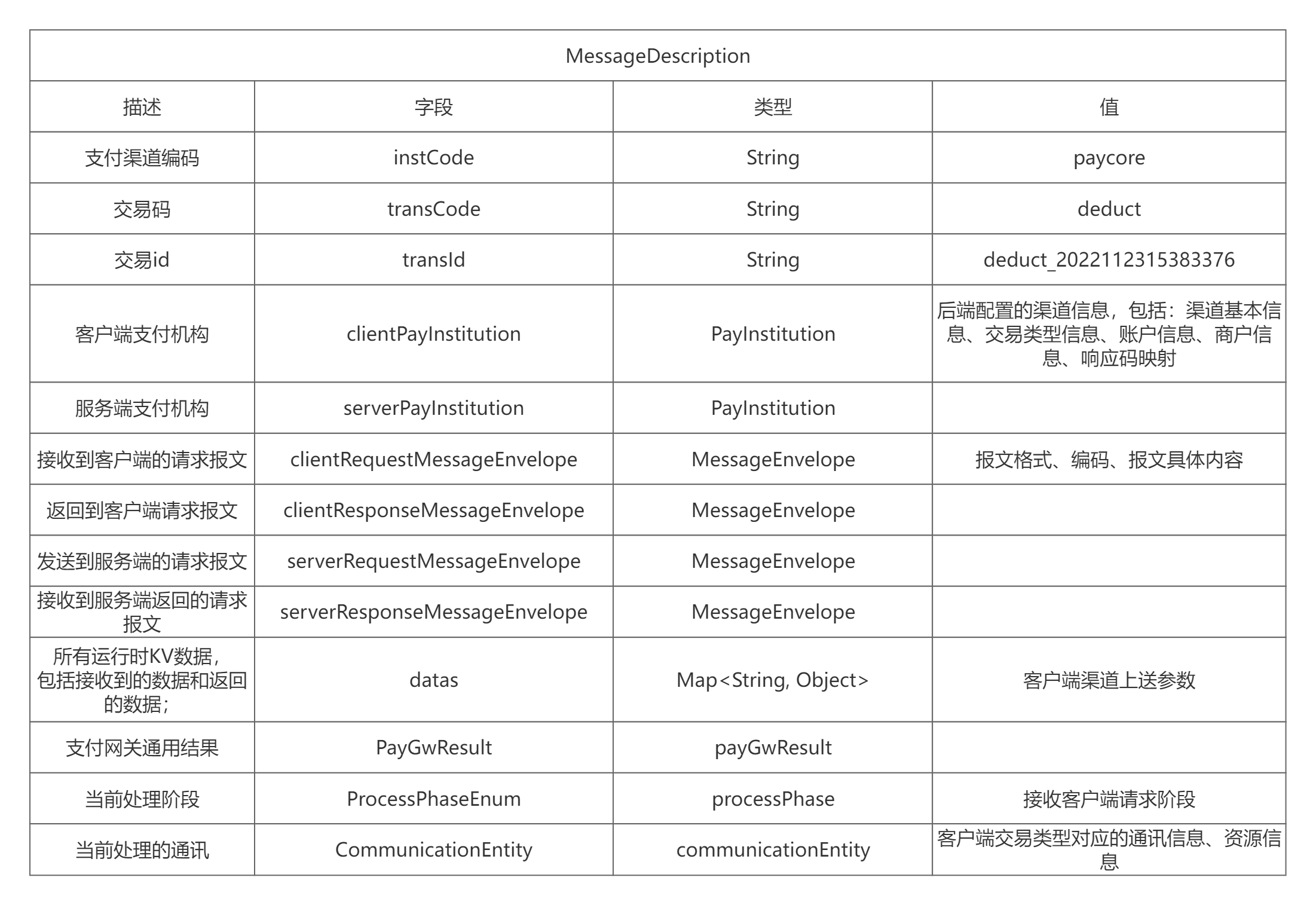
这样,机器学习的应用,需要先回答以下几个问题:
1.为什么要进行数据预处理,数据预处理分为几个步骤?
2.为什么要提取关键特征,怎么提取关键特征?
3.为什么要选择支持向量机这个模型,模型该如何建立?
4.怎么对模型进行训练,怎么验证所训练模型的好坏?
