目录
概要
一、代码概览
二、详解
基本逻辑
1.数据准备
2.设计神经网络
初版
改进版
测试
总结
概要
原文链接:DeepLearning in Pytorch|我的第一个NN-共享单车预测
我的第一个深度学习神经网络模型---利用Pytorch设计人工神经网络对某地区租赁单车的使用情况进行预测
输入节点为1个,隐含层为10个,输出节点数为1的小型人工神经网络,用数据的下标预测单车数量。
本文将以该神经网络模型为例,剖析深度学习部分概念,同时对原代码进行拆解分析
PS:
1.该神经网络无法达到解决实际问题的要求,但它结构简单,包含了神经网络的基本元素,可以达到初步入门深度学习以及熟悉Pytorch使用的效果,同时在实践过程中引出了过拟合现象。
2.Pytorch 2.2.1 (CPU) Python 3.6.13|Anaconda 环境
一、代码概览
bike1.py
二、详解
基本逻辑
在这里我要首先以一种朴素的方式描述一下学习和神经网络的基本逻辑。
假设自变量 x 和因变量 y,且它们之间存在映射关系 y = f(x)。法则 f(x) 未知,而现在我们有一些已知的 y 及其对应的 x,我们希望通过观测这些数据当中 y 与 x 的特征和关系,推测出可能满足要求的 f(x),从而对于一个新的自变量 x0,我们可以得到 f(x0) 作为预测值。
这些已知x和y的样本称为数据集,我们通常取一部分作为训练样本(训练集)供模型学习,另一部分(测试集)用于测试。
在实际中, y 与 x 的关系往往是复杂的,需要通过多层函数实现( y = f(g(h(...(x)))) ),我们把函数的层数称为深度,每个层都有权重参数和其他参数对上一层的值处理(加权求和+激活函数)后传递给更深层的神经元。在训练过程中,当一个输入 x0 经过多个层得到预测输出 y0’(1)时,模型就会与实际值 y0 比较,然后对各个层的参数进行调整,重新输入模型得到 y0’(2),再与 y0 比对······经过多次迭代,最终当 y0(n) 与 y0 的误差在可接受范围内(模型预测值与实际值拟合)时,我们就得到了一个对训练集学习产生的预测神经网络。
其中,输入层到输出层的过程称为神经网络的前馈运算,迭代进行参数更新的过程称为反向传播算法。
一般而言,前馈运算可以表示为以下的伪代码:
# 输入数据
input_data = ...# 输入层
input_layer_output = input_data# 隐藏层(可以有多个隐藏层)
for layer in hidden_layers:layer_activation = activation_function(layer_weights * input_layer_output)input_layer_output = layer_activation# 输出层
output_activation = activation_function(output_layer_weights * input_layer_output)# 输出结果
output_result = output_activation其中,activation_function() 表示激活函数,layer_weights 和 output_layer_weights 表示每个神经元的权重。
这就是神经网络的前馈运算过程。它负责将输入数据从输入层传递到输出层,并产生相应的输出结果。前馈运算和反向传播算法只是神经网络的一部分,其他重要的步骤包括损失函数计算等。
神经网络的数学逻辑较为复杂,建议先做了解后再来上手实操。下面我们讨论我们的BikeNN。
1.数据准备
#导入需要使用的库
import numpy as np
import pandas as pd #读取csv文件的库
import matplotlib.pyplot as plt #绘图
import torch
import torch.optim as optim
#读取数据到内存中,rides为一个dataframe对象
data_path = 'Documents/hour.csv' #文件路径
rides = pd.read_csv(data_path)
rides.head()
在这个项目中,我们引入了numpy pandas matplotlib.pyplot torch 和 torch.optim
NumPy提供多维数组对象和数学函数;而Pandas 是建立在 NumPy 之上的数据处理库,适用于数据清洗、分析和处理;Matplotlib 是一个绘图库,matplotlib.pyplot 是 Matplotlib 的子模块,用于将数据可视化(绘图);PyTorch 是我们的主要工具,与其他深度学习框架相比它提供了张量计算和动态计算图(可以将张量理解为多维数组);torch.optim 是 PyTorch 提供的优化算法模块,包含了常见的优化器,用于更新深度学习模型中的参数以最小化损失函数。
