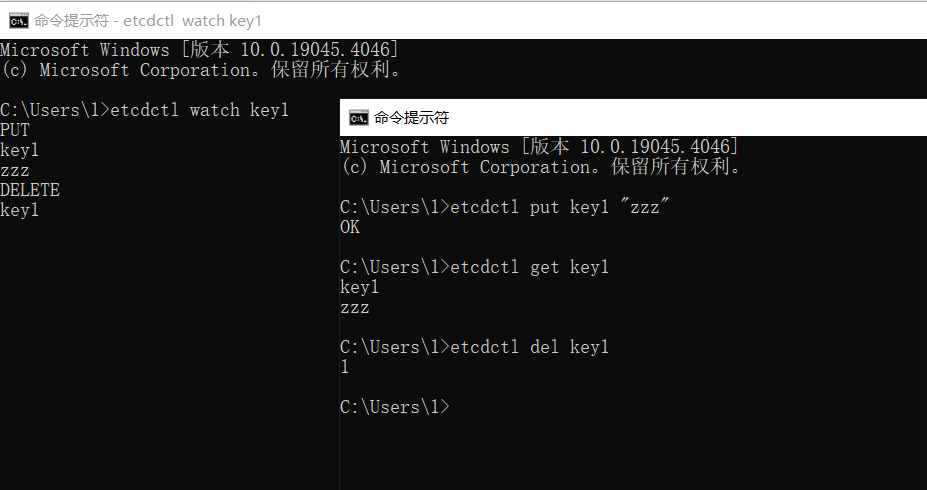
文章目录
- 集合
- Set集合介绍
- HashSet集合的介绍和使用
- LinkedHashSet的介绍以及使用
- 哈希值
- 哈希值的计算方式
- HashSet的存储去重的过程
- Map集合
- Map的介绍
- HashMap的介绍以及使用
- HashMap的两种遍历方式
- 方式1:获取key,然后再根据key获取value
- 方式2:同时获取key和value
- HashMap存储自定义对象
- Map的练习
- LinkedHashMap
- TreeSet
- TreeMap
- HashTable和Vector集合
- HashTable集合
- Vector集合
- Properties集合(属性值)
- List嵌套Map
- Map嵌套map
- 哈希表结构存储过程
- HashMap无参数构造方法的分析
- HashMap有参数的构造方法的分析
- tableSizeFor方法分析
- Node内部类的分析
- 存储元素的put方法源码
- putVal方法源码
- resize方法的扩充计算
- 确定元素存储的索引
- 遇到重复哈希值的对象
集合
Set集合介绍
1.概述:set是一个接口,是Collection下的子接口
2.使用:
a.所用的方法和Collection接口中的方法一模一样
b.set接口中的方法并没有堆Collection中的方法进行任何的扩充
c.set以及下面所有的实现类集合相当是一个傀儡
因为所用的set集合底层都是依靠map集合实现的
HashSet集合的介绍和使用
1.概述:HashSet是Set接口的实现类对象
2.特点
a.元素无序
b.元素不可重复
c.无索引
d.线程不安全
3.数据结构:哈希表
jdk8之前: 哈希表 = 数组+链表
jdk8之后:哈希表 = 数组+链表+红黑树
方法
和Collection一模一样
import java.util.HashSet;
import java.util.Iterator;public class test08 {public static void main(String[] args) {final HashSet<String> set = new HashSet<>();set.add("张三");set.add("李四");set.add("王五");set.add("孙六");System.out.println(set);Iterator<String> iterator = set.iterator();while (iterator.hasNext()){System.out.println(iterator.next());}System.out.println("=======================");for (String s : set) {System.out.println(s);}}
}
运行结果

LinkedHashSet的介绍以及使用
概述 LinkedHashSet extends HashSet
特点:
a.元素有序
b.元素布克重复
c.无索引
d.线程不安全
数据结构
哈希表+双向链表
使用 和HashSet一样
public static void main(String[] args) {final HashSet<String> set = new HashSet<>();set.add("张三");set.add("李四");set.add("王五");set.add("孙六");set.add("张三");System.out.println(set);Iterator<String> iterator = set.iterator();while (iterator.hasNext()){System.out.println(iterator.next());}System.out.println("=======================");for (String s : set) {System.out.println(s);}}
哈希值
概述 计算机计算出来的一个十进制数,我们可以理解为是对象的地址值
获取哈希值:Object类中的
int hashCode()
结论:
如果内容一样,哈希值一定一样
如果内容同不用,哈希值也有可能不一样
public class test10 {public static void main(String[] args) {String s1 = "abc";String s2 = "abc";System.out.println(s1.hashCode());System.out.println(s2.hashCode());System.out.println("==================");String s3 = "通话";String s4 = "重地";System.out.println(s3.hashCode());System.out.println(s4.hashCode());}
}运行结果

哈希值的计算方式