所以,接下来我先对我的课题做一个简要的介绍,然后来一一回答上面提出的问题。
3、课题综述
废话少说,总结就是:
1.铝在国民经济中的应用范围广泛
2.铝电解产业发展迅速
3.快速发展的同时出现很多问题
4.学界出现了很多铝电解槽状态评估方法
5.本课题建立基于支持向量机的槽况评判模型
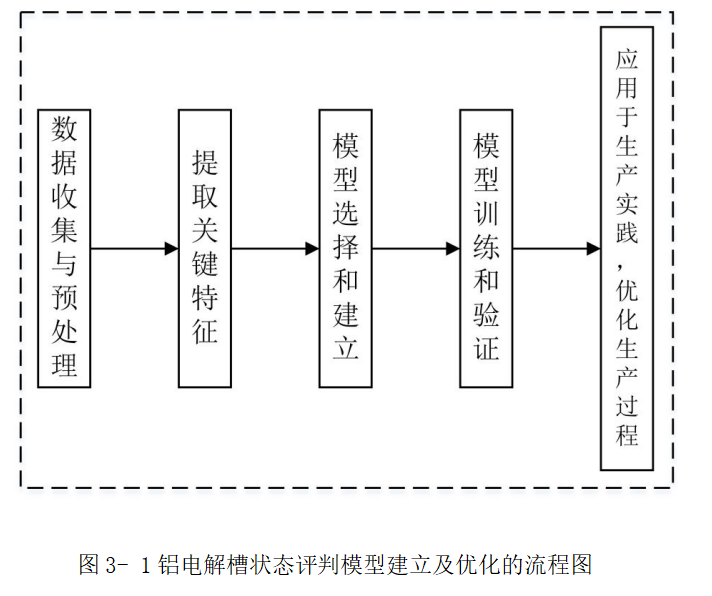
6.我主要做了这些工作:数据预处理、提取关键特征、建立模型并训练
7.我建立的模型有什么用,还有哪些需要改进的地方
4、为什么要进行数据预处理,数据预处理分为几个步骤?
还是ChatGPT,我根据我的论文,总结概况铝电解数据的特点:数据维度高、数据量大、噪声干扰强、非线性关系强


这是我收到导师发给我的数据:
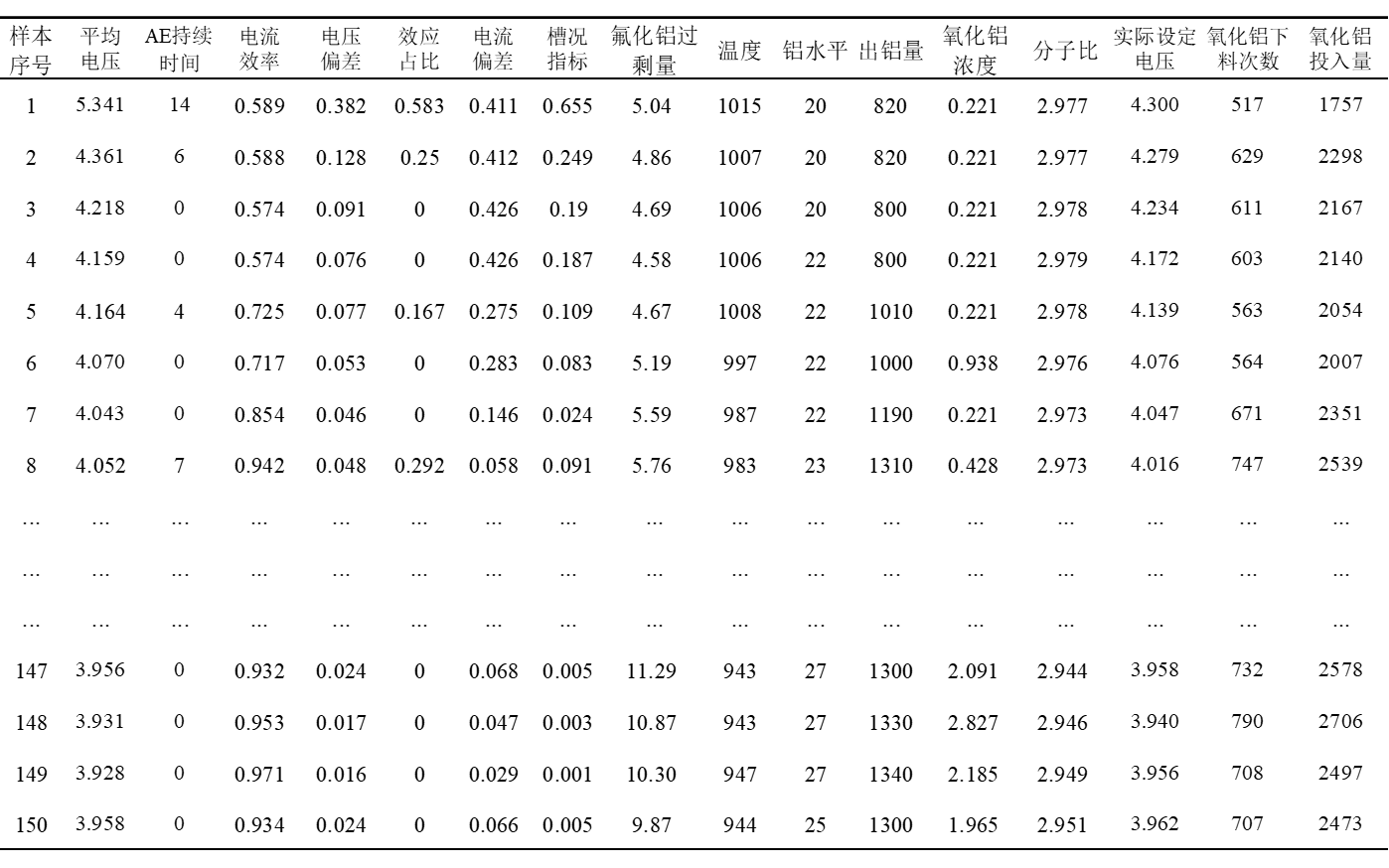
