文章目录
- 目标
- 工具
- 特征工程和多项式回归概述
- 多项式特征
- 选择功能
- 备用视图
- 扩展功能
- 复杂的功能
- 恭喜!
目标
在本实验中,你将:探索特征工程和多项式回归,它们允许您使用线性回归的机制来拟合非常复杂,甚至非常非线性的函数。
工具
您将利用在以前的实验中开发的函数以及matplotlib和NumPy。
import numpy as np
import matplotlib.pyplot as plt
from lab_utils_multi import zscore_normalize_features, run_gradient_descent_feng
np.set_printoptions(precision=2) # reduced display precision on numpy arrays
特征工程和多项式回归概述
开箱即用,线性回归提供了一种构建如下形式模型的方法:
fw,b= w0x0 + w1x1+…+ wn -1xn-1+ b (1)
如果你的特征/数据是非线性的,或者是特征的组合呢?例如,房价不倾向于与居住面积成线性关系,而是对非常小或非常大的房子不利,导致上图所示的曲线。我们如何使用线性回归的机制来拟合这条曲线呢?回想一下,我们拥有的“机制”是修改(1)中的参数w, b以使方程与训练数据“拟合”的能力。然而,无论对(1)中的w,b进行多少调整,都无法实现对非线性曲线的拟合。
多项式特征
上面我们考虑的是一个数据是非线性的场景。我们试着用已知的知识来拟合非线性曲线。我们从一个简单的二次方程开始:
y=1+x^2
你对我们使用的所有例程都很熟悉。可以在lab_utils.py文件中查看它们。我们将使用np.c […]这是一个NumPy例程,用于沿着列边界进行连接。
# create target data
x = np.arange(0, 20, 1)
y = 1 + x**2
X = x.reshape(-1, 1)model_w,model_b = run_gradient_descent_feng(X,y,iterations=1000, alpha = 1e-2)plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("no feature engineering")
plt.plot(x,X@model_w + model_b, label="Predicted Value"); plt.xlabel("X"); plt.ylabel("y"); plt.legend(); plt.show()
X@model_w + model_b: 这是执行矩阵乘法的操作。X是一个二维数组(可能是通过x.reshape(-1,
1)得到的),model_w是模型权重,model_b是模型截距。这里计算的是线性回归模型的预测值y,即y = Xw + b。

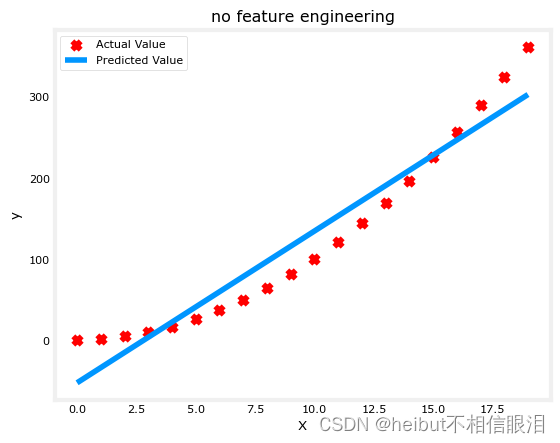
不出所料,不太合适。需要的是y = w0x0^2+b这样的东西,或者多项式特征。要实现这一点,您可以修改输入数据来设计所需的特性。如果您将原始数据与x值平方的版本交换,那么您可以实现y = wox + b。让我们尝试一下。将x换成下面的x**2:
# create target data
x = np.arange(0, 20, 1)
y = 1 + x**2# Engineer features
X = x**2 #<-- added engineered feature
X = X.reshape(-1, 1) #X should be a 2-D Matrix
model_w,model_b = run_gradient_descent_feng(X, y, iterations=10000, alpha = 1e-5)plt.scatter(x, y, marker='x', c='r', label="Actual Value");
plt.title("Added x**2 feature")
plt.plot(x, np.dot(X,model_w) + model_b, label="Predicted Value");
plt.xlabel("x"); plt.ylabel("y");
plt.legend();
plt.show()

