欢迎来到白刘的领域 Miracle_86.-CSDN博客
系列专栏 C语言知识
先赞后看,已成习惯
创作不易,多多支持!

目录
一、数组名的理解
二、使用指针访问数组
三、一维数组传参本质
四、冒泡排序
五、二级指针
六、指针数组
七、指针数组模拟二维数组
一、数组名的理解
在上一篇博客中,我们在使用指针访问数组时,有这样的代码:
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int *p = &arr[0];详见:灵魂指针,教给(一)-CSDN博客
这里我们使用了&arr[0]的方式拿到了数组的首元素地址,但是数组名本身就是地址,而且是数组首元素的地址,我们可以做个测试,来看下面这段代码:
#include <stdio.h>
int main()
{int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };printf("&arr[0] = %p\n", &arr[0]);printf("arr = %p\n", arr);return 0;
}第一个printf打印arr[0]的地址,第二个打印数组名代表的地址。
来看运行结果:

我们可以发现,这两个地址一模一样,这也证明了,数组名就是数组首元素(第一个元素)的地址。
我们再来看一段代码:
#include <stdio.h>
int main()
{int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };printf("%d\n", sizeof(arr));return 0;
}我们在前面讲到,指针(地址)的大小是4或者8个字节,而arr是数组名,是数组首元素的地址,那这个应该是打印4或者8,但是这段代码的结果为40。这是为什么呢?
确实,arr作为数组名是数组首元素的地址,但是这里有两个例外:
sizeof(数组名),在sizeof中单独存放数组名,这里的数组代表整个数组,计算的是整个数组的大小,单位为字节
&数组名,这里的数组名也表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素地址是有区别的)。
除了上述两个例外,其它任何位置出现数组名,都是代表的数组首元素地址。
那我们再来看一段代码:
#include <stdio.h>
int main()
{int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };printf("&arr[0] = %p\n", &arr[0]);printf("arr = %p\n", arr);printf("&arr = %p\n", &arr);return 0;
}来看结果:

我们发现,三个地址完全相同,那arr和&arr到底有啥区别呢?别着急,我们继续来做个测试:
#include <stdio.h>
int main()
{int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };printf("&arr[0] = %p\n", &arr[0]);printf("&arr[0]+1 = %p\n", &arr[0]+1);printf("arr = %p\n", arr);printf("arr+1 = %p\n", arr+1);printf("&arr = %p\n", &arr);printf("&arr+1 = %p\n", &arr+1);return 0;
}来看运行结果:
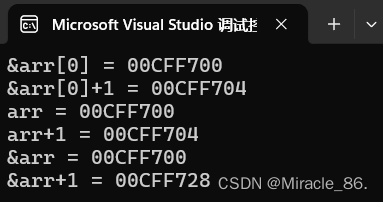
这里挑了一组比较明显的结果,我们可以发现&arr[0]和&arr[0]+1之间差了4个字节,arr和arr+1之间也差了4个字节,这是因为它们都是数组首元素的地址,+1的意思是跳过一个元素。
但是&arr和&arr+1差了有40个字节,因为&arr是数组的地址,而arr有10个元素,每个元素的大小是4个字节,所以arr的大小为40个字节,+1是跳过整个数组。
讲到这,想必大家都明白数组名的意义了吧。
二、使用指针访问数组
前面做好铺垫,我们就可以很容易地使用指针访问数组了。
#include <stdio.h>
int main()
{int arr[10] = {0};//输⼊int i = 0;int sz = sizeof(arr)/sizeof(arr[0]);//输⼊int* p = arr;for(i=0; i<sz; i++){scanf("%d", p+i);//scanf("%d", arr+i);//也可以这样写}//输出for(i=0; i<sz; i++){printf("%d ", *(p+i));}return 0;
}创建了一个int类型的指针p,指向数组arr的首元素的地址,然后p+i代表指向第i个元素,再对其解引用进行输出。
上述代码搞清之后,我们不妨大胆想象一下,,既然arr和p是等价的,那我们既然可以写arr[i],那可不可以写p[i]呢?答案是可以,来看代码:
#include <stdio.h>
int main()
{int arr[10] = {0};//输⼊int i = 0;int sz = sizeof(arr)/sizeof(arr[0]);//输⼊int* p = arr;for(i=0; i<sz; i++){scanf("%d", p+i);//scanf("%d", arr+i);//也可以这样写}//输出for(i=0; i<sz; i++){printf("%d ", p[i]);}return 0;
}运行结果,毫无疑问是没有问题的:
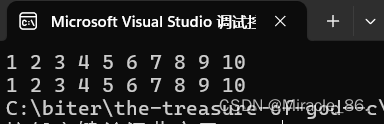
同理arr[i]也等价于*(arr+i),数字元素的访问在编译器处理的时候,也是转换为首元素地址+偏移量求出元素地址,然后解引用访问。
三、一维数组传参本质
数组我们已经很熟悉了,我们在之前也有所提到过,数组可以传递给函数,如果有忘了的老铁可以进入下方传送门:
C语言中的工具箱——函数-CSDN博客
那今天我们来认真介绍一下一维数组传参的本质 。
首先,引出一个问题,我们之前计算数组元素个数,都是在函数外部的,那我们在函数内部计算个数可以吗?
#include <stdio.h>
void test(int arr[])
{int sz2 = sizeof(arr)/sizeof(arr[0]);printf("sz2 = %d\n", sz2);
}
int main()
{int arr[10] = {1,2,3,4,5,6,7,8,9,10};int sz1 = sizeof(arr)/sizeof(arr[0]);printf("sz1 = %d\n", sz1);test(arr);return 0;
}我们来看运行结果:

