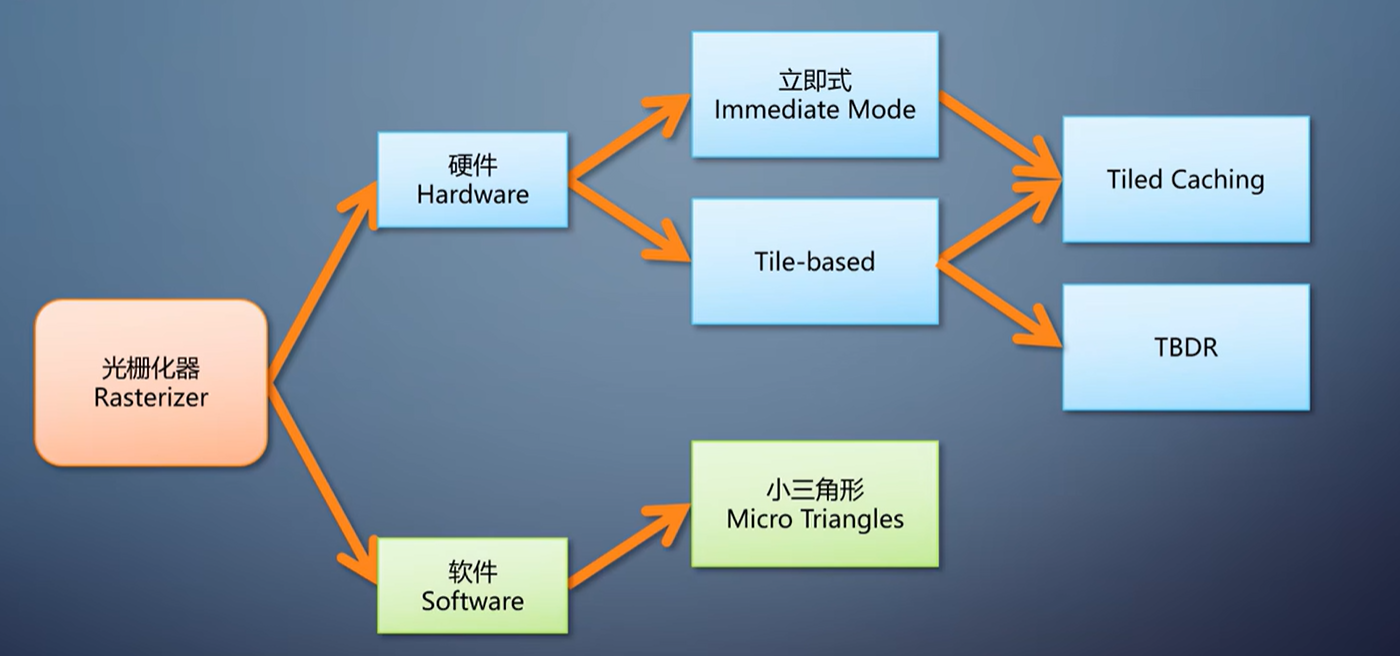
- 【GPU】图形流水线基础
- 【GPU】逻辑上的模块划分
- 【GPU】部署到硬件
- 【GPU】完整的软件栈
前几期我们过了一遍GPU的软硬栈。这次我们将深入GPU图形流水线的一些细节,看看那些不可编程的模块是怎么工作的。
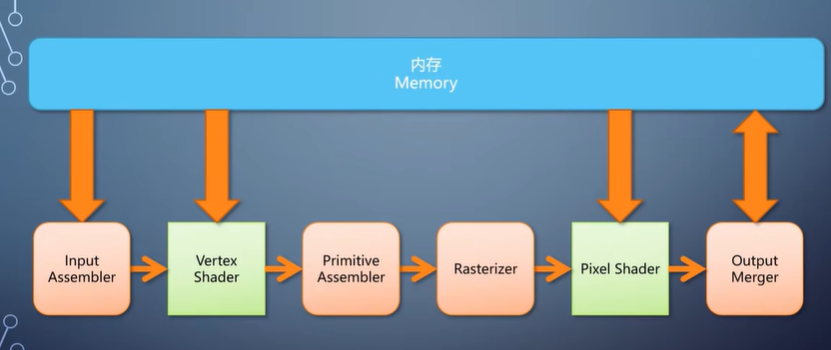
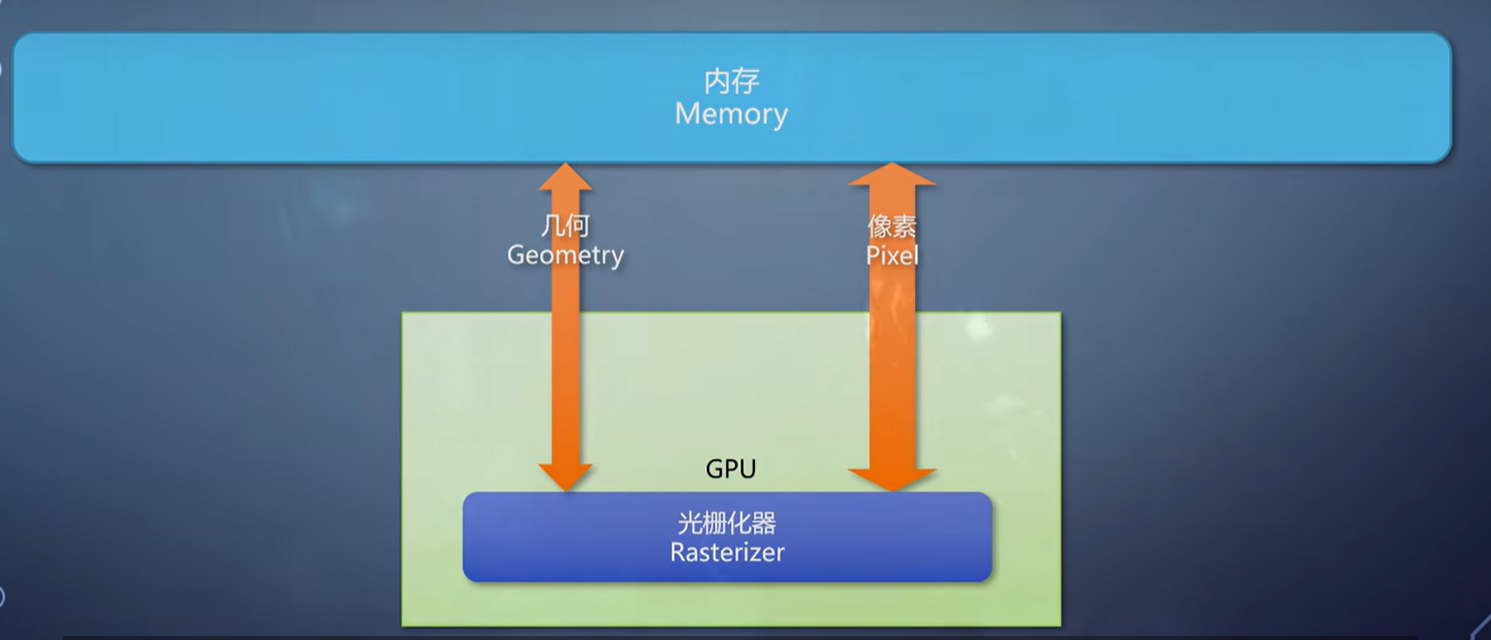
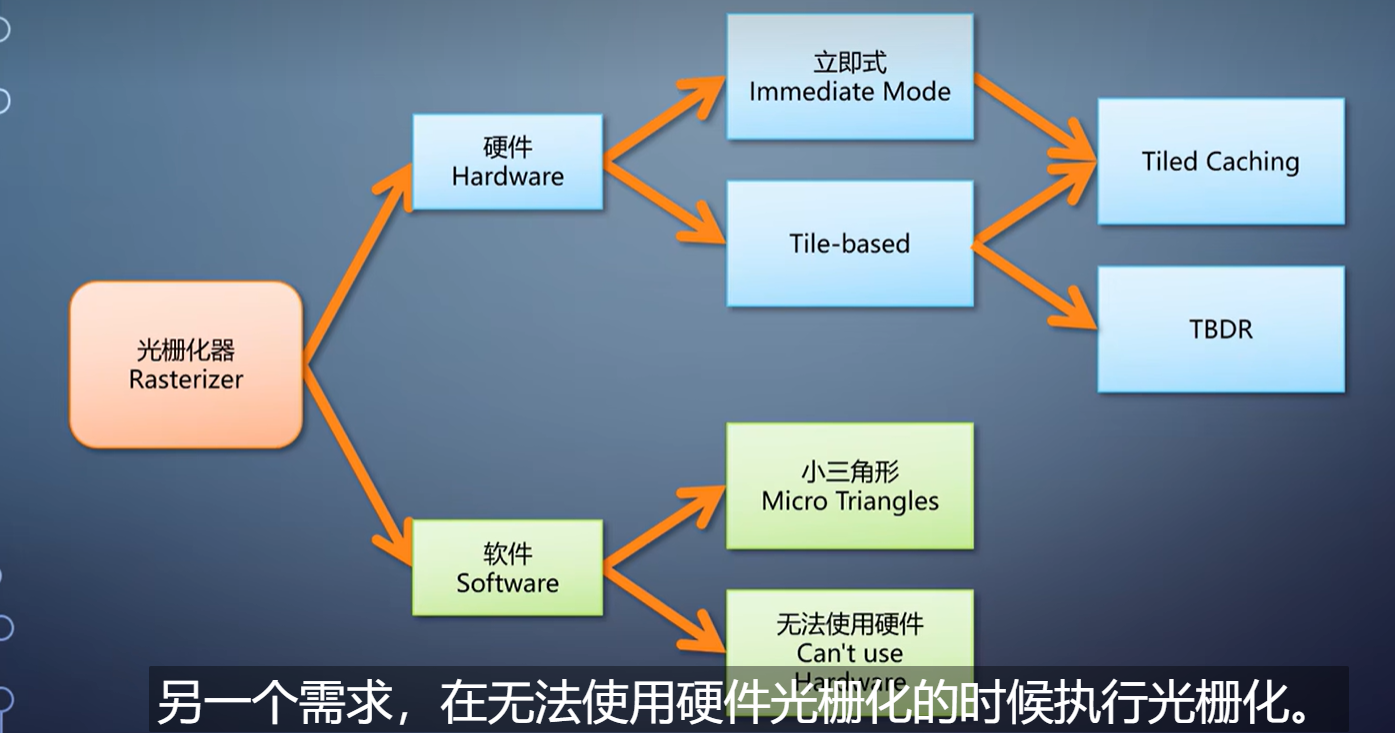
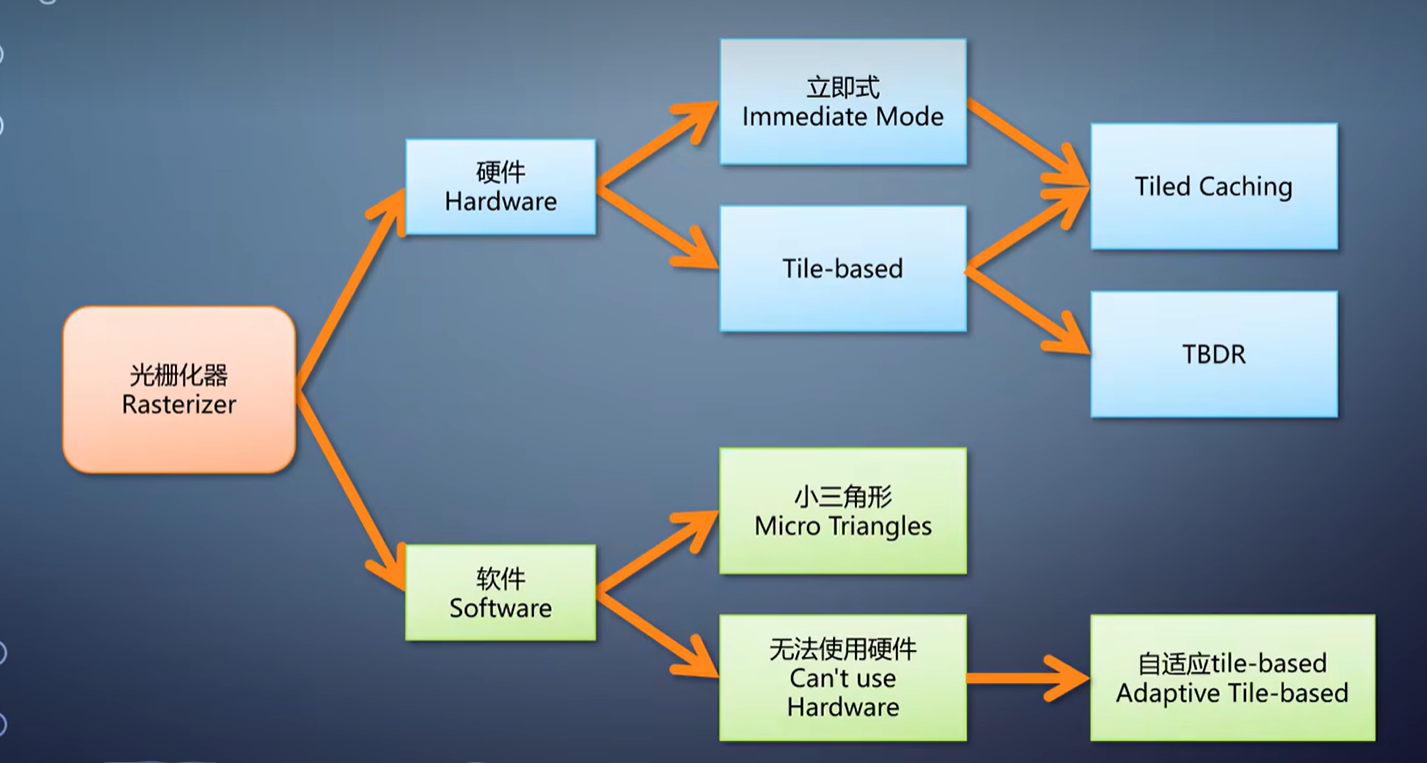
对于GPU的图形流水线来说,最核心最重要的一个组件就是光栅化器。
它的存在,直接决定了GPU在实时渲染方面的优势。以至于很多时候光栅化就是GPU图形流水线的代称。
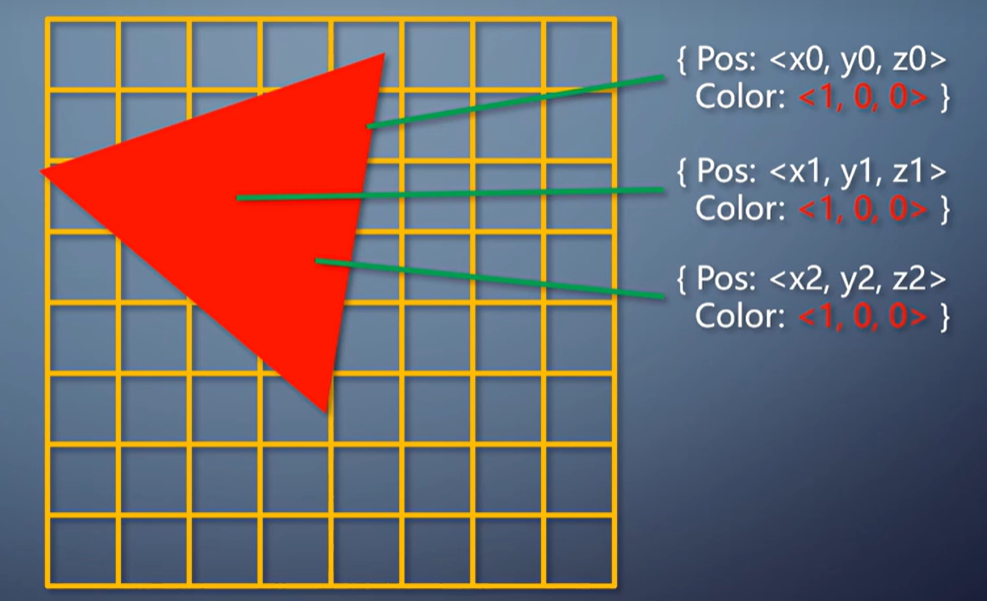
以前说过,经过vertex shader之后,每个顶点上都有了转换后的属性。