噪声干扰强: 在铝电解生产过程中,主要的工艺技术参数的数据来源于传感器、变送器等仪表仪器,然而受到仪表精度、测量环境、测量方法以及人为因素的影响,采集到的数据不可避免地出现噪点或异常值等情况。
数据维度高:关于铝电解的数据参数有14个(实际上影响铝电解的参数远不止这些,甚至多达数十上百个),如果把这些参数都输入模型中,训练难度高及训练时间长。
非线性关系强:因不同参数变量间存在不同的量纲,且使用未处理的现场数据进行故障诊断和槽况分类,会影响实验结果,而且计算复杂度会大大增加。
那么,针对铝电解数据的特点,需要做什么呢?
噪声干扰强 -> 异常值剔除
非线性关系强 -> 数据归一化
数据维度高 -> 相关性分析及特征值提取
这是我论文上的插图
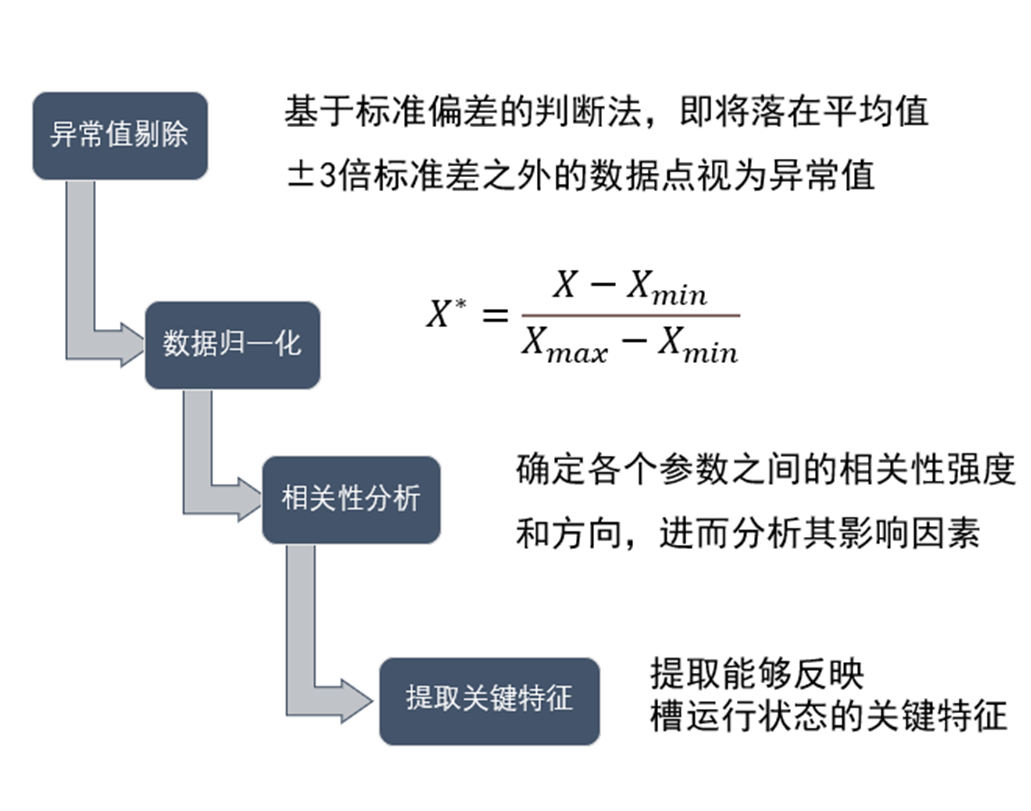
5、为什么要提取关键特征,怎么提取关键特征?