可以看出在函数内部没有得到正确的数组元素个数。
所以我们来学习数组传参的本质,刚刚我们介绍过:数组名是数组首元素的地址;那么在数组传参的时候,传递的是数组名,也就是说数组传参的本质上是传递数组首元素的地址。
所以函数形参理论上应该使用指针变量来接收首元素地址。你们函数内部我们在写sizeof(arr)计算的是一个地址的大小而不是数组的大小(单位:字节)。正是因为函数的参数部分的本质是指针,所以在函数内部是没法求数组元素个数的。
总结:一维数组传参,形参可以写成数组,也可以写成指针。
四、冒泡排序
排序想必大家都知道是什么意思,但是这个冒泡是什么意思呢?咕嘟咕嘟冒泡泡嘛?事实上,确实可以是这样的。
来看下图:

我们在生活中可以看见这种现象:烧开水冒的泡泡或者是我们在水下吐泡泡,从下往上移动,越接近水面泡泡会越来越大。上面这个动图也是如此,我们看5是最大的数字,所以我们要让它慢慢浮到后面(或者前面)。
冒泡排序的核心思想:两两相邻元素进行比较。其实也可以总结为:两层循环,一层判断。
直接上代码:
//⽅法1
#include<stdio.h>
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{int i = 0;for(i=0; i<sz-1; i++){int j = 0;for(j=0; j<sz-i-1; j++){if(arr[j] > arr[j+1]){int tmp = arr[j];arr[j] = arr[j+1];arr[j+1] = tmp;}}}
}
int main()
{int arr[] = {3,1,7,5,8,9,0,2,4,6};int sz = sizeof(arr)/sizeof(arr[0]);bubble_sort(arr, sz);for(int i=0; i<sz; i++){printf("%d ", arr[i]);}return 0;
}我们来看第二种优化后的方法:
//⽅法2 - 优化
#include<stdio.h>
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{int i = 0;for (i = 0; i < sz - 1; i++){int flag = 1;//假设这⼀趟已经有序了int j = 0;for (j = 0; j < sz - i - 1; j++){if (arr[j] > arr[j + 1]){flag = 0;//发⽣交换就说明,⽆序int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}if (flag == 1)//这⼀趟没交换就说明已经有序,后续⽆序排序了break;}
}
int main()
{int arr[] = { 3,1,7,5,8,9,0,2,4,6 };int sz = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, sz);for (int i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}由于第一种可能存在无效遍历,所以我们第二种方法设置了一个flag变量来判断是否有序。
五、二级指针
二级指针,听起来很牛逼的样子,但实际上还是挺好理解的。我们说指针变量,它其实也是个变量,是变量就有地址,那它的地址存放在哪里呢?
这就引出了二级指针。
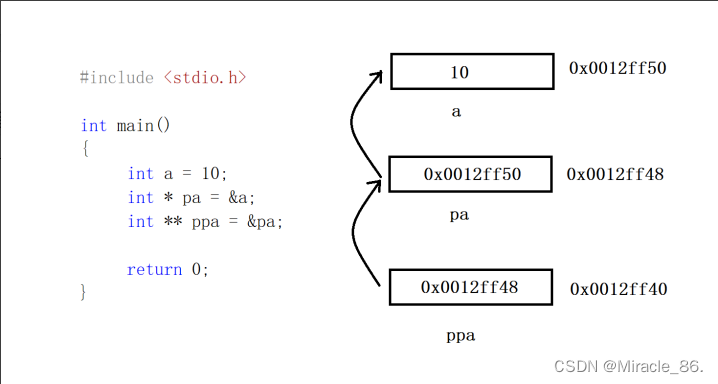
上图中的ppa就是指向指针pa的二级指针,存放的是pa的地址,它的类型是int * *,
**ppa = 30,等价于*pa = 30,等价于a = 30。
六、指针数组
指针数组这个名字,很抽象,你说它到底是指针还是数组?答案是数组,其实它是这么理解的:(装着)指针(的)数组。后面我们还会学到一个非常非常容易和它混淆的东西叫:数组指针。我们中国汉语一般是习惯把定于放在中心词的前面,像红苹果、小朋友...这俩玩意也不例外,数组指针和指针数组,谁在后面就是谁。
我们还可以类比一下其它类型的数组,像整型数组和字符数组。
 指针数组是用来存放指针(地址)的。
指针数组是用来存放指针(地址)的。
如下图:
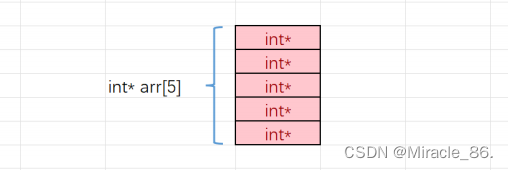
指针数组的每个元素是地址,又可以指向一块区域。
指针数组有什么用呢?我们接着往下学习。
七、指针数组模拟二维数组
既然指针数组可以存放指针,那我每个指针都再指向一个地址,是不是就模拟出二维数组了,因为二维数组的本质是元素为一维数组的数组,我们在之前也有提过:
C语言中的百宝箱——数组(2)-CSDN博客
画图的话就是如下:
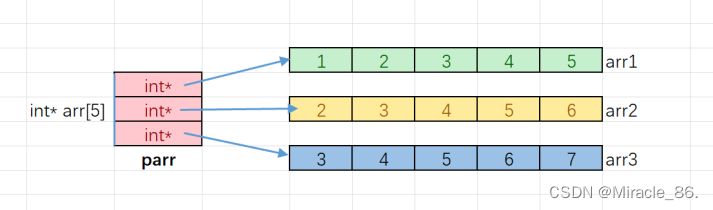
我们来代码实现一下:
#include <stdio.h>
int main()
{int arr1[] = { 1,2,3,4,5 };int arr2[] = { 2,3,4,5,6 };int arr3[] = { 3,4,5,6,7 };//数组名是数组⾸元素的地址,类型是int*的,就可以存放在parr数组中int* parr[3] = { arr1, arr2, arr3 };int i = 0;int j = 0;for (i = 0; i < 3; i++){for (j = 0; j < 5; j++){printf("%d ", parr[i][j]);}printf("\n");}return 0;
}运行结果如下:
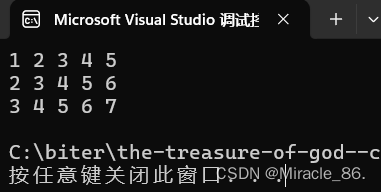
注:上述代码仅是模拟出二维数组的效果,并非完全是二维数组,因为每一行是非连续的。


![[C语言]——分支和循环(4)](https://img-blog.csdnimg.cn/direct/d0a718175c6245c2a7094d5c2b9fbc19.png)



](https://img-blog.csdnimg.cn/direct/ed23e46ddb6140919ce24c611926718c.png)