最近做了一些大模型训练相关的训练相关的技术储备,在内部平台上完成了多机多卡的llm 预训练的尝试,具体的过程大致如下:
数据准备:
大语言模型的训练依赖于与之匹配的语料数据,在开源社区有一群人在自发的整理高质量的语料数据,可以通过 以下的一些链接获取
liwu/MNBVC at main
Skywork/SkyPile-150B · Datasets at Hugging Face
预训练框架:
选用了百川智能的开源框架
原始版本代码训练准备:
根据README 里面的介绍,需要准备以下几样东西:
-
训练数据,按照训练的卡的数目分成多个文件,每个文件的每一行为一整句的语料,类似这样的文件

添加图片注释,不超过 140 字(可选)
-
分词器(tokenizer) ,下载 分词器 到当前目录下。
-
修改hostfile训练脚本,单机训练情况下,不依赖于多机多卡的hostfile, 修改启动脚本 添加启动项 --num_nodes 即可完成单机多卡的训练
#!/bin/bash
deepspeed --hostfile config/hostfile --num_nodes=1 \ train.py \ --deepspeed \ --deepspeed_config config/deepspeed.json
原版的训练中几个要处理的问题
-
deepspeed.zero.Init. 错误
这个错误是发生在 deepspeed 设置优化等级不为3的情况下,调用deepspeed.zero.Init 函数会报错,需要在初始化的时候判断一下优化等级是不是3,因此修改代码如下:
//train.py def prepare_model():ds_config = json.load(open(args.deepspeed_config))# print(type(ds_config["zero_optimization"]['stage']))with deepspeed.zero.Init(config_dict_or_path=args.deepspeed_config,enabled=ds_config["zero_optimization"]['stage']==3,mem_efficient_linear=False,mpu=None):model = BaiChuanForCausalLM(smallconfig)
-
数据不可无限读取
def get_data(self):# todo 循环读取#data = self.data.pop(0)在原版本的实现中,数据是从队列中pop 出来的,导致当数据读完了之后会报一个错误导致训练中断
此外原版代码中所有的语料是读取到内存中再进行操作,但是随着语料的量级达到T级别,基本无法全部用内存hold 住所有的语料,另外读取语料的到内存的时间也会很长,基于以上几点考虑,重新选择tfrecord 作为新的数据的存储方式
TFRecord
tfrecord 是一种在tensorflow 中常用的数据格式,数据基于protobuf 完成序列化存储,配合对应的index 可以实现高速的数据读取从而减少数据读取造成的性能瓶颈,原版的训练代码基于的pytorch的框架,可以pip 安装
pip install tfrecord
来使用这个数据结构, 注意这个库可能会遇到protobuf 版本库的问题,通过pip 重新安装 protobuf==3.19 可以解决,
编写对应的代码完成将原来的jsonl 数据转换成tfrecord
//tools/jsonlmutiltfrecord.py
import tfrecord
import os
from tqdm import tqdm
import json
import torch
from tfrecord.torch.dataset import MultiTFRecordDataset, TFRecordDatasetori_path = "/workspace/mnt/storage/zhaozhijian/silk-debug/Baichuan-7B/data_dir_ori"
out_path = "/workspace/mnt/storage/zhaozhijian/silk-debug/Baichuan-7B/data_dir_mutil_test"if not os.path.exists(out_path):os.mkdir(out_path)numgpu = 16
fidlist = []
for i in range(numgpu):writer = tfrecord.TFRecordWriter(os.path.join(out_path,"data" +str(i)+".tfrecord"))fidlist.append(writer)if 1:files = os.listdir(ori_path)count = 0for file in files:with open(os.path.join(ori_path, file)) as f:for line in tqdm(f.readlines()):dict_ = json.loads(line)fidlist[count%numgpu].write({"text":(dict_["text"].encode('utf-8'), "byte")})count +=1for writer in fidlist:writer.close()os.system("python3 -m tfrecord.tools.tfrecord2idx " + os.path.join(out_path))tfrecord_path = os.path.join(out_path,"data{}.tfrecord")
index_path = os.path.join(out_path,"data{}.tfindex")
splits = {"1": 1,
}
description = {"text": "byte"}
dataset = MultiTFRecordDataset(tfrecord_path, index_path, splits, description, infinite=False)
loader = torch.utils.data.DataLoader(dataset, batch_size=1)for item in loader:print(item['text'].decode('utf-8'))这里需要注意,tfrecord 的写入的数据只有int,float, byte 3种形式,因此string 格式的数据数据需要通过utf-8的编码写入到tfrecord 中,再读取的时候通过utf-8的解码才能还原为写入的string数据,对应修改train.py 文件,
from tfrecord.torch.dataset import TFRecordDataset, MultiTFRecordDataset...
class DataEngine():...def load_tfrecode_data_mutil(self):splits = {}for file_path in self.local_input_paths: splits[file_path.replace('.tfrecord', '')] = 1.0/len(self.local_input_paths)tfrecord_path = "{}.tfrecord"index_path = "{}.tfindex"description = {"text": "byte"}dataset = MultiTFRecordDataset(tfrecord_path, index_path, splits, description, infinite=False)self.loader = torch.utils.data.DataLoader(dataset, batch_size=1)return
...