通过进入String的hashCode方法,查看相关的代码
public int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}hash = h;}return h;}
从上述代码中看到31作为常量相乘,31是一个质数,因为31这个数可以尽可能的解决哈希碰撞问题
尽量的不出现,内容不一样,但是哈希值一样的问题
HashSet的存储去重的过程
1.计算元素的哈希值,比较元素哈希值
2.如果哈希值不一样,直接存
3.如果哈希值一样,再比较内容(equals)
4.如果哈希值不一样,内容一样,存
5.如果哈希值一样,内容一样,去重复,后面的会把前面的覆盖掉
Map集合
Map的介绍
概述:双列集合的顶级接口
组成部分
一个元素是有两部分构成
key = value ----- 键值对
HashMap的介绍以及使用
概述:是Map的实现类
特点:
a.元素无序
b.key唯一,value可重复
c.无索引
d.线程不安全
数据结构:哈希表
常用方法
V put(K key, V value) -> 存储元素
V remove(Object key) ->根据key删除对应的键值对
V get(Object key) -> 根据key获取对应的value
boolean containsKey(Object key) ->判断Map中是否包含指定的key
Collection values() -> 将Map中所有的value存储到Collection集合中
Set keySet() -> 将Map中所有的key获取出来存到Set集合中
Set<Map.Entry<K,V>> entrySet() -> 获取Map中所有的键值对对象,放到set集合中
public class test {public static void main(String[] args) {final HashMap<Integer, String> set = new HashMap<>();//存储元素set.put(0001,"李云龙");set.put(0002,"丁伟");set.put(0003,"孔捷");System.out.println(set);//根据key删除对应的键值对set.remove(0001);System.out.println(set);//根据key获取对应的ValueSystem.out.println(set.get(2));//判断map中是否含有指定的keySystem.out.println(set.containsKey(1));}
}
注意 如果key重复了,后米的会把前面的覆盖掉,去重复过程和set一模一样
HashMap的两种遍历方式
方式1:获取key,然后再根据key获取value
Set keySet() ----- 将Map中所有的key获取出来存到Set集合中
public class test02 {public static void main(String[] args) {final HashMap<Integer, Object> hashMap = new HashMap<>();hashMap.put(1,"李云龙");hashMap.put(2,"丁伟");hashMap.put(3,"孔捷");/** 先调用keySet方法,获取map中所有的key,存储到Set集合中* 遍历Set集合,调用map中的get方法,根据key获取value* */Set<Integer> set = hashMap.keySet();for (Integer key : set) {String value = (String) hashMap.get(key);System.out.println(key + "....." + value);}}
}
方式2:同时获取key和value
Set<Map.Entry<K,V>> entrySet() — 获取Map中所有的键值对对象,放到set集合中
1.我们只需要获取到每个键值对的条目就行了
2.拿到条目,就能拿到条目上的key和value
3.记录key和value的条目, Map中的静态接口 — Map.Entry
Map.Entry中有两个方法
getKey() 获取key
getValue() 获取value
Set<Map.Entry<Integer, Object>> set1 = hashMap.entrySet();for (Map.Entry<Integer, Object> integerObjectEntry : set1) {Integer key = integerObjectEntry.getKey();String value = (String) integerObjectEntry.getValue();System.out.println(key + "...." + value);}
HashMap存储自定义对象
1.key存储自定义对象,value类型随意
2.需要key重写hashCode和equals方法
相关代码
