文章目录
- 1.什么是线程池
- 2.线程池的优势
- 3.原理
- 4.代码编写
- 4.1 阻塞队列
- 4.2 ThreadPool线程池
- 4.3 Worker工作线程
- 4.4 代码测试
- 5. 拒绝策略
- 5.1 抽象Reject接口
- 5.2 BlockingQueue新增tryPut方法
- 5.3 修改ThreadPool的execute方法
- 5.4 ThreadPool线程池构造函数修改
- 5.5 拒绝策略实现
- 1. 丢弃策略
- 2. 移除最老元素
- 3. 死等
- 4. 抛出异常
- 5.6 代码测试
- 6.全部代码
1.什么是线程池
线程池,通过创建了一定数量的线程并将其维护在一个池(即容器)中。当有新的任务提交时,线程池会从池子中分配一个空闲线程来执行任务,而不是每次都新建线程。执行完任务后,线程不会被销毁,而是返回到线程池中等待下一个任务。
2.线程池的优势
- 避免线程的重复创建与销毁:对于需要执行的任务,如果每个任务都需要创建一个线程,线程执行完任务后销毁,那么会极大的造成资源的浪费。一方面任务数量可能会很庞大,创建与之匹配的线程会对内存造成严重消耗;另一方面,创建完的线程只工作一次,资本家看了落泪,md血亏啊。
- 降低资源消耗:创建的线程反复利用,避免了创建与销毁带来的开销
- 提高工作的准备时间:被提交的任务可以迅速被线程池中存储的线程执行,无需重新创建
3.原理
线程池中存在以下核心组件
- 线程池容器(存储工作线程)
- 任务队列(存储需要执行的任务)
下述代码中,线程池使用HashSet存储;任务队列,使用的是这篇文章实现的BlockingQueue阻塞队列
另外,单纯的Thread线程能够存储的信息太少,因此我们创建Worker对象,extents Thread来包装Thread
下图是线程池的工作流程
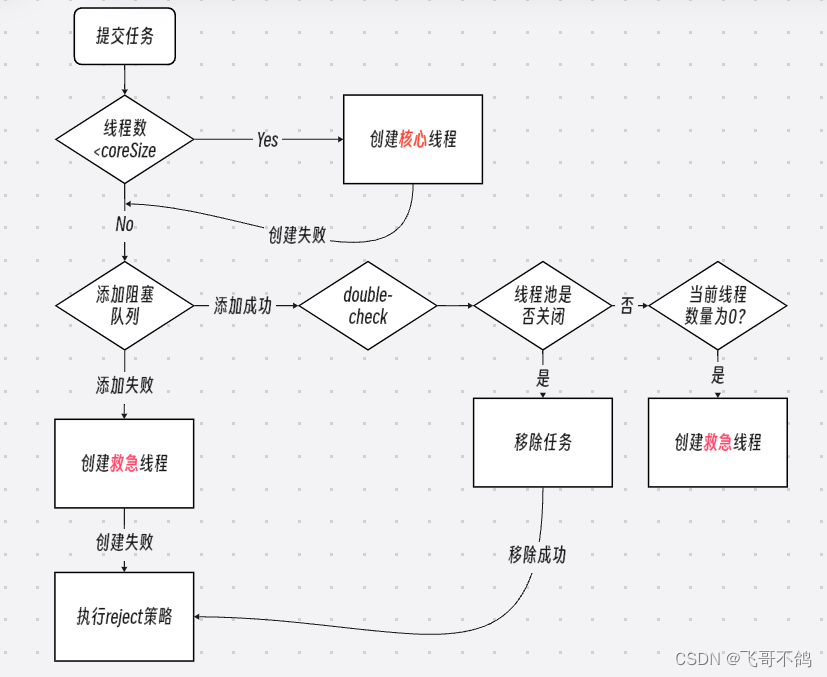
大体来说,线程池执行逻辑分为三大步骤
- 如果
current thread number<coreSize,创建核心线程执行任务tip:
- current thread number在源码中,是有一个
AtomicInteger变量ctl表示。ctl是核心线程池状态控制器,它被分为两个组成部分。其中,高三位表示runStatus,线程池状态;低三位表示workCount,工作线程数量。 - 选择一个变量ctl同时存储runStatus和workCount,可以通过一次
CAS操作实现原子赋值,而不用两次。
- current thread number在源码中,是有一个
- 如果核心线程创建失败,或者核心线程数量过多,则将任务存储在阻塞队列中:在这一步中,存在非常多的细节。
2.1. 如果当前线程池不处于RUNNING状态,尝试创建救急线程运行,不执行入队操作
2.2. 如果入队失败,同样创建救急线程
2.3. 如果线程池处于运行状态,且入队成功。进行double-check,重新检查线程池状态ctl
2.4. 如果此时线程池不处于RUNNIG状态,移除刚入队的任务,并执行reject策略
2.5. 如果线程池依然处于RUNNIG状态,且工作线程为0,创建救急线程,执行任务 - 如果上述步骤均失败,创建救济线程,如果依然失败,执行reject策略
4.代码编写
4.1 阻塞队列
实现请看BlockingQueue阻塞队列,本文不再赘述
4.2 ThreadPool线程池
/*** 线程池*/
@Slf4j
public class ThreadPool {// 核心线程数private int coreSize;// 阻塞队列private BlockingQueue<Runnable> workQueue;// 队列容量private int capacity;// 工作线程private final HashSet<Worker> workers = new HashSet<>();// todo: Worker(详见下一部分)private final class Worker extents Thread { /*...*/ }public ThreadPool(int coreSize, int capacity) {this.coreSize = coreSize;this.capacity = capacity;this.workQueue = new BlockingQueue<>(capacity);}/*** 执行task任务. 如果当前线程数量 < coreSize, 创建线程执行* 否则加入阻塞队列. 如果阻塞队列已满, 执行当前拒绝策略* @param task 需要执行任务*/public void execute(Runnable task) {if (task == null)throw new NullPointerException("task is null");synchronized (workers) {if (workers.size() < coreSize) {// 创建线程执行(我们倾向于创建新线程来执行任务, 而非已创建线程)log.info("创建worker");Worker worker = new Worker(task);workers.add(worker);worker.start(); // 千万别写成调用run方法, 否则主线程会阻塞(run不会开启线程)}else {log.info("添加阻塞队列");// 添加阻塞队列workQueue.put(task);}}}
}
上述代码实现简易版线程池。
workQueue:阻塞队列,用于存储待执行的任务coreSize:核心线程数量capacity:阻塞队列大小workers:工作线程的存储容器(线程池),用HashSet实现。请注意,HashSet是线程不安全的,因此在对HashSet操作时,记得加锁保证不会出现并发问题
本节对execute执行逻辑进行一定的简化,暂时不考虑拒绝策略(后续介绍)。
- 如果当前线程数量 < coreSize,创建核心线程并执行任务
- 否则添加阻塞队列