def prepare_data():data_dir = args.data_dir....# data_engine.load_data()data_engine.load_tfrecode_data_mutil()return data_engine
...
def train(data_engine, model_engine):model_engine.train()step = 0data =[]for item in data_engine.loader:while 1:line = item['text'].decode('utf-8')cc = data_engine.sp.EncodeAsIds(line.strip()) + [data_engine.EOS_TOKEN_ID]if len(cc) < data_engine.MIN_TEXT_LEN:continuedata.extend(cc)if len(data) >= data_engine.micro_batch_size * (data_engine.max_length + 1):index = data_engine.micro_batch_size * (data_engine.max_length + 1)data = data[:index]breakseq = np.asarray(data).reshape(data_engine.micro_batch_size, data_engine.max_length + 1)data = torch.LongTensor(seq)data = data.cuda(non_blocking=True)loss = model_engine(data, labels=data).lossmodel_engine.backward(loss)model_engine.step()step += 1data =[]return成功解决数据加载中内存和读取速度的问题
多机多卡训练
原版本使用的hostfile 做为启动器,这个有一个前提条件需要各个机器之间可以通过ssh协议互相通信,但是在我们的内部ATOM的环境中无法做到这个,所以启动多机多卡的训练的时候会出现启动两个单机训练和无法启动训练两种情况,这些和我们的多机多卡训练不符
经过摸索后,我们采用了torchrun的启动方式,利用master_addr 等环境变量,用torchstyle 的方式启动多机多卡训练,解决了deepspeed 启动器对于ssh 通信的依赖
NUM_GPUS=8
torchrun --nnodes=$WORLD_SIZE --nproc-per-node=$NUM_GPUS --master-addr=$MASTER_ADDR \--master-port=$MASTER_PORT --node-rank=$RANK \train.py \--deepspeed \--deepspeed_config config/deepspeed.json >log$RANK.txt对应的修改train.py 中的一些内容:
//train.py
###
deepspeed.init_distributed()
args.local_rank=int(os.environ['LOCAL_RANK'])
###
def prepare_data():...model = BaiChuanForCausalLM(smallconfig)torch.cuda.set_device(args.local_rank)...def train(data_engine, model_engine):model_engine.train()local_rank = int(os.environ['LOCAL_RANK'])...data = data.cuda(non_blocking=True).to(local_rank)...一些遗留的BUG:
启动训练会卡住: 原因特别傻,就是现在在数据目录下会有tfrecord 和 index 两种后缀的文件,在按照radnk分的时候由于不够随机,会有loader 读取不到文件,导致计算loss 时候卡住,修改 DataEngine
files = [x for _, x in enumerate(self.global_input_paths)if x.find('.tfrecord') != -1]self.local_input_paths = [x for i, x inenumerate(files)if i % dist.get_world_size() == dist.get_rank()]即可。
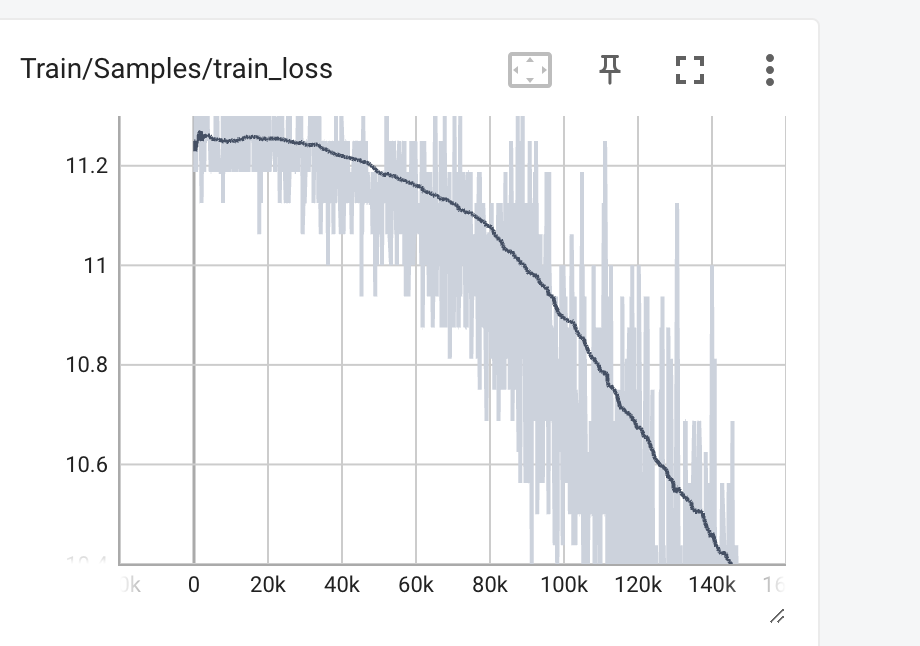
最终的训练loss 如下: