前言
文档的智能解析与理解成为为知识管理的关键环节。特别是在处理扫描文档时,如何有效地理解和提取表单信息,成为了一个具有挑战性的问题。扫描文档的复杂性,包括其结构的多样性、非文本元素的融合以及手写与印刷内容的混合,都为自动化处理带来了难题。本文记录了基于Transformer架构的文档理解模型常见方法和相关数据集。
基于Transformer架构的文档理解模型
-
Layout-Visual Fusion Models:这类模型专注于整合文档图像的布局和视觉信息与文本内容,以增强文档理解。这些模型结合了边界框坐标、图像嵌入和空间关系等特征,以捕获文档的结构布局。常见的有:
-
LayoutLM:这是第一个将文本级文档信息(使用WordPiece表示)与文本的二维位置表示结合进行联合训练的Transformer模型。LayoutLM在微调阶段还加入了图像嵌入,以考虑文档图像中令牌区域的空间布局。它在包括表单理解在内的多个下游任务上取得了新的最先进结果。
-
LayoutLMv2:这是LayoutLM模型的进化版本。关键思想是进一步整合文本、布局和视觉信息之间的关系。作者通过在预训练阶段引入图像信息以及引入新的预训练任务来实现这一点。LayoutLMv2在预训练时使用了空间感知的自注意力机制,这使得模型能够考虑令牌之间的一维和二维关系。
更多的多模态的文档智能方法介绍可以参考之前文章《【文档智能】多模态预训练模型及相关数据集汇总》、《【文档智能】:GeoLayoutLM:一种用于视觉信息提取(VIE)的多模态预训练模型》
-
-
Graph-Based Models:基于图的文本关系建模技术使用图神经网络(GNNs)来捕获文档中文本片段之间的复杂关系。这些模型使用编码器处理文本和视觉特征,然后通过图模块构建一个软邻接矩阵来表示片段之间的成对关系。
-
PICK:PICK模型使用文本和布局特征,结合图学习模块来捕获文档中文本片段之间的关系。PICK的架构由三个独立的模块组成:编码器模块、图模块和解码器模块。编码器模块处理原始文档,将文本和图像特征结合起来。图模块构建一个软邻接矩阵来表示文本片段之间的成对关系。解码器模块结合编码器和图模块的结果,执行序列标注任务。
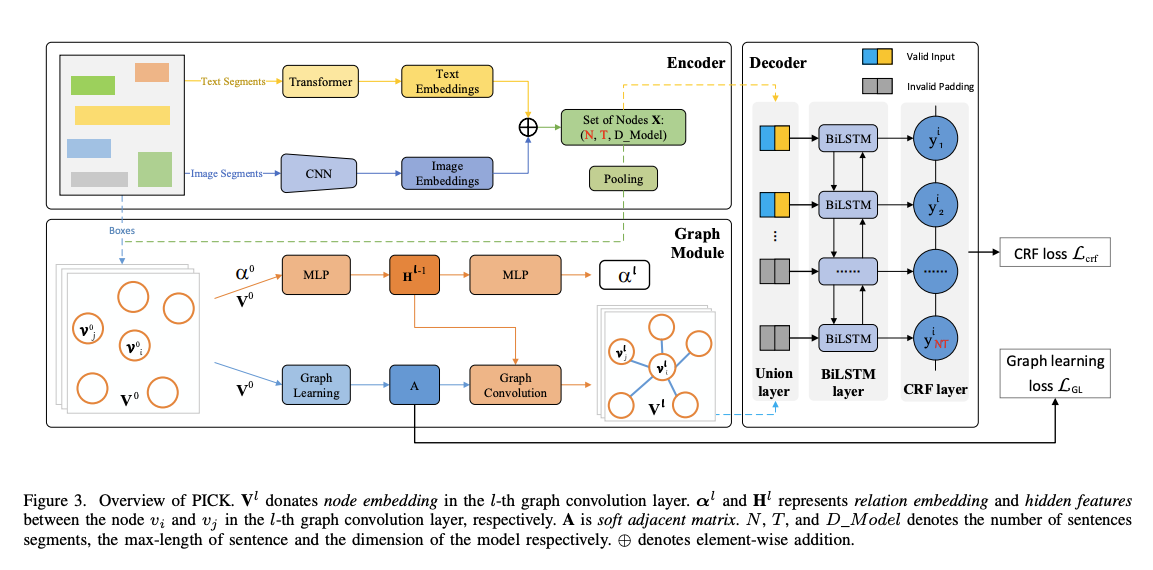
链接:PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks
-
TRIE:TRIE模型将文本阅读和文本理解任务融合到一个端到端训练的网络中。该模型包含文本阅读模块、多模态上下文块和信息提取模块。文本阅读模块使用ResNet CNN和Feature Pyramid Network (FPN)提取输入图像的卷积特征。这些特征随后被用于确定可能的文本区域。多模态上下文块融合文本、位置和视觉特征。信息提取模块使用这些特征来分离实体并提取它们的值。
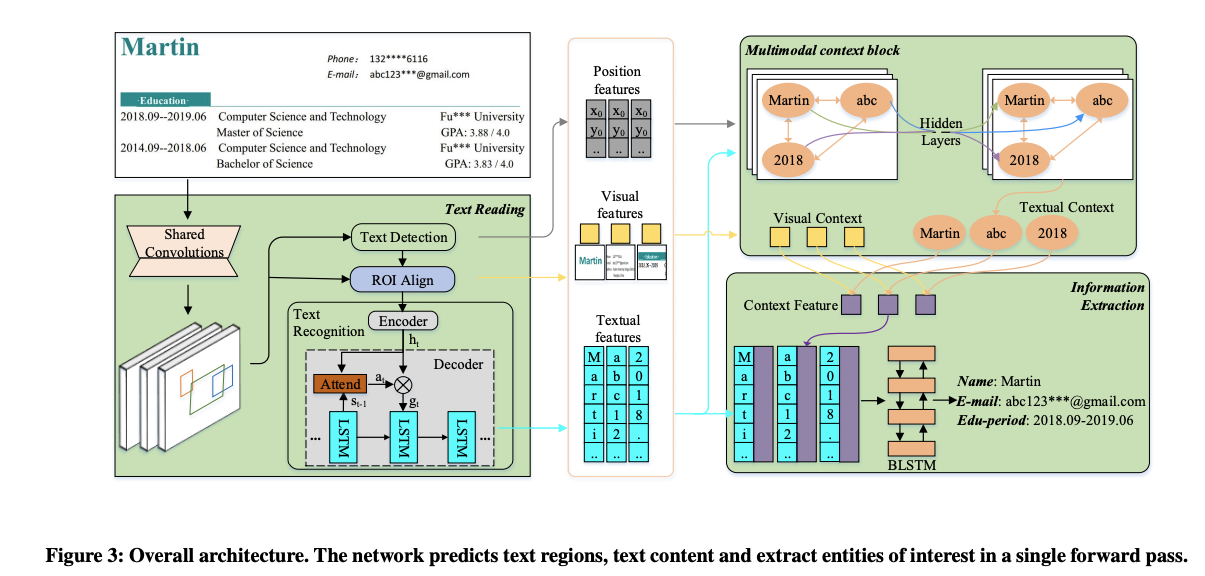
