目录
一、存储卷的分类
二、empty存储卷以及特点
三、hostpath存储卷以及特点
四、nfs存储卷以及特点
五、pvc存储卷
查看pv的定义
查看pvc的定义
实操:静态创建pv的方式 实现pvc存储卷
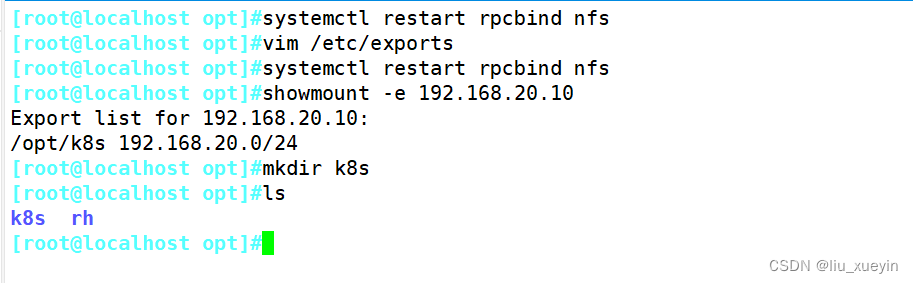
步骤一:先完成nfs的目录共享,需要准备不同的目录
步骤二:编写配置文件,完成静态pv的创建,设置访问模式和资源大小等
步骤三:编写pvc创建配置文件,完成创建,查看是否与pv绑定
步骤四:基于pvc存储卷创建pod
实操:基于nfs存储卷插件动态创建pv,实现pvc存储卷
步骤一:完成nfs共享准备
步骤二:创建 Service Account,用来管理 NFS Provisioner 在 k8s 集群中运行的权限,设置 nfs-client 对 PV,PVC,StorageClass 等的规则
步骤三:使用 Deployment 来创建 NFS Provisioner
编辑 步骤四:创建 StorageClass,负责建立 PVC 并调用 NFS provisioner 进行预定的工作,并让 PV 与 PVC 建立关联
步骤五:创建pvc存储卷以及创建pod测试
六、总结
一、存储卷的分类
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动(容器一旦被删除再次重建,那么数据都会丢失)。其次,在Pod中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的Volume抽象就很好的解决了这些问题。Pod中的容器通过Pause容器共享Volume。
查看支持的存储卷类型
kubectl explain pod.spec.volumes常用的有:
emptyDir、hostPath、nfs、persistentVolumeClaim
二、empty存储卷以及特点
当Pod被分配给节点时,首先创建emptyDir卷,并且只要该Pod在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。Pod 中的容器可以读取和写入emptyDir卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,emptyDir中的数据将被永久删除。
piVersion: v1
kind: Pod
metadata:name: pod01namespace: defaultlabels:app: myapp
spec:containers:- name: myappimage: soscscs/myapp:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80#定义容器挂载内容volumeMounts:#使用的存储卷名称,如果跟下面volume字段name值相同,则表示使用volume的这个存储卷- name: html#挂载至容器中哪个目录mountPath: /usr/share/nginx/html/- name: busyboximage: busybox:1.28imagePullPolicy: IfNotPresentvolumeMounts:- name: html#在容器内定义挂载存储名称和挂载路径mountPath: /data/command: ['/bin/sh','-c','while true;do echo $(date) >> /data/index.html;sleep 2;done']#定义存储卷volumes:#定义存储卷名称 - name: html#定义存储卷类型emptyDir: {}