tip: 如果任务数量超过阻塞队列容量,那么依据阻塞队列的性质,后续的所有线程都会阻塞,等待容量减少。
4.3 Worker工作线程
我们使用包装过后的线程对象。且Worker是ThreadPool的内部类
private final class Worker extends Thread {// 执行的任务private Runnable task;Worker(Runnable task) {this.task = task;}/*** 执行task任务, 如果task为null, 则从workQueue工作队列中获取任务* 如果工作队列中不存在等待执行的任务, 终止当前Worker工作线程*/@Overridepublic void run() {while (task != null || (task = workQueue.take()) != null) {try {log.info("运行任务");task.run();} catch (Exception e) {e.printStackTrace();} finally {task = null;}}// 移除当前工作线程synchronized (workers) {workers.remove(this);}}
}
为了简化代码编写,本文只存在核心线程。核心线程的工作是监视阻塞队列,获取待执行的任务并执行
在run方法中,while循环的条件有二
task != null: worker线程创建时,会分配第一个待执行的任务。如果待执行的任务不为null,则执行任务task = workQueue.take():worker线程持续监视workQueue阻塞队列中的任务,如果存在任务,获取并执行
tip: workQueue.take()是一个阻塞的方法,没有时间的限制。也就是说,哪怕workQueue为空,该方法也会死等下去
4.4 代码测试
import lombok.extern.slf4j.Slf4j;@Slf4j
public class Test {public static void main(String[] args) throws InterruptedException {ThreadPool threadPool = new ThreadPool(2, 5);for (int i = 0; i < 10; i++) {int j = i;// 任务创建时间为2s, 任务消费时间显著低于任务创建时间.// 因此本模型是个典型的快生产, 慢消费的模型threadPool.execute(() -> {try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}log.info(String.valueOf(j));});}}
}
控制台输出
21:07:34.189 [main] INFO com.fgbg.juc.ThreadPool - 创建worker
21:07:34.202 [main] INFO com.fgbg.juc.ThreadPool - 创建worker
21:07:34.202 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:34.205 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:34.205 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:34.205 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:34.205 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:34.205 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:34.203 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:34.209 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:36.223 [Thread-0] INFO com.fgbg.juc.Test - 0
21:07:36.223 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:36.223 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:36.239 [Thread-1] INFO com.fgbg.juc.Test - 1
21:07:36.240 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:36.240 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:07:38.239 [Thread-0] INFO com.fgbg.juc.Test - 2
21:07:38.239 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:38.256 [Thread-1] INFO com.fgbg.juc.Test - 3
21:07:38.256 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:40.250 [Thread-0] INFO com.fgbg.juc.Test - 4
21:07:40.250 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:40.265 [Thread-1] INFO com.fgbg.juc.Test - 5
21:07:40.266 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:42.252 [Thread-0] INFO com.fgbg.juc.Test - 6