链接:TRIE: End-to-End Text Reading and Information Extraction for Document Understanding
-
-
Multi-Modal Fusion Models:这些大型模型通过引入新机制来更好地整合文本、布局和视觉信息。它们通常对Transformer架构进行修改,例如引入空间感知的自注意力机制,以捕获令牌之间的多维关系。
-
SelfDoc:SelfDoc模型在编码文本特征时采用了一种新颖的方式。它不是在词级别上工作,而是将文本按语义相关组件(如文档对象提案,包括文本块、标题、列表、表格、图形)进行分组,作为模型输入。SelfDoc使用Faster R-CNN在公共文档数据集上进行文档对象检测任务的训练。
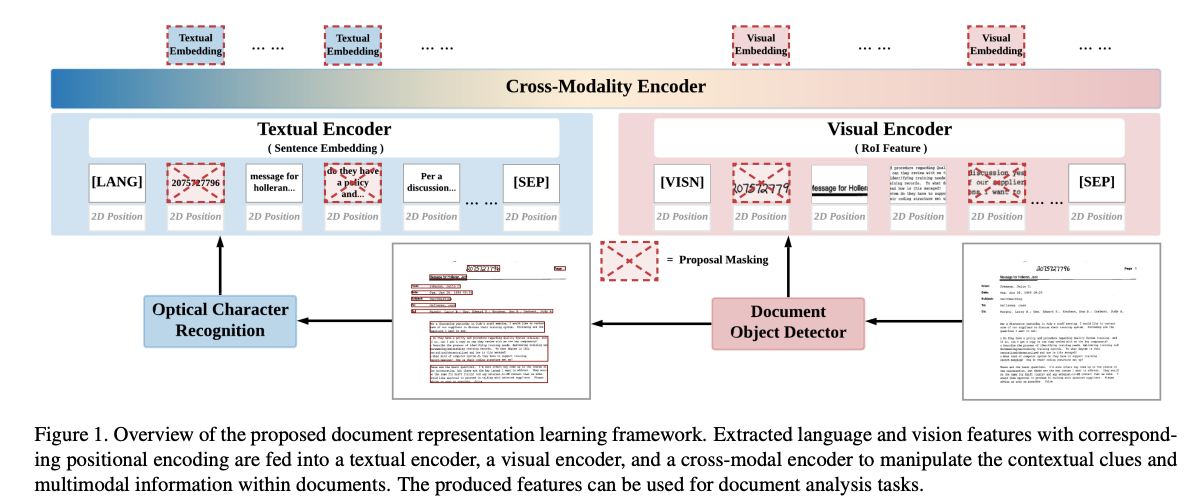
链接:SelfDoc: Self-Supervised Document Representation Learning
-
UniLMv2:UniLMv2允许统一语言模型的预训练,该模型由自编码和部分自回归模型组成。自编码模型类似于BERT,通过上下文预测令牌。部分自回归模型基于掩蔽和伪掩蔽令牌,可以预测一个或多个掩蔽(或伪掩蔽)令牌。
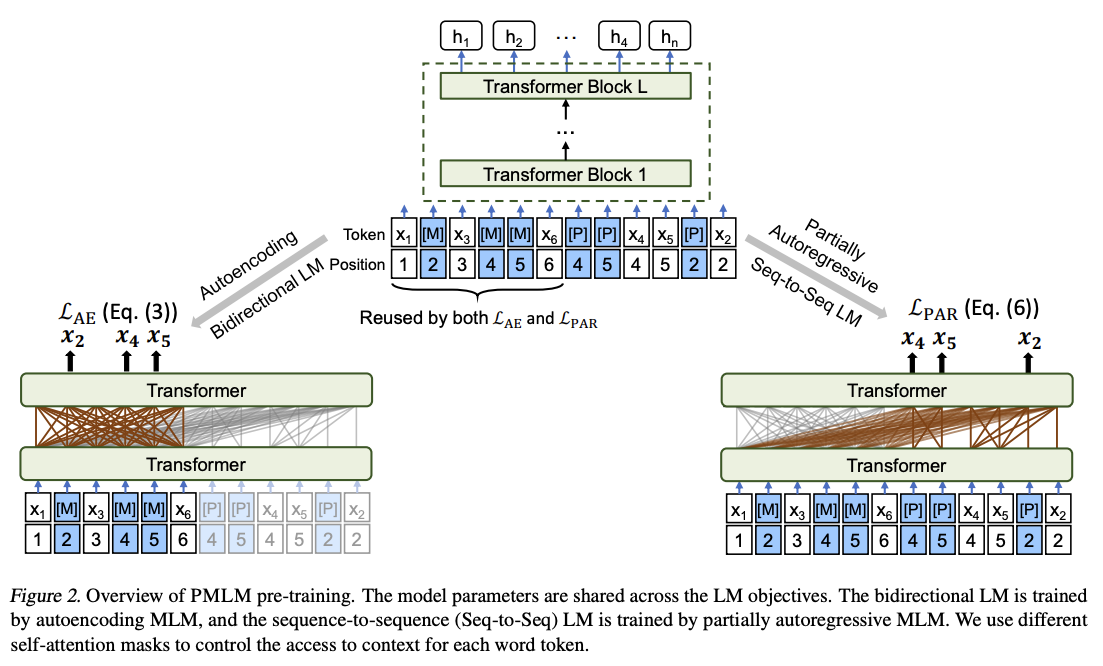
链接:UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
-
DocFormer:DocFormer通过融合视觉和语言网络层来改进多模态训练。它使用ResNet CNN获取视觉特征,并使用OCR结果对文档图像进行文本嵌入。
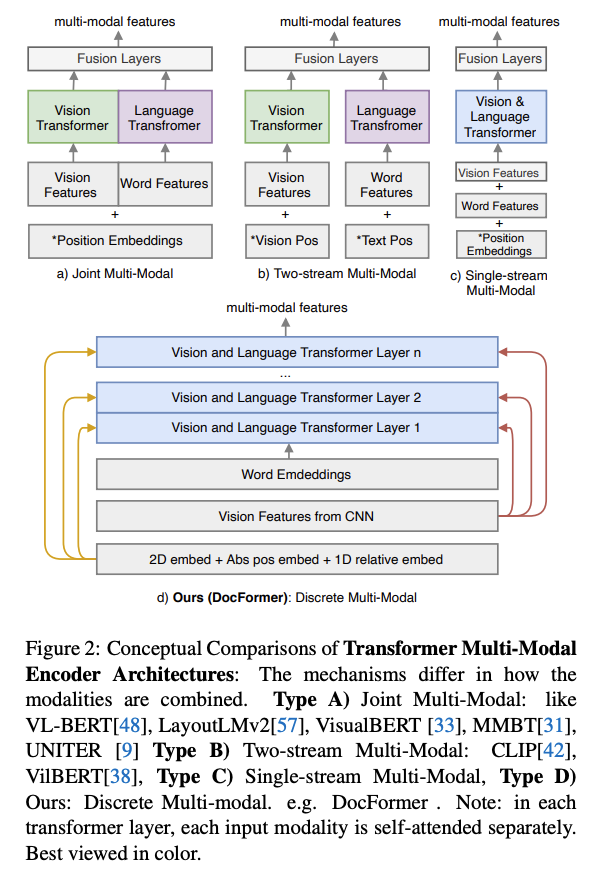
链接:Docformer:End-to-end transformer for document understanding
-
StrucText:StrucText模型使用视觉和文本文档特征的多模态组合。文本嵌入由语言令牌嵌入组成,其中每个文本句子都被连贯地处理以保持语义上下文。此外,还使用ResNet来提取图像特征,并结合序列ID嵌入来利用文本段的顺序。
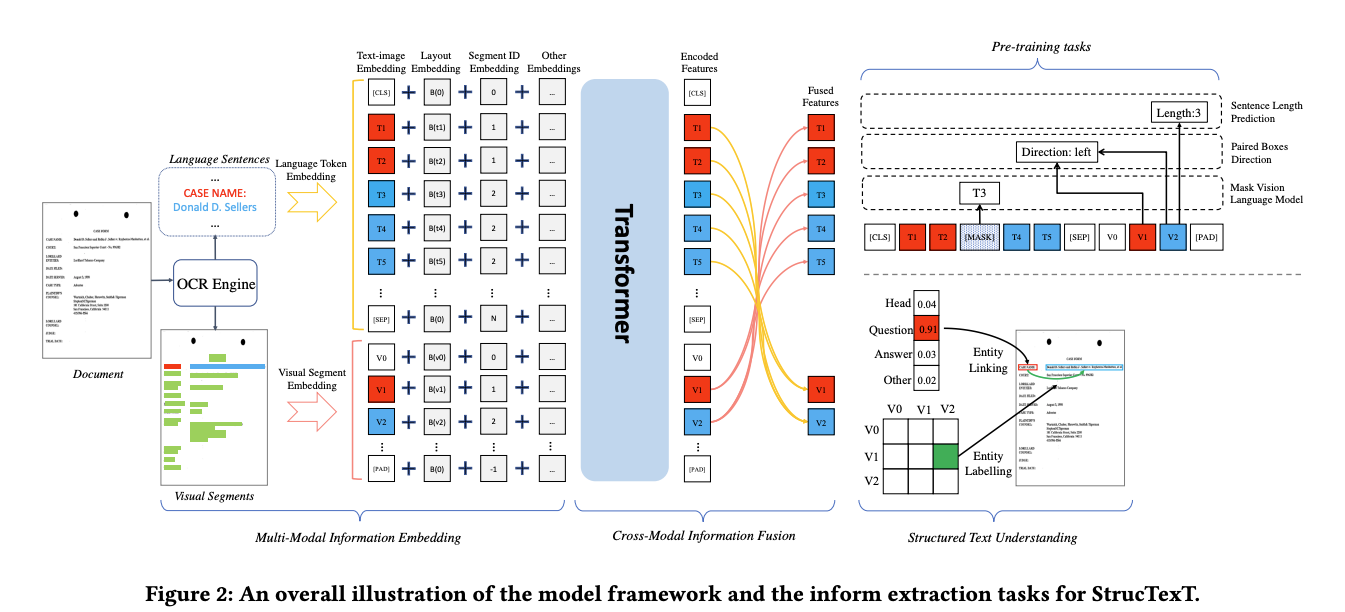
链接:StrucTexT: Structured Text Understanding with Multi-Modal Transformers
-
BROS:BROS模型在预训练时不包含文本图像,而是专注于结合文本和位置信息,忽略布局模态。BROS引入了一个自定义文本序列化器,根据相邻令牌的位置对令牌进行排序。
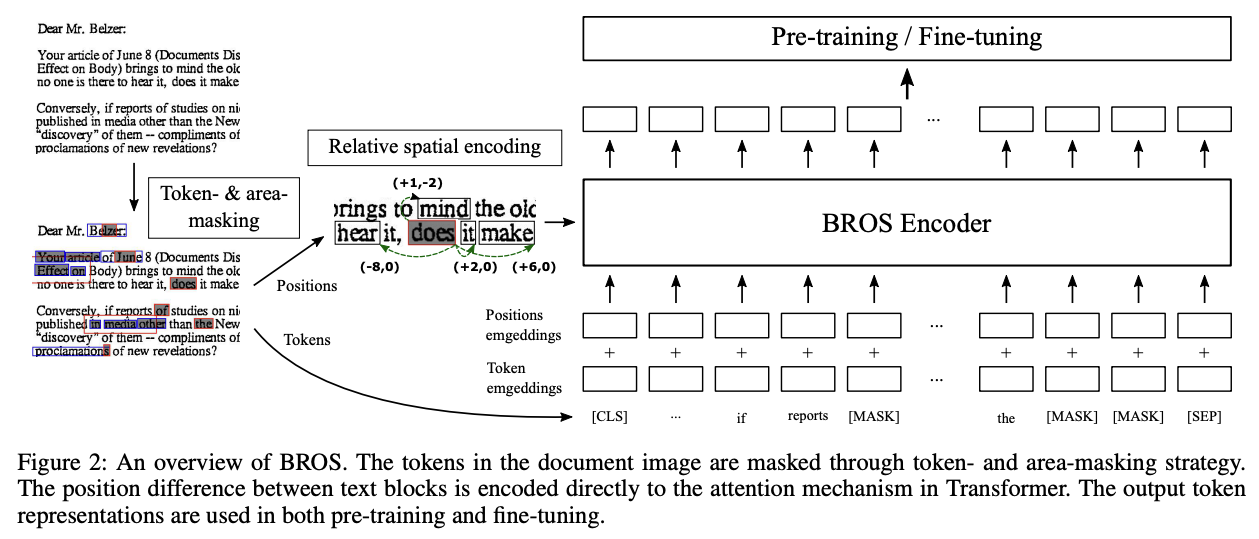
链接:BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
-
-
Cross-Modal Interaction Models:跨模态交互模型促进不同模态(如文本和布局)之间的交互。它们采用注意力机制和融合策略,以实现跨模态信息交换,增强数据的感知和理解。