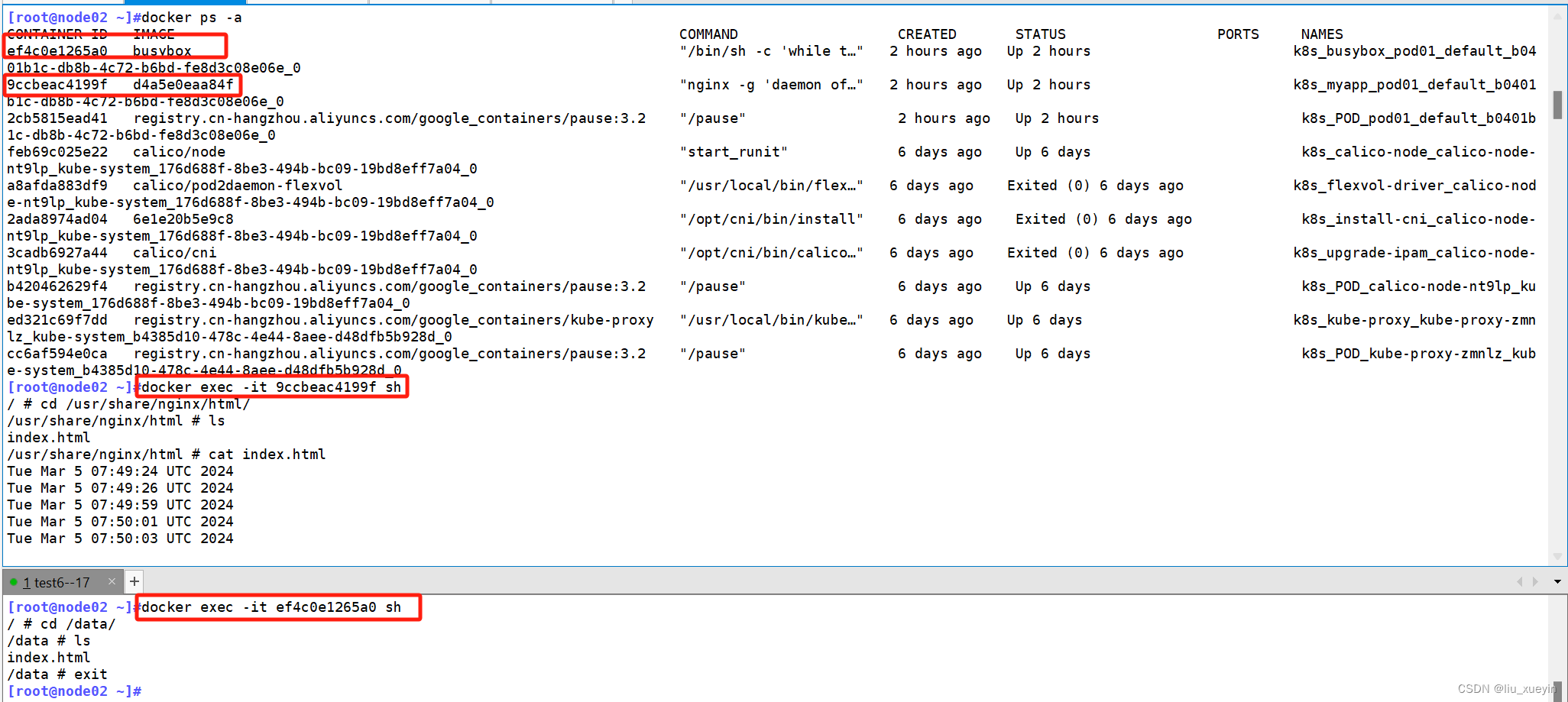
在上面定义了2个容器,其中一个容器是输入日期到index.html中,然后另一个容器是否可以获取日期文件index.html。以验证两个容器之间挂载的emptyDir实现共享。
三、hostpath存储卷以及特点
apiVersion: v1
kind: Pod
metadata:name: pod01namespace: default
spec:containers:- name: myappimage: soscscs/myapp:v1#定义容器挂载内容volumeMounts:#使用的存储卷名称,如果跟下面volume字段name值相同,则表示使用volume的这个存储卷- name: html#挂载至容器中哪个目录mountPath: /usr/share/nginx/html#读写挂载方式,默认为读写模式falsereadOnly: false#volumes字段定义了paues容器关联的宿主机或分布式文件系统存储卷volumes:#存储卷名称- name: html#路径,为宿主机存储路径hostPath:#在宿主机上目录的路径path: /data/pod/volume1#定义类型,这表示如果宿主机没有此目录则会自动创建type: DirectoryOrCreate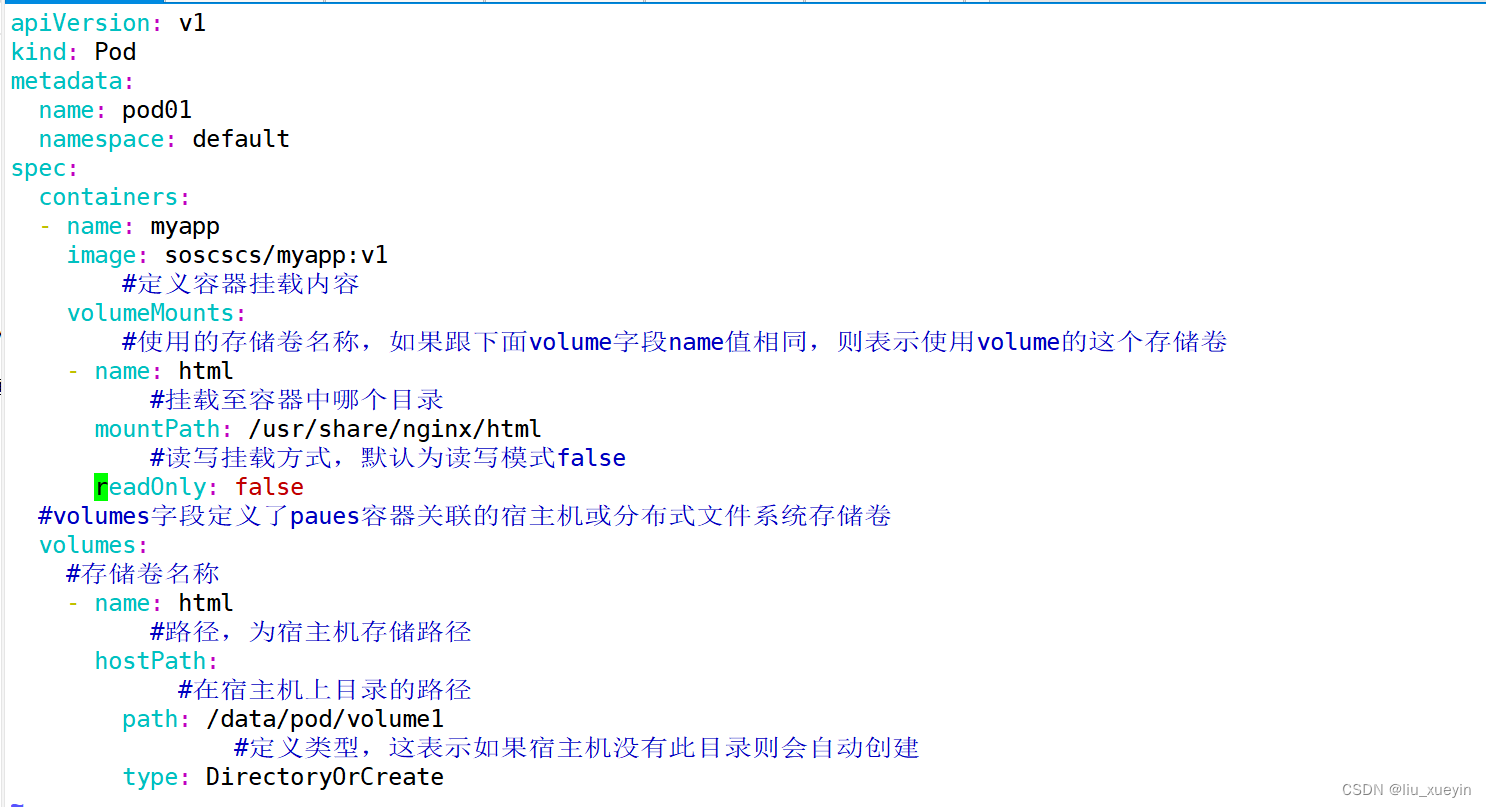
 删除pod,再重建,验证是否依旧可以访问原来的内容
删除pod,再重建,验证是否依旧可以访问原来的内容
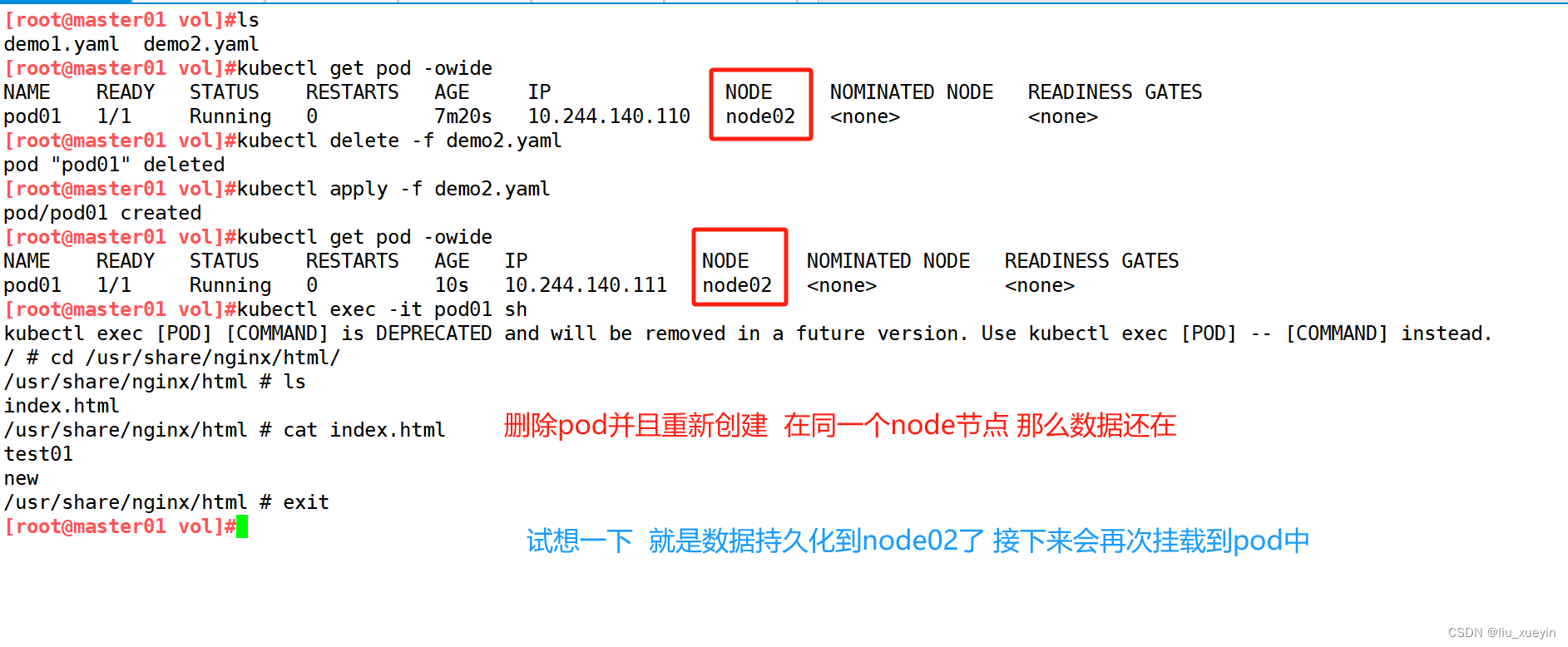
删除pod,再重建,指定到node01节点,验证是否依旧可以访问原来的内容


四、nfs存储卷以及特点
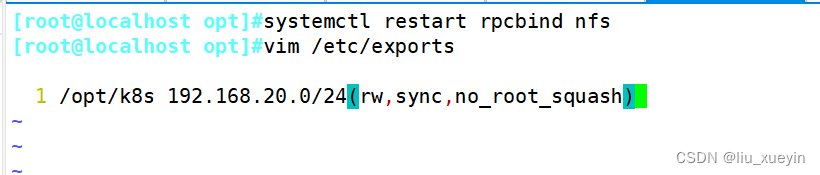
准备好nfs共享
apiVersion: v1
kind: Pod
metadata:name: pod-vol-nfsnamespace: default
spec:containers:- name: myappimage: soscscs/myapp:v1volumeMounts:- name: htmlmountPath: /usr/share/nginx/htmlvolumes:- name: htmlnfs: #存储卷类型为nfspath: /opt/k8s #共享的目录为/opt/k8sserver: 192.168.20.10 #可以为主机名(但是做了hosts映射),或者ip也可以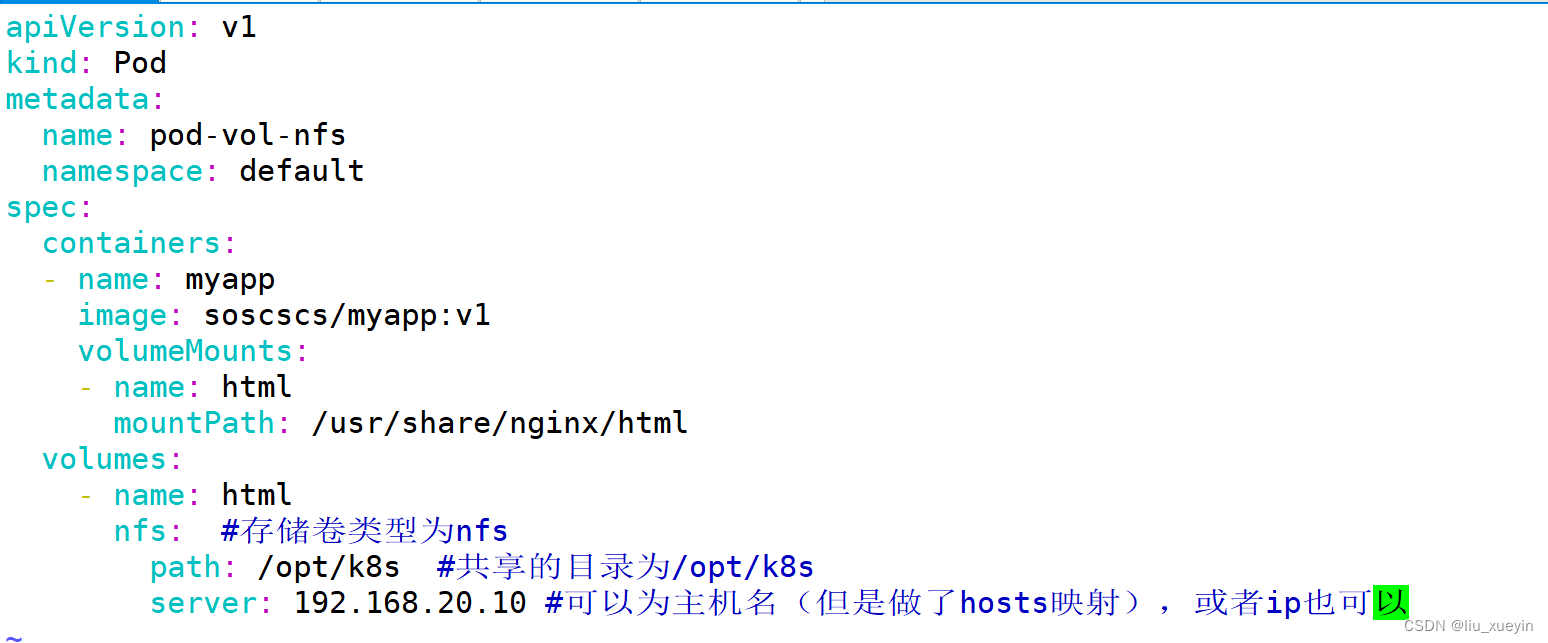

删除nfs相关pod,再重新创建,可以得到数据的持久化存储
可以实现跨node节点的完成数据持久化
五、pvc存储卷
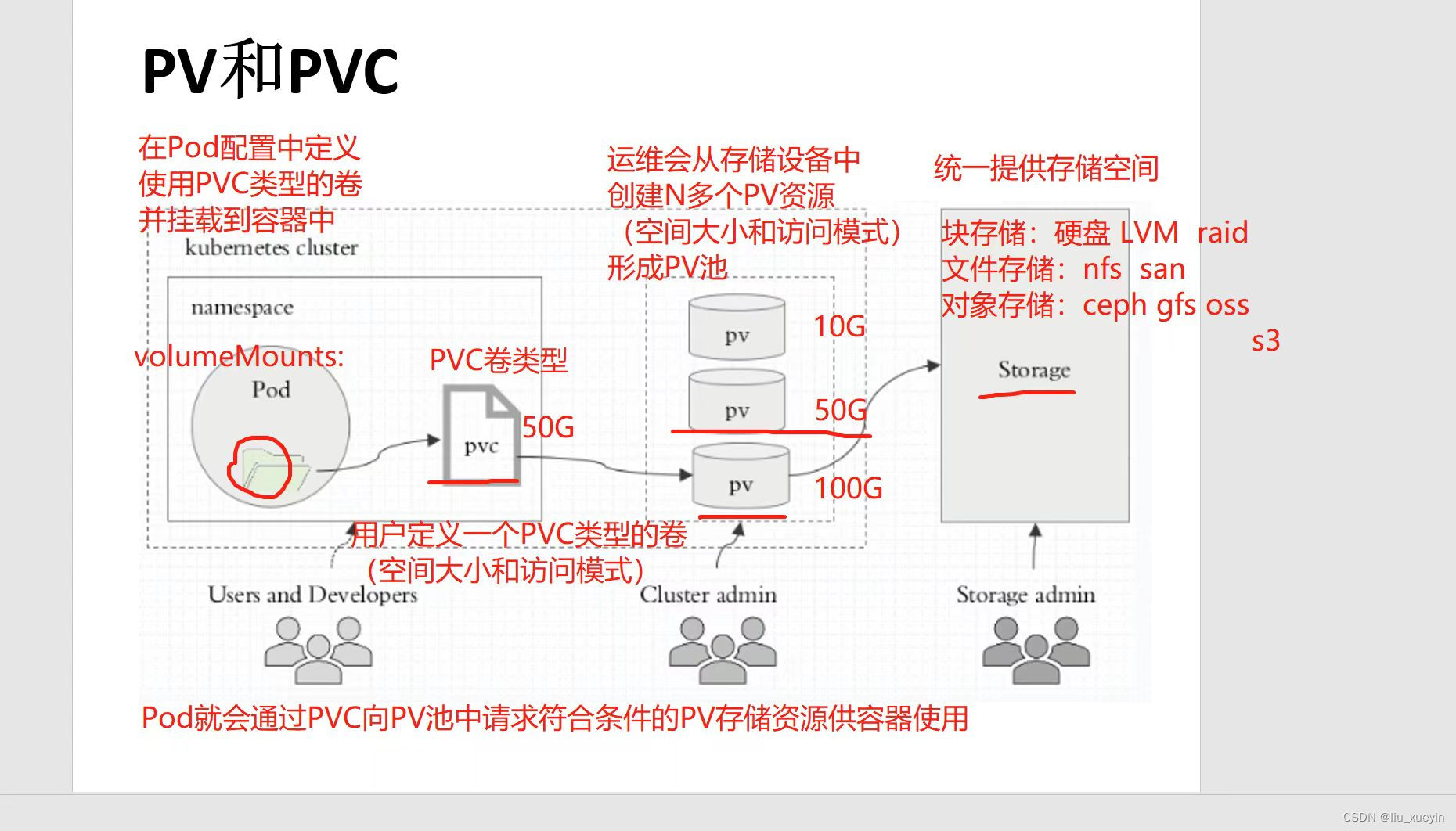
PV 全称叫做 Persistent Volume,持久化存储卷。它是用来描述或者说用来定义一个存储卷的,这个通常都是由运维工程师来定义。
PVC 的全称是 Persistent Volume Claim,是持久化存储的请求。它是用来描述希望使用什么样的或者说是满足什么条件的 PV 存储。
PVC 的使用逻辑:在 Pod 中定义一个存储卷(该存储卷类型为 PVC),定义的时候直接指定大小,PVC 必须与对应的 PV 建立关系,PVC 会根据配置的定义去 PV 申请,而 PV 是由存储空间创建出来的。PV 和 PVC 是 Kubernetes 抽象出来的一种存储资源。