这些库是我们在基于Pytorch的深度学习任务中最基本的函数库,我们用 NumPy 加载和处理数据,利用 Pandas 进行数据清洗和转换,使用 Matplotlib.pyplot 可视化数据,然后使用 PyTorch 构建和训练深度学习模型,并利用 torch.optim 模块选择和应用优化算法。
#我们取出最后一列的前50条记录来进行预测
counts = rides['cnt'][:50]#获得变量x,它是1,2,……,50
x = np.arange(len(counts))# 将counts转成预测变量(标签):y
y = np.array(counts)# 绘制一个图形,展示曲线长的样子
plt.figure(figsize = (10, 7)) #设定绘图窗口大小
plt.plot(x, y, 'o-') # 绘制原始数据
plt.xlabel('X') #更改坐标轴标注
plt.ylabel('Y') #更改坐标轴标注
plt.show()在读取文件后,我们定义了NumPy数组 x 和 y,在本例中,x 是样本的序号(创建了一个1-50的有序数组),y 是共享单车数目counts(从hour.csv读取得到),然后利用绘图函数将X和Y关系用图像表示了出来:
2.设计神经网络
初版
#版本1
#取出数据库中的最后一列的前50条记录来进行预测
counts = rides['cnt'][:50]#创建变量x,它是1,2,……,50
x = torch.tensor(np.arange(len(counts), dtype = float), requires_grad = True)# 将counts转成预测变量(标签):y
y = torch.tensor(np.array(counts, dtype = float), requires_grad = True)首先取出前50组样本作为训练集,定义张量 x 和 y:
(PS:我们在这里主要用到两种数据结构,一种是Python提供的NumPy数组,另一种是Pytorch提供的tensor张量,二者之间可以通过库函数转换)
使用 np.arange(len(counts), dtype=float) 创建了一个 NumPy 数组,其中包含了 0 到 49 的数字序列,然后使用 torch.tensor() 将该数组转换为 PyTorch 张量 x,设置 requires_grad=True 允许对 x 进行梯度计算;
用 np.array(counts, dtype = float) 将 counts 转换为 NumPy 数组,然后使用 torch.tensor() 函数将其转换为 PyTorch 的张量对象,设置 requires_grad 参数以启用梯度计算。这样就可以在训练神经网络时,根据预测值与真实标签的差异来计算损失,并通过反向传播更新网络参数。
# 设置隐含层神经元的数量
sz = 10# 初始化所有神经网络的权重(weights)和阈值(biases)
weights = torch.randn((1, sz), dtype = torch.double, requires_grad = True) #1*10的输入到隐含层的权重矩阵
biases = torch.randn(sz, dtype = torch.double, requires_grad = True) #尺度为10的隐含层节点偏置向量
weights2 = torch.randn((sz, 1), dtype = torch.double, requires_grad = True) #10*1的隐含到输出层权重矩阵learning_rate = 0.001 #设置学习率
losses = []# 将 x 转换为(50,1)的维度,以便与维度为(1,10)的weights矩阵相乘
x = x.view(50, -1)
# 将 y 转换为(50,1)的维度
y = y.view(50, -1)这段代码实现了一个简单的神经网络模型,包括设置隐含层神经元数量、初始化权重和阈值、设定学习率、以及对输入数据进行维度转换的操作,具体如下:
- 设置了隐含层神经元的数量为 10。
- 初始化所有神经网络的参数(权重和阈值):
weights是一个大小为 (1, 10) 的权重矩阵,将输入到隐含层的权重初始化为随机值。biases是一个大小为 (10,) 的偏置向量,用于隐含层节点的初始化。weights2是一个大小为 (10, 1) 的权重矩阵,表示隐含层到输出层的权重初始化。
learning_rate = 0.001:设置学习率为 0.001。losses = []:初始化一个空列表用于存储损失值。- 将输入