public class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return age == person.age && Objects.equals(name, person.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class test03 {public static void main(String[] args) {HashMap<Person, String> hashMap = new HashMap<>();hashMap.put(new Person("李云龙",18),"独立团");hashMap.put(new Person("孔捷",26),"新一团");hashMap.put(new Person("丁伟",26),"新二团");System.out.println(hashMap);}
}Map的练习
需求:用Map集合统计字符串中每一个字符出现的次数
步骤
1.创建Scanner对象,调用next方法录入字符串
2.创建HashMap集合,key为String用于存储字符串,value作为Integer用于存储字符对应的个数
3.遍历字符串,判断,集合中有没有该字符
4.如果没有,将该字符以及对用的1存到Map集合中
5.如果有,根据该字符获取对用的value,对value进行加一
6.将该字符以及对用的value值存进去
7.输出
public class test03 {public static void main(String[] args) {System.out.println("请输入字符串");final Scanner scanner = new Scanner(System.in);String data = scanner.next();final HashMap<String, Integer> hashMap = new HashMap<>();char[] chars = data.toCharArray();for (char aChar : chars) {String achar = aChar + "";if (!hashMap.containsKey(achar)){hashMap.put(achar,1);}else {int value = hashMap.get(achar);value ++;hashMap.put(achar,value);}}System.out.println(hashMap);}
}
LinkedHashMap
概述 LinkedHashMap extends HashMap
特点:
a.有序
b.无索引
c.key唯一,value可重复
d.线程不安全
数据结构
哈希表+双向链表
用法:和HashMap一样
public class test04 {public static void main(String[] args) {final LinkedHashMap<String, String> hashMap = new LinkedHashMap<>();hashMap.put("001","李云龙");hashMap.put("002","丁伟");hashMap.put("003","孔捷");System.out.println(hashMap);//使用keyset方式遍历final Set<String> set = hashMap.keySet();for (String s : set) {final String s1 = hashMap.get(s);System.out.println(s+"...."+s1);}//使用entrySet方式遍历final Set<Map.Entry<String, String>> entries = hashMap.entrySet();for (Map.Entry<String, String> entry : entries) {System.out.println(entry.getKey()+ "...." +entry.getValue());}}
}
TreeSet
1.概述:ThreeSet是Set接口的实现类
2.特点:
a.可以对元素进行排序
b.元素唯一
c.无索引
d.线程不安全
3.数据结构
红黑树
4.方法 和HashSet一样
构造
TreeSet() — 对元素进行自然排序 ---- ASCII
TreeSet(Comparator<? suoer E> comparator) ----------- 按照指定规则进行排序
相关练习代码
public class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return age == person.age && Objects.equals(name, person.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}
}
import java.util.Comparator;