上面介绍的PV和PVC模式是需要运维人员先创建好PV,然后开发人员定义好PVC进行一对一的Bond,但是如果PVC请求成千上万,那么就需要创建成千上万的PV,对于运维人员来说维护成本很高,Kubernetes提供一种自动创建PV的机制,叫StorageClass,它的作用就是创建PV的模板。
创建 StorageClass 需要定义 PV 的属性,比如存储类型、大小等;另外创建这种 PV 需要用到的存储插件,比如 Ceph 等。 有了这两部分信息,
Kubernetes 就能够根据用户提交的 PVC,找到对应的 StorageClass,然后 Kubernetes 就会调用 StorageClass 声明的存储插件,自动创建需要的 PV 并进行绑定。
PV是集群中的资源。 PVC是对这些资源的请求,也是对资源的索引检查。
PV和PVC之间的相互作用遵循这个生命周期:
Provisioning(配置)---> Binding(绑定)---> Using(使用)---> Releasing(释放) ---> Recycling(回收)
●Provisioning,即 PV 的创建,可以直接创建 PV(静态方式),也可以使用 StorageClass 动态创建
●Binding,将 PV 分配给 PVC
●Using,Pod 通过 PVC 使用该 Volume,并可以通过准入控制StorageProtection(1.9及以前版本为PVCProtection) 阻止删除正在使用的 PVC
●Releasing,Pod 释放 Volume 并删除 PVC
●Reclaiming,回收 PV,可以保留 PV 以便下次使用,也可以直接从云存储中删除
根据这 5 个阶段,PV 的状态有以下 4 种:
●Available(可用):表示可用状态,还未被任何 PVC 绑定
●Bound(已绑定):表示 PV 已经绑定到 PVC
●Released(已释放):表示 PVC 被删掉,但是资源尚未被集群回收
●Failed(失败):表示该 PV 的自动回收失败
//一个PV从创建到销毁的具体流程如下:
1、一个PV创建完后状态会变成Available,等待被PVC绑定。
2、一旦被PVC邦定,PV的状态会变成Bound,就可以被定义了相应PVC的Pod使用。
3、Pod使用完后会释放PV,PV的状态变成Released。
4、变成Released的PV会根据定义的回收策略做相应的回收工作。有
三种回收策略,Retain、Delete和Recycle。
- Retain就是保留现场,K8S集群什么也不做,等待用户手动去处理PV里的数据,处理完后,再手动删除PV。
- Delete策略,K8S会自动删除该PV及里面的数据。(对于动态配置的PV来说,默认回收策略为Delete。表示当用户删除对应的PVC时,动态配置的volume将被自动删除。)
- Recycle方式,K8S会将PV里的数据删除,然后把PV的状态变成Available,又可以被新的PVC绑定使用。(如果用户删除PVC,则删除卷上的数据,卷不会删除)
查看pv的定义
apiVersion: v1kind: PersistentVolumemetadata: #由于 PV 是集群级别的资源,即 PV 可以跨 namespace 使用,所以 PV 的 metadata 中不用配置 namespacename: spec#查看pv定义的规格
kubectl explain pv.spec
spec:nfs:(定义存储类型)path:(定义挂载卷路径)server:(定义服务器名称)accessModes:(定义访问模型,有以下三种访问模型,以列表的方式存在,也就是说可以定义多个访问模式)- ReadWriteOnce #(RWO)卷可以被一个节点以读写方式挂载。 ReadWriteOnce 访问模式也允许运行在同一节点上的多个 Pod 访问卷。- ReadOnlyMany #(ROX)卷可以被多个节点以只读方式挂载。- ReadWriteMany #(RWX)卷可以被多个节点以读写方式挂载。