为什么要提取关键特征,这个问题其实在上面以及回答了。因为影响铝电解槽况运行的参数多,不能把所有参数都作为模型的输入参数,且很多参数存在强相关性,所以要进行相关性分析及特征值提取。
可以利用spss软件分析参数的相关性。我收到的数据都是连续型数据,样本量大于30,数据可以认为符合正态分布,所以采用皮尔逊相关系数
ChatGPT:


我论文中的插图:
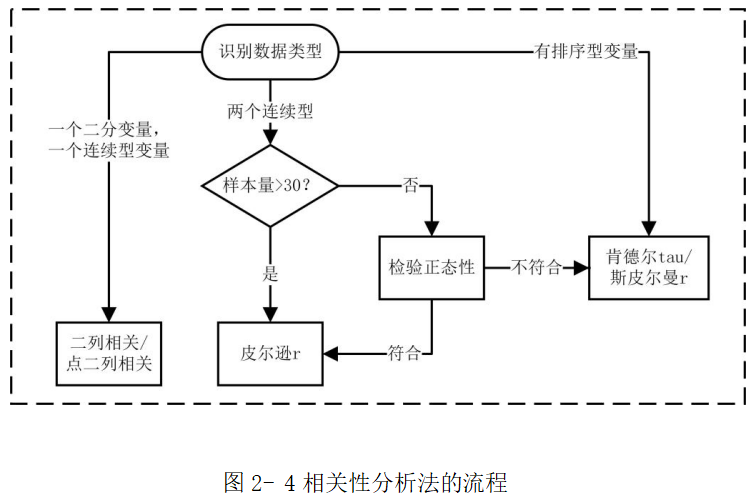
论文的思路就是:铝电解的数据存在强相关性,所以可以利用相关性分析,提前出主要的几个特征作为模型的输入。

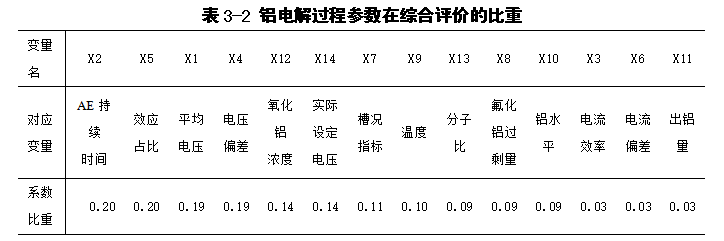
但是我无法用相关性分析法提前关键特征,所以后来在曾同学的帮助下用了主元分析法,结果如下:


数据预处理部分解决了,接下来就是模型选择的问题了。
6、为什么要选择支持向量机这个模型?

“为什么要选择支持向量机”,这个问题可以转化为:因为铝电解数据有什么样的特点,而支持向量机又有什么优点,所以我选择支持向量机。
1、铝电解涉及参数较多,在处理高维数据时,SVM可更好地反映槽况
2、SVM泛化能力强,数据过小或过大时,可防止出现欠拟合和过拟合
3、SVM通过核函数进行特征转化,将数据从低维空间映射到高维空间,使分类更容易
7、模型该如何建立?