import java.util.TreeSet;public class test05 {public static void main(String[] args) {final TreeSet<String> treeSet = new TreeSet<>();treeSet.add("d");treeSet.add("a");treeSet.add("v");treeSet.add("c");treeSet.add("e");System.out.println(treeSet);System.out.println("=================");final TreeSet<Person> people = new TreeSet<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge() - o2.getAge();}});people.add(new Person("李云龙",30));people.add(new Person("丁伟",21));people.add(new Person("孔捷",42));System.out.println(people);}
}
TreeMap
1.概述:TreeMap是Map接口的实现类
2.特点:
a.可以对key进行排序
b.无索引
c.线程不安全
3.数据结构:
红黑树
4.方法:
和HashMao一样
1.构造:
TreeMap() -> 按照自然顺序对key进行排序
TreeMap(Comparator<? super K> comparator)-> 按照指定规则对key进行排序
public class test06 {public static void main(String[] args) {final TreeMap<String, String> treeMap = new TreeMap<>();treeMap.put("a","宝儿姐");treeMap.put("b","张之维");treeMap.put("c","王也");treeMap.put("e","张楚岚");System.out.println(treeMap);System.out.println("====================");final TreeMap<Person, String> treeMap1 = new TreeMap<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge() - o2.getAge();}});treeMap1.put(new Person("李云龙",32),"独立团");treeMap1.put(new Person("丁伟",42),"新一团");treeMap1.put(new Person("孔捷",33),"新二团");System.out.println(treeMap1);}
}
HashTable和Vector集合
HashTable集合
1.概述:是Map的实现类
2.特点:
a.无序
b.key唯一,value可重复
c.无索引
d.线程安全
3.数据结构
哈希表
4.用法
和HashMap一样
public class test07 {public static void main(String[] args) {final Hashtable<String, String> hashtable = new Hashtable<>();hashtable.put("老天师","张之维");hashtable.put("不要碧莲","张楚岚");hashtable.put("土豪道士","王也");System.out.println(hashtable);}
}
Vector集合
1.概述 是Collection的实现类
2.特点
a.有序
b.有索引
c.元素可重复
d.线程安全
3.数据结构
数组
4.用法 和ArrayList一样
5.底层分析:
a.Vector ---- new底层会直接产生一个长度为10 的空数组
b.数组扩容 Arrays.copyof 扩容两倍
public class test08 {public static void main(String[] args) {final Vector<String> vector = new Vector<>();vector.add("李云龙");vector.add("丁伟");vector.add("孔捷");System.out.println("vector = " + vector);}
}
HashMap和Hashtable的区别
1.相同点
key唯一,无索引,元素无序,底层都是哈希表
2.不同点
HashMap线程不安全,允许有null键null值
Hashtable线程安全,不允许有null键null值
Properties集合(属性值)
1.概述:Properties是Hashtable的子类
2.特点
a.无序
b.key唯一,value可重复
c.无索引
d.线程安全
e.Properties的key的value类型默认是String
f.不允许有null键null值
3.数据结构
哈希表
4.用法:
可以使用HashMap的方法
5.特有方法
Object setProperty(String key, String value) -> 存储键值对