#nfs 支持全部三种;iSCSI 不支持 ReadWriteMany(iSCSI 就是在 IP 网络上运行 SCSI 协议的一种网络存储技术);HostPath 不支持 ReadOnlyMany 和 ReadWriteMany。#新版本的k8s还增减了ReadWriteOncePod 表示可以与某一个pod进行绑定capacity:(定义存储能力,一般用于设置存储空间)storage: 2Gi (指定大小)storageClassName: (自定义存储类名称,此配置用于绑定具有相同类别的PVC和PV)persistentVolumeReclaimPolicy: Retain #回收策略(Retain/Delete/Recycle)#Retain(保留):当用户删除与之绑定的PVC时候,这个PV被标记为released(PVC与PV解绑但还没有执行回收策略)且之前的数据依然保存在该PV上,但是该PV不可用,需要手动来处理这些数据并删除该PV。
#Delete(删除):删除与PV相连的后端存储资源。对于动态配置的PV来说,默认回收策略为Delete。表示当用户删除对应的PVC时,动态配置的volume将被自动删除。(只有 AWS EBS, GCE PD, Azure Disk 和 Cinder 支持)
#Recycle(回收):如果用户删除PVC,则删除卷上的数据,卷不会删除。(只有 NFS 和 HostPath 支持)查看pvc的定义
kubectl explain pvc #查看PVC的定义方式
KIND: PersistentVolumeClaim
VERSION: v1
FIELDS:apiVersion <string>kind <string> metadata <Object>spec <Object>#PV和PVC中的spec关键字段要匹配,比如存储(storage)大小、访问模式(accessModes)、存储类名称(storageClassName)
kubectl explain pvc.spec
spec:accessModes: (定义访问模式,必须是PV的访问模式的子集)resources:requests:storage: (定义申请资源的大小)storageClassName: (定义存储类名称,此配置用于绑定具有相同类别的PVC和PV)实操:静态创建pv的方式 实现pvc存储卷
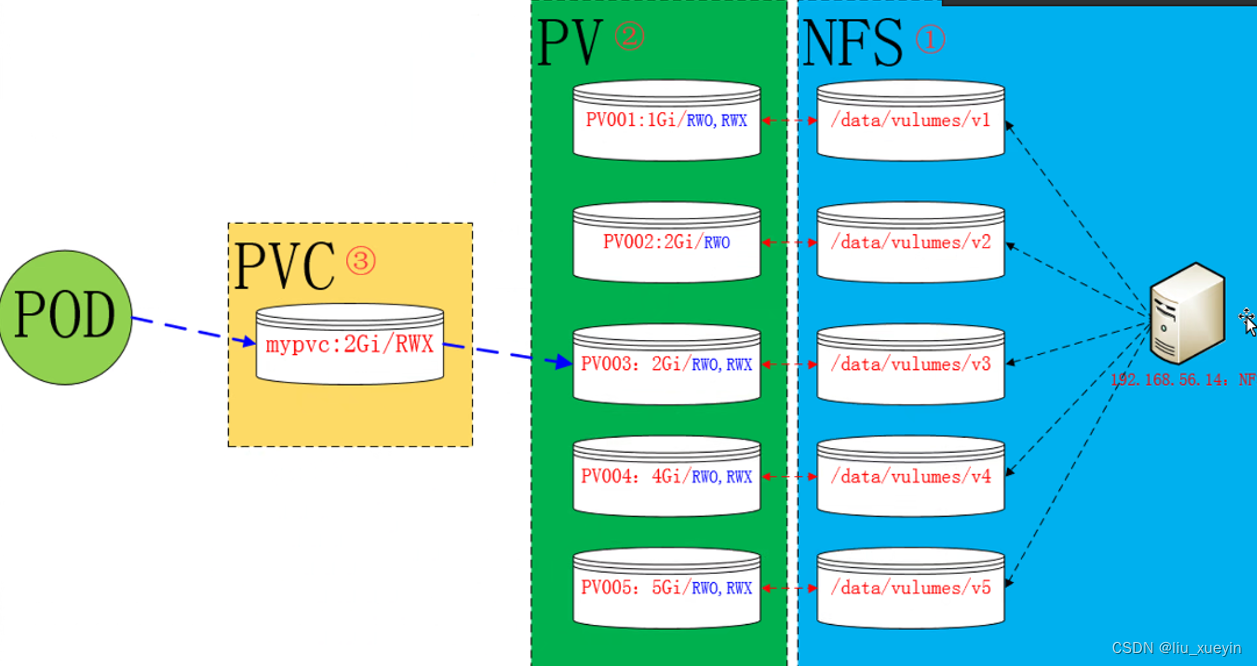
步骤一:先完成nfs的目录共享,需要准备不同的目录
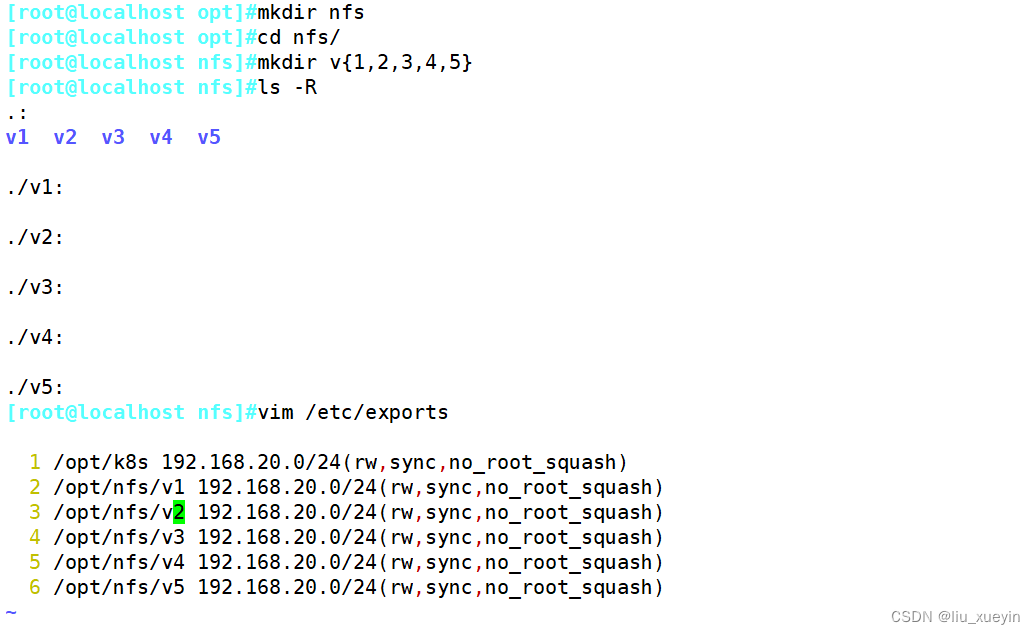
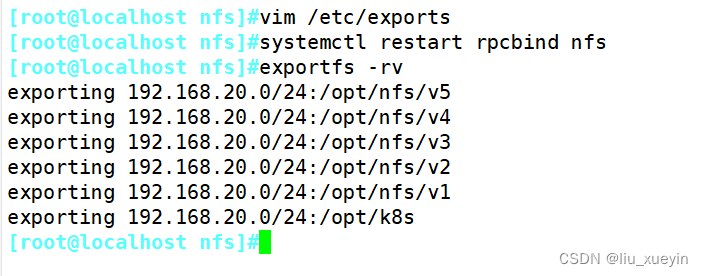
步骤二:编写配置文件,完成静态pv的创建,设置访问模式和资源大小等
apiVersion: v1
kind: PersistentVolume
metadata:name: pv001labels:name: pv001
spec:nfs:path: /opt/nfs/v1server: 192.168.20.10accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 1Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv002labels:name: pv002
