- 参考书:
- 《speech and language processing》
- 《统计自然语言处理》 宗成庆
-
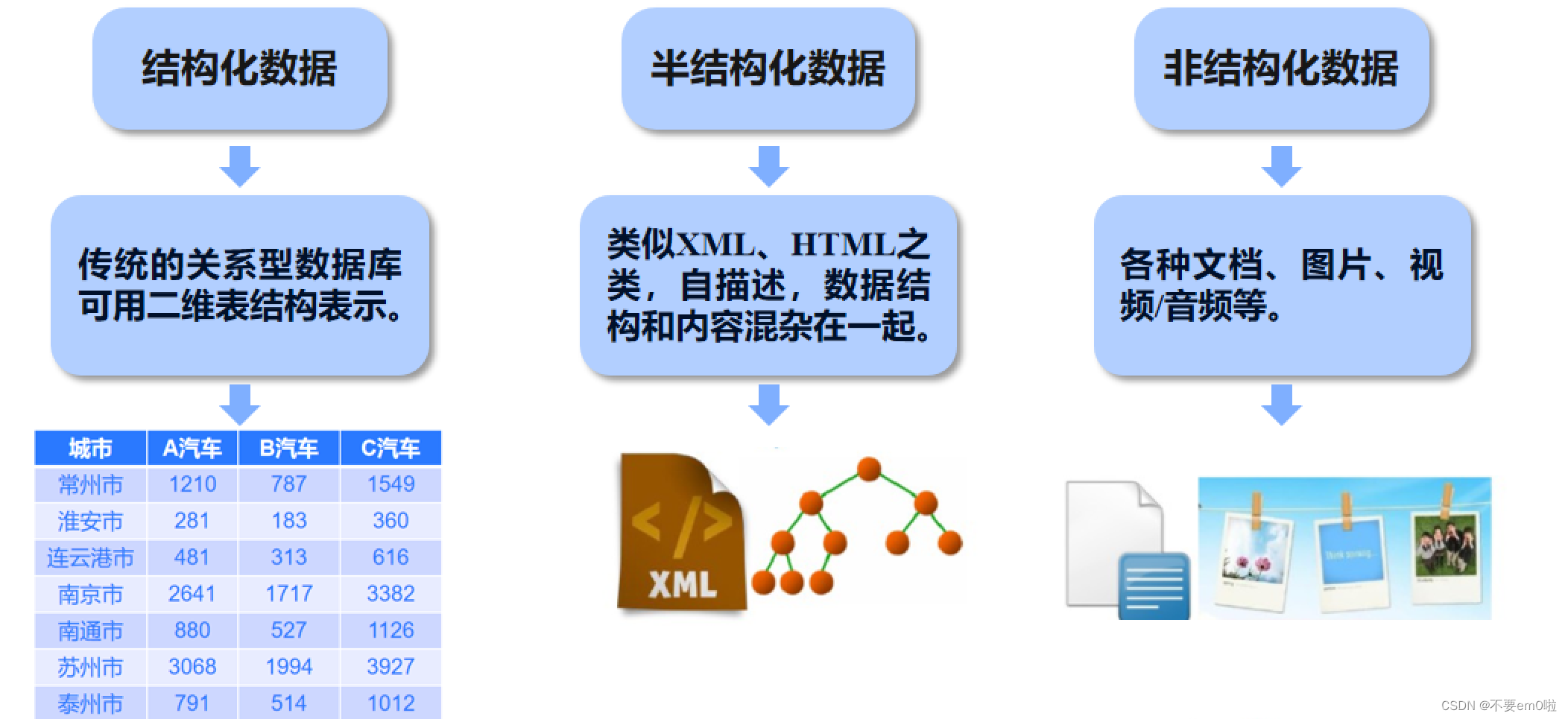
语言是思维的载体,自然语言处理相比其他信号较为特别
-
word2vec用到c语言
-
Question
- 预训练语言模型和其他模型的区别?
预训练模型是指在大规模数据上进行预训练的模型,通常使用无监督学习方法。
在预训练阶段,模型通过学习数据的统计特征来捕捉数据的潜在结构和语义信息。
预训练模型的目标是学习到一个通用的表示,使得该表示可以应用于各种下游任务,如文本分类、命名实体识别等。预训练模型的优势在于可以利用大规模数据进行训练,从而提取出更丰富的特征表示,有助于提高模型的泛化能力和性能。
case:像wordvec2给出所有英文/中文单词的嵌入式表示,可适用于谣言检测
其他深度学习模型通常是指从头开始训练的模型,也称为端到端模型。
这些模型需要根据具体任务的特点和数据集的特征进行设计和调整。相比于预训练模型,
其他深度学习模型需要更多的标注数据和计算资源来进行训练,并且对于不同的任务需要重新设计网络结构和调整超参数。
与之相对应的是其他模型,如传统的机器学习模型或基于规则的模型。
这些模型通常需要手动设计特征或规则,并且需要有标注的数据进行监督学习。
相比之下,预训练模型不需要手动设计特征,而是通过大规模数据自动学习特征表示。
- 同步的序列到序列 与异步的序列到序列 的区别?
