目录
- 快捷键
- 基础
- 数据透视图
- 统计某列的值出现的频数
- 数据有效性
- 数据分列
- 运算符顺序
- 文本匹配中的通配符
- 错误的类型(常与IF嵌套使用)
- 函数
- RANK(num, ref, [order])
- MID(str, start, len)
- 逻辑函数
- 混合函数
- 选取整列
- AVERAGEIF(range, criteria, average_range)
- TRIMMEAN(array, percent)
- LARGE(array, k)
- SMALL(array, k)
- FIND( 文本, 范围,数值)
- SUBSTITUTE(text, old_text, new_text[, instance_num])
- ROUND(number, num_digits)
- COUNT
- COUNTA
- COUNTBLANK
- COUNTIF
- DATE
- DAY/MONTH/YEAR/WEEKDAY
- NOW
- TODAY
- 重复字符串REPT
- 颜色
- 实际应用
- 判断某个单元格内容是否在某行之中
- 判断两列是否相等
- 在一列中查找另一列的数据,并且标出来:
- 在excel中生成sql的insert语句
快捷键
-
shift+箭头
将选定区域扩展一个单元格宽度 -
ctrl+shift+箭头
将选定区域扩展到与当前单元格同一行或同一列的最后一个非空白单元格 -
shift+home
将选定区域扩展到行首 -
ctrl+shift+home
将选定区域扩展到工作表的开始(A1) -
ctrl+shift+end
将选定区域扩展到表最后一个使用的单元格 -
shift+pagedown/pageup
将选定区域向上/下扩展一屏 -
ctrl+*
选定有效工作区 -
自动填充
选中要填充的单元格,输入公式,ctrl+enter
比如在N2写上一个-1,要填充N2:N10的话,在
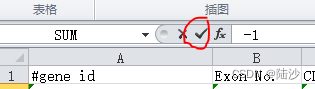
先打勾,然后在左侧(这个叫名称框)写上范围,然后ctrl+enter,然后ctrl+d即可。
-
查看最大行数
ctrl+⬇ -
查看最大列数
ctrl+➡本机
excel2010最大行数是104 8576,最大列数是XFD,也就是16384列。
基础
数据透视图
统计某列的值出现的频数
- 选中一列带表头的数据
- 插入数据透视表
- 在数据透视表字段中,把列名加入行和值区域,此时值区域把计算类型改为计数
数据有效性
数据-数据工具-数据有效性验证
数据分列
选定-数据-分列-按字段长度/符号分列-拆分结果会自动覆盖后几列,所以要确保后面有空位
运算符顺序

文本匹配中的通配符
*:任何字符?:任何单个字符~:解除字符的通配性,如~*就是查找带*这个字符本身的
错误的类型(常与IF嵌套使用)
- ISERROR( )
括号中为:#N/A、#VALUE、#REF、#DIV/0、#NUM、#NAME?或#NULL时为TRUE - ISNA( )
括号中为:#N/A时为TRUE - IFERROR(value, value_if_error)
函数
- =开始输入
- 1-based index
- 函数引用单元格时,默认使用的是相对引用,即扩展时会按相对位置返回计算结果,如果要使用绝对引用,需要输入符号
$或者直接按F4 - 公式求值可以debug公式是否有错误
RANK(num, ref, [order])
num指要找位置的数字,ref是在哪里找,order=0/不写,则是降序,不为0就是升序。
如果有重复值,相同值会有相同的rank,但是会有几个rank被跳过(留空)
MID(str, start, len)
截取字符串的
字符串函数还有LEN, LEFT, RIGHT,VLOOKUP