包括位置、法线方向、颜色、纹理坐标等。
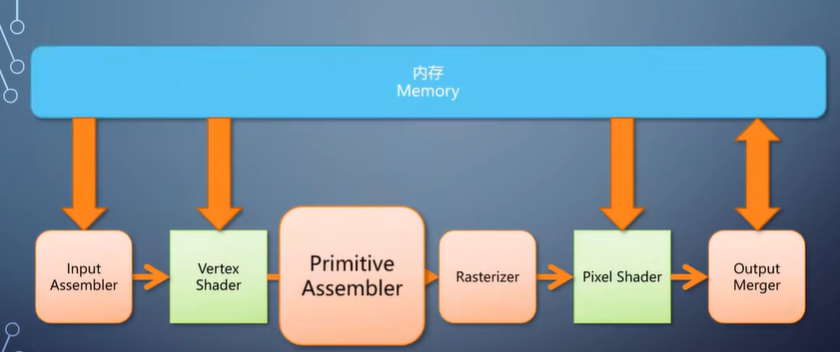
经过primitive assembler之后来到光栅化阶段,转换成像素。
所以,光栅化这个操作,本质上就是把三个顶点上的信息,
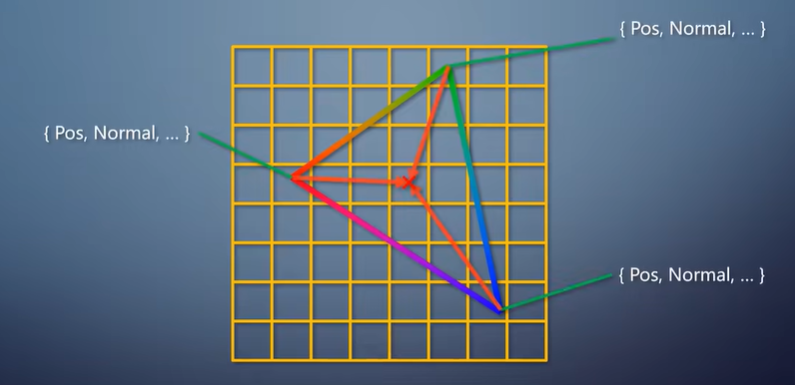
插值到这个三角形覆盖的每个像素上,交给pixel shader。
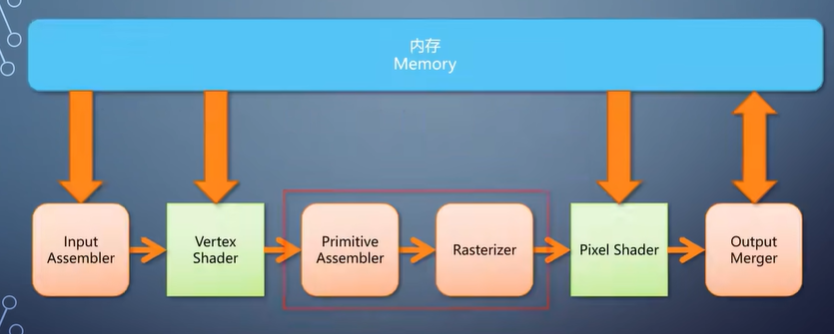
Primitive assembler和光栅化总是连在一起, 因此成为了广义的光栅化器。
下面我也会把这两部分合并起来描述算法。要完成这样的插值,常见的方法称为扫描线算法。
顶点上有一系列的属性,根据三个顶点的位置和属性变化的程度,可以算出这个三角形覆盖的区域里。

从一个像素挪到右边或者下边,各个属性会改变多少。这称为ddx和ddy。

对于一个三角形来说,属性的ddx和ddy都是常量,只要算一次就行。
接着,从最靠上的顶点开始,沿着轮廓一行一行往下扫。
每一行根据三角形轮廓就能知道应该从哪里开始,到哪里结束。

往右一个像素,属性增加一次ddx,往下一行,属性增加一次ddy。
这样扫描生成三角形覆盖的所有像素。
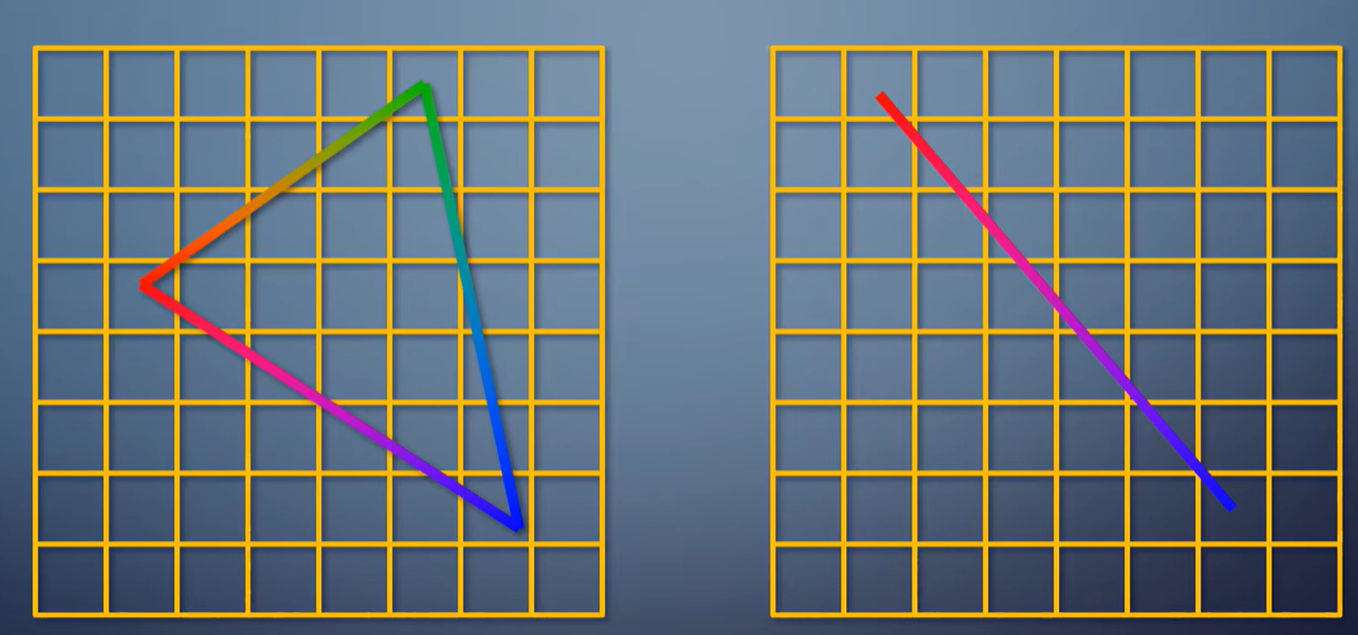

那么,像素在什么情况下认为被三角形覆盖?这叫做光栅化规则。普通模式下,光栅化三角形看的是像素中心是否在三角形之内。
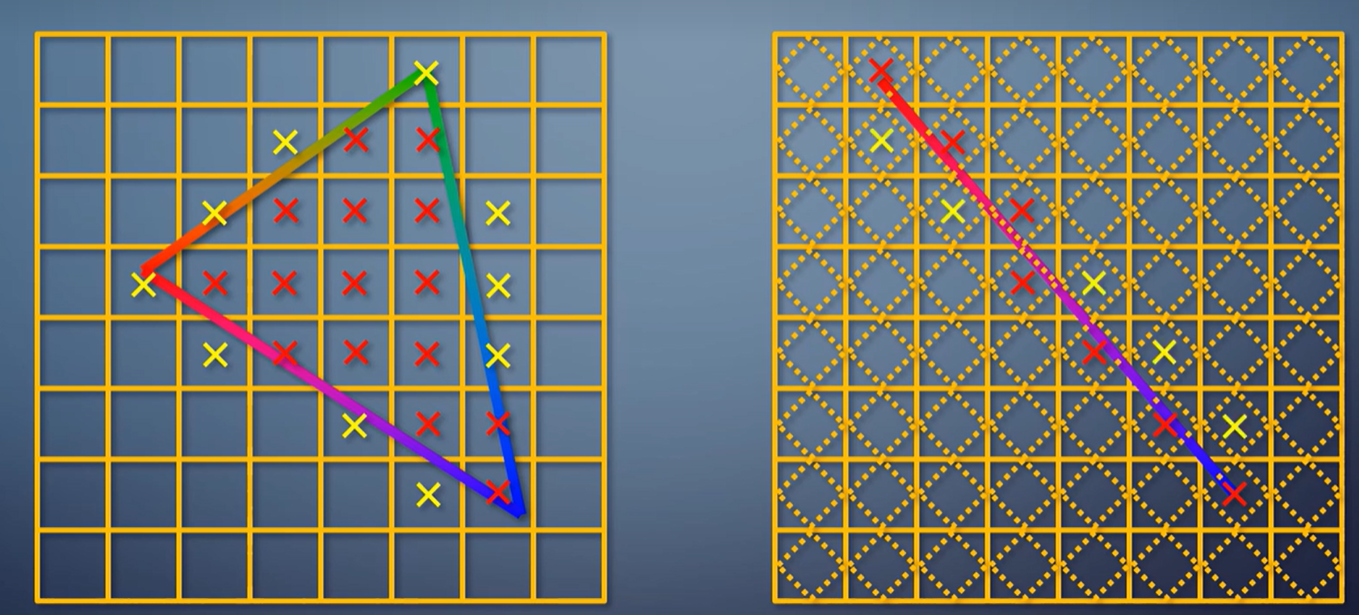
光栅化线看的是线是否经过像素里的一个菱形区域,另一种模式是只要沾到一点就算覆盖。这叫保守式光栅化,常用于体素化的需求。