ChatGPT:

我的论文:
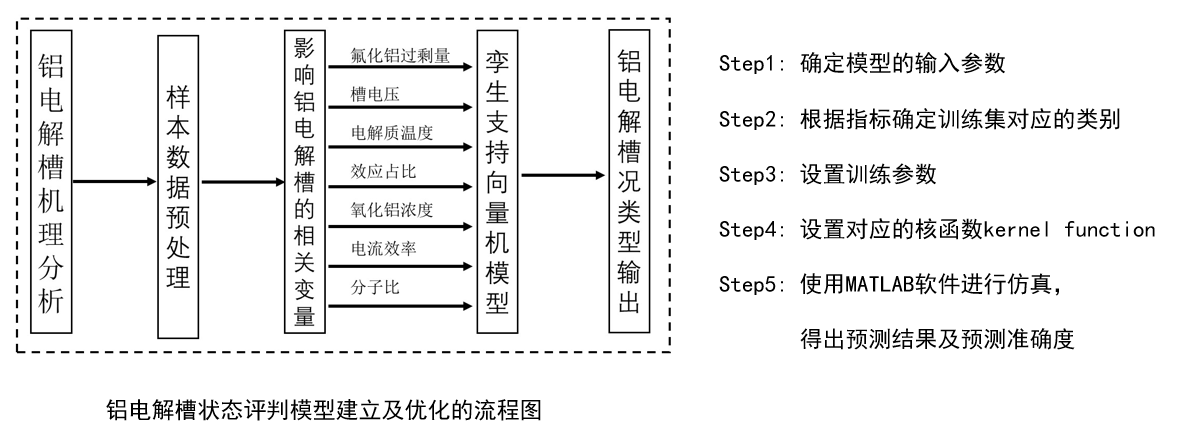
但是在这里有个问题还需要解决:支持向量机属于有监督学习,所以在训练之前要先根据指标对模型进行分类。

现在需要解决的问题是:怎么根据一组数据对槽况进行打标签?即根据什么指标对槽况进行分类?
8、如何确定最优槽状态评判指标?
这里我根据前人的经验,选取了三个指标进行比对,分别是综合指标d、电解温度、电流效率。
根据综合指标分类的代码如下,这里我用MATLAB:
选取的三个指标进行比对,结果如下:
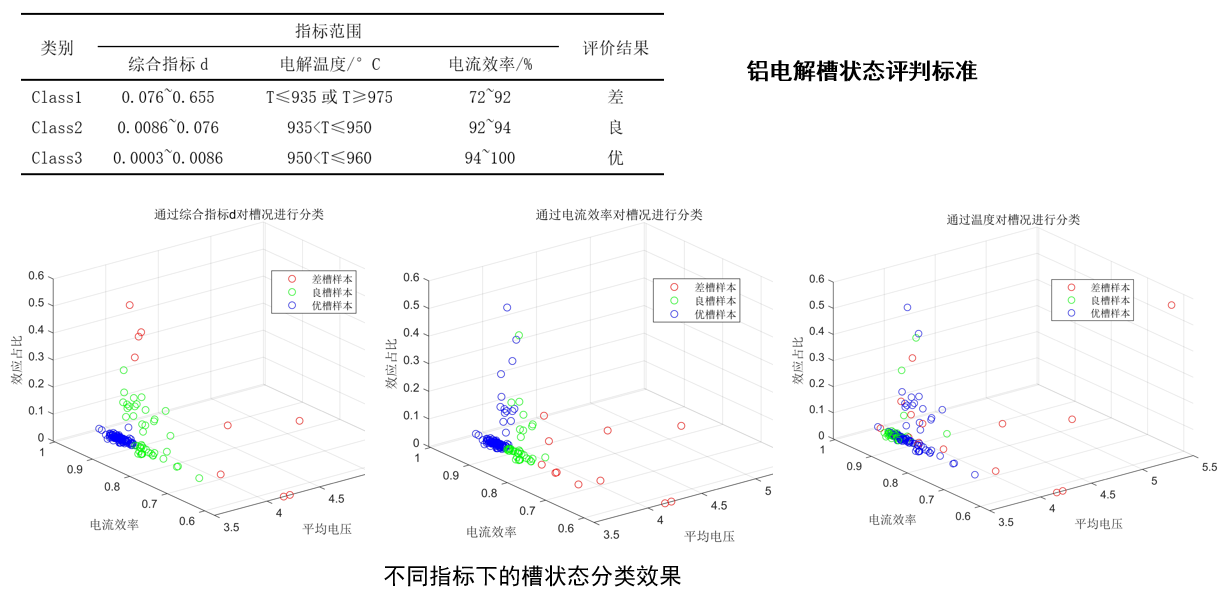
其实我后面想了一下,综合指标d是根据效应占比、电流效率、平均电压来综合评判的,那么电流效率和槽温度就不能也用这几个参数来综合评判了,只不过根据最后模型的准确度来看,综合指标d确实分类效果好一些。

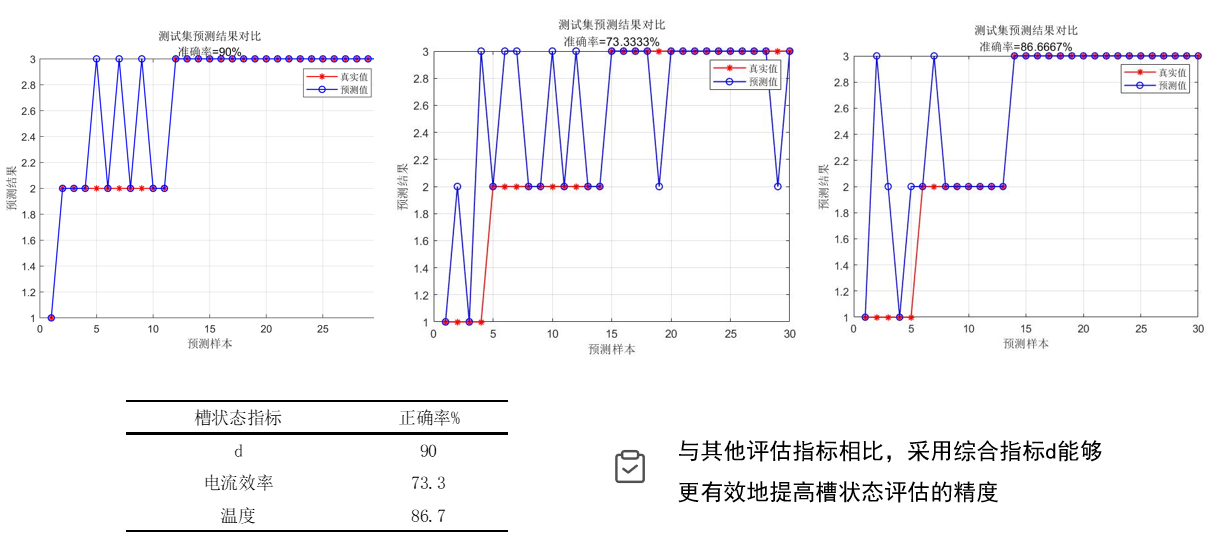
根据支持向量机的分类结果来看,综合指标d的分类效果最佳:
9、怎么对模型进行训练?
怎么对模型进行训练,其实这个问题可以转化为:模型建立的分为几个过程。这几个过程就是上面提到的,数据预处理->特征提取->找出最优的槽况分类指标
接下来就是不断调整支持向量机相应的参数和核函数,得出最优分类结果对应的参数和核函数,具体我不在这里进行展开。