VLOOKUP中FALSE要求精确匹配,TRUE是近似匹配
逻辑函数
IF, OR, AND
混合函数
Sumif Countif
选取整列
A:A
AVERAGEIF(range, criteria, average_range)
average_range是实际求值得区域,如果忽略会使用range。range是criteria作用的区域。criteria可以使用通配符,也可以是字符串。如果两个范围大小和形状不同,则会使用 average_range 中左上方的单元格作为起始单元格,然后加入与 range 的大小和形状相对应的单元格确定。
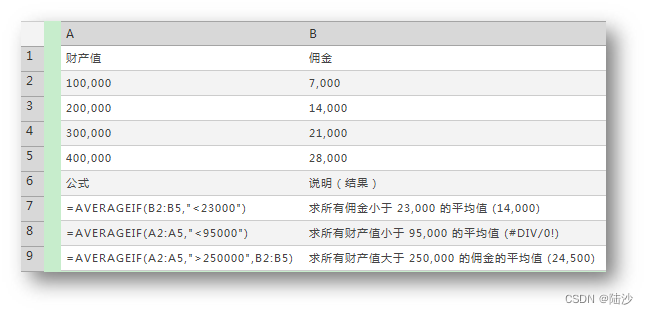
- 若要在计算中包含引用中的逻辑值和代表数字的文本,请使用·
AVERAGEA函数。 - 若要只对符合某些条件的值计算平均值,请使用
AVERAGEIF函数或AVERAGEIFS函数。
TRIMMEAN(array, percent)
从头尾一共去掉perc的数据,再计算平均值
LARGE(array, k)
返回第k个最大值,降序
SMALL(array, k)
FIND( 文本, 范围,数值)
查找一个字符在另一个字符串中的位置
数值表示查找第几个.
=FIND( “a”, “abcaef”,1)= 1
=FIND( “a”, “abcaef”,2)= 4
SUBSTITUTE(text, old_text, new_text[, instance_num])
对将text中的old_text替换为new_text,如果指定了instance_num,则替换第instance_num个old_text,否则替换所有的。
ROUND(number, num_digits)
四舍五入,num_digits是位数
num_digits为0指四舍五入到最接近的整数;num_digits<0,则在小数点左侧四舍五入
ROUND(21.5, -1) 得20
Round(-1.475, 2)得-1.48
ROUNDUP始终 向上舍入,远离0
ROUNDDOWN 始终向下舍入,朝向0
MROUND(num, multiple)
=MROUND(1.3, 0.2)将 1.3 四舍五入到最接近 0.2 的倍数。1.4
=MROUND(5, -2)
返回错误值 #NUM!, 因为 -2 和 5 的符号不同。
向 Multiple 参数提供十进制值时,中点数字的舍入方向不明确。例如,MROUND (6.05,0.1) 返回 6.0,而 MROUND (7.05,0.1) 返回7.1。
COUNT
统计数字个数,不包含空值
COUNTA
统计非空单元格数
COUNTBLANK
统计空格数
COUNTIF
DATE
根据数值返回日期
DAY/MONTH/YEAR/WEEKDAY
返回日期是一个月中的第几天/月/年
NOW
返回当前日期和时间
TODAY
返回当前日期
重复字符串REPT

颜色
开始-条件格式:为满足条件的单元格设置格式
可以为单元格设置颜色,然后利用颜色做筛选
实际应用
判断某个单元格内容是否在某行之中
判断L3是否在G行之中
=IF(COUNTIF(G:G,L3)>0,"有","")
=COUNTIF(M:M,"有")
判断两列是否相等
数据分列,然后
=IF(AND(A1=C1, B1=D1), “”, “FAIL”)
然后下拉至最后
=COUNTIF(E1:E7837, “FAIL”)
注意: AND放前面,countif条件是字符的话直接写,如果是其他,如"=0"这样写
在一列中查找另一列的数据,并且标出来:
选中目标列,选择条件格式-新规则-使用公式确定要格式化的单元格-
=NOT(ISNA(VLOOKUP(A1, B : B: B:B,1,FALSE)))
A1是要突出显示的目标列的第一个单元格,B是筛选条件列
在excel中生成sql的insert语句
- 编写语句
举例:
=CONCATENATE("insert into sgrna_human(gene_id, cds, chr, start, end, chr_dir, sgrna_dir, seq, pam) values ('"&A1&"','"&B1&"','"&C1&"','"&D1&"','"&E1&"','"&F1&"','"&G1&"','"&H1&"','"&I1&"');")
用concatenate是因为单个格子字符数不能超过255,短的话直接写insert就好了。
比如另一个table,我可以写成:
=CONCATENATE("insert into idv values ('"&A1&"','"&B1&"','"&C1&"','"&D1&"','"&E1&"');")
另外注意一下格式:
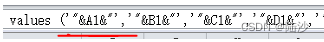
-
选择要填充的区域
我现在第一行是表头,所以公式我是写在J1的。当前共有2310行,如果拉太多行(选中整列),那么填充太费时间。所以在名称框中写好需要填充的区域,如现在的J1:J2310
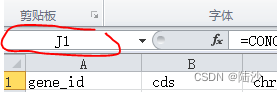
然后ctrl+d,填充完毕。直接copy到文本文件test.sql中。 -
登录进mysql,然后
use db;source test.sql即可。