x和标签y进行维度转换(根据矩阵乘法的运算规则需要):x.view(50, -1)将x转换为大小为 (50, 1) 的张量,以便与大小为 (1, 10) 的weights矩阵相乘。y.view(50, -1)将y转换为大小为 (50, 1) 的张量。
这段代码准备了神经网络所需的初始参数(也是模型后面迭代更新的对象),并对输入数据进行了适当的处理,以便后续在神经网络模型中使用。这是建立神经网络模型前的一些基本设置和准备工作。
重头戏来了
for i in range(100000):# 从输入层到隐含层的计算hidden = x * weights + biases# 将sigmoid函数作用在隐含层的每一个神经元上hidden = torch.sigmoid(hidden)#print(hidden.size())# 隐含层输出到输出层,计算得到最终预测predictions = hidden.mm(weights2)##print(predictions.size())# 通过与标签数据y比较,计算均方误差loss = torch.mean((predictions - y) ** 2) #print(loss.size())losses.append(loss.data.numpy())# 每隔10000个周期打印一下损失函数数值if i % 10000 == 0:print('loss:', loss) #对损失函数进行梯度反传loss.backward()#利用上一步计算中得到的weights,biases等梯度信息更新weights或biases中的data数值weights.data.add_(- learning_rate * weights.grad.data) biases.data.add_(- learning_rate * biases.grad.data)weights2.data.add_(- learning_rate * weights2.grad.data)# 清空所有变量的梯度值。# 因为pytorch中backward一次梯度信息会自动累加到各个变量上,因此需要清空,否则下一次迭代会累加,造成很大的偏差weights.grad.data.zero_()biases.grad.data.zero_()weights2.grad.data.zero_()这段代码是神经网络结构中最重要的训练部分,也是深度学习任务所需运行时间最长的部分,包括前向传播、计算损失、反向传播更新参数等步骤。对于循环次数为 100,000 次的训练过程:
- 从输入层到隐含层的计算:将输入
x与权重weights相乘并加上偏置biases得到隐含层的输出hidden。 - 对隐含层的输出应用 Sigmoid 函数,将其值压缩到 (0, 1) 区间内。
- 隐含层的输出再通过权重
weights2得到最终的预测结果predictions。 - 计算预测结果与真实标签
y之间的均方误差作为损失值loss。 - 将每一步的损失值存储在列表
losses中。 - 每 10,000 次迭代打印一次当前的损失值。
- 对损失值进行反向传播,计算各个参数的梯度信息。
- 根据梯度信息使用梯度下降算法更新权重
weights、biases和weights2。 - 清空所有参数的梯度信息,以便下一轮迭代时重新计算新的梯度。
我们不难发现,每一层(包括中间的隐藏层和最后的输出层)的输出 hidden/predictions 都是通过加权参数作用下加权求和,然后由激活函数Sigmoid函数决定神经元是否激活。
每次迭代得到一个预测结果predictions,将它与真实标签 y 比对得到损失值 loss并将其可视化(每迭代10000次输出一次当前的loss,这样我们可以看到loss随着迭代次数增多的变化)。
通过我们前面提到的反向传播算法(Pytorch提供 .backward()函数计算所有变量的梯度信息,并将叶节点的导数值存储在.grad中)计算各个参数的梯度信息,从而更新参数配置(weights、biases 和 weights2)以获得更准确的预测predictions。
# 打印误差曲线
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()误差loss随迭代次数变化曲线:
显然误差loss随迭代次数增多而下降,在20000次以后基本不再下降
x_data = x.data.numpy() # 获得x包裹的数据
plt.figure(figsize = (10, 7)) #设定绘图窗口大小
xplot, = plt.plot(x_data, y.data.numpy(), 'o') # 绘制原始数据yplot, = plt.plot(x_data, predictions.data.numpy()) #绘制拟合数据
plt.xlabel('X') #更改坐标轴标注
plt.ylabel('Y') #更改坐标轴标注