比如前几年很热门的SVO cone tracing, 就用保守式光栅化来把整个场景变成体素的表达。
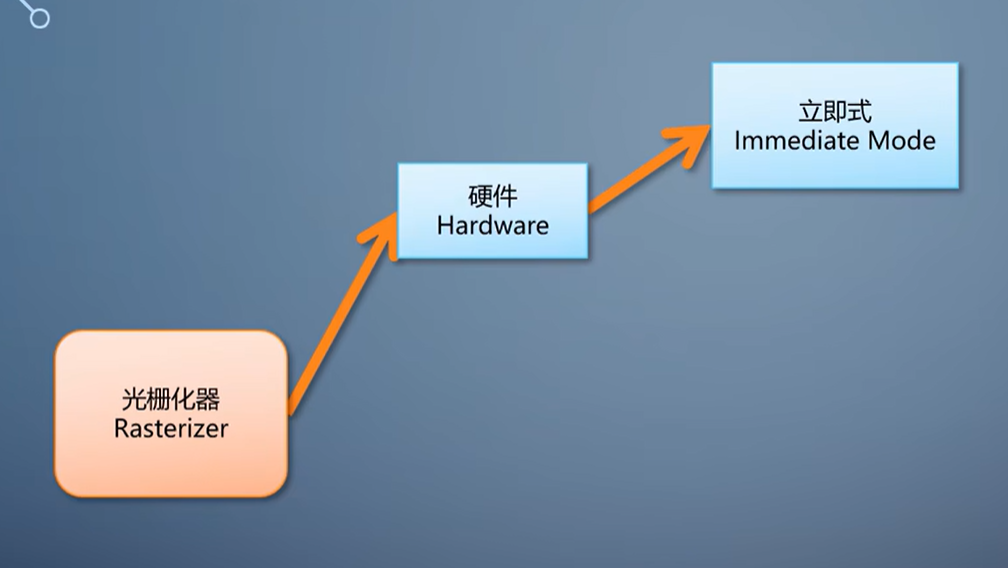
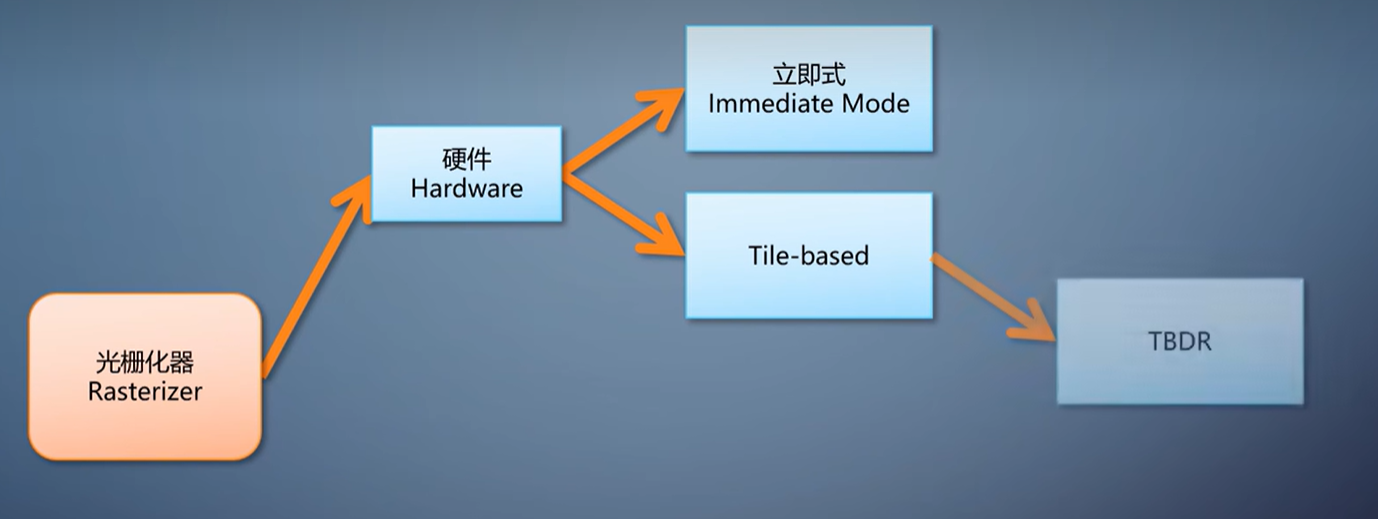
光栅化的算法有了,直接放到硬件上,就成了立即式光栅化。

这个做法很淳朴,用ASIC把刚才描述的算法变成硬连线。
在算法完全固定的情况下,ASIC的效率远高于FPGA和可编程单元。, 立即式光栅化生成的像素,经过流水线后面的几个阶段,写入内存里的渲染目标。

渲染目标可能是纹理也可能是帧缓存。
对于大三角形来说,这么做性能非常高。因为只要算一次ddx、ddy,后面一路累加过去就行,可以不被打断地一直执行同样的操作。

但是,如果三角形层层叠叠,就得反复写入内存,带宽占用很大,功耗高。


对PC渲染的需求来说,只要性能高,功耗高一点也可以接受的,
所以往往会选择立即式光栅化的方案。

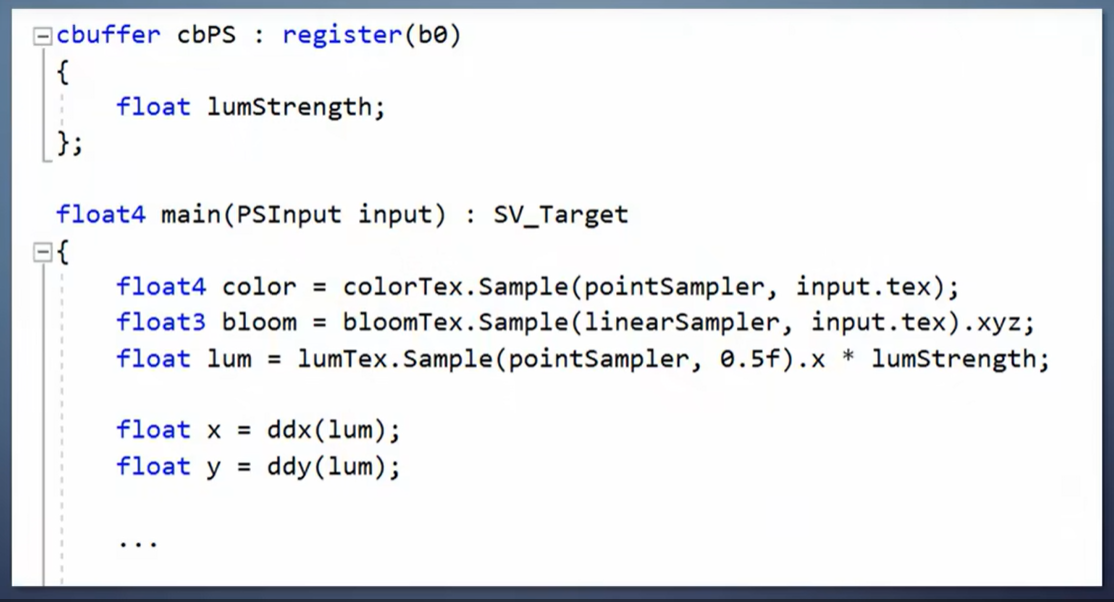
这张图是我在AMD的GPU上得到的,其中的颜色表达了像素到达pixel shader的顺序。
从这里可以看出,这个GPU采取了32个像素的高度,一条一条的光栅化方式。

而CPU光栅化的WARP,就是一个一个像素扫过去的方式。
到了移动平台,这就够呛了。移动平台更看重的是性能功耗比。

如果性能只有一半,但功耗只有四分之一,也会考虑采纳。
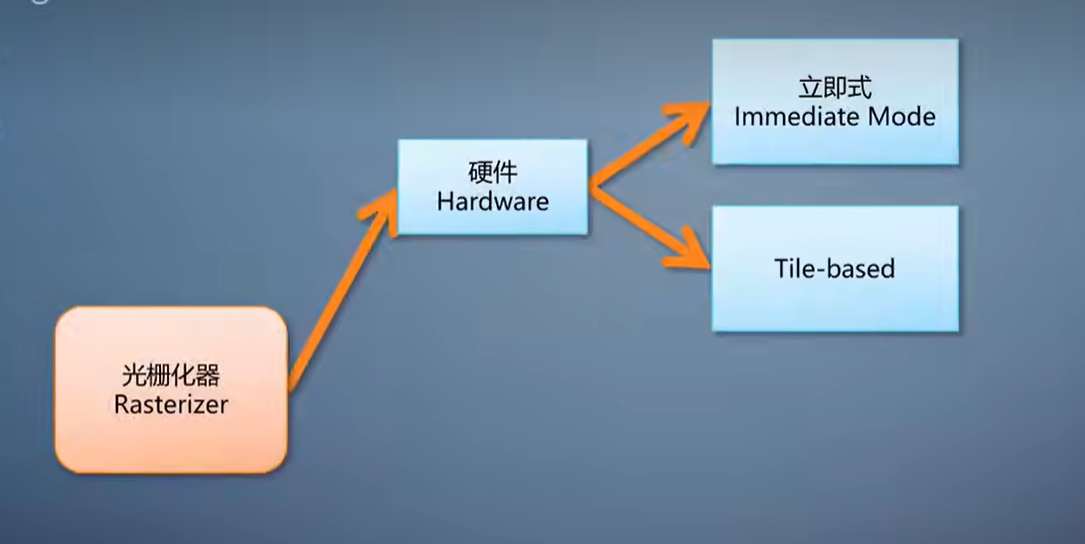
于是,移动平台上,光栅化往往采用tile-based方案。它把渲染目标划分成很多固定大小的tile,常见的是32x32。

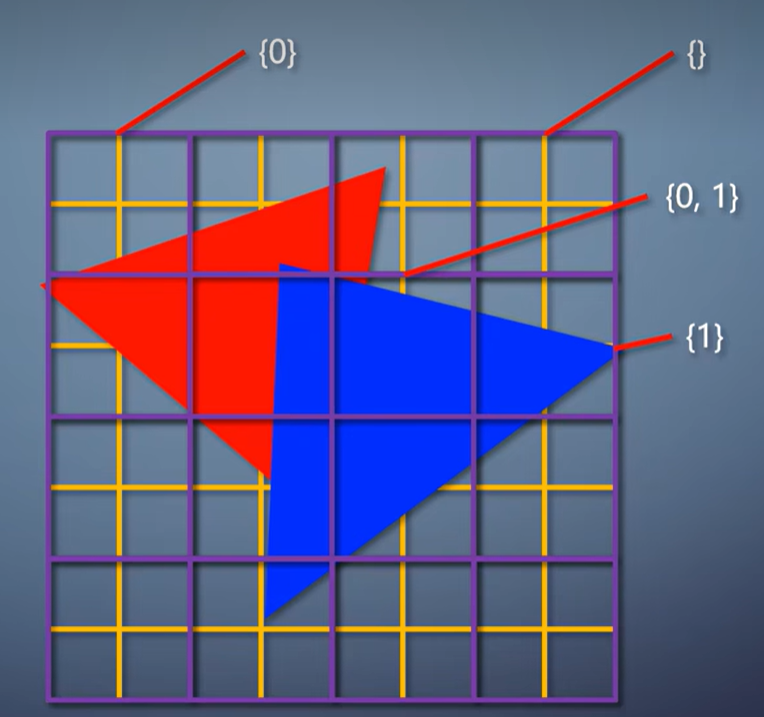
每个tile包含一个列表,存有和这个tile相交的所有三角形。所以tile-based光栅化不再是一个一个三角形处理,而是一批一批处理。
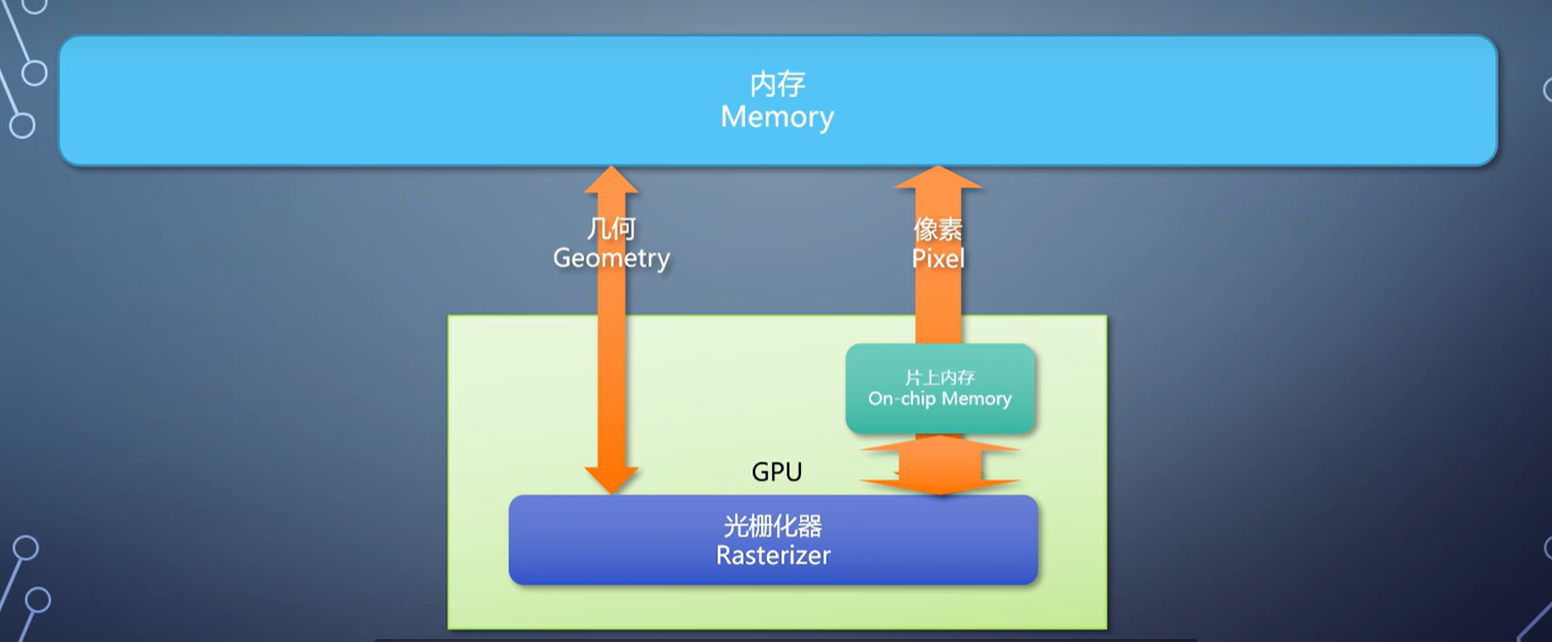
这样的GPU,需要有一个片上内存充当cache的角色,不需要大,但访问速度远远高于内存。

对于每个tile,先会把渲染目标的对应区域载入GPU的片上内存。接着用扫描线算法,把列表里的三角形都渲染上去。,最后把片上内存里的结果存到渲染目标。
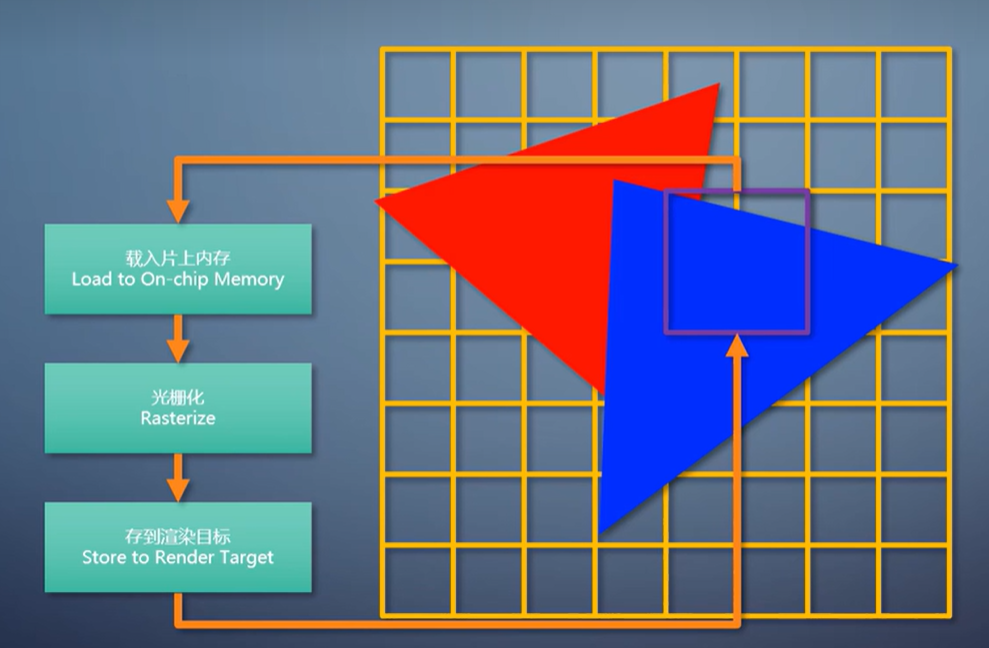
然后开始处理第二个tile。
不管三角形如何层层叠叠,每个tile每次对内存的读写,总是只有32x32个像素,远低于立即式。
但因为一个三角形没法一直填充下去,会因为tile而被打断,性能其实是降低的。