spec:nfs:path: /opt/nfs/v2server: 192.168.20.10accessModes: ["ReadWriteOnce"]capacity:storage: 2Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv003labels:name: pv003
spec:nfs:path: /opt/nfs/v3server: 192.168.20.10accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 2Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv004labels:name: pv004
spec:nfs:path: /opt/nfs/v4server: 192.168.20.10accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 4Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv005labels:name: pv005
spec:nfs:path: /opt/nfs/v5server: 192.168.20.10accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 5Gi
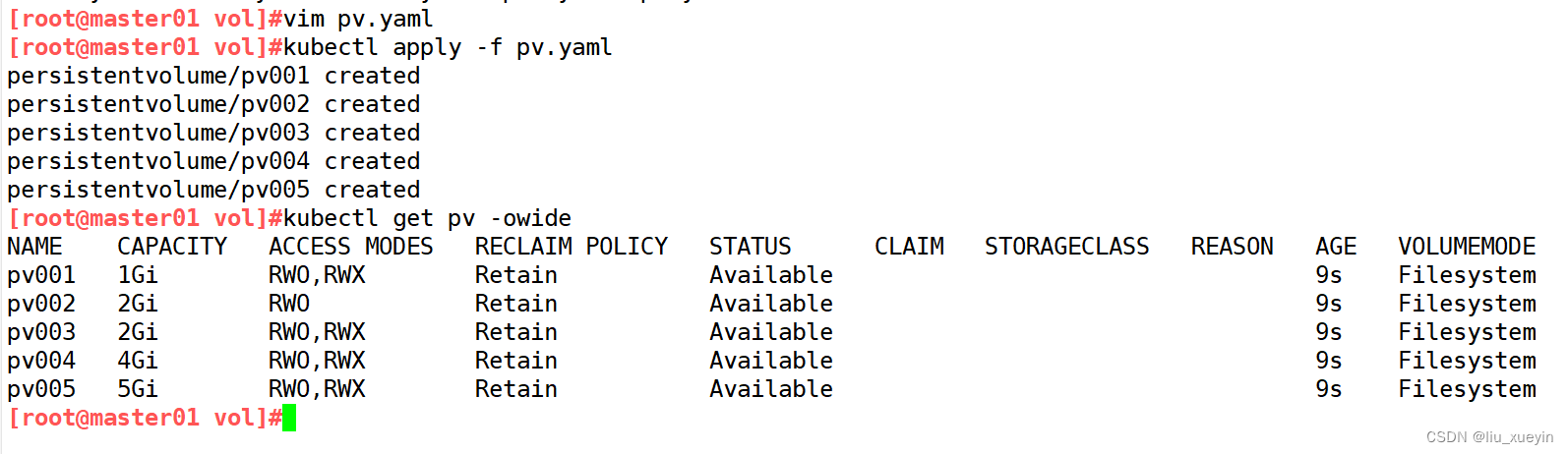
步骤三:编写pvc创建配置文件,完成创建,查看是否与pv绑定
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: mypvc #定义pvc的名称namespace: default
spec:accessModes: ["ReadWriteMany"]resources:requests:storage: 2Gi
---
apiVersion: v1
kind: Pod
metadata:name: pod-vol-pvcnamespace: default
spec:containers:- name: myappimage: soscscs/myapp:v1volumeMounts:- name: html #与下面定义的存储卷名称一致mountPath: /usr/share/nginx/htmlvolumes:- name: html #定义的是pvc的名称persistentVolumeClaim:claimName: mypvc #通过名称调用定义的pvc

步骤四:基于pvc存储卷创建pod
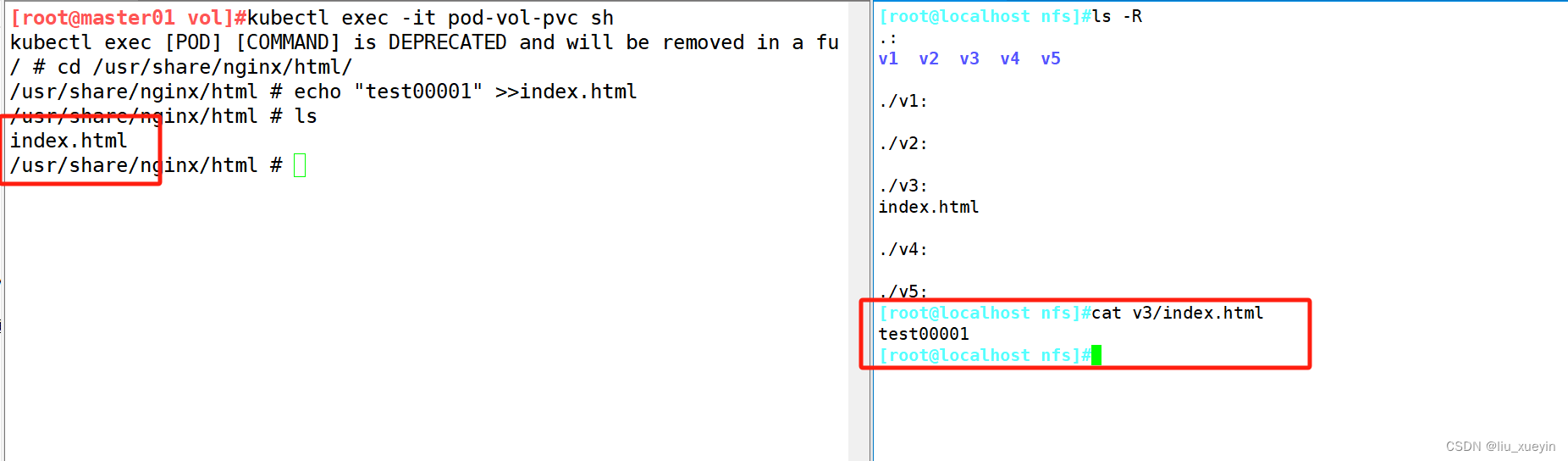
静态创建PV的步骤:
1)准备好存储设备和共享目录
2)准备创建PV资源的配置文件,定义访问模式(ReadWriteOnce、ReadOnlyMany、ReadWriteMany、ReadWriteMany)、存储空间大小、回收策略(Retain、Recycle、Delete)、存储设备类型、storageClassName等
3)准备创建PVC资源的配置文件,定义访问模式(必要条件,必须是PV支持的访问模式)、存储空间大小(默认就近选择大于等于指定大小的PV)、storageClassName等来绑定PV
4)创建Pod资源挂载PVC存储卷,定义卷类型为persistentVolumeClaim,并在容器配置中定义存储卷挂载点路径
实操:基于nfs存储卷插件动态创建pv,实现pvc存储卷
搭建 StorageClass + nfs-client-provisioner ,实现 NFS 的动态 PV 创建
