Django模型层(附带test环境)
目录
- Django模型层(附带test环境)
- 连接数据库
- Django ORM
- 在models.py中建表
- 允许为空
- 指定默认值
- 数据库迁移命令
- 开启测试环境
- 建表语句补充(更改默认表名)
- 数据的增加
- 时间数据的时区
- 多表数据的增加
- 一对多
- 多对多
- 数据的删除
- 修改数据
- 查询数据
- 查询所有数据
- 去重查询
- 排序查询
- 统计
- 剔除指定数据
- 多表查询
- 示例
- 一对多:图书与出版社
- 多对多:图书和作者
- 方式【1】**推荐**
- 方式【2】**不推荐**
- 校验数据是否存在
- 字段的筛选查询
- 连表查询
- 正向查询
- 反向查询
- 聚合函数(aggregate)
- 分组查询
- F与Q查询
- F查询
- Q查询
- Django开启事务
- choices参数
连接数据库
这是Django默认的数据库
DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3','NAME': BASE_DIR / 'db.sqlite3',}
}
修改为我们需要的配置
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'mydj','USER': 'root','PASSWORD': '7997','HOST': '127.0.0.1','PORT': 3306,'CHARSET': 'utf8',}
}
django 默认使用mysqldb模块链接mysql
但是该模块的兼容性不好,需要手动修改为pymysql链接
在项目下的init或者任意的应用名下的init文件中书写一下代码
init.py
import pymysqlpymysql.install_as_MySQLdb()
Django ORM
在models.py中建表
id字段Django会自动帮忙创建
from django.db import models# Create your models here.
class User(models.Model):username = models.CharField(max_length=32)password = models.CharField(max_length=32)
允许为空
class MyModel(models.Model):name = models.CharField(max_length=50, null=True) # 允许name字段为空
指定默认值
class MyModel(models.Model):age = models.IntegerField(default=18) # 默认年龄为18岁
数据库迁移命令
-
创建操作记录
-
python manage.py makemigrations操作完后Django会自动在migrations目录下生成sql语句文件
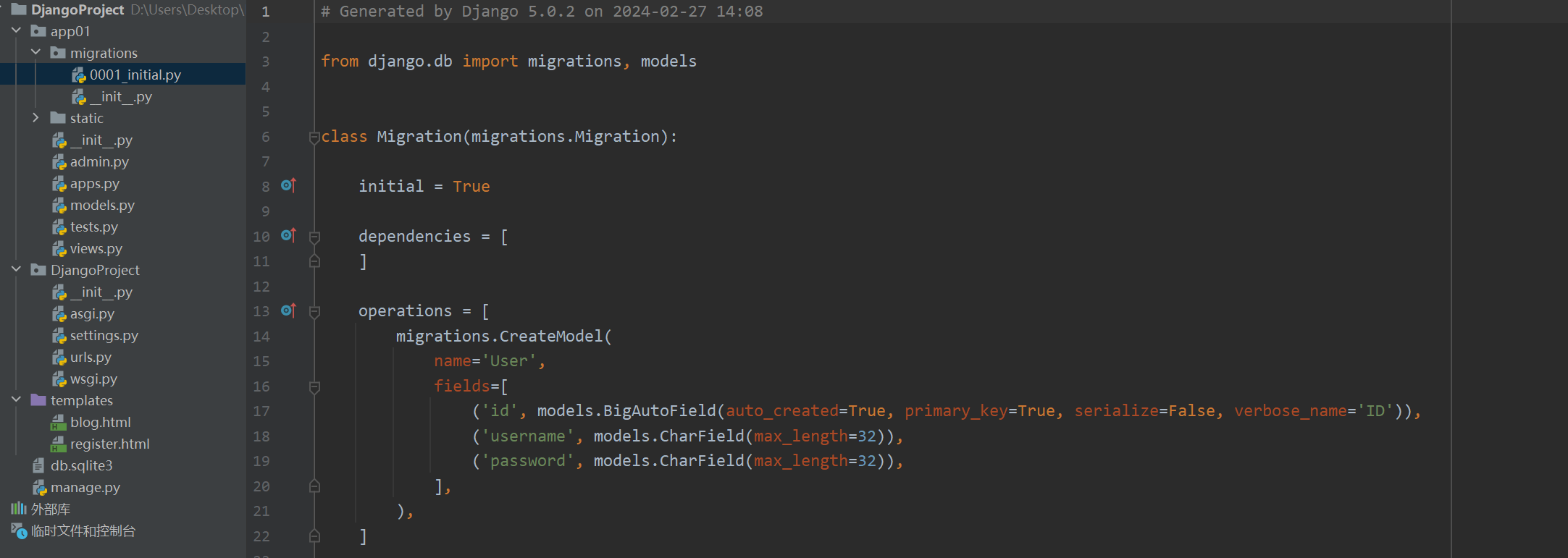
-
-
同步到数据库
-
python manage.py migrate
-
等待表创建完毕
这样就是成功执行建表语句了
删除字段只要在models中删除对应的字段行,然后重新makemigrations即可生成新的sql语句
开启测试环境
首先在app下找到tests.py文件并进入
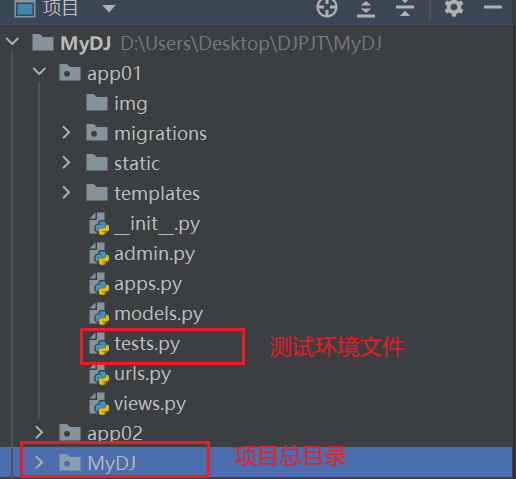
'MyDJ.settings'要换成自己的项目名,我的是MyDJ
import osfrom django.test import TestCaseif __name__ == '__main__':# 导入一句话 : 来自于 manage.py 中的第一句话os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetime# 启动Djangodjango.setup()from app01 import models# 开始业务代码user = models.user.objects.create(username='张三',password='222')
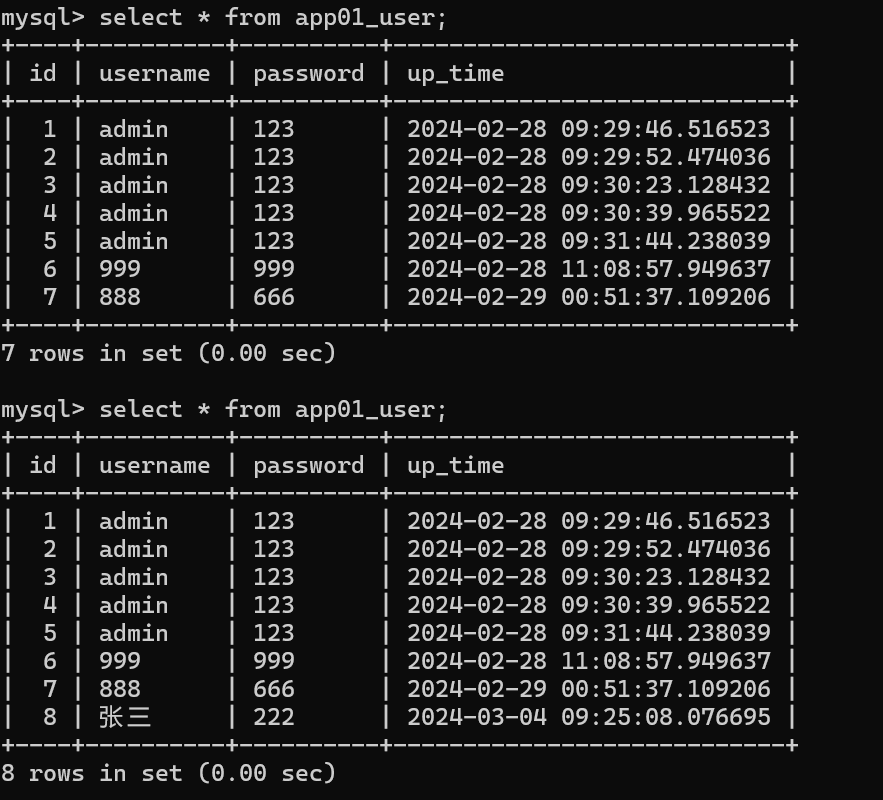
成功~
建表语句补充(更改默认表名)
class Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=True)# 绑定出版社外键publish = models.ForeignKey('Publish', on_delete=models.CASCADE, to_field='id', default=1)# 绑定图书表和作者表,用ManyToManyField自动创建第三张表author = models.ManyToManyField('Author')class Meta():# 不添加的话默认表名app01_bookdb_table = 'book'
数据的增加
data = models.user.objects.create(username="李四",password=929)