只是相比之下功耗降得更多。

这是在高通的GPU上跑出来的光栅化顺序图。
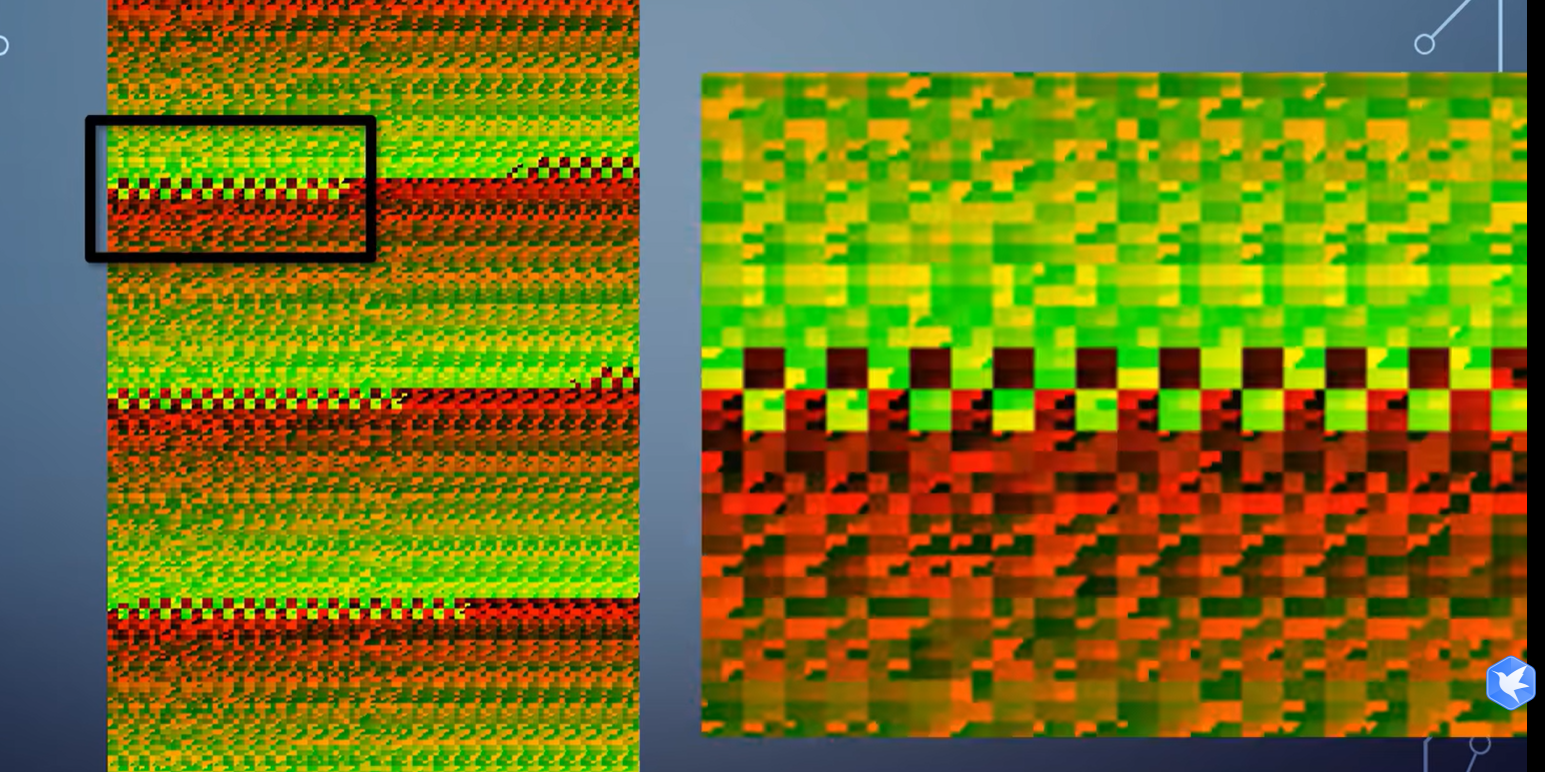
可以看到每个tile大小固定,一个一个tile铺成了整个屏幕。
为了让大家加深印象,这里举两个实际的场景,比较一下立即式和tile-based在工作流程上的区别。
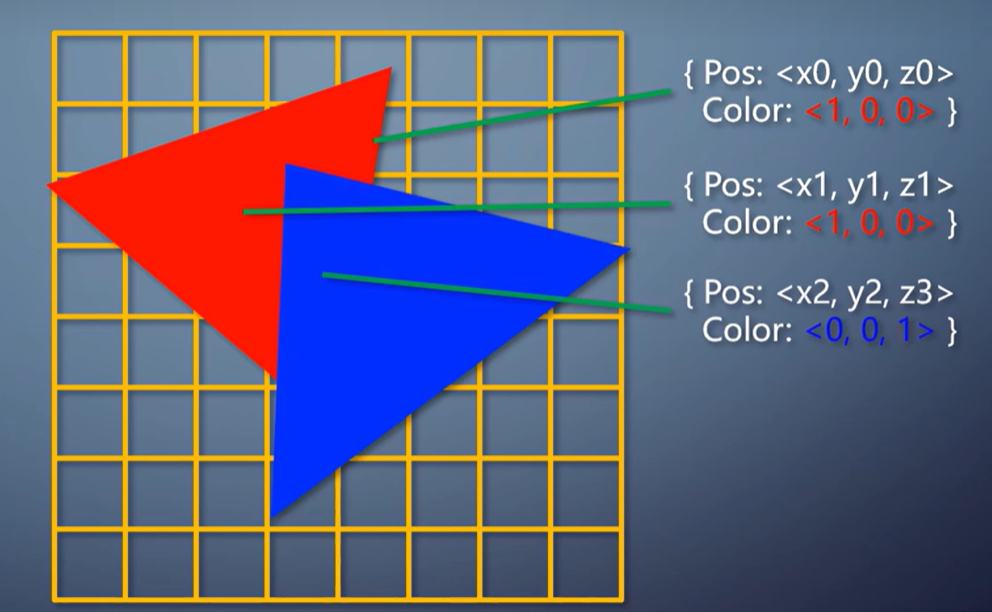
同样是渲染两个三角形。
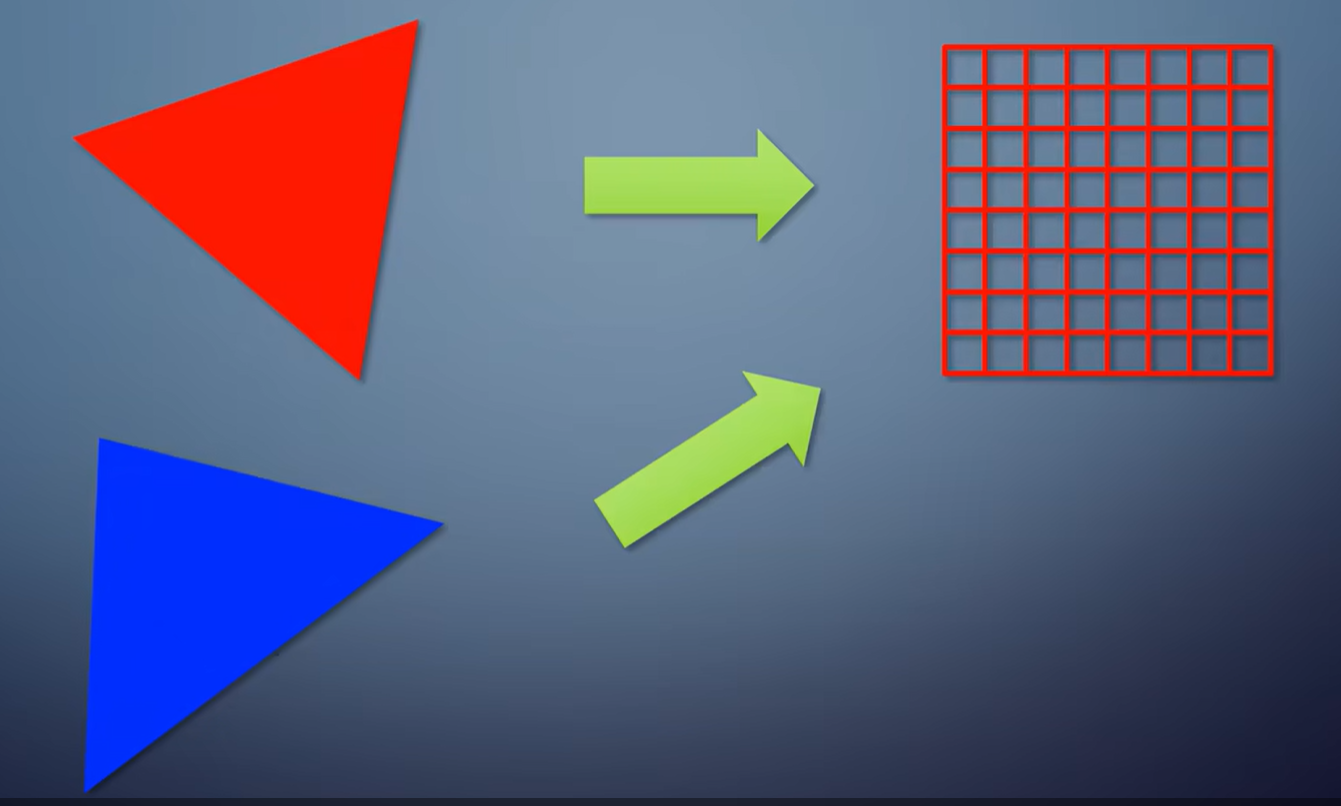
第一种情况,把它们渲染到同一张纹理。
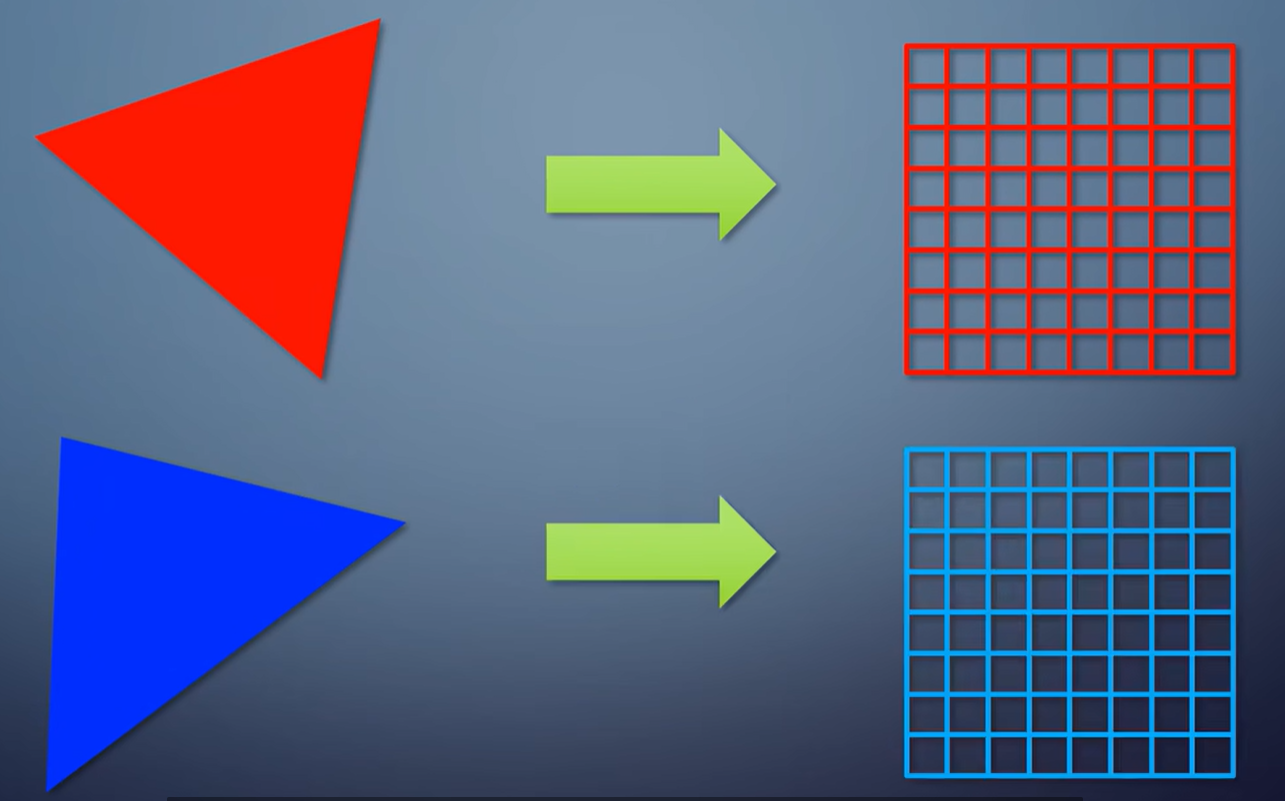
第二种情况,把它们分别渲染到两张纹理。
对于立即式来说,都是把三角形光栅化出去。