10、怎么验证所训练模型的好坏?
在这里,我选择支持向量机和孪生支持向量机进行对比:

还可以是这样的思路:

11、我的论文所做工作有什么用?
针对铝电解行业存在的问题,电解铝行业需要不断优化生产技术,减少能源消耗,降低生产成本,以应对市场变化,实现企业及行业的可持续发展。
在“中国制造2025”背景下,铝电解槽的质量和效率对于铝行业的发展具有重要影响。铝电解槽的状态评估需要处理大量的数据信息,如电解槽内部的温度、流场分布、电流密度等参数。传统的铝电解槽状态评估方法需要停机后才能进行评估,这不仅影响生产效率,而且可能会错过一些关键信息。相较于传统的铝电解槽状态评估方法,本课题设计铝电解槽况评判模型,对数据进行分类及对模型进行优化,该模型可以帮助企业掌握铝电解槽的运行状态和性能表现,及时发现问题并进行维护和优化。随着人工智能技术的发展,铝电解槽况评判模型也可以与先进的智能化监控系统结合起来,实现实时监测和预警,进一步提高铝电解槽的生产效率和安全可靠性。
12、结语
其实在论文的写作中,我并没有对机器学习和支持向量机有多深入,更多地是论文自洽上画了比较多精力。而自洽,就是应该如何讲好自己的故事,让别人了解你的工作、相信你的成果,我认为,这才是本科生论文写作中最为重要的部分。
另外,我现在已经在工作了,论文写作和代码方面暂不作支持!