String getProperty(String key) -> 根据key获取value
Set stringPropertyNames() -> 获取所有的key,存放到Set集合中
void load(InputStream inStream) -> 将流中的数据信息加载到Properties集合中
public class test01 {public static void main(String[] args) {final Properties properties = new Properties();//将键值对存入集合properties.setProperty("username","root");properties.setProperty("password","1234");System.out.println("properties = " + properties);//根据key获取相应的valueSystem.out.println(properties.getProperty("username"));//获取所有的key,存放到set集合中和keyset方法效果一致final Set<String> set = properties.stringPropertyNames();for (String s : set) {System.out.println(properties.getProperty(s)+"...."+s);}}
}
List嵌套Map
需求:
一班有四名同学。学号和姓名分别为:
1=张楚岚,2=冯宝宝,3=王也,4=诸葛青
二班有三名同学,分别为:
1=张之维,2=张灵玉 3=夏禾
将同学的信息以键值对形式存入到2个Map集合中,再将2个map集合存储到list集合中
public class test02 {public static void main(String[] args) {final HashMap<Integer, String> hashMap = new HashMap<>();final HashMap<Integer, String> hashMap1 = new HashMap<>();hashMap.put(1,"张楚岚");hashMap.put(2,"冯宝宝");hashMap.put(3,"王也");hashMap.put(4,"诸葛青");hashMap1.put(1,"张之维");hashMap1.put(2,"张灵玉");hashMap1.put(3,"夏禾");final ArrayList<HashMap<Integer,String>> list = new ArrayList<>();list.add(hashMap);list.add(hashMap1);//遍历列表for (HashMap<Integer, String> integerStringHashMap : list) {final Set<Map.Entry<Integer, String>> entries = integerStringHashMap.entrySet();for (Map.Entry<Integer, String> entry : entries) {System.out.println(entry.getKey()+"..."+entry.getValue());}}}
}
Map嵌套map
javaSE集合存储的是学号 键,值学生姓名
1 张三
2 李四
javaEE 结合存储的是学号 键,值学生姓名
1 王五
2 赵六
public class test03 {public static void main(String[] args) {final HashMap<Integer, String> hashMap = new HashMap<>();final HashMap<Integer, String> hashMap1 = new HashMap<>();hashMap.put(1,"张三");hashMap.put(2,"李四");hashMap1.put(1,"王五");hashMap1.put(2,"田六");final HashMap<HashMap<Integer,String>, String> map = new HashMap<>();map.put(hashMap,"javaSE");map.put(hashMap1,"javaEE");//遍历大mapfinal Set<Map.Entry<HashMap<Integer, String>, String>> entries = map.entrySet();for (Map.Entry<HashMap<Integer, String>, String> entry : entries) {System.out.println(entry.getKey()+"...."+entry.getValue());}}
}
哈希表结构存储过程
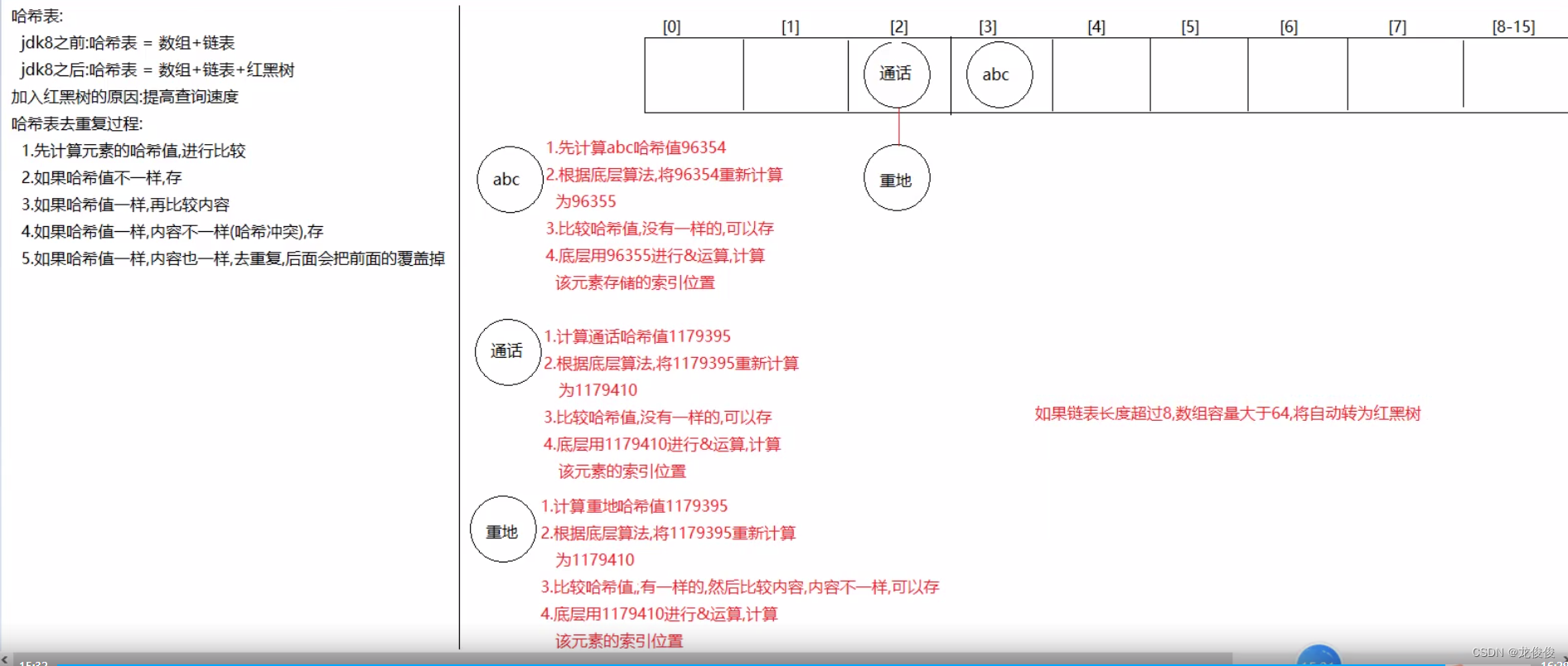
要知道的点