两个三角形是不是到同一个纹理无所谓。操作是一样的。因此两者的性能和功耗区别可以忽略不计。
对于tile-based,这俩就很不一样了。

第一种情况,光栅化的流程是,第一个tile载入到片上内存,渲染两个三角形,存到纹理;
第二个tile载入到片上内存,渲染两个三角形,存到纹理;
依此处理完所有tile。
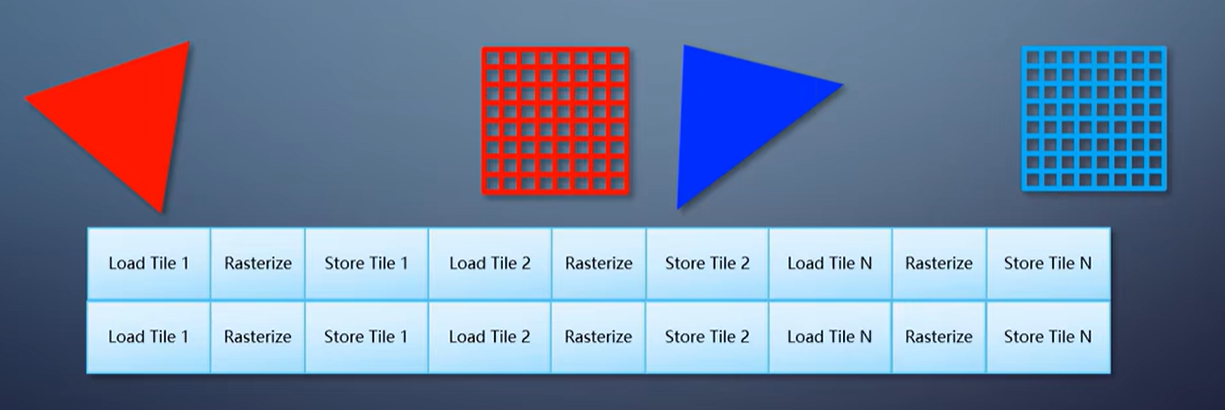
第二种情况的流程就变成,纹理A的第一个tile载入到片上内存,渲染三角形A,存到纹理A;
纹理A的第二个tile载入到片上内存,渲染三角形A,存到纹理A;
依此处理完纹理A的所有tile;
纹理B的第一个tile载入到片上内存,渲染三角形B,存到纹理B;
纹理B的第二个tile载入到片上内存,渲染三角形B,存到纹理B;依此处理完纹理B的所有tile。
注意,在片上内存里的操作非常快,访问内存里的纹理,慢得多而且耗电得多。
因此第一种情况比第二种好情况得多。这也是为什么在tile-based GPU上,切换渲染目标成为大忌。
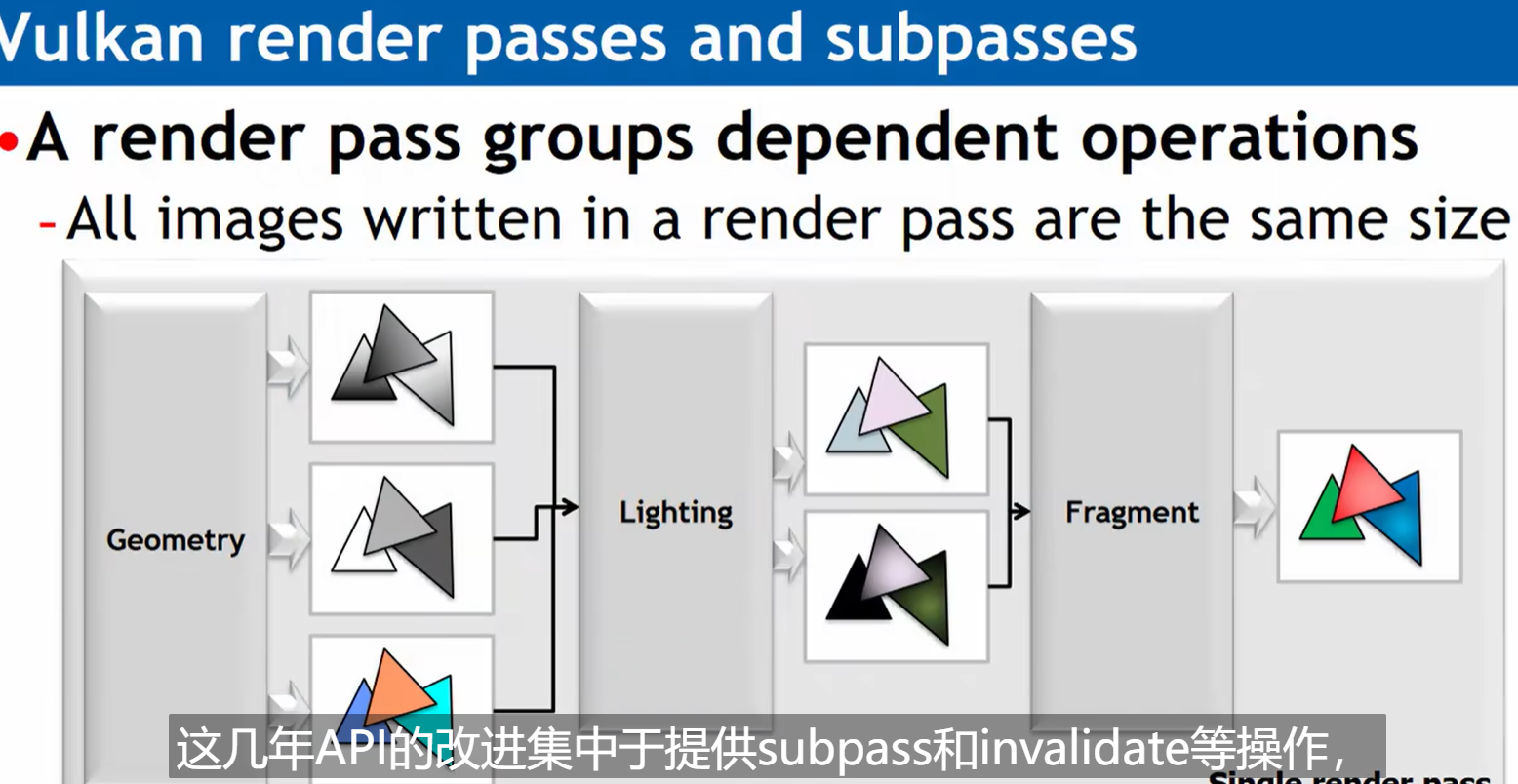
这几年API的改进集中于提供subpass和invalidate等操作,可以让开发者决定是否把纹理的tile载入片上内存,以及渲染后是否存到纹理,以减少这部分的开销和功耗。

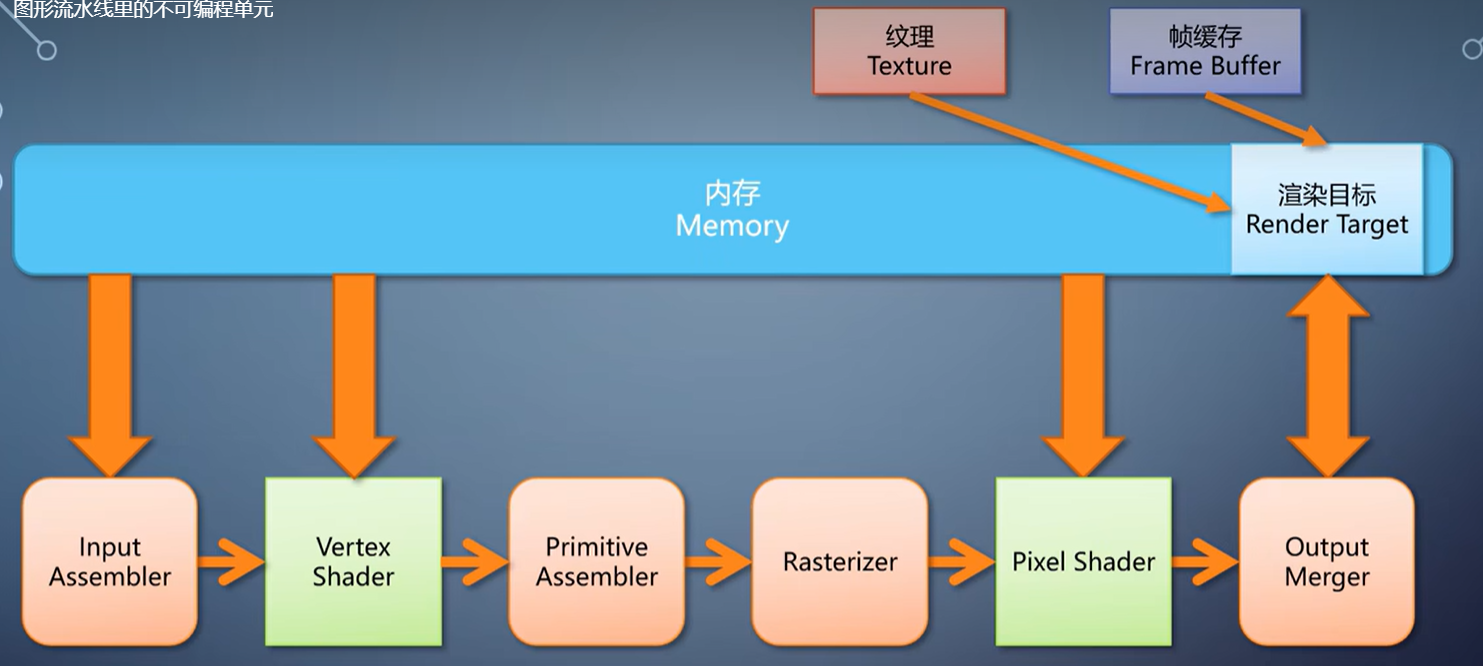
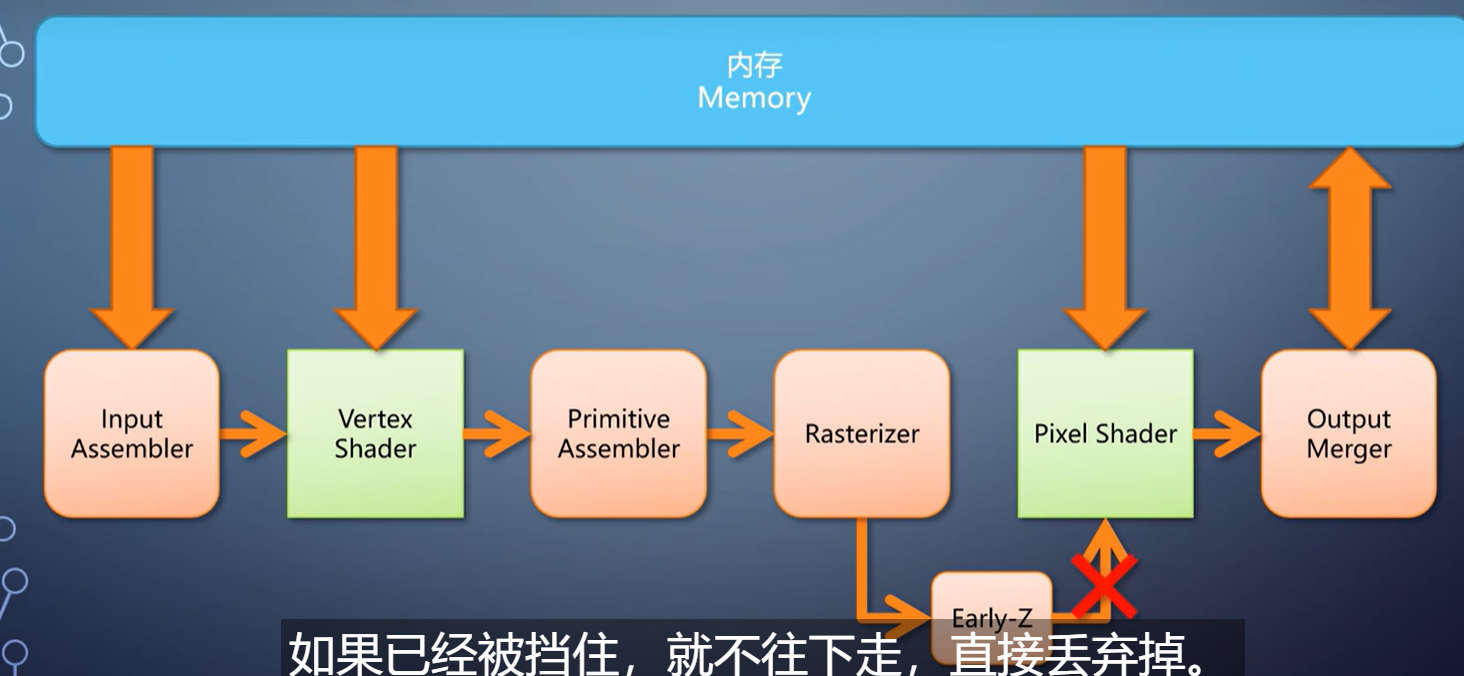
继续往后看。光栅化产生的像素,会进入pixel shader,然后是output merger。