同步的序列到序列和异步的序列到序列是两种不同的机器翻译模型架构。
同步的序列到序列模型是指源语言句子和目标语言句子之间的对应关系是一一对应的,即源语言句子中的每个词都对应目标语言句子中的一个词。这种模型在训练和推理过程中都需要同时考虑源语言和目标语言的上下文信息,因此被称为同步模型。同步模型通常使用编码器-解码器结构,其中编码器将源语言句子编码为一个固定长度的向量表示,解码器根据这个向量表示生成目标语言句子。
异步的序列到序列模型是指源语言句子和目标语言句子之间的对应关系不是一一对应的,即源语言句子中的一个词可能对应目标语言句子中的多个词,或者多个词对应一个词。这种模型在训练和推理过程中可以分别处理源语言和目标语言的上下文信息,因此被称为异步模型。异步模型通常使用多层编码器和解码器,其中编码器将源语言句子编码为一个序列的向量表示,解码器根据这个序列的向量表示生成目标语言句子。
总结来说,同步的序列到序列模型要求源语言和目标语言的对应关系是一一对应的,而异步的序列到序列模型允许源语言和目标语言的对应关系是一对多或多对一的。这两种模型在处理机器翻译任务时有不同的优势和适用场景。
- Transformer和Bert的区别
Transformer和BERT都是自然语言处理领域中非常重要的模型,它们都基于Transformer架构,但在一些细节上有所不同。
Transformer是一种用于序列到序列任务的模型架构,最初被提出用于机器翻译任务。它使用了自注意力机制(self-attention)来捕捉输入序列中不同位置之间的依赖关系,避免了传统的循环神经网络中的顺序计算。Transformer由编码器和解码器组成,编码器将输入序列映射为一系列隐藏表示,解码器则根据编码器的输出生成目标序列。