-
UDoc:UDoc是一个框架,采用了多层门控交叉注意力编码器,能够在单个模型内实现有效的跨模态交互。与传统方法不同,UDoc考虑了文档的复杂性和多样性,结合了文本和视觉特征。UDoc采用三种预训练任务:掩蔽句子建模(MSM)、视觉对比学习(VCL)和视觉-语言对齐(VLA)。
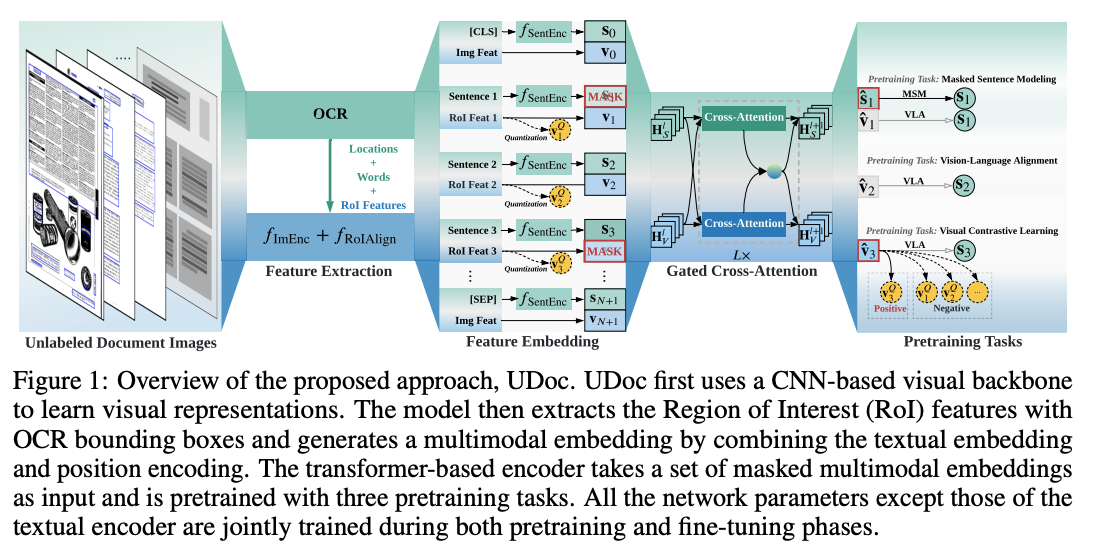
链接:Unified Pretraining Framework for Document
Understanding -
TILT(Text-Image-Layout Transformer):TILT是为了解决文档中超出纯文本的自然语言理解的复杂挑战而设计的神经网络架构。TILT旨在同时捕获布局信息、视觉特征和文本语义,使其能够处理具有丰富空间布局的文档,如表格和表单。

链接:Going full-tilt boogie on document understanding with text-image-layout transformer
-
-
Sequence-to-Sequence Models:编码器-解码器和序列到序列模型涉及编码器处理输入数据和解码器生成序列输出。这些模型可以用于文本生成、翻译和序列预测等任务。
-
GenDoc:GenDoc模型采用了编码器-解码器架构,使其能够适应不同输出格式的多样化下游任务。GenDoc的预训练任务包括掩蔽文本预测、掩蔽图像令牌预测和掩蔽坐标预测,以适应多种模态。该模型整合了模态特定的指令、解耦注意力和混合模态专家(MoE)方法,以有效地捕获每个模态的信息。
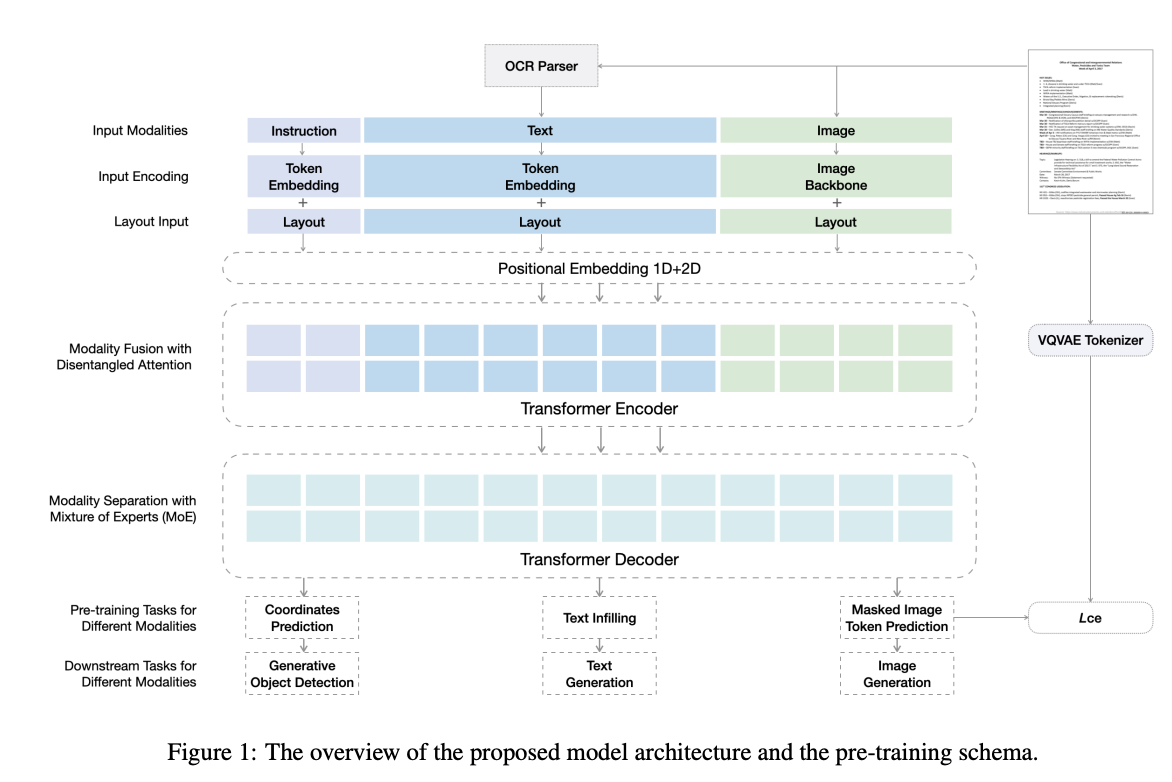
链接:Sequence-to-Sequence Pre-training with Unified Modality Masking for Visual Document Understanding
-
DocFormerv2:DocFormerv2包含一个专门处理文档的多模态编码器,该编码器能够处理文本内容和文档固有的空间特征。模型采用了创新的预训练任务,如token-to-line和token-to-grid预测,以捕获文档布局和结构。这使得模型能够理解文档元素的空间排列。为了有效地整合来自文档图像的空间信息,作者引入了空间特征,编码了位置、大小和类别等关键元素。
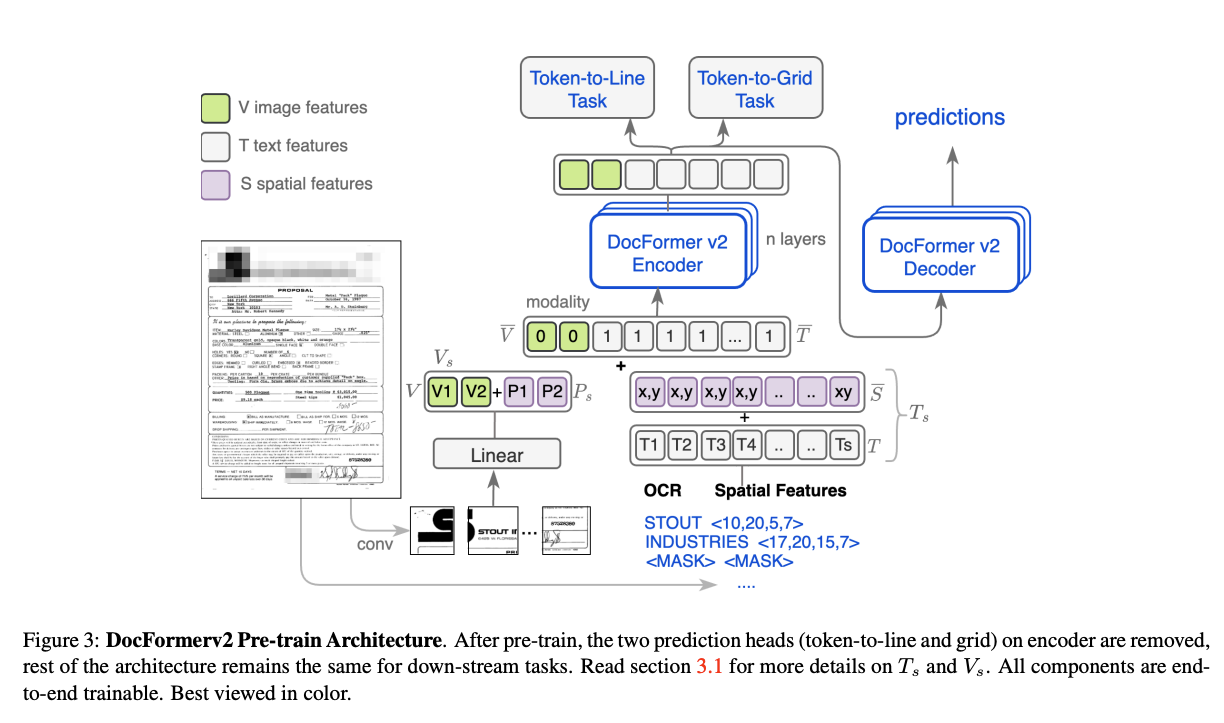
链接:DocFormerv2: Local Features for Document Understanding
-
-
Layout Representation and Language-Independent Models:布局表示模型专注于捕获和表示文档中组件的空间排列。语言独立模型旨在处理多种语言的文档理解。
-