场景是存在遮挡的,近的会挡住远的。

之前说过,这是在output merger里通过深度测试来完成。

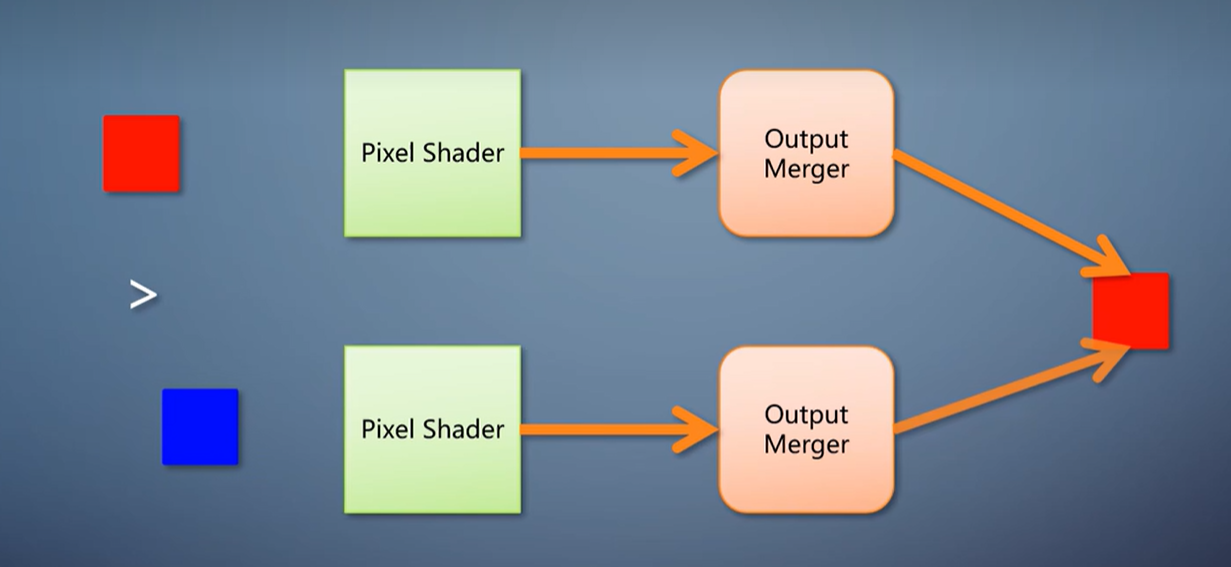
假设光栅化产生了像素A,跑完后面的流程,写入渲染目标,又在同一位置产生像素B。
这里会产生两个问题。
第一,如果像素B比像素A还近,,那它跑完后面的流程之后,会覆盖掉像素A。
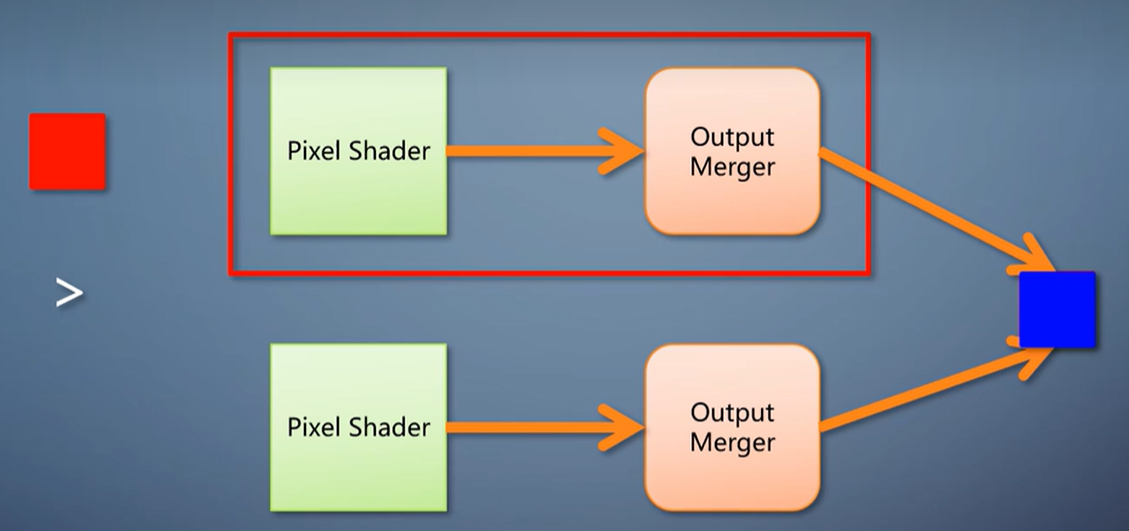
这使得像素A经过的pixel shader和output merger完全浪费了。

第二,如果像素B比像素A还远,也得等到运行了pixel shader,进入output merger,才能发现有遮挡,才抛弃掉像素B。
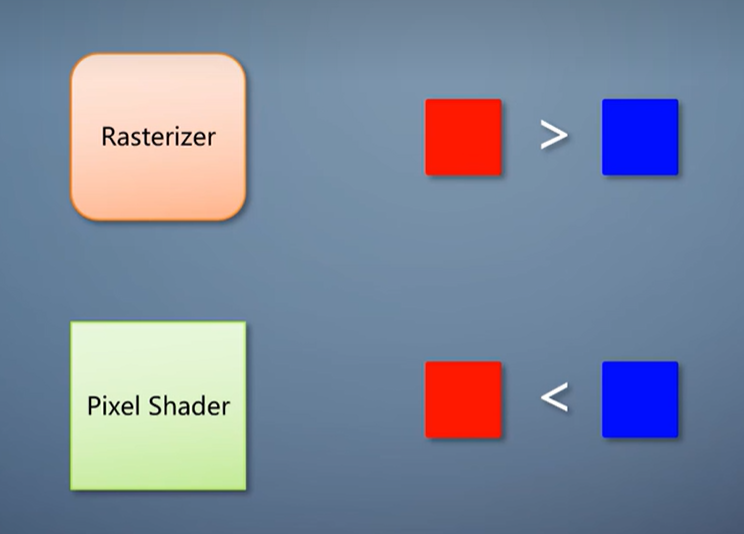
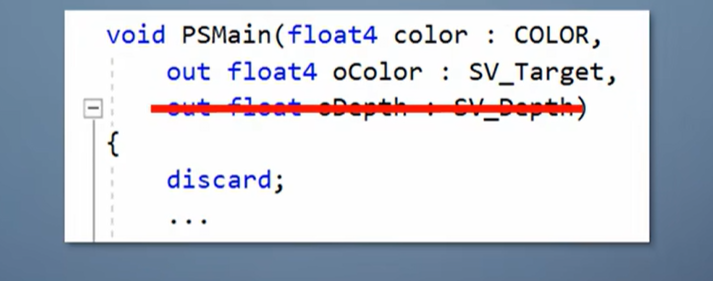
那么像素B的pixel shader也白运行了。能不能把深度测试从output merger挪到pixel shader之前呢?

不总是可以的,因为pixel shader不但能输出颜色,也能输出深度。

如果光栅化产生的深度和pixel shader输出的深度顺序不一致,在pixel shader之前执行深度测试就会出错。
为解决第二个问题,GPU引入的功能称为early-z。
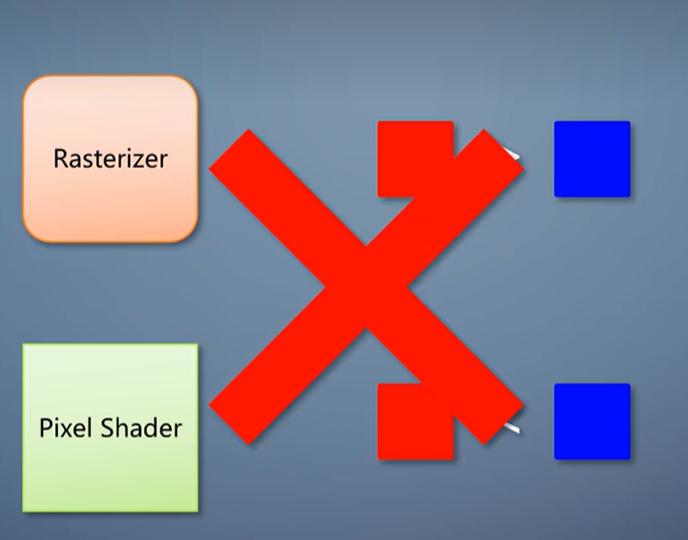
在渲染状态符合条件的情况下,驱动会检查一下pixel shader,如果不输出深度、不用discard丢弃像素,就启用early-z。


像素在进入pixel shader之前提前进行一次深度测试。
如果已经被挡住,就不往下走,直接丢弃掉。
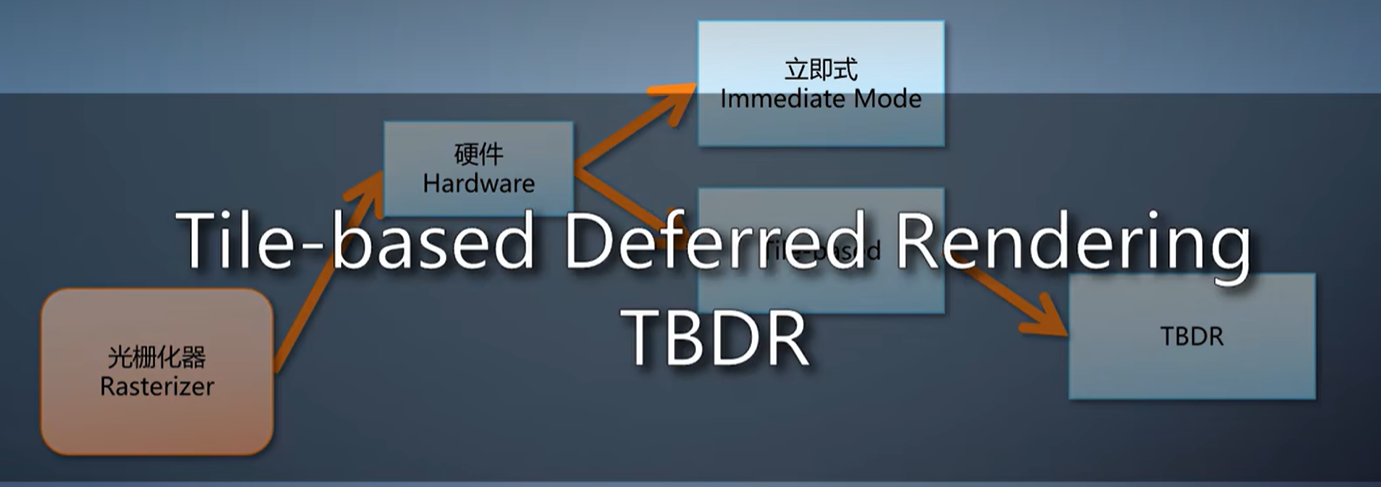
在tile-based的光栅化上,有的GPU会有个称为TBDR的模式,tile-based deferred rendering。
TBDR在开启深度测试的情况下,把光栅化插值得到的像素属性都写入片上内存。
这时候不可见的像素就被抛弃了,只有可见的继续往下走,同时解决那两个问题。
但是它无法独立存在的,也是要一系列条件都符合的情况下才能启用,否则退回到tile-based模式。
既然立即式性能高,tile-based性能功耗比高,能不能取长补短一下?

有的,Maxwell之后的NVIDIA GPU,就采用了两者的结合,称为tiled caching。
它的tile巨大,256x256这个级别,cache也很大,不光像素,还可以把tile需要的几何也载入cache。
这么做降低了内存访问,性能和性能功耗比都更高了。这里仍然可以用一张光栅化的顺序图来看到这个情况。
前面说的,都是用硬件直接构造光栅化。它的性能优势来自于ASIC上执行固定的算法,但因此牺牲了灵活性。
有没有可能用软件来构造光栅化呢?这里说的软件,不是指在CPU运行,而是在GPU的可编程单元里运行。
有些需求使得软件光栅化变得很重要。
第一个需求,小三角形的光栅化性能。
在实际中,硬件光栅化的输出并不是一个一个像素,而是一个一个2x2的像素块。

这称为一个quad,quad之内每个像素都有邻居,于是可以在pixel shader里获得任何变量的ddx和ddy,只要和邻居一减就出来了。

这四个像素如果有在三角形之外的,之后才会被丢弃。

对于大三角形来说,最多也就是边缘的像素存在浪费。
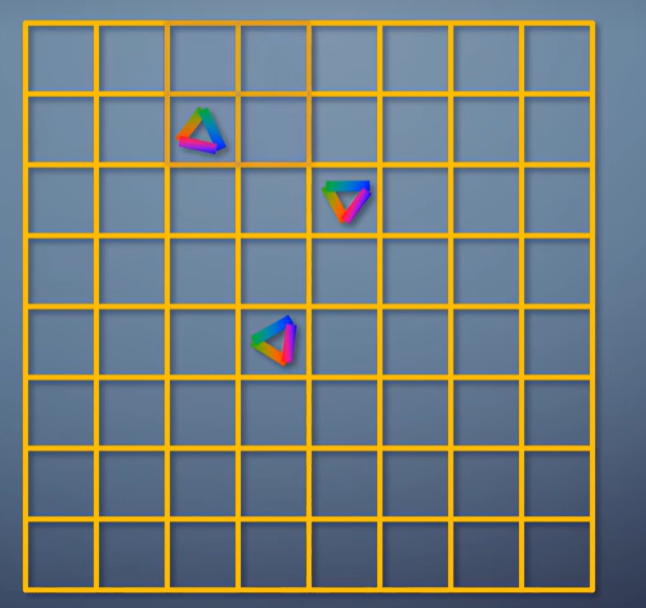
但对于小于一个像素的三角形,这就浪费了3/4。
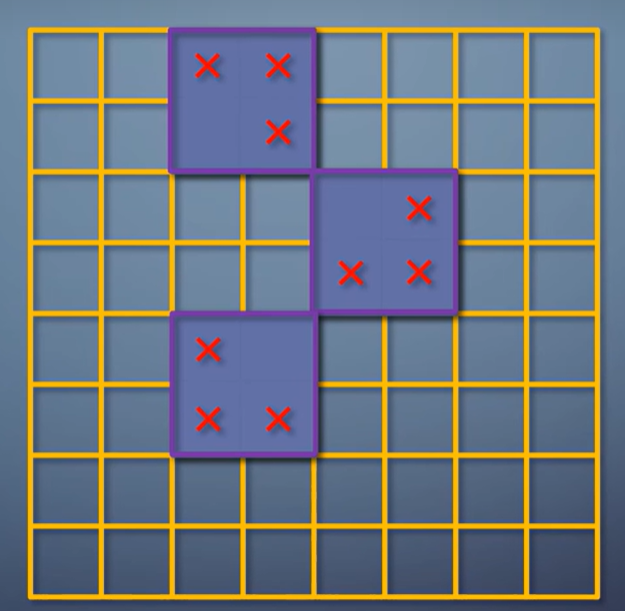
因此,对于大量三角形都小于一个像素的时候,构造一个以像素为单位的软件光栅化器,可以避免浪费,性能反而更高。

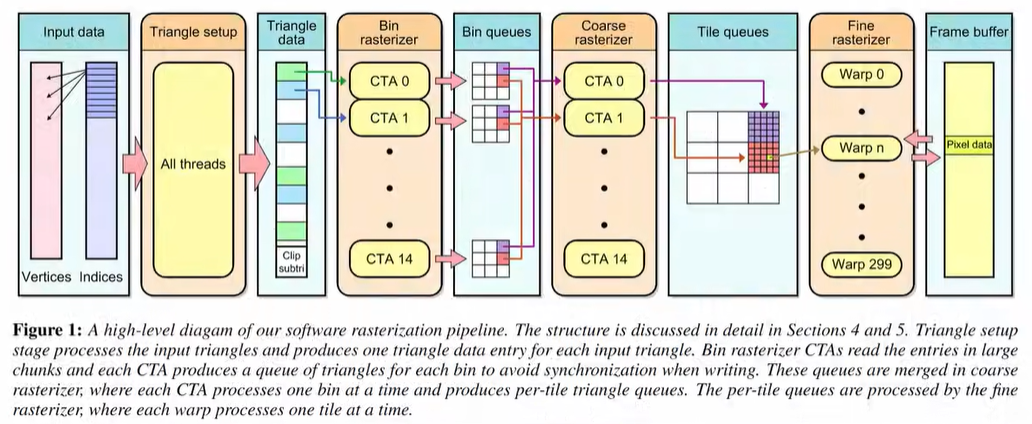
在UE5的Nanite里就是这么做的优化。另一个需求,在无法使用硬件光栅化的时候执行光栅化。
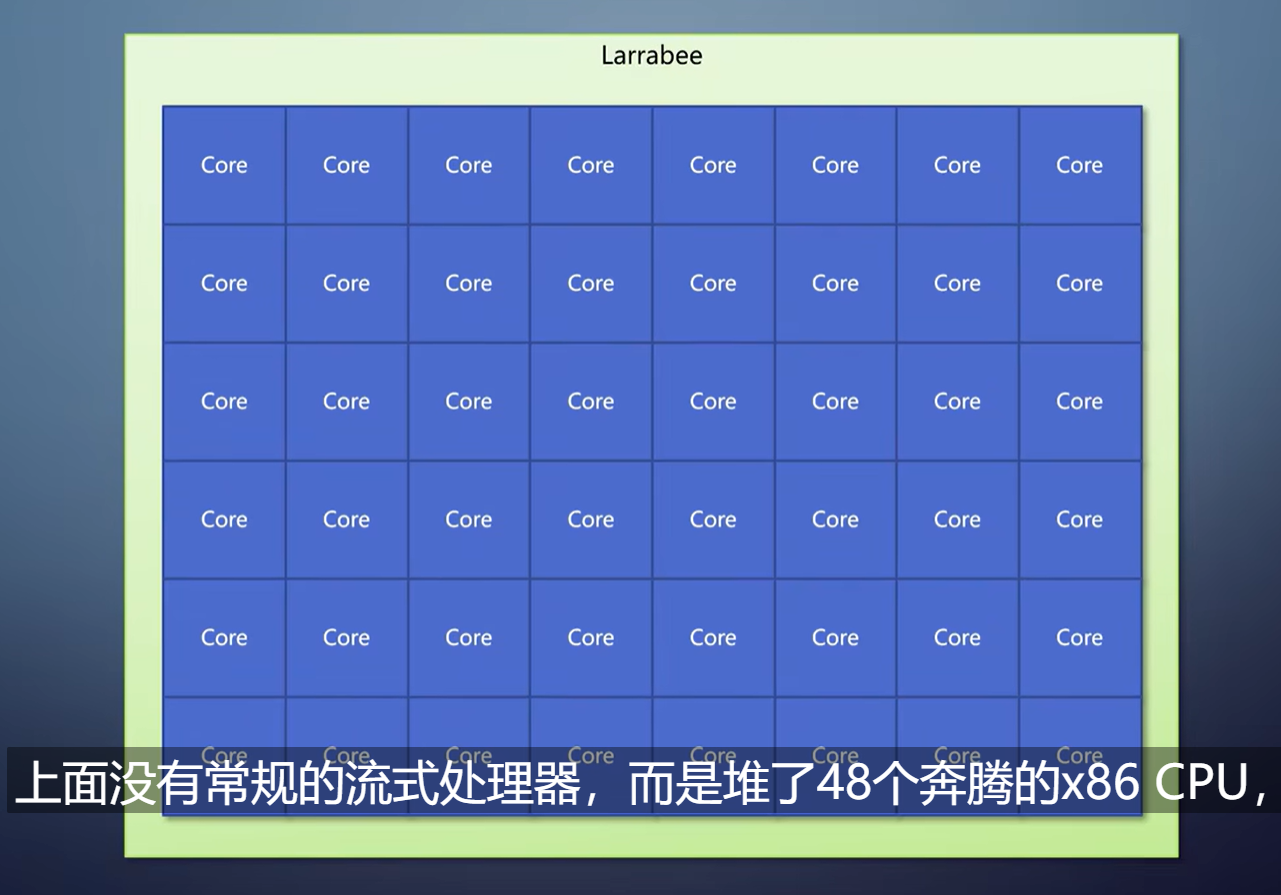
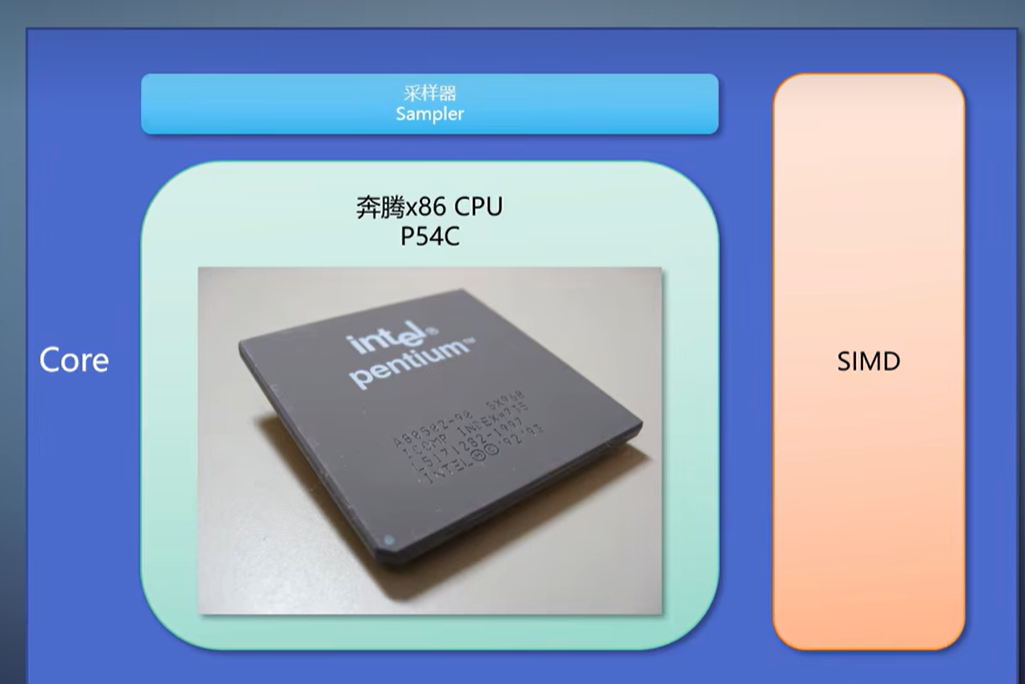
典型的是Intel在08年的Larrabee。上面没有常规的流式处理器,而是堆了48个奔腾的x86 CPU,加上很宽的SIMD指令集。
在那些CPU上执行的是个特制的软件光栅化算法,自适应细分的tile-based光栅化。

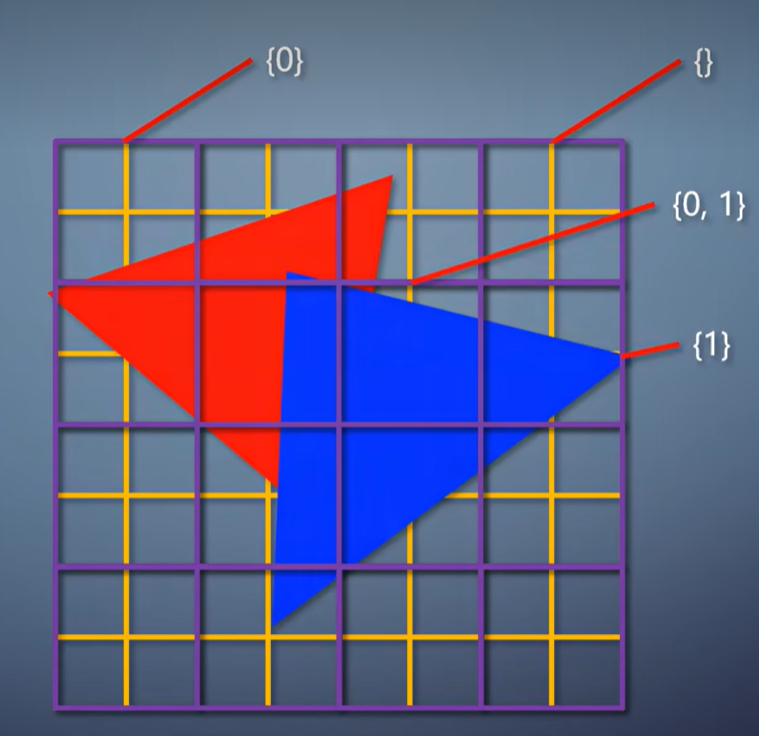
首先,像普通的tile-based一样,, 把整个渲染目标分成一系列tile,但是每个tile较大,至少64x64。

每次都是进行宽度为16的SIMD计算。这部分细节,

有兴趣的朋友可以看Salvia渲染器,里面有这个算法的开源实现。
Salvia渲染器: https://github.com/wuye9036/SalviaRenderer/
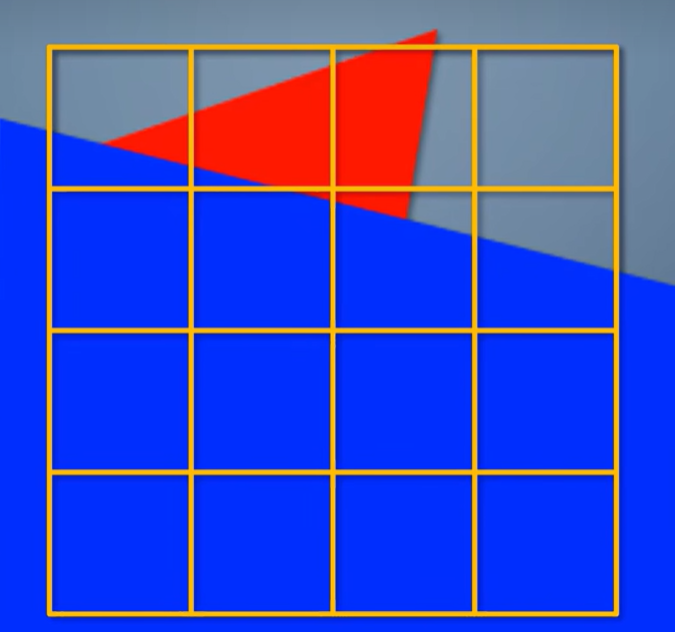
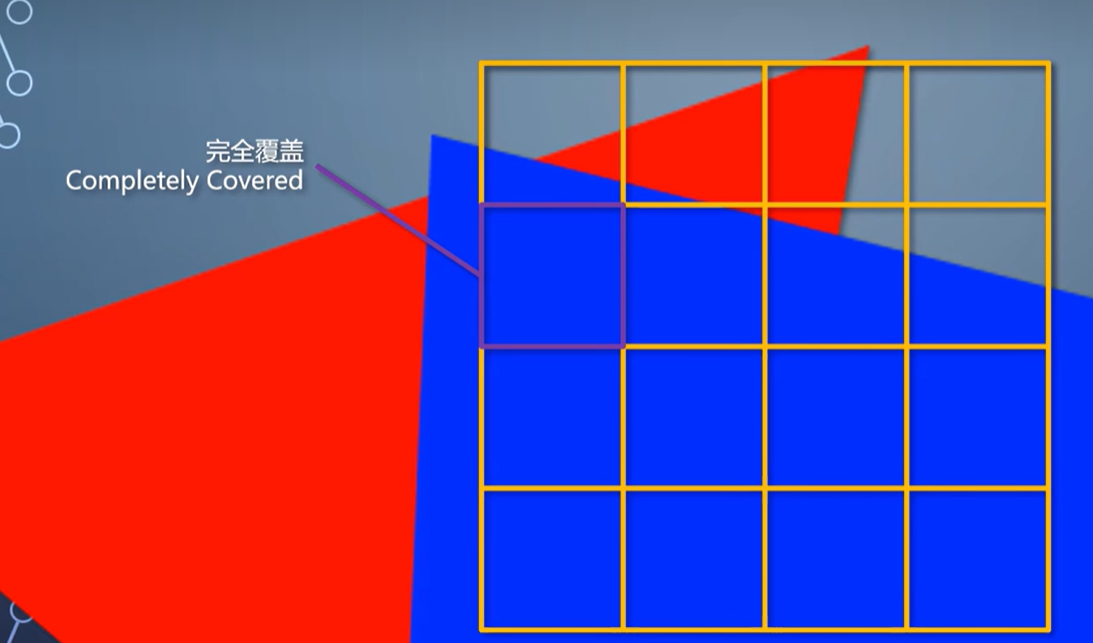
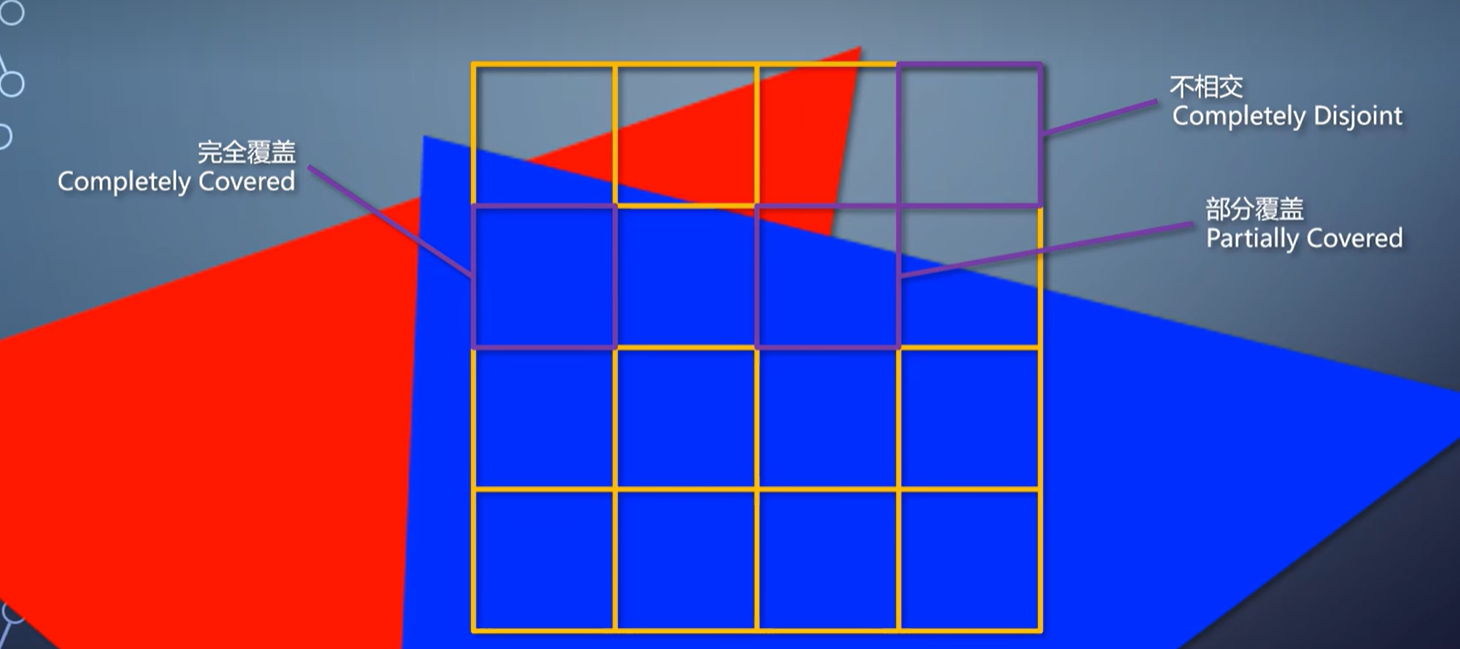
同样也是每个tile包含与它相交的三角形列表。接着把这个tile等分成16个小tile,测试每个小tile和三角形的相交情况。
完全覆盖了,就全部填充。完全不相交,就跳过。
如果部分覆盖,就把小tile再继续分成16个更小的tile,再次测试,以此类推直到像素级别为止。