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练语言模型。与传统的语言模型只使用左侧或右侧的上下文信息不同,BERT通过使用双向上下文信息进行预训练,从而更好地理解词语的含义。BERT的预训练过程包括两个任务:掩码语言建模(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)。在预训练完成后,BERT可以通过微调来适应各种下游任务,如文本分类、命名实体识别等。
因此,Transformer是一种通用的模型架构,适用于各种序列到序列的任务,而BERT是基于Transformer的预训练语言模型,可以通过微调适应各种下游任务。
- Bert的输出是什么
Bert(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,它可以将输入的文本转换为向量表示。Bert的输出是一个表示输入文本的向量序列,其中每个向量都包含了该位置的词语的语义信息。
具体来说,Bert模型通过将输入文本分为多个token,并将每个token转换为对应的词向量。这些词向量经过多层的Transformer编码器进行处理,得到每个token的上下文相关表示。Bert模型的输出包括两个部分:
Token级别的输出:每个token对应一个向量表示,这些向量可以用于各种下游任务,如文本分类、命名实体识别等。
句子级别的输出:Bert模型还提供了一个特殊的向量表示,通常被称为CLS向量(classification vector),它捕捉了整个句子的语义信息。这个CLS向量可以用于句子级别的任务,如句子分类、句子相似度计算等。