Kubernetes 本身支持的动态 PV 创建不包括 NFS,所以需要使用外部存储卷插件分配PV。详见:https://kubernetes.io/zh/docs/concepts/storage/storage-classes/
卷插件称为 Provisioner(存储分配器),NFS 使用的是 nfs-client,这个外部卷插件会使用已经配置好的 NFS 服务器自动创建 PV。
Provisioner:用于指定 Volume 插件的类型,包括内置插件(如 kubernetes.io/aws-ebs)和外部插件(如 external-storage 提供的 ceph.com/cephfs)。
步骤一:完成nfs共享准备
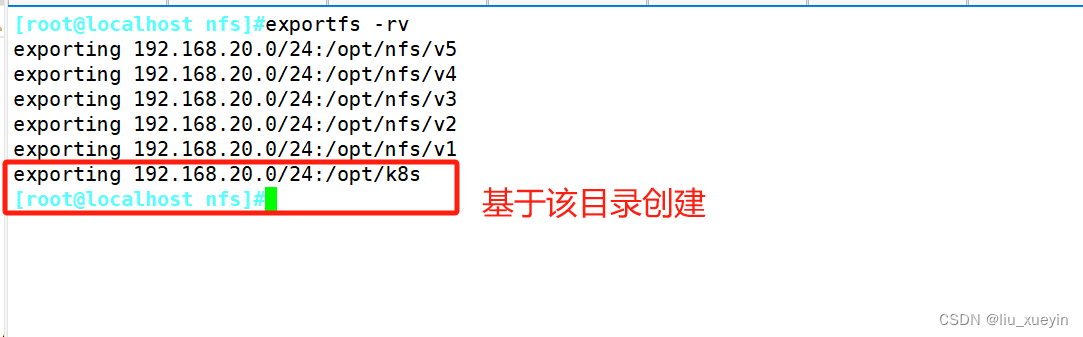
步骤二:创建 Service Account,用来管理 NFS Provisioner 在 k8s 集群中运行的权限,设置 nfs-client 对 PV,PVC,StorageClass 等的规则
#创建service Account 账户,用来管理 NFS Provisioner 在 k8s 集群中运行的权限
metadata:name: nfs-client-provisioner
---
#创建集群角色
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: nfs-client-provisioner-clusterrole
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["list", "watch", "create", "update", "patch"]- apiGroups: [""]resources: ["endpoints"]verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
---
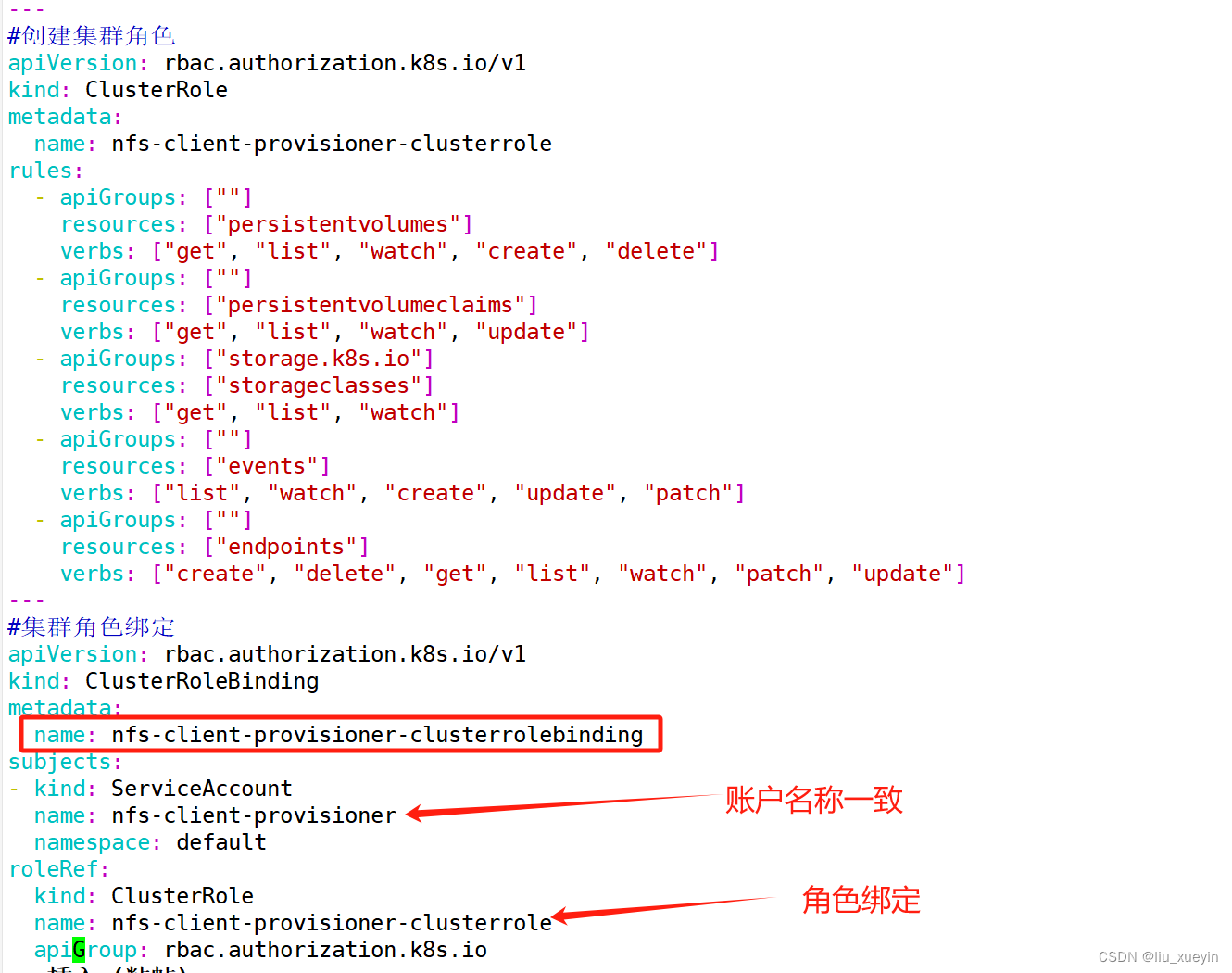
#集群角色绑定
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: nfs-client-provisioner-clusterrolebinding
subjects:
- kind: ServiceAccountname: nfs-client-provisionernamespace: default
roleRef:kind: ClusterRolename: nfs-client-provisioner-clusterroleapiGroup: rbac.authorization.k8s.io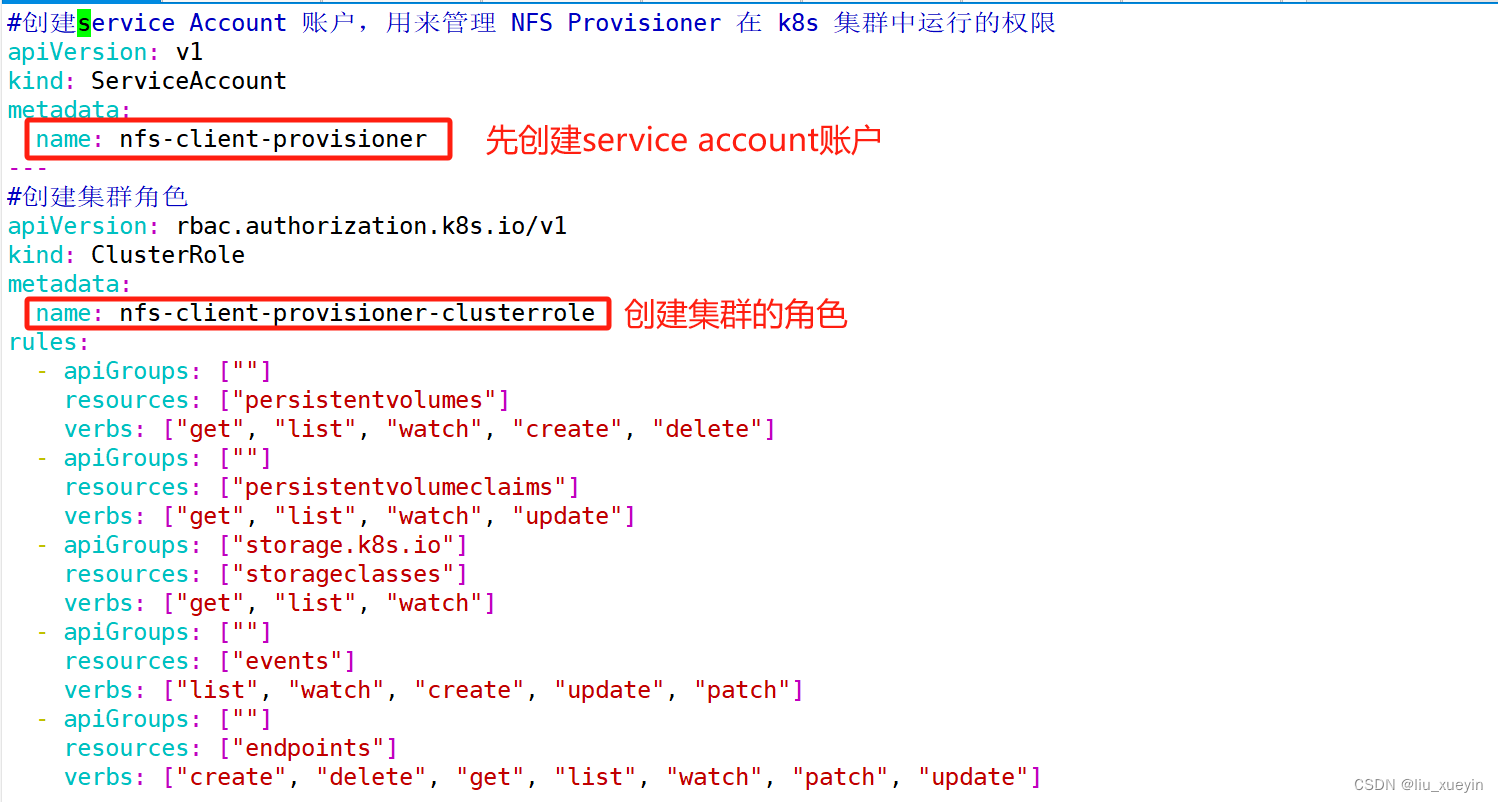


步骤三:使用 Deployment 来创建 NFS Provisioner
NFS Provisioner(即 nfs-client),有两个功能:一个是在 NFS 共享目录下创建挂载点(volume),另一个则是将 PV 与 NFS 的挂载点建立关联。
#由于 1.20 版本启用了 selfLink,所以 k8s 1.20+ 版本通过 nfs provisioner 动态生成pv会报错,解决方法如下:
vim /etc/kubernetes/manifests/kube-apiserver.yaml
spec:
containers:
- command:
- kube-apiserver
- --feature-gates=RemoveSelfLink=false #添加这一行
- --advertise-address=192.168.20.30
......