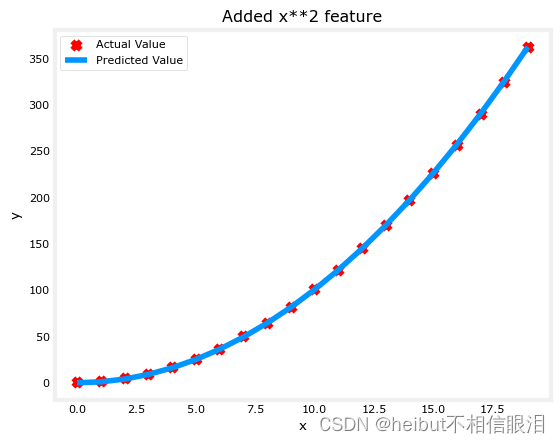
太棒了!近乎完美的契合。注意图正上方的w和b的值:w, b通过梯度下降找到:w:[1.], b: 0.0490。梯度下降法将w, b的初始值修改为(1.0,0.049)或
y = 1 * x^2+ 0.049
的模型,非常接近我们的目标y = 1 *x^2 + 1。如果你把它放久一点,它可能是一个更好的匹配。
选择功能
上面,我们知道x2项是必需的。需要哪些特性可能并不总是很明显。我们可以添加各种潜在的特性来尝试找到最有用的。例如,如果我们改为:
y= w0x0 + w1x 1^2 +w2x2 ^3 +b
呢?运行下一个单元格。
# create target data
x = np.arange(0, 20, 1)
y = x**2# engineer features .
X = np.c_[x, x**2, x**3] #<-- added engineered feature
model_w,model_b = run_gradient_descent_feng(X, y, iterations=10000, alpha=1e-7)plt.scatter(x, y, marker='x', c='r', label="Actual Value");
plt.title("x, x**2, x**3 features")
plt.plot(x, X@model_w + model_b, label="Predicted Value");
plt.xlabel("x");
plt.ylabel("y");
plt.legend();
plt.show()
np: 指的是NumPy库,它是Python中用于科学计算的一个基础库,提供了大量的数学函数和操作数组的工具。
c_[]: 是NumPy中的一个对象,用于沿第二轴(即列)连接数组。它允许你将多个一维数组作为列拼接成一个二维数组。

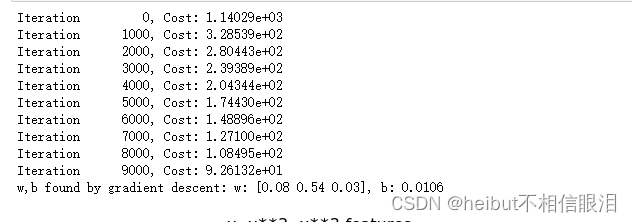
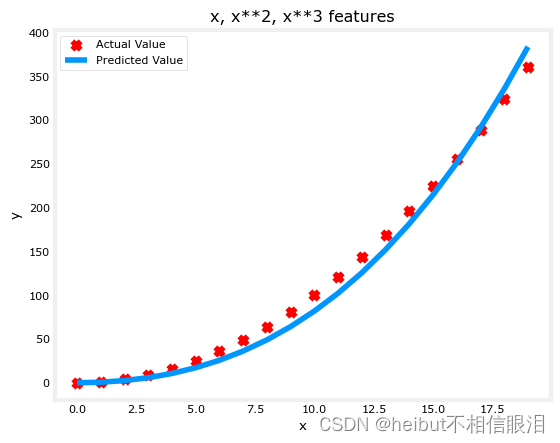
注意w=[0.08 0.54 0.03]和b的值为0.0106,这意味着拟合/训练后的模型为:
0.08x+0.54x2 +0.03x2+0.0106
梯度下降通过增加相对于其他数据的wi项来强调最适合x2数据的数据。如果你要跑很长时间,它会继续减少其他条款的影响。
梯度下降是通过强调其相关参数来为我们选择“正确”的特征
让我们回顾一下这个想法:
- 最初,特征被重新缩放,以便它们彼此比较
- 更小的权重值意味着更不重要/正确的特征,在极端情况下,当权重变为零或非常接近零时,相关特征有助于将模型拟合到数据。
- 上面,在拟合之后,与x2特征相关的权值比x或x3的权值大得多,因为它在拟合数据时最有用。
备用视图
上面,多项式特征是根据它们与目标数据的匹配程度来选择的。另一个考虑这个问题的方法是注意我们仍然在使用线性回归一旦我们创建了新的特性。鉴于此,最佳特征将是相对于目标的线性特征。这是最好的理解举个例子。
# create target data
x = np.arange(0, 20, 1)
y = x**2# engineer features .
X = np.c_[x, x**2, x**3] #<-- added engineered feature
X_features = ['x','x^2','x^3']
fig,ax=plt.subplots(1, 3, figsize=(12, 3), sharey=True)
for i in range(len(ax)):ax[i].scatter(X[:,i],y)ax[i].set_xlabel(X_features[i])
ax[0].set_ylabel("y")
plt.show()
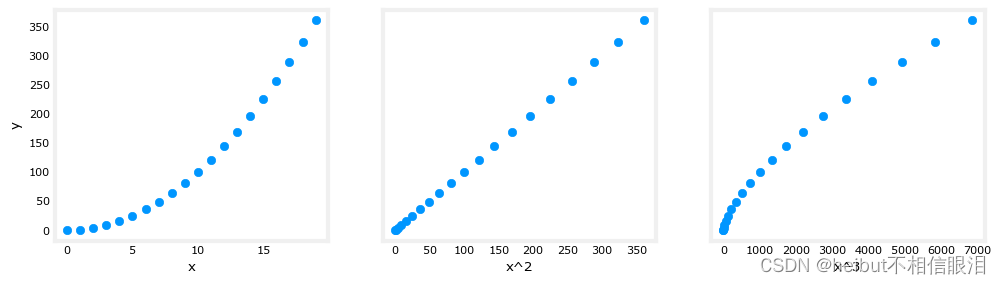
上面,很明显,映射到目标值y的x2特征是线性的。然后,线性回归可以很容易地使用该特征生成模型。
扩展功能
如上一个实验所述,如果数据集具有明显不同尺度的特征,则应将特征缩放应用于速度梯度下降。在上面的例子中,有x, x2和x3,它们自然会有非常不同的尺度。让我们把z分数归一化应用到我们的例子中。
# create target data
x = np.arange(0,20,1)
X = np.c_[x, x**2, x**3]
print(f"Peak to Peak range by column in Raw X:{np.ptp(X,axis=0)}")# add mean_normalization
X = zscore_normalize_features(X)
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X,axis=0)}")
np.ptp() 函数是 NumPy 库中的一个函数,用于计算数组沿指定轴的数值范围(最大值与最小值之差)。这个函数名“ptp”代表“peak to peak”,直译为“峰到峰”,即从最低点到最高点的距离。当你对数据集进行分析时,了解数据的范围可以帮助你更好地理解数据的分布情况。