需要注意的是,Bert模型是基于无监督预训练的,它通过大规模的语料库进行训练,学习到了丰富的语义信息。在实际应用中,可以将Bert模型作为特征提取器,将其输出作为输入传递给其他机器学习模型或神经网络进行下游任务的训练和推理。
- Bert的过程与作用
-
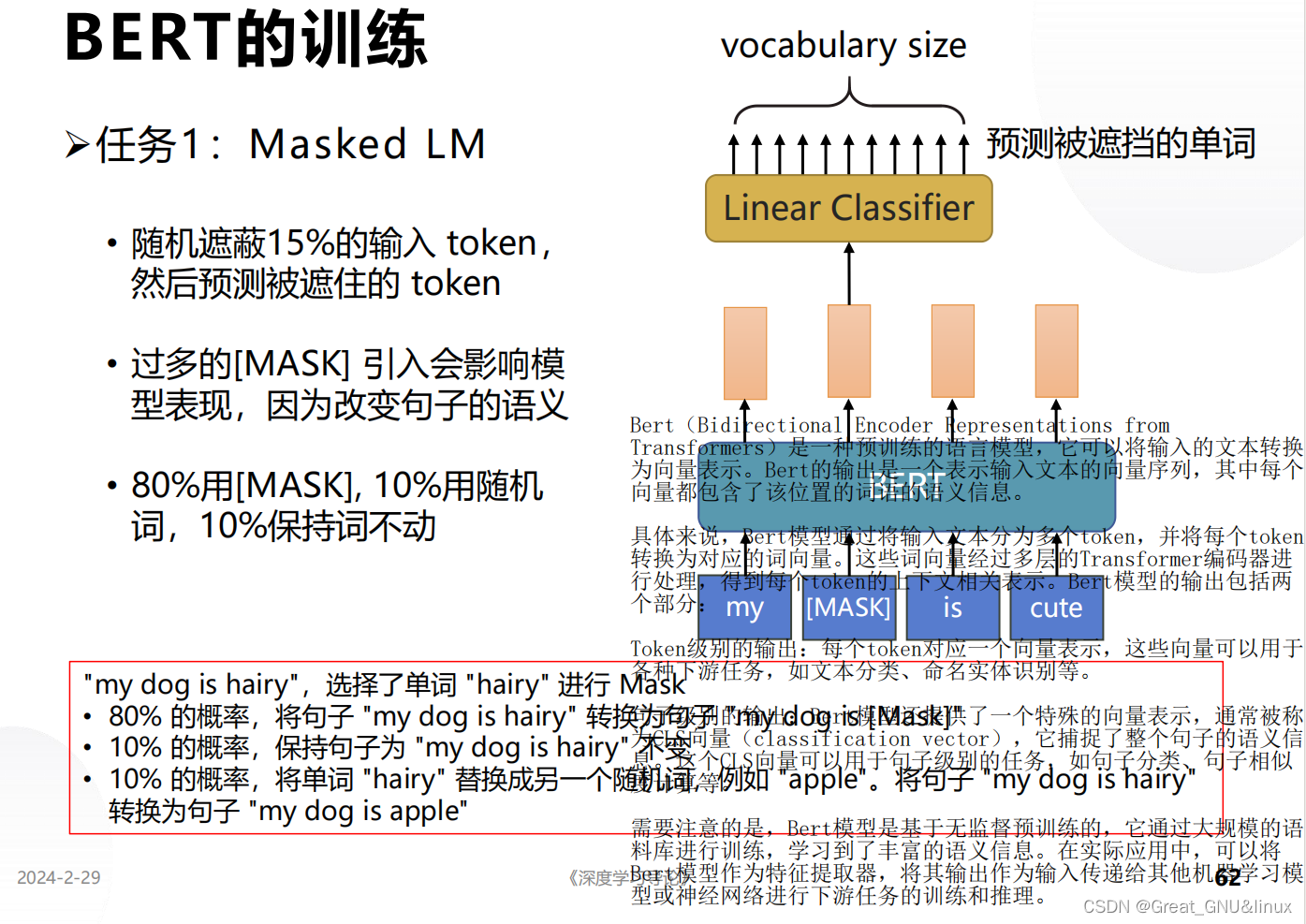
从训练过程可以看出,掩码语言建模 ⟹ \Longrightarrow ⟹学习上下文单词间关系;
实现方式:Mask也有特殊嵌入式表示,按多头自注意力机制,输出各token的向量序列,掩码token对应的向量反嵌入转为单词
-
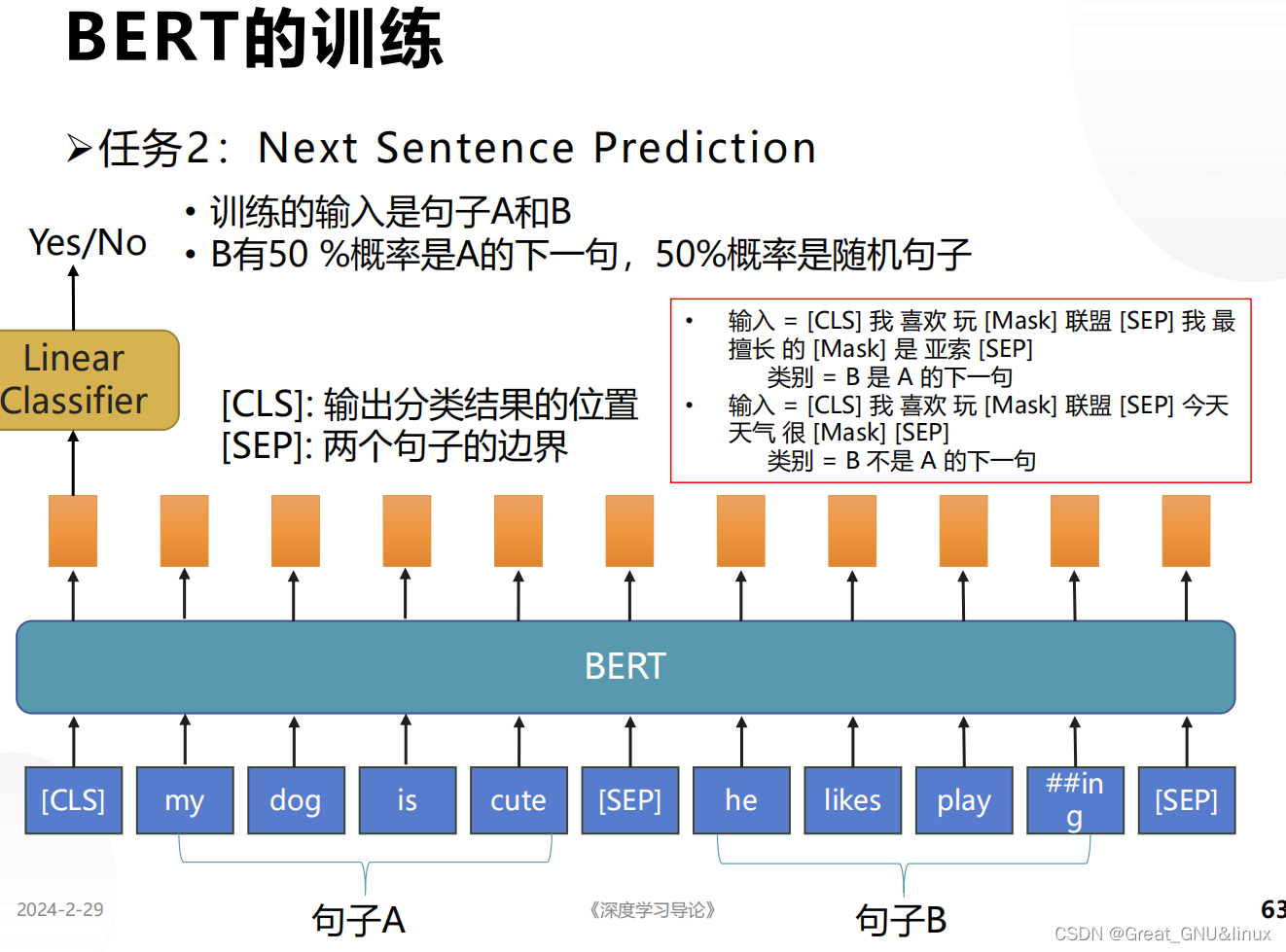
预测下一句是否合理 ⟹ \Longrightarrow ⟹学习单词的集合表示 → \rightarrow →句义的上下文关系
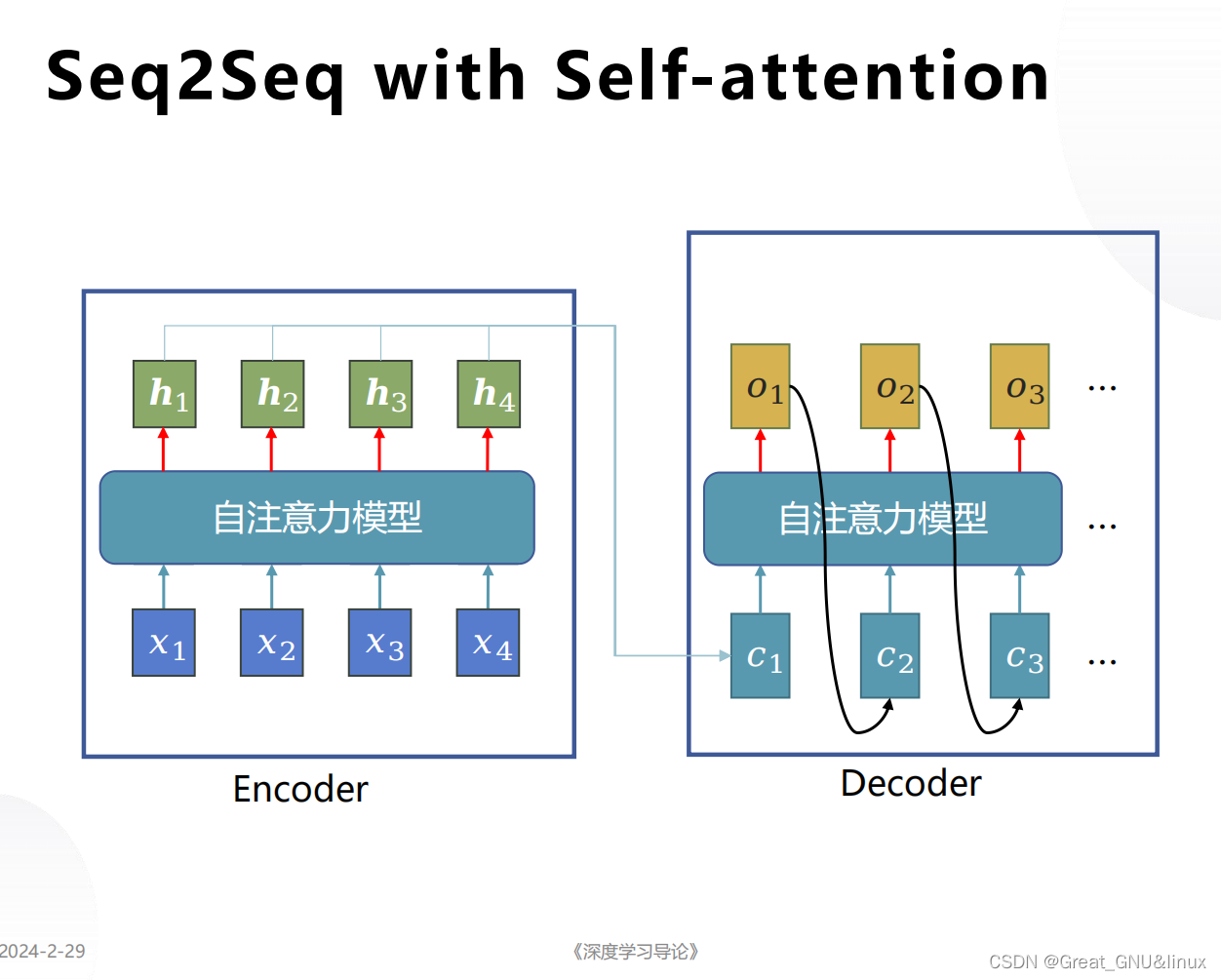
- 多头自注意力机制用于编码,可以或用LSTM解码,这就是Transformer.
- Fourier变换的作用?
Fourier变换是一种数学工具,用于将一个函数从时域(域)转换到频域(频率域)。它可以将一个信号分解成一系列不同频率的正弦和余弦函数的叠加,从而揭示出信号中包含的各个频率成分的强度和相位信息。
Fourier变换在信号处理、图像处理、通信系统、音频处理等领域中具有广泛的应用。它可以用于信号滤波、频谱分析、噪声去除、图像压缩、音频合成等任务。通过将信号从时域转换到频域,我们可以更好地理解信号的频率特性,从而更好地处理和分析信号。