data = models.user(username="陈五",password=909)
data.save()
时间数据的时区
创建时间字段(如:DateTimeField())
中国时区需要将settings中部分设置修改为:
LANGUAGE_CODE = 'zh-hans'TIME_ZONE = 'Asia/Shanghai'
多表数据的增加
一对多
此时有一张作者表和作者详情表
作者详情表绑定这作者表的id
class Author(models.Model):# 作者名name = models.CharField(max_length=32, unique=True)# 年龄age = models.IntegerField()class Meta():db_table = 'author'class AuthorDetail(models.Model):# 作者电话phone = models.CharField(max_length=11)# 作者地址addr = models.CharField(max_length=132)# 作者名 绑定外键author_name = models.ForeignKey('Author', on_delete=models.CASCADE, to_field='id', default=1, null=True)class Meta():db_table = 'authordetail'
对外键关系表进行增加操作
import osfrom django.test import TestCase
import datetimeif __name__ == '__main__':os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetimedjango.setup()from app01 import models# author_name内必须是一个Author实例对象,不能直接使用参数内容models.Author.objects.create(name='张三', age=11)detail_id = models.Author.objects.get(id=1)models.AuthorDetail.objects.create(phone='123', addr="北京", author_name=detail_id)
多对多
假设有一张图书表和作者表,两者由第三张表绑定外键关系
class Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=True)# 绑定图书表和作者表,用ManyToManyField自动创建第三张表author = models.ManyToManyField('Author')class Meta():# 不添加的话默认表名app01_bookdb_table = 'book'class Author(models.Model):# 作者名name = models.CharField(max_length=32, unique=True)# 年龄age = models.IntegerField()class Meta():db_table = 'author'
import osfrom django.test import TestCase
import datetimeif __name__ == '__main__':os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetimedjango.setup()from app01 import models# 为作者和图书的多对多的第三张表添加信息author_obj = models.Author.objects.get(id=1)book_obj = models.Book.objects.get(id=1)book_obj.author.add(author_obj)# 删除外键关系'''author_obj = models.Author.objects.get(id=1)book_obj = models.Book.objects.get(id=1)book_obj.author.remove(author_obj)'''# 修改外键关系'''author_obj = models.Author.objects.get(id=2)book_obj = models.Book.objects.get(id=1)book_obj.author.set([author_obj])'''# 清空外键关系'''book_obj = models.Book.objects.get(id=1)book_obj.author.clear()'''
author_obj:获取作者表实例
book_obj:获取图书表实例
book_obj.author.add(author_obj):add内的参数是author表的实例
数据的删除
data = models.user.objects.filter(username="张三").delete()
data = models.user.objects.get(id=9)