plt.legend([xplot, yplot],['Data', 'Prediction under 1000000 epochs']) #绘制图例
plt.show()最后我们获取 x 和对应 predictions 的数据绘制出来:
这个模型有两个问题:
1.显然预测曲线在第一个波峰比较好地拟合了数据,但是在此后,它却与真实数据相差甚远
2.它的运行时间较长
实际上这两个问题是基于同一个原因:我们输入层的 x 范围是1-50,经过权重和偏置(范围在(-1,1))处理后结果就变成了(-50,50)可能会使得 sigmoid 函数的多个峰值无法很好地发挥作用,需要更多的计算时间来让神经网络学习适应这种范围的输入;sigmoid 函数的输出范围在(0, 1),如果输入的值范围较大,可能会导致 sigmoid 函数在不同位置出现多个峰值,这可能会增加模型训练的复杂度,需要更多的迭代次数才能调节神经元的权重和偏置,使得模型收敛到期望的位置。如果用于适应Sigmoid函数输入的时间少些,模型的拟合程度也会更高。
改进版
要改进上面的问题可以考虑两种手段:
- 调整权重和偏置的初始化范围,使其适应输入数据的范围,可以尝试根据实际情况选择更合适的初始化方案。
- 使用其他激活函数代替 sigmoid 函数,如 ReLU 函数等,能够更好地处理梯度消失和爆炸等问题,有助于加速模型的收敛速度。(AlexNet)
在这里我们采用第一种:将输入数据的范围做归一化处理,也就是让 x 的输入数值范围为0~1。
因为数据中 x 的范围是1~50,所以,我们只需要将每一个数值都除以50(len(counts))就可以了:
x = torch.FloatTensor(np.arange(len(counts), dtype = float) / len(counts))改进后的代码 :
#版本2
#取出最后一列的前50条记录来进行预测
counts = rides['cnt'][:50]#创建归一化的变量x,它的取值是0.02,0.04,...,1
x = torch.tensor(np.arange(len(counts), dtype = float) / len(counts), requires_grad = True)# 创建归一化的预测变量y,它的取值范围是0~1
y = torch.tensor(np.array(counts, dtype = float), requires_grad = True)# 设置隐含层神经元的数量
sz = 10# 初始化所有神经网络的权重(weights)和阈值(biases)
weights = torch.randn((1, sz), dtype = torch.double, requires_grad = True) #1*10的输入到隐含层的权重矩阵
biases = torch.randn(sz, dtype = torch.double, requires_grad = True) #尺度为10的隐含层节点偏置向量
weights2 = torch.randn((sz, 1), dtype = torch.double, requires_grad = True) #10*1的隐含到输出层权重矩阵learning_rate = 0.001 #设置学习率
losses = []# 将 x 转换为(50,1)的维度,以便与维度为(1,10)的weights矩阵相乘
x = x.view(50, -1)
# 将 y 转换为(50,1)的维度
y = y.view(50, -1)for i in range(100000):# 从输入层到隐含层的计算hidden = x * weights + biases# 将sigmoid函数作用在隐含层的每一个神经元上hidden = torch.sigmoid(hidden)# 隐含层输出到输出层,计算得到最终预测predictions = hidden.mm(weights2)# + biases2.expand_as(y)# 通过与标签数据y比较,计算均方误差loss = torch.mean((predictions - y) ** 2) losses.append(loss.data.numpy())# 每隔10000个周期打印一下损失函数数值if i % 10000 == 0:print('loss:', loss)#对损失函数进行梯度反传loss.backward()#利用上一步计算中得到的weights,biases等梯度信息更新weights或biases中的data数值weights.data.add_(- learning_rate * weights.grad.data) biases.data.add_(- learning_rate * biases.grad.data)weights2.data.add_(- learning_rate * weights2.grad.data)# 清空所有变量的梯度值。# 因为pytorch中backward一次梯度信息会自动累加到各个变量上,因此需要清空,否则下一次迭代会累加,造成很大的偏差weights.grad.data.zero_()biases.grad.data.zero_()weights2.grad.data.zero_()
