诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Get an A in Math: Progressive Rectification Prompting
ArXiv网址:https://arxiv.org/abs/2312.06867
官方实现网站:PRP
官方代码:https://github.com/wzy6642/PRP
本文是2024年AAAI论文,关注MWP任务。作者来自西交和圣母大学。
本文算是CoT的一种多步改进方案。
本文主要考虑到CoT会在推理路径中出错,从而导致最终结果错误,因此提出零样本提示学习方法Progressive Rectification Prompting (PRP),先通过CoT得到一个初始答案,然后以verify-then-rectify的逻辑来识别错误答案、修正推理路径:①verify: 把预测结果填回去预测问题中的masked numerical value(用正则表达式找问题中的数字,挖空一个来预测),如果预测不对就不正确 ②rectify: 用不正确答案生成推理路径(看下图,总之意思就是给(几)个参考错误答案让LLM重算)。(这两步可能会经过多次迭代)

本文认为以前工作的不足之处在于不会检查错误和改正,而这是一项重要的考试技巧。现有的检查错误的方法是重复运行LLM,投票选择最一致的答案,即self-consistency;改正的方法如progressive-hint prompting1在问题后面添加(Hint: The answer is near [H]);CoT方法对中间过程出错很敏感。
考试技巧:
第一步:substitute verification (比repeatedly checking好)
第二步:发现答案错误后要LLM避免重复出错(the answer is likely not [H])
此外还用“两个认知系统”理论来解释PRP。顶会论文是真能编啊。
(论文和代码里的模版有轻微区别,但是意思差不多其实)
1. 模版
初始模版:Q: [Q]. A: Let’s think step by step
获得答案的模版:[R] Therefore, the answer (expressed in Arabic numerals and without units) is:
得到第一个答案: a 0 ( g e n ) a_0^{(gen)} a0(gen)
verification的问题:[Q] Suppose the answer is [A]. What is X? (If X is irrelevant to the calculation process please answer Unknown)
然后再对这个问题进行推理,得到X的预测结果。
condition mask method
如果预测错误,就认为[A]错误,rectification阶段在原问题后加:“(The answer is likely not [H])”
就成了:Q: [Q] (The answer is likely not [H]) A: Let’s think step by step
2. 实验
2.1 数据集
AddSub
SingleOp
MultiArith
SingleEq
SVAMP
GSM8K
GSM-IC2-1K