MCLR:MCLR(Multi-Scale Cell-Based Layout Representation)提出了一种基于单元格的布局表示方法。这种方法使用行和列索引来定义文档中组件的位置,与人类阅读习惯相一致,有助于更直观地理解布局结构。MCLR架构包括三个主要组成部分:基于单元格的布局、多尺度布局和数据增强。
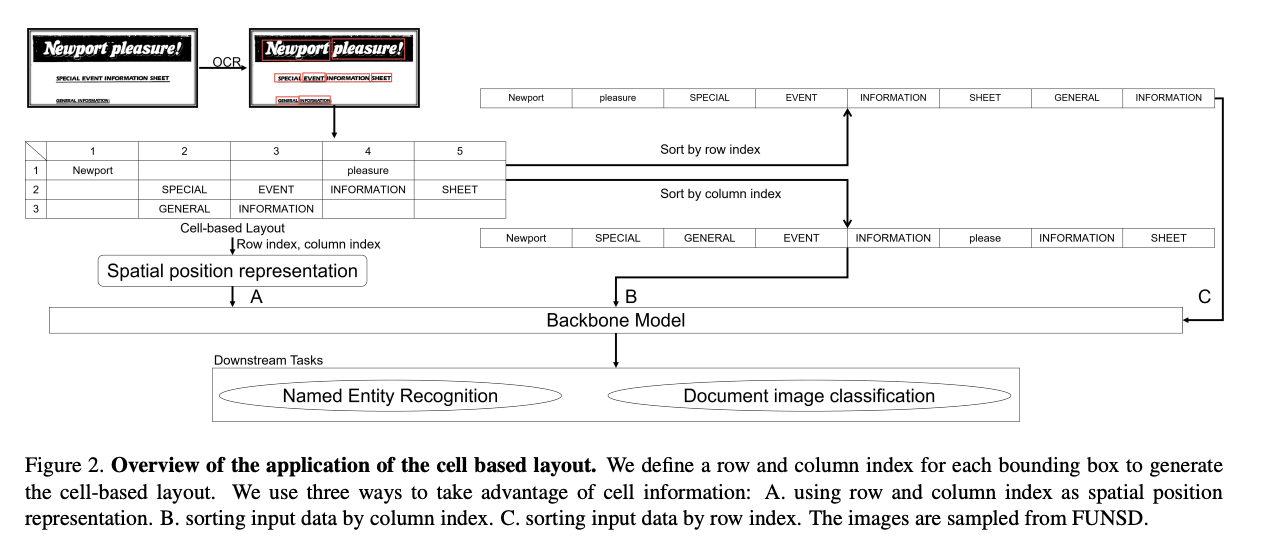
链接:Multi-scale Cell-based Layout Representation for Document Understanding
-
LiLT(Language-independent Layout Transformer):LiLT是一个新颖的框架,它允许在单一语言的文档上进行预训练,然后针对多种语言进行微调。LiLT的核心架构基于并行双流Transformer模型,有效地处理文本和布局信息。在预训练期间,LiLT解耦文档的文本和布局方面,并采用双向注意力互补机制(BiACM)来促进这些模态之间的交互。然后,模型使用现成的预训练文本模型进行下游任务的微调,确保LiLT能够从单语言文档中学习和泛化布局知识到多语言环境中。
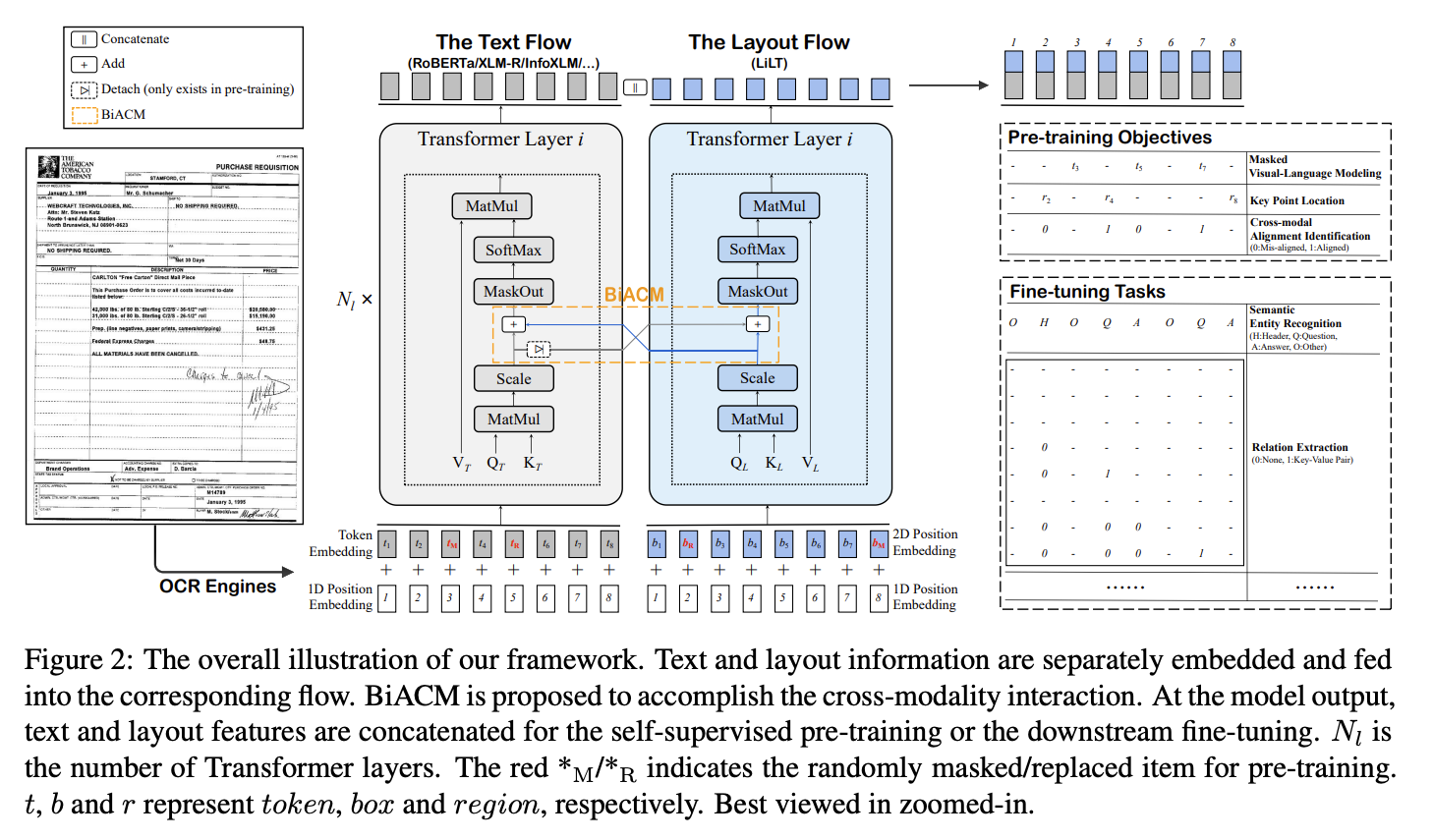
链接:LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding
-
-
Hybrid Transformer Architectures:混合Transformer架构利用创新设计来解决文档理解中的计算复杂性和多样化结构表示的挑战。这些模型通常结合了新的注意力机制,并利用Transformer架构来高效处理多模态信息。
-
StructuralLM:StructuralLM是LayoutLM模型的后继者。与LayoutLM不同,StructuralLM操作的是2D单元格位置嵌入,而不是2D词嵌入。其核心思想是通过分组来更好地捕获词之间的关系。
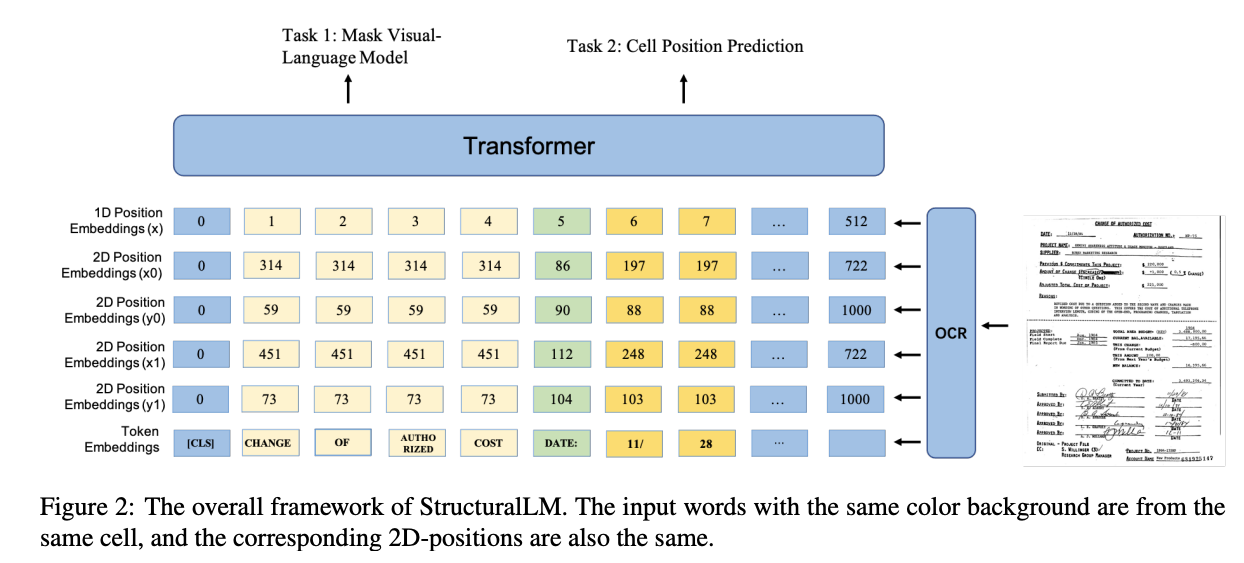
链接:StructuralLM:Structural pre-training for form understanding
-
StrucTexTv2:StrucTexTv2结合了视觉和文本信息,有效地分析文档图像。该模型采用了独特的预训练策略,包括Mask Language Modeling (MLM)和Mask Image Modeling (MIM),利用文本区域级别的掩蔽来预测视觉和文本内容。
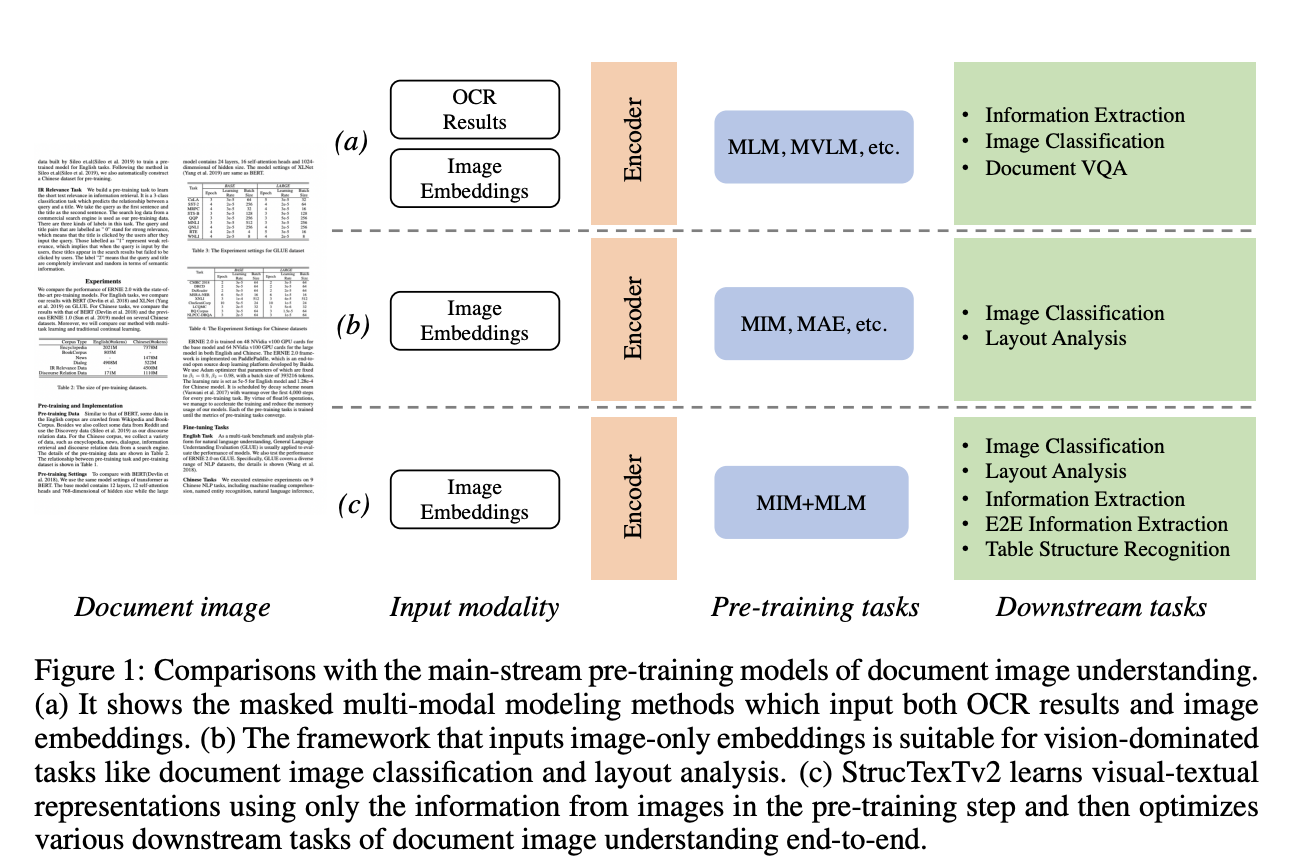
链接:StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
-
Fast-StrucTexT:Fast-StrucTexT是一个创新且高效的基于Transformer的框架,专为文档理解任务设计。该模型通过引入新颖的小时玻璃Transformer架构、模态引导的动态令牌合并和对称交叉注意力(Symmetry Cross-Attention, SCA)来实现高性能和效率。