plt.semilogy(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()是的,其他部分完全一样!我们再来看看它的误差曲线:
预测结果曲线:
我们可以发现:
和先前相比,loss 直到迭代80000次才逐渐稳定,因为有更多的迭代用于更新模型的参数,使其更加准确,而非浪费在处理Sigmoid函数峰值上;
改进后的模型运行速度更快,数据图出现了两个波峰,也非常好地拟合了这些数据点,形成一条优美的曲线。
测试
用后面50组样本(测试集)进行测试
#测试50组数据
counts_predict = rides['cnt'][50:100] #读取待预测的接下来的50个数据点#首先对接下来的50个数据点进行选取,注意x应该取51,52,……,100,然后再归一化
x = torch.tensor((np.arange(50, 100, dtype = float) / len(counts)), requires_grad = True)
#读取下50个点的y数值,不需要做归一化
y = torch.tensor(np.array(counts_predict, dtype = float), requires_grad = True)x = x.view(50, -1)
y = y.view(50, -1)# 从输入层到隐含层的计算
hidden = x * weights + biases# 将sigmoid函数作用在隐含层的每一个神经元上
hidden = torch.sigmoid(hidden)# 隐含层输出到输出层,计算得到最终预测
predictions = hidden.mm(weights2)# 计算预测数据上的损失函数
loss = torch.mean((predictions - y) ** 2)
print(loss)x_data = x.data.numpy() # 获得x包裹的数据
plt.figure(figsize = (10, 7)) #设定绘图窗口大小
xplot, = plt.plot(x_data, y.data.numpy(), 'o') # 绘制原始数据
yplot, = plt.plot(x_data, predictions.data.numpy()) #绘制拟合数据
plt.xlabel('X') #更改坐标轴标注
plt.ylabel('Y') #更改坐标轴标注
plt.legend([xplot, yplot],['Data', 'Prediction']) #绘制图例
plt.show()测试的计算过程和训练当中每一次迭代的计算过程基本类似
作出拟合数据与原始数据图: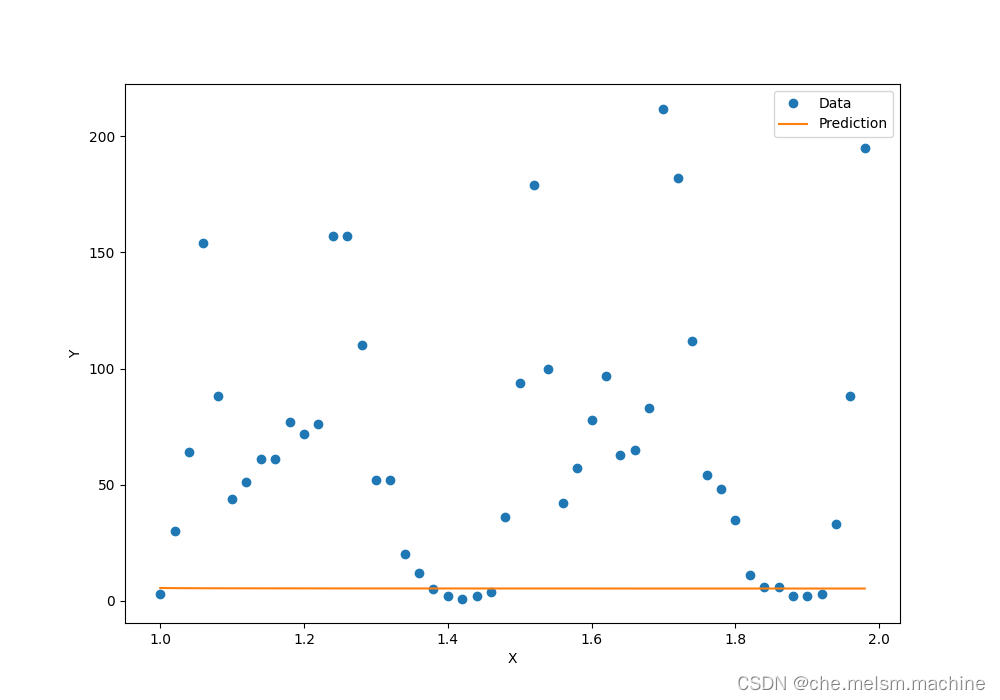
模型预测与实际数据竟然完全对不上!为什么我们的神经网络可以非常好地拟合已知的50个数据点,却在测试集上出错了呢?因为y(单车数量)与x(数据序号)根本没有关系!这就是在机器学习中最常见的困难---过拟合
过拟合(Overfitting)是指机器学习模型在训练数据上表现很好,但在测试数据上表现较差的情况。过拟合通常发生在模型过度复杂(参数太多)或者训练数据量太少的情况下。这两种情况都可能会把训练集的特征误以为是全部样本的特征。
对于我们的单车预测模型,问题显然在于我们要求模型学习 单车数量y 与 数据序号x 之间的关系,模型通过学习我们给出的前五十组数据(训练集)学会了它所认为的样本特征,但当我们引入后面50组样本(测试集)时,我们发现模型学到的特征是没有意义的,它只能反映训练集中的某些特点。
如果要解决这个问题,我们就应该让模型学习关于样本的更多特征,如:星期几、是否节假日、温度、湿度等(显然这些才是真正会影响x的因素)。当然从理论上讲,这样得到的神经网络更复杂,但显然他的预测更能达到我们想要的效果。
总结
我们通过简单的神经网络模型--单车预测了解了深度学习的基本逻辑和Pytorch的使用(虽然这是一个错误的模型hhh),我们将在下一篇中用更多新的手段构建预测更精准、更好的神经网络模型
主要参考资料:《深度学习原理与Pytorch实践》
参考代码:bike1.py · che.melsm/DeepLearning Project - Gitee.com
阅读原文:DeepLearning in Pytorch|我的第一个NN-共享单车预测