21:07:42.252 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:42.268 [Thread-1] INFO com.fgbg.juc.Test - 7
21:07:42.268 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:07:44.260 [Thread-0] INFO com.fgbg.juc.Test - 8
21:07:44.275 [Thread-1] INFO com.fgbg.juc.Test - 9
线程池核心线程数为2,因此一开始迅速创建2个worker线程。但因为阻塞队列容量为5,且每个线程工作需要2s,耗时远远小于任务产出的速度,因此队列被迅速沾满
当提交第8个任务时,主线程进入阻塞状态,无法继续提交任务(2个任务正在执行 + 5个任务添加阻塞队列 + 1个任务刚要入队,就阻塞了)
当第一个任务被执行完成,Thread-0 Worker执行阻塞队列中的其他任务。此时存在多余位置,之前被阻塞主线程成功提交任务,并继续循环
后续的流程大体一致,故不在做多余分析。
5. 拒绝策略
所谓拒绝策略,就是提供给调用方一个选择。如果调用方提交了过量的任务,多余的任务作何种处理。
由上方代码分析可知,我们一开始对于过量的任务,处理方案就是死等。但这种方案无法满足其他特定的需求,比如某个场景对执行速度有要求,等待一段时间后阻塞队列依然无法处理额外的任务,那么主线程就要抛弃该任务。死等是处理的方式之一,但存在不少的局限性,我们需要更多的处理方式。
对于不同的处理方式,我们可以选择将代码写死在ThreadPool中,但这样太不灵活,对于不同的场景,我们需要添加大量if else。因此我们可以采用策略模式,将拒绝的行为抽象成一个接口,创建ThreadPool时,由调用方传递接口。这样我们就可以在不改变ThreadPool内部代码的同时,改变ThreadPool面对超量任务的拒绝行为
5.1 抽象Reject接口
@FunctionalInterface
public interface RejectPolicy {// 执行拒绝策略void reject(Runnable task, BlockingQueue<Runnable> workQueue);
}
5.2 BlockingQueue新增tryPut方法
tryPut方法,尝试将元素立刻添加到阻塞队列中,不支持阻塞等待
// 尝试立即添加元素
public boolean tryPut(T task) {lock.lock();try {if (deque.size() == capacity) return false;deque.addLast(task);return true;} finally {lock.unlock();}
}
5.3 修改ThreadPool的execute方法
execute执行task入队操作时,如果入队失败(阻塞队列已满),则调用reject执行拒绝策略
public void execute(Runnable task) {if (task == null)throw new NullPointerException("task is null");synchronized (workers) {if (workers.size() < coreSize) {// 创建线程执行(我们倾向于创建新线程来执行任务, 而非已创建线程)log.info("创建worker");Worker worker = new Worker(task);workers.add(worker);worker.start(); // 千万别写成调用run方法, 否则主线程会阻塞(run不会开启线程)}else {log.info("添加阻塞队列");/*----------------modify below-------------------*/// 添加阻塞队列// workQueue.put(task);// 添加失败if ( !workQueue.tryPut(task)) {// 执行拒绝策略rejectPolicy.reject(task, workQueue);}}}}
5.4 ThreadPool线程池构造函数修改
// 拒绝策略private RejectPolicy rejectPolicy;public ThreadPool(int coreSize, int capacity, RejectPolicy rejectPolicy) {this(coreSize, capacity);this.rejectPolicy = rejectPolicy;}
5.5 拒绝策略实现
因为RejectPolicy接口有@FunctionalInterface,支持lambda表达式,因此编写的时候可以简写
1. 丢弃策略
(task, workQueue) -> {}
2. 移除最老元素
(task, workQueue) -> { workQueue.poll(); }
tip: 笔者自定义的BlockingQueue没有实现
poll方法,各位读者如果感兴趣,可以自行实现。需要注意的是,记得加锁保证线程安全
3. 死等
(task, workQueue) -> { workQueue.put(task); }
4. 抛出异常
(task, workQueue) -> { new RuntimeException("workQueue is full"); }
5.6 代码测试
@Slf4j
public class Test3 {public static void main(String[] args) throws InterruptedException {ThreadPool threadPool = new ThreadPool(2, 5, (task, workQueue) -> {log.info("任务丢弃");});for (int i = 0; i < 10; i++) {int j = i;threadPool.execute(() -> {try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}log.info(String.valueOf(j));});}}