具体来说,Fourier变换可以将一个连续时间的函数表示为一系列复数的和,每个复数代表了不同频率的正弦和余弦函数的振幅和相位。这些复数被称为频谱,它们描述了信号在不同频率上的能量分布情况。通过对频谱进行操作,我们可以实现信号的滤波、频谱分析和合成等功能。
总结一下,Fourier变换的作用是将一个函数从时域转换到频域,揭示出信号中各个频率成分的强度和相位信息,为信号处理和分析提供了重要的数学工具。
- 在检测 人脸框 方面,yolov3和MTCNN的区别?
Yolov3和MTCNN是两种常用的人脸检测算法,它们在实现原理和性能上有一些区别。
Yolov3是一种基于深度学习的目标检测算法,它通过将图像分成多个网格,并在每个网格上预测多个边界框和类别概率来实现目标检测。相比于传统的滑动窗口方法,Yolov3具有更高的检测速度和更好的准确率。在人脸框检测方面,Yolov3可以通过训练一个人脸数据集来实现人脸框的检测,但由于其设计的特点,可能会存在一定的定位误差。
MTCNN(Multi-task Cascaded Convolutional Networks)是一种基于深度习的多任务级联卷积网络,主要用于人脸检测和人脸关键点定位。MTCNN通过级联三个网络来逐步筛选候选框,并对候选框进行精确定位和人脸关键点定位。相比于Yolov3,MTCNN在人脸框检测方面更加准确,能够提供更精细的人脸框位置和人脸关键点信息。
综上所述,Yolov3和MTCNN在人脸框检测方面的区别主要体现在实现原理和性能上。Yolov3具有更高的检测速度,但可能存在一定的定位误差;而MTCNN在准确性和精细度上更胜一筹。选择哪种算法取决于具体应用场景和需求。