后来,Larrabee项目停止,砍掉显示输出能力后改造成Xeon Phi运算卡,那个SIMD指令集成了AVX-512。
普遍猜测是功耗控制不住。NVIDIA也有个类似的工作,用CUDA构造软件光栅化。既然光栅化器也可以用软件构造了,那么其他固定流水线模块呢?
挨个过一遍吧。Input assembler负责读取和组装顶点。

在shader能直接访问buffer之后,, 这很容易就能改成让shader读取。
有时候性能还能更高。比如位置和法线用不同的index的情况,

如果必须用硬件input assembler,就得重新组织buffer,有些数据得复制组合多份。

在shader里写代码读取的话,可以支持多个index buffer,总的数据量更小。这在虚幻引擎里面叫做manual vertex fetch模式,用得越来越多。
Stream output原理也一样,无非就是改成写入UAV。Tessellator是在三角形内生成新的顶点, 连起来变成一组三角形。

我发明过一个方法,通过查找表迅速定位顶点之间的连接关系,在compute shader里实现tessellator。只要修改查找表就能更换连接的pattern,不一定要按照硬件写死的。

这个算法被《文明》系列游戏借鉴了,用于地形的细分,通过可定制pattern的思路,做到比硬件tessellator更高的速度。
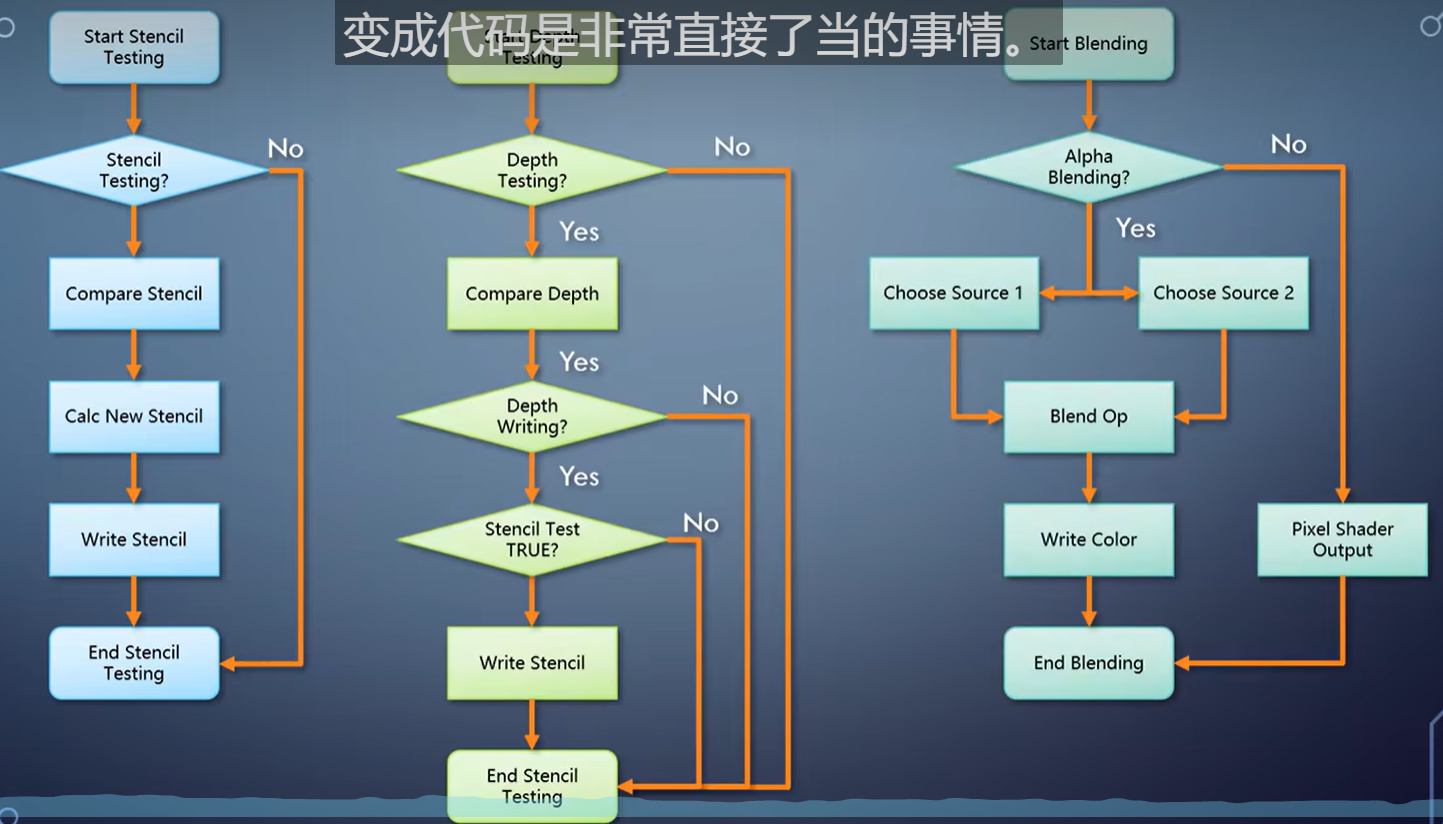
最后的output merger,执行的是这个流程图,变成代码是非常直接了当的事情。
唯一需要注意的是alpha blending如果没有硬件帮助,性能会受一些影响。
如此看来,图形流水线里的几乎每一部份,都可以用可编程单元来构造。唯一必须用硬件才有绝对性能优势的是纹理采样。

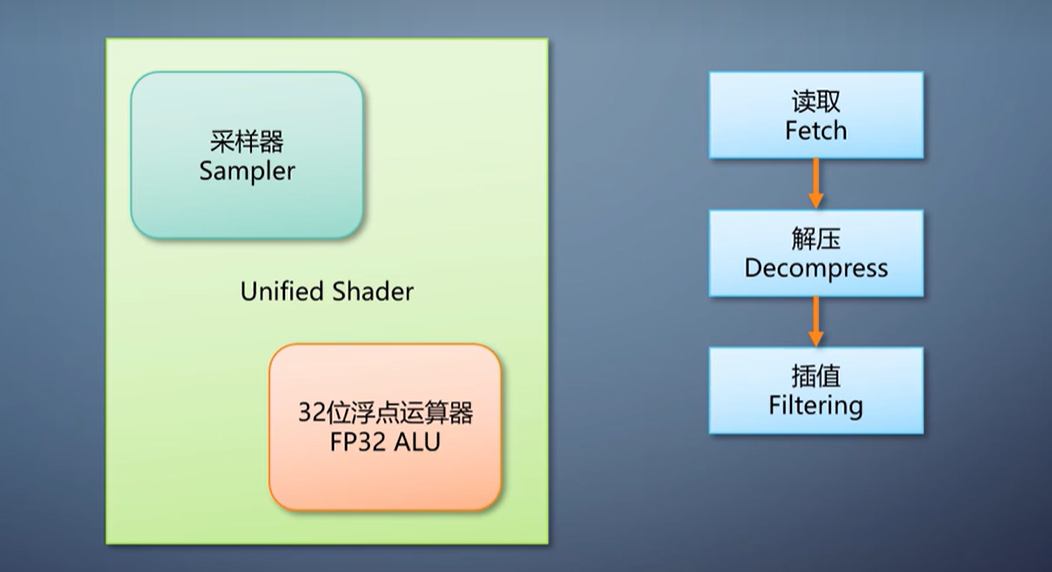
它需要对纹理进行读取、解压、插值,计算量不小,算法很固定,适合硬件连线去做。
按照Larrabee的研究,用软件实现性能会降低12到40倍。
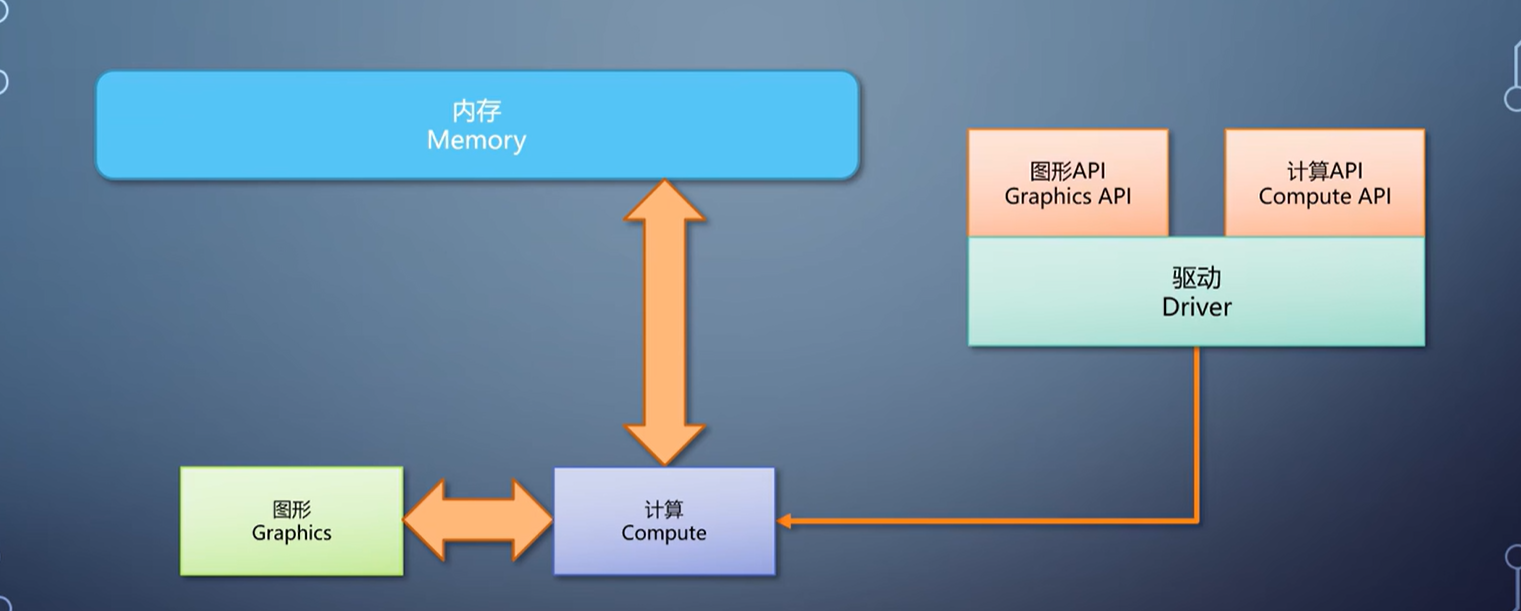
而对于那些所谓“通用GPU,只有计算流水线没有图形流水线的诈骗货,其实也可以用这样的软件方式构造图形流水线,在驱动里无缝衔接,成为真正的GPU。
我们把光栅化的各种方法过了一遍,并提出了如何用可编程的单元构造整条图形流水线。下一期,我们将关注于另一条越来越重要的流水线,光线跟踪。
欢迎继续收看,再见。
来自:龚大的杂货铺的教学视频