}
上述代码选择的拒绝策略是丢弃
控制台输出
21:46:37.621 [main] INFO com.fgbg.juc.ThreadPool - 创建worker
21:46:37.630 [main] INFO com.fgbg.juc.ThreadPool - 创建worker
21:46:37.631 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.631 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.631 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:46:37.631 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.631 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.631 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.631 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.631 [main] INFO com.fgbg.juc.Test3 - 任务丢弃
21:46:37.631 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.631 [main] INFO com.fgbg.juc.Test3 - 任务丢弃
21:46:37.632 [main] INFO com.fgbg.juc.ThreadPool - 添加阻塞队列
21:46:37.632 [main] INFO com.fgbg.juc.Test3 - 任务丢弃
21:46:37.633 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:46:39.636 [Thread-1] INFO com.fgbg.juc.Test3 - 1
21:46:39.636 [Thread-0] INFO com.fgbg.juc.Test3 - 0
21:46:39.636 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:46:39.636 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:46:41.644 [Thread-0] INFO com.fgbg.juc.Test3 - 3
21:46:41.645 [Thread-0] INFO com.fgbg.juc.ThreadPool - 运行任务
21:46:41.644 [Thread-1] INFO com.fgbg.juc.Test3 - 2
21:46:41.645 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:46:43.651 [Thread-1] INFO com.fgbg.juc.Test3 - 5
21:46:43.651 [Thread-0] INFO com.fgbg.juc.Test3 - 4
21:46:43.651 [Thread-1] INFO com.fgbg.juc.ThreadPool - 运行任务
21:46:45.657 [Thread-1] INFO com.fgbg.juc.Test3 - 6
由日志可知,第8,9,10号任务被丢弃。任务对应的输出为7,8,9。观察输出的数字,发现最大值为6。因此确认了7~10号任务全部被拒绝,测试成功
6.全部代码
BlockingQueue
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;// 消息队列(阻塞队列)
class BlockingQueue<T> {// 队列private Deque<T> deque = new ArrayDeque<>();// 容量private int capacity;// 锁private final ReentrantLock lock = new ReentrantLock();// 消费者等待条件private Condition consumerWaitSet = lock.newCondition();// 生产者等待条件private Condition producerWaitSet = lock.newCondition();public BlockingQueue(int capacity) {this.capacity = capacity;}// 添加元素public void put(T element) {lock.lock();try {// 队列已满while (deque.size() == capacity) {try {// 阻塞等待producerWaitSet.await();} catch (InterruptedException e) {}}// 添加元素deque.addLast(element);// 唤醒其它线程consumerWaitSet.signal();} finally {lock.unlock();}}// 获取元素public T take() {lock.lock();try {// 判空while (deque.size() == 0) {try {// 阻塞等待consumerWaitSet.await();} catch (InterruptedException e) {}}// 获取元素T res = deque.pollFirst();producerWaitSet.signal();return res;} finally {lock.unlock();}}// 尝试立即添加元素public boolean tryPut(T task) {lock.lock();try {if (deque.size() == capacity) return false;deque.addLast(task);return true;} finally {lock.unlock();}}
