1. 丢弃法

在层之间加入随机噪音

加入噪音的一些规则
加入噪音后不要改变期望
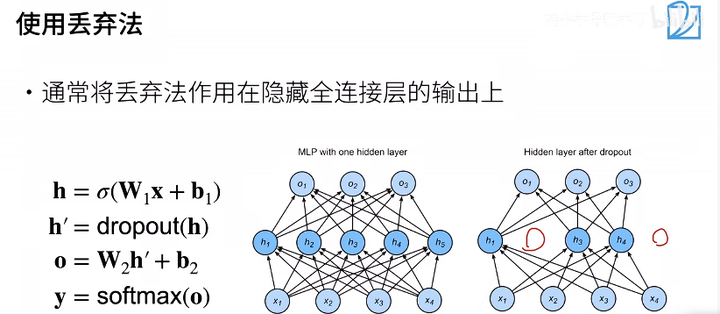
使用丢弃法

推理中的丢弃法

总结
2. 代码实现
4.6. 暂退法(Dropout![]() https://zh.d2l.ai/chapter_multilayer-perceptrons/dropout.html
https://zh.d2l.ai/chapter_multilayer-perceptrons/dropout.html
2.1 Dropout
import torch from torch import nn from d2l import torch as d2l def dropout_layer(X, dropout): assert 0 <= dropout <= 1 # 在本情况中,所有元素都被丢弃 if dropout == 1: return torch.zeros_like(X) # 在本情况中,所有元素都被保留 if dropout == 0: return X mask = (torch.rand(X.shape) > dropout).float() return mask * X / (1.0 - dropout)
2.2 测试dropout_layer函数
X= torch.arange(16, dtype = torch.float32).reshape((2, 8)) print(X) print(dropout_layer(X, 0.)) print(dropout_layer(X, 0.5)) print(dropout_layer(X, 1.))
2.3 定义模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
2.4 定义模型
dropout1, dropout2 = 0.2, 0.5 class Net(nn.Module): def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training = True): super(Net, self).__init__() self.num_inputs = num_inputs self.training = is_training self.lin1 = nn.Linear(num_inputs, num_hiddens1) self.lin2 = nn.Linear(num_hiddens1, num_hiddens2) self.lin3 = nn.Linear(num_hiddens2, num_outputs) self.relu = nn.ReLU() def forward(self, X): H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs)))) # 只有在训练模型时才使用dropout if self.training == True: # 在第一个全连接层之后添加一个dropout层 H1 = dropout_layer(H1, dropout1) H2 = self.relu(self.lin2(H1)) if self.training == True: # 在第二个全连接层之后添加一个dropout层 H2 = dropout_layer(H2, dropout2) out = self.lin3(H2) return out net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
2.5 训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256 loss = nn.CrossEntropyLoss(reduction='none') train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) trainer = torch.optim.SGD(net.parameters(), lr=lr) d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
3. 简洁实现
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), # 在第一个全连接层之后添加一个dropout层 nn.Dropout(dropout1), nn.Linear(256, 256), nn.ReLU(), # 在第二个全连接层之后添加一个dropout层 nn.Dropout(dropout2), nn.Linear(256, 10)) def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights);
4. 小结

13 丢弃法dropout【李沐动手学深度学习v2笔记】![]() https://zhuanlan.zhihu.com/p/685141275
https://zhuanlan.zhihu.com/p/685141275





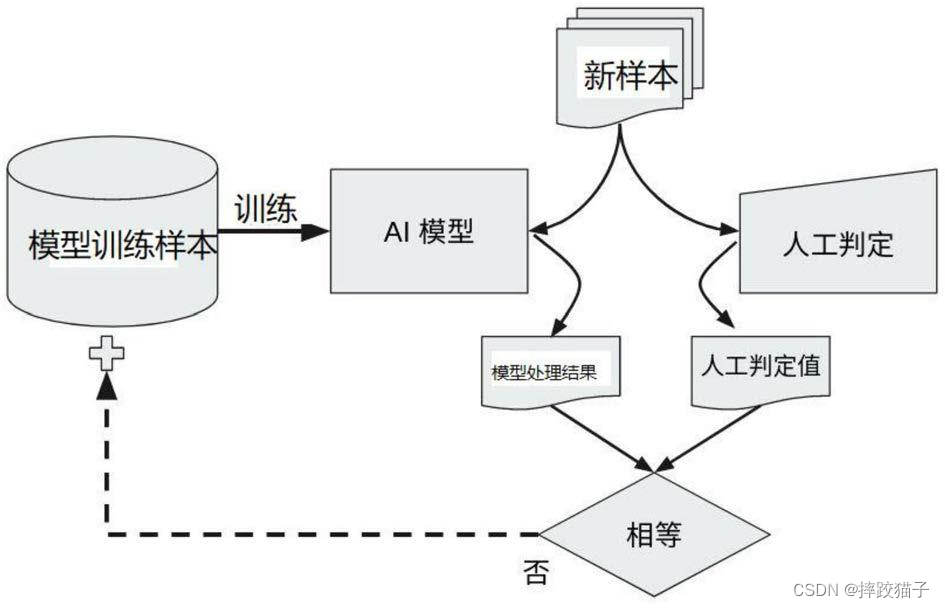

![[Redis]——数据一致性,先操作数据库,还是先更新缓存?](https://img-blog.csdnimg.cn/direct/3e043ea768e0470db53c0bfd3d15162e.png)