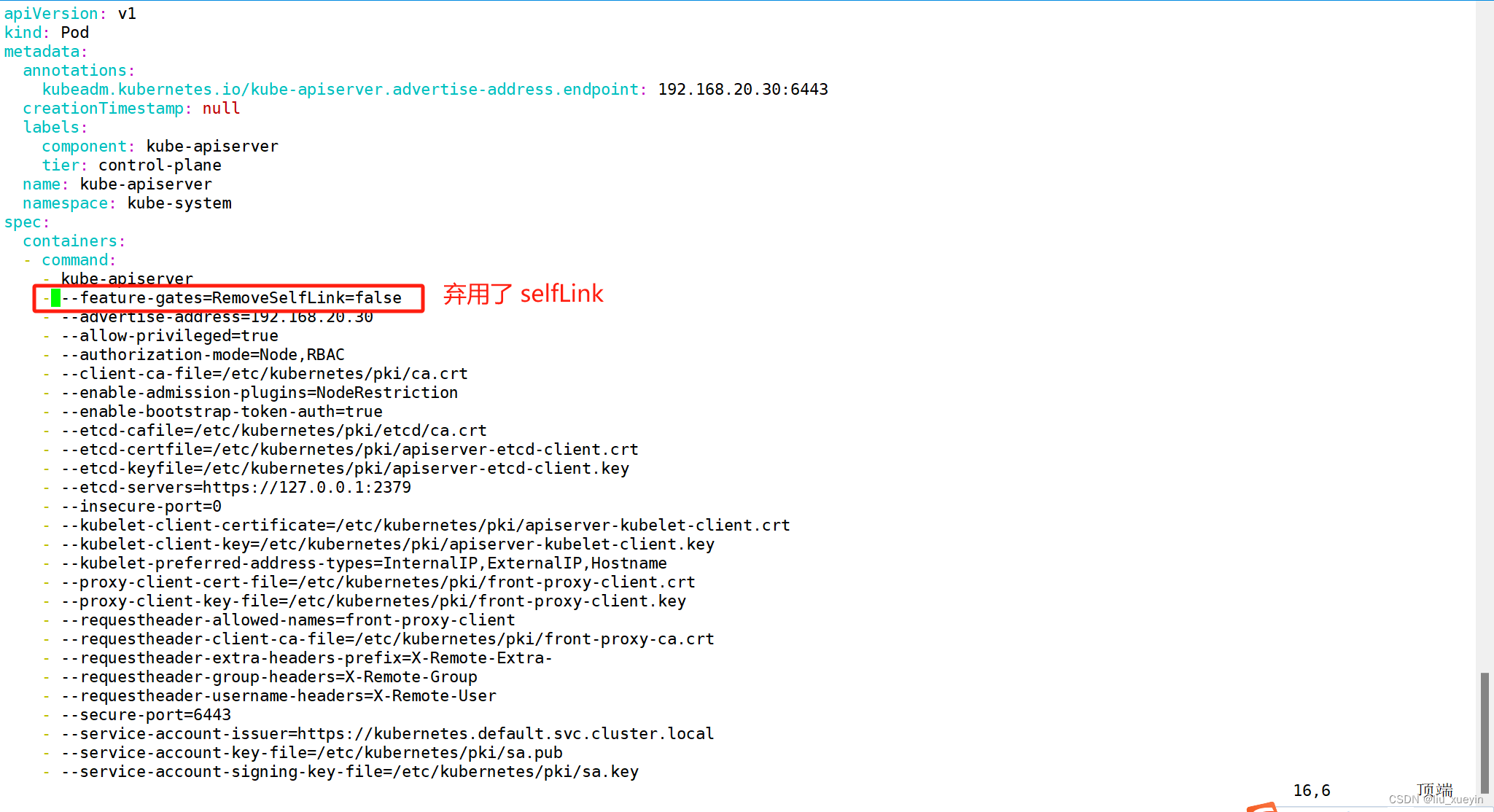

接下来以deployment的方式创建nfs的存储插件
kind: Deployment
apiVersion: apps/v1
metadata:name: nfs-client-provisioner
spec:replicas: 1selector:matchLabels:app: nfs-client-provisionerstrategy:type: Recreatetemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisioner #指定Service Account账户containers:- name: nfs-client-provisionerimage: quay.io/external_storage/nfs-client-provisioner:latestimagePullPolicy: IfNotPresentvolumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: nfs-storage #配置provisioner的Name,确保该名称与StorageClass资源中的provisioner名称保持一致- name: NFS_SERVERvalue: 192.168.20.10 #配置绑定的nfs服务器- name: NFS_PATHvalue: /opt/k8s #配置绑定的nfs服务器目录volumes: #申明nfs数据卷- name: nfs-client-rootnfs:server: 192.168.20.10path: /opt/k8s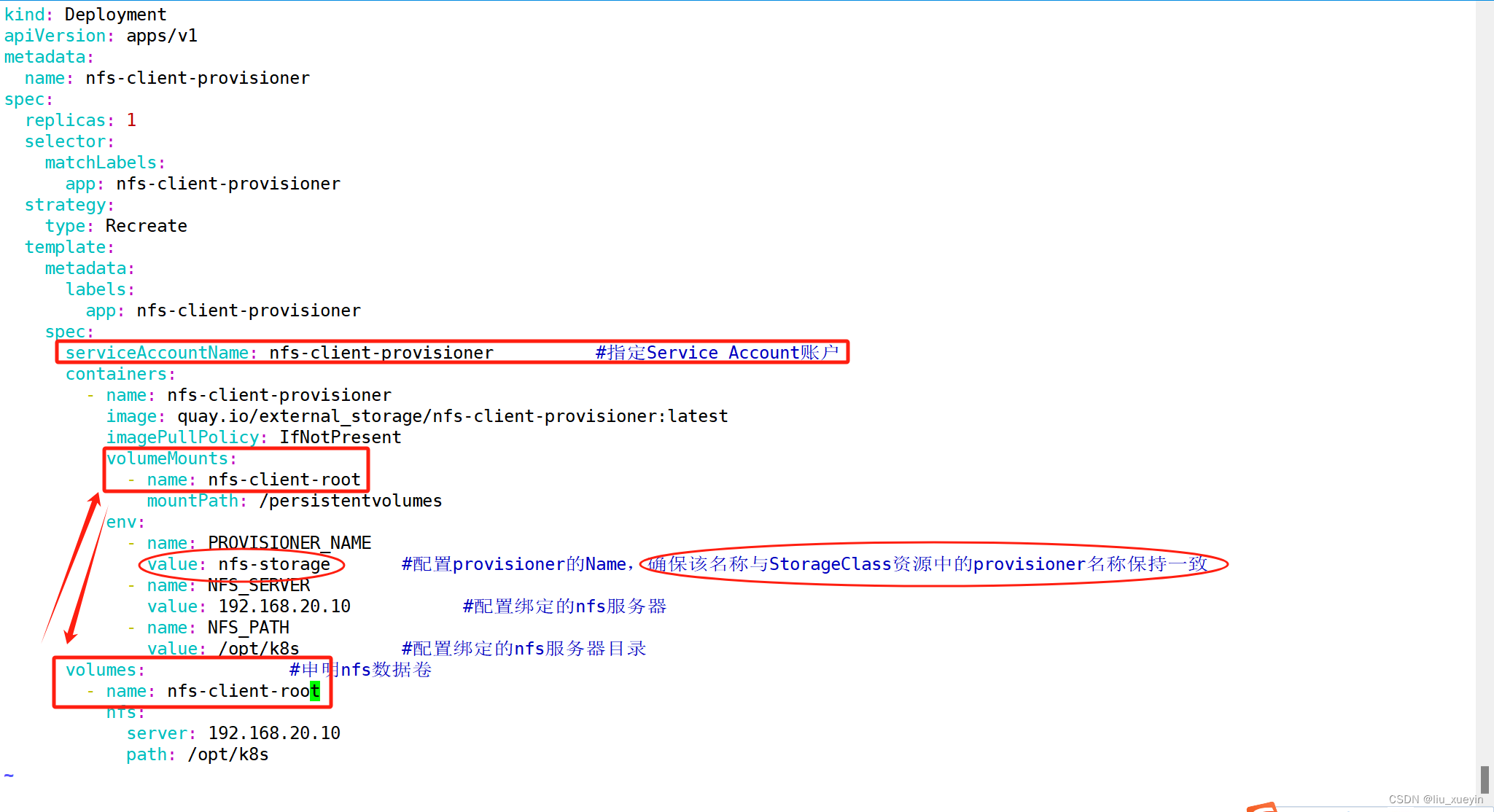
 步骤四:创建 StorageClass,负责建立 PVC 并调用 NFS provisioner 进行预定的工作,并让 PV 与 PVC 建立关联
步骤四:创建 StorageClass,负责建立 PVC 并调用 NFS provisioner 进行预定的工作,并让 PV 与 PVC 建立关联
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: nfs-client-storageclass
provisioner: nfs-storage #这里的名称要和provisioner配置文件中的环境变量PROVISIONER_NAME保持一致
parameters:archiveOnDelete: "false" #false表示在删除PVC时不会对数据目录进行打包存档,即删除数据;为ture时就会自动对数据目录进行打包存档,存档文件以archived开头

步骤五:创建pvc存储卷以及创建pod测试
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: test-nfs-pvc#annotations: volume.beta.kubernetes.io/storage-class: "nfs-client-storageclass" #另一种SC配置方式
spec:accessModes:- ReadWriteManystorageClassName: nfs-client-storageclass #关联StorageClass对象resources:requests:storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:name: test-storageclass-pod
spec:containers:- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentcommand:- "/bin/sh"- "-c"args:- "sleep 3600"volumeMounts:- name: nfs-pvcmountPath: /mntrestartPolicy: Nevervolumes:- name: nfs-pvcpersistentVolumeClaim:claimName: test-nfs-pvc #与PVC名称保持一致
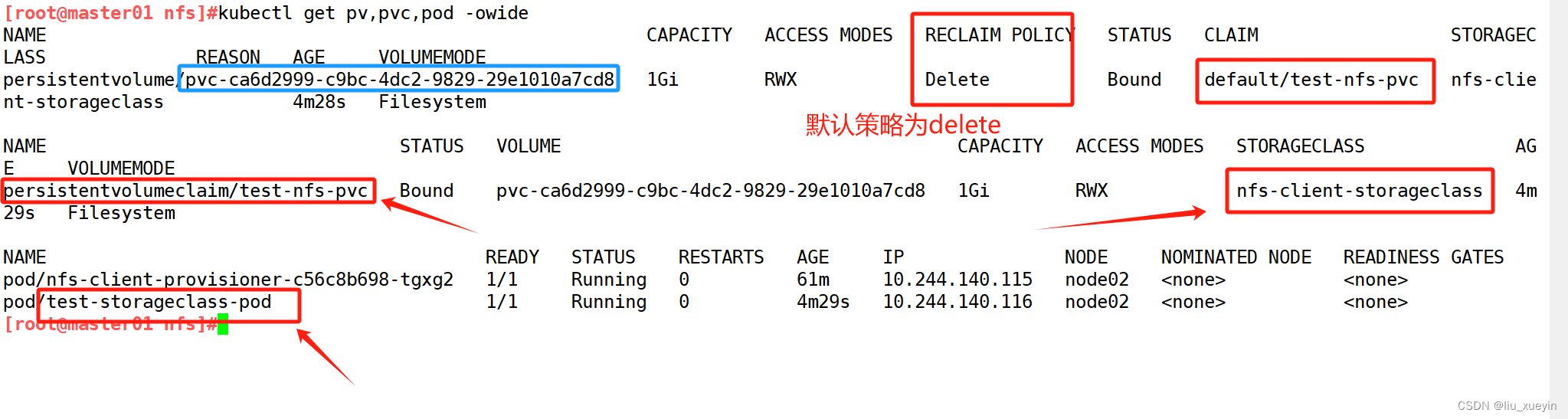
验证

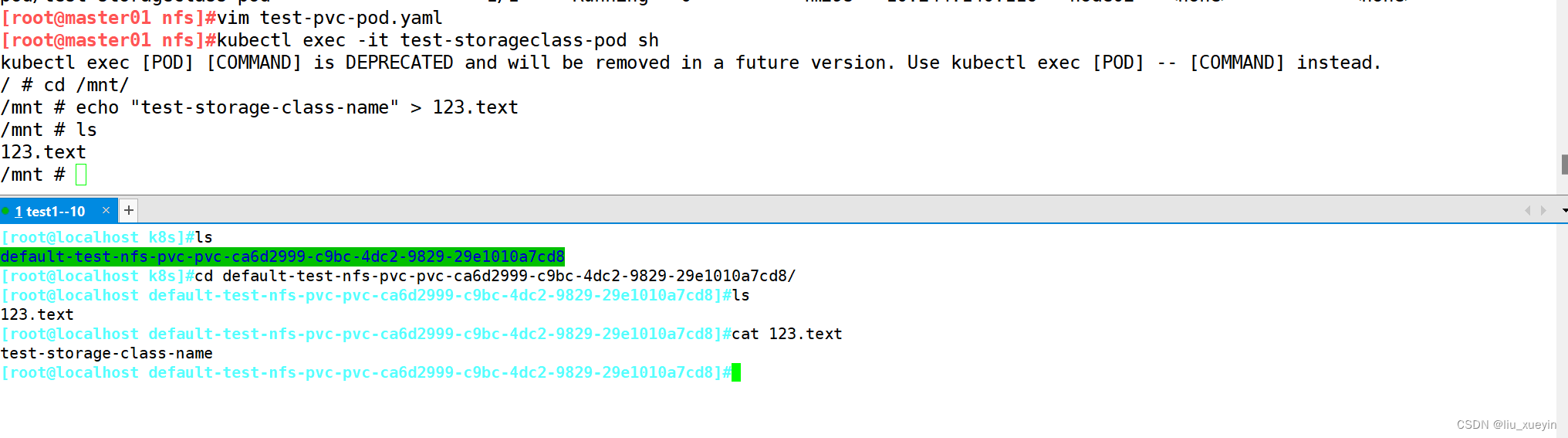 六、总结
六、总结
动态创建PV的步骤:
1)准备好存储设备和共享目录
2)如果是外置存储卷插件,需要先创建serviceaccount账户(Pod使用访问apiserver使用的账户)和RBAC授权(创建角色授予相关资源对象的操作权限,再将账户与角色绑定),使得serviceaccount账户具有对PV、PVC、StorageClass等资源的操作权限
3)准备创建外置存储插件Pod资源的配置文件(外置存储插件在k8s集群中以pod形式运行),定义serviceaccount账户作为Pod的用户,并设置相关的环境变量(比如存储插件名称等)
4)创建StorageClass资源,provisioner要设置为存储插件名称
------------------------以上操作是一劳永逸的,
之后只需要创建PVC资源引用StorageClass就可以自动调用存储卷插件动态创建PV资源
------------------------
5)准备创建PVC资源的配置文件,定义访问模式、存储空间大小、storageClassName设置为StorageClass资源名称等来动态创建PV资源并绑定PV
6)创建Pod资源挂载PVC存储卷,定义卷类型为persistentVolumeClaim,并在容器配置中定义存储卷挂载点路径