GSM-ICM-1K
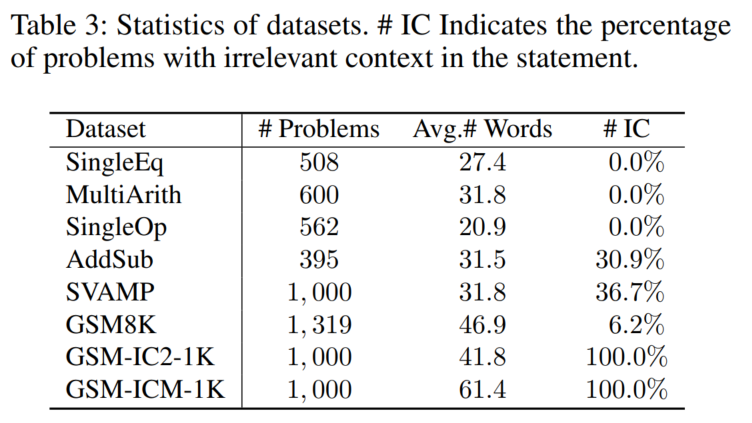
2.2 实验设置
LLM:text-davinci-003
2.3 baseline
direct
zero-shot-CoT
PS
Manual-CoT
Auto-CoT
PHP-CoT
2.4 实验结果与分析
1. 主实验结果
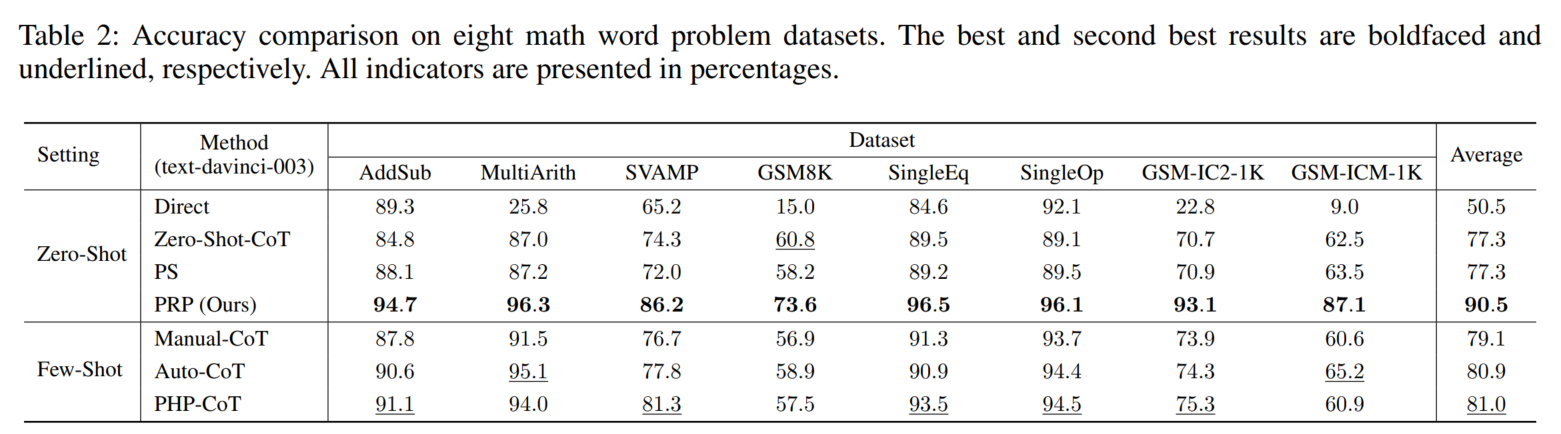
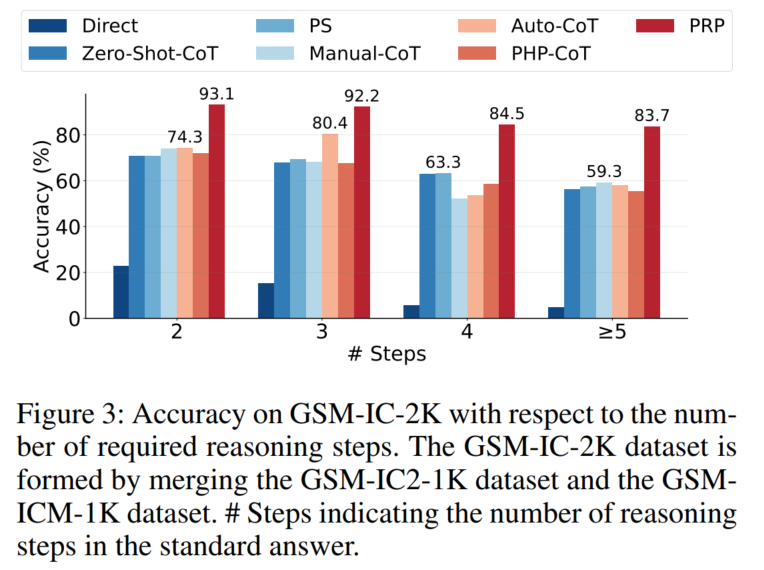
↑题目越复杂,PRP提升效果越多
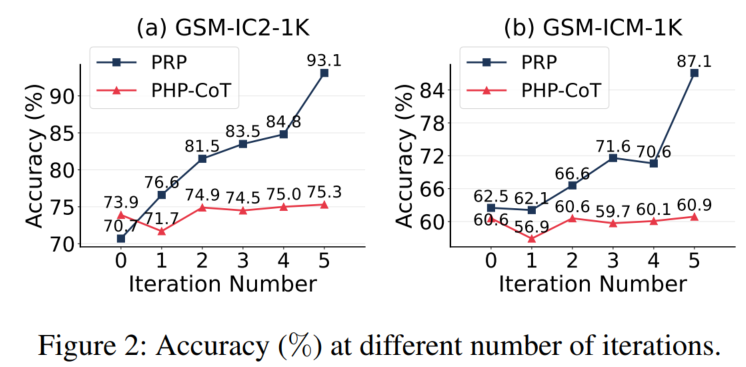
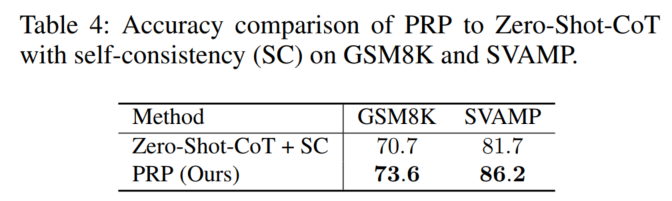
2. 消融实验
↑说明PRP效果更稳定
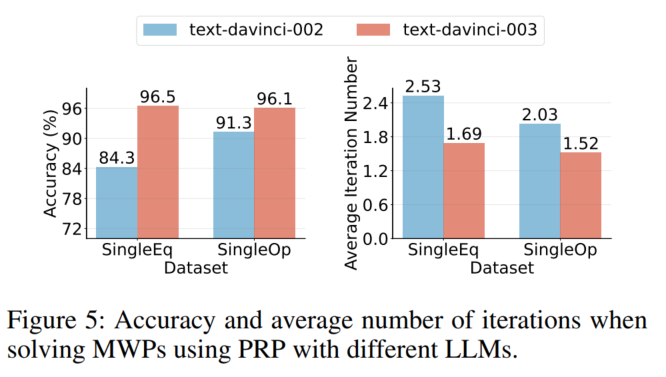
↑说明LLM越好,PRP效果越好
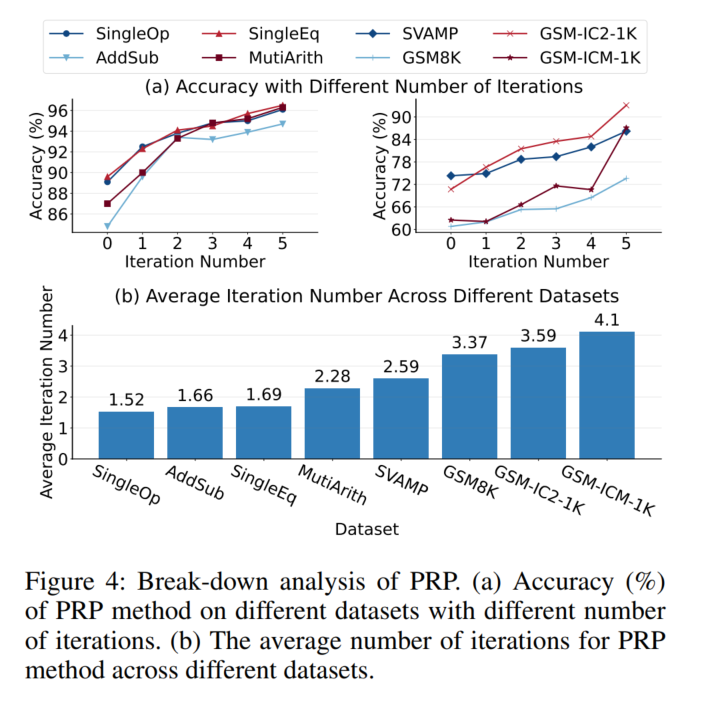
↑最大迭代数提升后,ACC会增加
3. 案例分析

3. 代码复现
我的复现版本(已以GPT-3.5为模型基底,在toy example Alg514的测试集上完成了零样本推理):https://github.com/PolarisRisingWar/Numerical_Reasoning_Collection/blob/master/codes/PRP.py
Progressive-Hint Prompting Improves Reasoning in Large Language Models ↩︎