}
RejectPolicy
@FunctionalInterface
public interface RejectPolicy {// 执行拒绝策略void reject(Runnable task, BlockingQueue<Runnable> workQueue);
}
ThreadPool
import lombok.extern.slf4j.Slf4j;import java.util.HashSet;/*** 线程池*/
@Slf4j
public class ThreadPool {// 核心线程数private int coreSize;// 阻塞队列private BlockingQueue<Runnable> workQueue;// 队列容量private int capacity;// 工作线程private final HashSet<Worker> workers = new HashSet<>();// 拒绝策略private RejectPolicy rejectPolicy;private final class Worker extends Thread {// 执行的任务private Runnable task;Worker(Runnable task) {this.task = task;}/*** 执行task任务, 如果task为null, 则从workQueue工作队列中获取任务* 如果工作队列中不存在等待执行的任务, 终止当前Worker工作线程*/@Overridepublic void run() {while (task != null || (task = workQueue.take()) != null) {try {log.info("运行任务");task.run();} catch (Exception e) {e.printStackTrace();} finally {task = null;}}// 移除当前工作线程synchronized (workers) {workers.remove(this);}}}public ThreadPool(int coreSize, int capacity) {this.coreSize = coreSize;this.capacity = capacity;this.workQueue = new BlockingQueue<>(capacity);}public ThreadPool(int coreSize, int capacity, RejectPolicy rejectPolicy) {this(coreSize, capacity);this.rejectPolicy = rejectPolicy;}/*** 执行task任务. 如果当前线程数量 < coreSize, 创建线程执行* 否则加入阻塞队列. 如果阻塞队列已满, 执行当前拒绝策略* @param task 需要执行任务*/public void execute(Runnable task) {if (task == null)throw new NullPointerException("task is null");synchronized (workers) {if (workers.size() < coreSize) {// 创建线程执行(我们倾向于创建新线程来执行任务, 而非已创建线程)log.info("创建worker");Worker worker = new Worker(task);workers.add(worker);worker.start(); // 千万别写成调用run方法, 否则主线程会阻塞(run不会开启线程)}else {log.info("添加阻塞队列");// 添加阻塞队列// workQueue.put(task);// 添加失败if ( !workQueue.tryPut(task)) {// 执行拒绝策略rejectPolicy.reject(task, workQueue);}}}}
}
Test
import lombok.extern.slf4j.Slf4j;@Slf4j
public class Test {public static void main(String[] args) throws InterruptedException {ThreadPool threadPool = new ThreadPool(2, 5);for (int i = 0; i < 10; i++) {int j = i;threadPool.execute(() -> {try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}log.info(String.valueOf(j));});}}
}
Test3
@Slf4j
public class Test3 {public static void main(String[] args) throws InterruptedException {ThreadPool threadPool = new ThreadPool(2, 5, (task, workQueue) -> {log.info("任务丢弃");});for (int i = 0; i < 10; i++) {int j = i;threadPool.execute(() -> {try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}log.info(String.valueOf(j));});}}
}