a.在不指定长度时,哈希表中的数组默认长度为16,HashMap创建出来,一开始没有床架长度为16的数组
b.在第一次put的时候,底层会创建出来长度为16的数组
c.哈希表中有一个数据加【加载因子】---- 默认为0.75(加载因子)---- 代表当元素存储到百分之七十五的时候要扩容了—0–2倍
d.如果元素的哈希值出现相同,内容不一样时,就会在同一个索引上以链表的形式存储,当链表长度达到8,并且当前数组长度>64时,链表就会改成使用红黑树存储
e.加入红黑树目的:查询快
面试时可能会问到的变量
default_initial_capacity:HashMap默认容量 16
defaul_load_factor:HashMap默认加载因子 0.75f
threshold 扩充的临界值 等于 容量8*0.75 =12 第一次扩容
threeify_threshold: 链表长度默认值,转为红黑树:8
min_treeify_capacity: 链表被树化时最小的数组容量 64
HashMap无参数构造方法的分析
HashMap中的静态成员变量
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
解析:使用无参数构造方法创建HashMap对象,将加载因子设置成默认的加载因子,loadfactor=0.75
HashMap有参数的构造方法的分析
解析 如果带有参数构造方法,传递哈希表的初始化容量和加载因子
HashMap(int initialCapacity, float loadFactor) ->创建Map集合的时候指定底层数组长度以及加载因子public HashMap(int initialCapacity, float loadFactor) {
//如果初始化容量小于0,直接抛出异常if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);
//如果初始化容量大于最大容量,初始化容量直接等于最大容量if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;
//如果loadFactor(加载因子)小于等于0,直接抛出异常if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);//10
tableSizeFor方法分析
tableSizeFor(initCapacity)方法计算哈希表的初始化容量
注意 哈希表是进行计算得出的容量,而初始化容量不直接等于我们传递的参数。
8 4 2 1规则—无论指定了多少容量,最终经过tableSizeFor这个方法计算以后,都会遵守8421规则去初始化列表容量
解析:该方法对我们传递的初始化容量进行位移运算,位移的结果是8421码
例如传递2,结果还是2,传递的是4,结果还是4
传递3,结果传递4,传递5,结果是8,传递20,结果是32
Node内部类的分析
哈希表是采用数组加链表的实现方法
HashMap中的内部类Node非常重要,证明HashSet是一个单向链表
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;
}
解析:内部类Node中具有四个成员变量
hash 对象的哈希值
key 作为键的对象
value 作为值的对象
next,下一个节点对象
存储元素的put方法源码
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}
解析:put方法中调用putVal方法,putVal方法中调用hash方法
hash(key)方法;传递要存储的元素,获取对象的哈希值
putVal方法:传递对象哈希值和要存储的对象key
putVal方法源码
Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;
解析,方法中进行Node对象数组的判断,如果数组是null或者长度等于0,那么就会调用resize()方法进行数组的扩充
resize方法的扩充计算
if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold
}
解析:计算结果,新的数组容量 = 原始数组容量 <<1,也就是乘以2
确定元素存储的索引
if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);
解析:i = (数组长度-1) & 对象的哈希值,会得到一个索引,然后在此索引下tab[i],创建链表对象。不同的哈希值的对象,也是有可能存储在同一个数组索引下
遇到重复哈希值的对象
Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;
解析 如果对象的哈希值相同,对象的equals方法返回true,判断为一个对象,进行覆盖操作
else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}
解析:如果对象哈希值相同吗,但是对象的equals方法返回false,将对此链表进行遍历
当链表没有下一个节点的时候,创建下一个节点存储对象