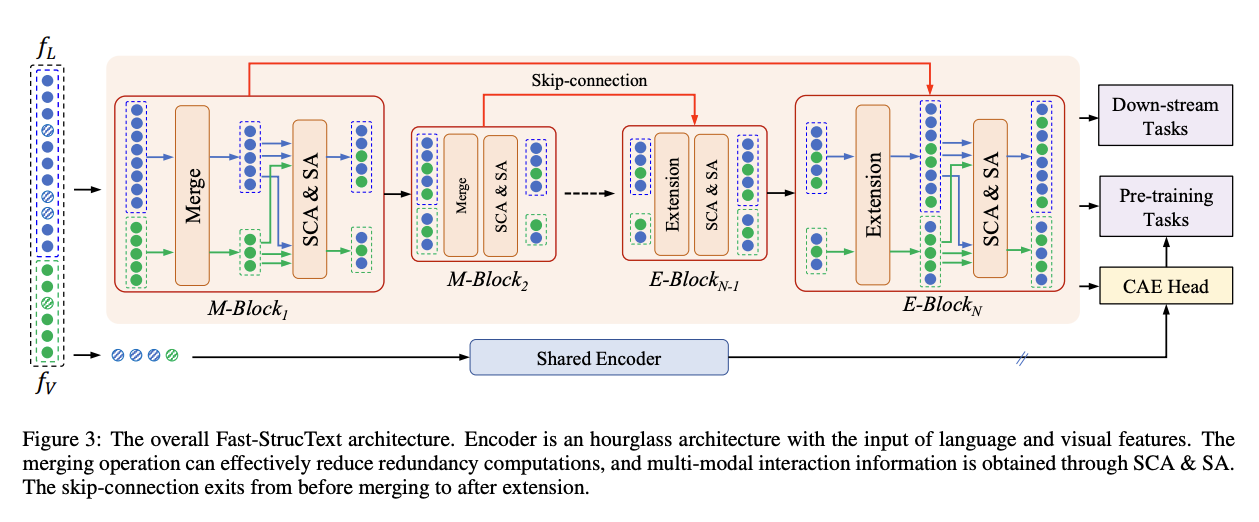
链接:Fast-StrucTexT: An Efficient Hourglass Transformer with Modality-guided Dynamic Token Merge for Document Understanding
-
文档理解数据集
| 数据集 | 文档内容 | 颜色 | 语言 | 文档数 | 文档类型 |
|---|---|---|---|---|---|
| FUNSD | Machine Written / Handwritten | B/W | EN | 199 | Form Documents |
| XFUND | Machine Written / Handwritten | B/W | Multi-lingual | 199/language | Form Documents |
| NAF | Machine written pre-printed text and mostly handwritten | B/W | EN | 865 | Multiple |
| IIT-CDIP | Machine Written, Handwritten | B/W | EN | 6,919,192 | Multiple |
| RVL-CDIP | Machine Written, Handwritten | B/W | EN | 400,000 | Multiple |
| PubLayNet | Machine Written | Color | EN | 364,232 | Medical Literature |
| SROIE | Machine Written with occasional handwriting | Color, B/W | EN | 1,000 | Receipts |
| CORD | Machine Written with occasional handwriting | Color | EN | 1,000 | Receipts |
| DocVQA | Machine Written, Handwritten | Color, B/W | EN | 12,767 | Multiple |
| Form-NLU | Machine Written, Handwritten | Color, B/W | EN | 10,857 | Multiple |
| VRDU | Machine Written | Color, B/W | EN | 2,556 | Ad-buy |
-