现在我们可以用一个更激进的alpha值再试一次:
x = np.arange(0,20,1)
y = x**2X = np.c_[x, x**2, x**3]
X = zscore_normalize_features(X) model_w, model_b = run_gradient_descent_feng(X, y, iterations=100000, alpha=1e-1)plt.scatter(x, y, marker='x', c='r', label="Actual Value");
plt.title("Normalized x x**2, x**3 feature")
plt.plot(x,X@model_w + model_b, label="Predicted Value");
plt.xlabel("x");
plt.ylabel("y");
plt.legend();
plt.show()
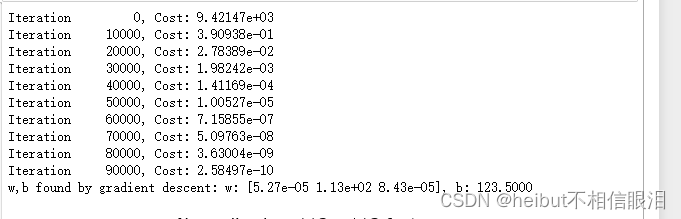
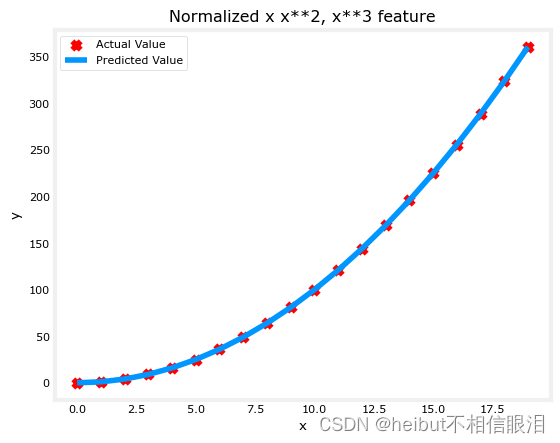
w: [5.27e-05 1.13e+02 8.43e-05], b: 123.5000
特征缩放允许更快地收敛。再次注意w的值,w项,也就是x2项是最重要的。梯度下降法几乎消除了x3项。
复杂的功能
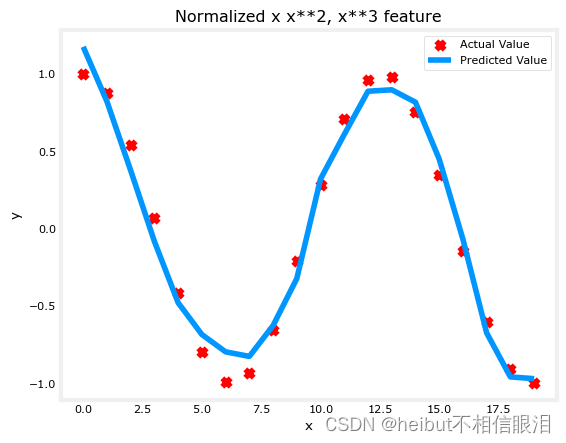
通过特征工程,即使是非常复杂的函数也可以建模:
x = np.arange(0,20,1)
y = np.cos(x/2)X = np.c_[x, x**2, x**3,x**4, x**5, x**6, x**7, x**8, x**9, x**10, x**11, x**12, x**13]
X = zscore_normalize_features(X) model_w,model_b = run_gradient_descent_feng(X, y, iterations=1000000, alpha = 1e-1)plt.scatter(x, y, marker='x', c='r', label="Actual Value");
plt.title("Normalized x x**2, x**3 feature")
plt.plot(x,X@model_w + model_b, label="Predicted Value");
plt.xlabel("x");
plt.ylabel("y");
plt.legend();
plt.show()
恭喜!
在这个实验中,你:学习了如何使用特征工程对复杂的,甚至是高度非线性的函数进行线性回归建模认识到在进行特征工程时应用特征缩放的重要性




![【动态规划.3】[IOI1994]数字三角形 Number Triangles](https://img-blog.csdnimg.cn/direct/7931675d8d7f4db5a0d78e51aae6ff94.png)

![[Buuctf] [MRCTF2020]Transform](https://img-blog.csdnimg.cn/direct/82715af271054cf19779368166013c2e.png)