RVL-CDIP和IIT-CDIP:Ryerson Vision Lab复杂文档信息处理RVL-CDIP数据集是为了评估深度卷积神经网络(Deep CNNs)而创建的。该数据集是IIT复杂文档信息处理测试集合IIT-CDIP的一个子集,后者包含了来自加州大学旧金山分校的遗产烟草文档图书馆(LTDL)的文档集合。IIT-CDIP由6,919,192个文档记录组成,每个记录都包含OCR识别的文本和各种结构和质量的元数据信息。此外,IIT-CDIP还包含扫描文档的源图像。总的来说,RVL-CDIP数据集包含400,000张灰度图像,分为16个类别(包括表单文档),每个类别有25,000张图像。该数据集分为320k训练图像、40k验证图像和40k测试图像。
链接:https://adamharley.com/
-
FUNSD:是一个用于表单理解任务的集合,包含了199个完全注释的表单,这些表单来自市场营销、科学等多个领域。所有表单都是经过光栅化处理的低分辨率单页表单,并且包含噪声。具体来说,从RVL-CDIP数据集的表单类别中手动挑选了3,200个符合条件的文档,并使用随机抽样的方法最终确定了199个文档。这些文档中的大多数文本内容是机器打印的,这可能不完全反映现实生活中手写内容更为常见的情况。
链接1:https://guillaumejaume.github.io/FUNSD/
FUNSD数据集中的每个表单都编码在一个JSON文件中,其中每个表单被视为一系列相互关联的语义实体(例如,一个名称字段与其对应的答案框相互关联)。每个语义实体包含一个标识符、一个标签、一个边界框、与其他实体的链接列表以及一个单词列表。总的来说,该数据集包含了9,707个语义实体和5,304个关系。另外的有人发现FUNSD数据集中存在一些错误和不一致之处,包括文本内容和边界框的错误以及关系注释的不一致性。他们发布了一个更新版本的数据集来修复发现的问题。
链接2:https://drive.google.com/drive/folders/1HjJyoKqAh-pvtg3eQAmrbfzPccQZ48rz?fbclid=IwAR2ouj5Sh0vkcKAMNfSoZjSM7vSpGnbK-AowWZZ8_Lltcn34hr7_nVcazu0
-
XFUND:是FUNSD数据集的扩展,它将数据集翻译成了七种其他语言,包括中文、日语、西班牙语、法语、意大利语、德语和葡萄牙语。与FUNSD类似,XFUND数据集包含了文档中的语义实体及其相互关系的信息。该数据集是通过从互联网收集上述语言的表单模板手动创建的。每个表单都使用合成信息填写一次,以防止表单重复并避免共享敏感信息。表单可以是数字填写或手写,然后扫描,以再次类似于原始的FUNSD数据集。为了为每个语义实体生成边界框,使用了Microsoft Read API。关系提取则是由注释者手动完成的。总的来说,XFUND数据集包含了每种语言199个表单(总共1,393个),并且分为训练/测试集,其中训练集和测试集分别包含149和50个文档。
链接:https://github.com/doc-analysis/XFUND
-
NAF:NAF数据集是从美国国家档案馆的历史表单图像中创建的注释数据集。这些表单具有不同的布局,并且由于它们的退化和用于打印的机械原因,图像带有噪声。数据集中的表单通常包含英文预印文本和英文输入文本,这些输入文本可能包括手写、打字和盖章内容。总的来说,该数据集包含了865张注释的灰度表单图像。这些图像的注释方式并未公开。NAF数据集被手动分为训练集、验证集和测试集,以确保每个集合包含具有不同表单布局的图像。通过这种方式,作者创造了一个场景,即训练集训练的分类器在测试集中不会遇到之前未见过的表单布局。
-
PubLayNet:是一个自动创建的数据集,通过匹配来自PubMed CentralTM的1,162,856篇科学PDF文章的XML表示和内容。该数据集主要是为了推进文档布局分析研究而创建的,因此它不是专门为表单检测制作的。注释是通过使用PDFMiner软件解析文章的PDF表示,然后将生成的布局与相应的XML表示匹配来创建的。虽然论文中没有提到,但在质量控制过程中似乎已经移除了大多数注释文档,因为只有364,232篇文档在这一步骤后仍然存在于数据集中。该数据集分为340,391页用于训练,11,858页用于开发,以及11,983页用于测试。开发和测试集都从多个不同的期刊中选择,并包含足够数量的表格、列表和图形。
链接:https://github.com/ibm-aur-nlp/PubLayNet
-
SROIE:数据集是作为2019年ICDAR扫描收据OCR和信息提取竞赛的一部分创建的。该数据集包含1000张扫描收据图像,根据三个竞赛任务(文本定位、OCR和关键信息提取)之一,收据有不同的注释。收据的纸张、墨水或打印质量可能较差,分辨率低,包含扫描伪影。此外,收据可能包含复杂布局中的不需要的干扰文本、长文本和小字体大小。每张收据都包含英文字符文本字段,如商品名称和数字字段,如单价和总成本。论文没有提到收据的来源。
链接:https://drive.google.com/drive/folders/1ShItNWXyiY1tFDM5W02bceHuJjyeeJl2
-
CORD:CORD数据集是为了OCR后解析而创建的第一个公共数据集,包含了11,000张来自印度尼西亚商店和餐厅的收据图像。这些图像是通过众包方式收集的。每张图像首先通过一个基于网络的注释工具进行注释,然后进行检查以确保其正确性和符合注释指南。由于担心意外发布敏感个人数据,最终的收据集中对敏感信息(如信用卡号码或个人全名)进行了模糊处理。在11,000张收据中,只有1,000张因这些担忧而对公众开放。根据论文的一位作者的说法,未来的数据发布情况尚不明确。
-
DocVQA:DocVQA是一个包含12,767张文档图像的数据集,用于视觉问答任务。这些文档图像来自UCSF工业文档图书馆。为了确保图像质量合适并且包含表格、表单、列表和图形等元素,这些文档是经过精心挑选的。文档被随机分为训练集、验证集和测试集,比例分别为80%、10%和10%。远程工作人员使用基于网络的三步注释工具为这些文档定义了50,000个问题和答案。在第一步中,工作人员为每个文档定义多达十个问题和答案对。在第二步中,另一位工作人员尝试回答这些定义的问题,而不会看到预定义的答案。如果在第一步的答案与第二步的答案之间没有匹配,那么这个问题将进入第三步,此时论文的作者可以手动编辑问题和答案对。除了问题和答案对,数据集还为每个问题定义了九种问题类型之一。一个问题类型的例子是表格/列表,它指定了回答问题是否需要理解表格或列表。一个问题可以被分配多个问题类型。
-
Form-NLU:Form-NLU是一个全面的数据库,旨在推进基于表单文档的自然语言理解(NLU)领域。该数据库总共包含857张文档图像、6,000个表单键和值,以及4,000个表格键和值。这些文档包括数字、打印和手写的各种表单类型。Form-NLU构成了一个公共可访问的财务表单数据库的一部分,该数据库起源于Form 604,由SIRCA收集。它提供了从2003年到2015年向澳大利亚证券交易所(ASX)提交的重要股东通知的文本记录。作者将注释分为三个专门的子任务:12种类型的键的键注释、成对值的值注释,以及标题、章节和其他组件的非键值注释。每个注释者负责处理一个子任务。
SIRCA:https://asic.gov.au/regulatory-resources/forms/forms-folder/604-notice-of-changeof-%20interests-of-substantial-holder/
ASX:https://www.asx.com.au/
-
VRDU:VRDU是一个用于视觉丰富文档理解的基准数据集,它由两个不同的数据集组成:广告购买表单(Ad-buy Forms)和注册表单(Registration Forms)。这些数据集旨在解决从视觉复杂文档中提取结构化数据的挑战。基准数据集包含五个关键要素:丰富的模式、布局丰富的文档、多样化的模板、高质量的OCR结果和标记级别的注释。该基准数据集专注于三个任务:
-
单模板学习(STL):模型在属于单一模板的文档上进行训练和评估。这意味着训练集、验证集和测试集都包含具有相同结构布局或模板的文档。此任务的目标是评估模型在面对一致且熟悉的文档布局时提取结构化数据的能力。
-
混合模板学习(MTL):模型在来自一组模板的文档上进行训练和评估。训练集、验证集和测试集包括来自不同但预定义模板的文档。此任务评估模型将其学习泛化到多样化文档布局的能力。
-
未见模板学习(UTL):未见模板学习任务挑战模型超越其训练经验。在此任务中,模型在来自模板子集的文档上进行训练,然后在训练期间从未遇到过的模板的文档上进行评估。目标是评估模型适应新的、以前未见过的文档布局和模板的能力。
-
总结
文档理解本质上是一个序列标注任务,类似于命名实体识别(NER),通常被称为关键信息提取(KIE)。本文总结了常见的文档智能理解相关模型方法及数据集,在文档理解领域,涉及到分析不同格式和模态(如文本、图像、表格和图表)的文档内容和结构。语言模型和Transformer架构在各种自然语言处理任务中展示了显著的能力,并且在计算机视觉和音频处理任务中也表现出色,这些模型在文档理解中的变革潜力已被广泛认可。
关于我
余俊晖,NLP炼丹师,目前专注自然语言处理领域研究。曾获得国内外自然语言处理算法竞赛TOP奖项近二十项。现就职于某公司 算法研究员。