data.delete()
修改数据
data = models.user.objects.get(id=10)
data.password=111
data.save()
data = models.user.objects.filter(id=10).update(username="张三")
查询数据
data = models.user.objects.filter(id=3)
print(data.values())
# get不能查询不存在的数据,否则会报错
data = models.user.objects.get(id=1)
查询所有数据
# 查询所有数据
data = models.user.objects.values()
# id=1的所有字段
data = models.user.objects.filter(id=1).values()
# 元组查询,结果只有值没有键
data = models.user.objects.values_list()
data = models.user.objects.filter(id=1).values_list()
去重查询
# 相同的username字段不会被多次查询
data = models.user.objects.values('username').distinct()
print(data)
data = models.user.objects.values('username','password').distinct()
排序查询
# 从小到大
data = models.user.objects.order_by('id').values('id')
# 从大到小
data = models.user.objects.order_by('-id').values('id')
统计
# 统计库中所有数据
data = models.user.objects.values().count()
# 库中名为admin的数量
data = models.user.objects.filter(username="admin").count()
剔除指定数据
# 排除id=1的数据
data = models.user.objects.values().exclude(id=1)
多表查询
假设有user、user2两个模型
# 一对多
data = models.user.objects.select_related('user2').all()
# 多对多
users = User.objects.prefetch_related('user2').all()
示例
创建book(书籍),Publish(出版社),Author(作者),AuthorDetail(作者详情)四个表
import datetimefrom django.db import modelsclass Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=datetime.datetime.now())class Publish(models.Model):# 出版社名name = models.CharField(max_length=32)# 出版社地址addr = models.CharField(max_length=132)# 出版社邮箱email = models.CharField(max_length=32)class Author(models.Model):# 作者名name = models.CharField(max_length=32)# 年龄age = models.IntegerField()class AuthorDetail(models.Model):# 作者电话phone = models.CharField(max_length=11)# 作者地址addr = models.CharField(max_length=132)
# 创建迁移文件
python manage.py makemigrations
python manage.py migrate
一对多:图书与出版社
一个出版社可以有多本图书,但是一本书只能有一个出版社
class Book(models.Model):# 书名title = models.CharField(max_length=32)# 定价price = models.IntegerField()# 出版日期publish_date = models.DateTimeField(auto_now=datetime.datetime.now())# 绑定出版社外键publish = models.ForeignKey('Publish',on_delete=models.CASCADE,to_field='id',default=1, null=True)
models.ForeignKey('Publish'):与Publish表关联
on_delete=models.CASCADE:指定外键关系(当图书信息被删除时出版社信息也会被删除)
to_field='id',default=1:绑定author表的id主键,并默认为1
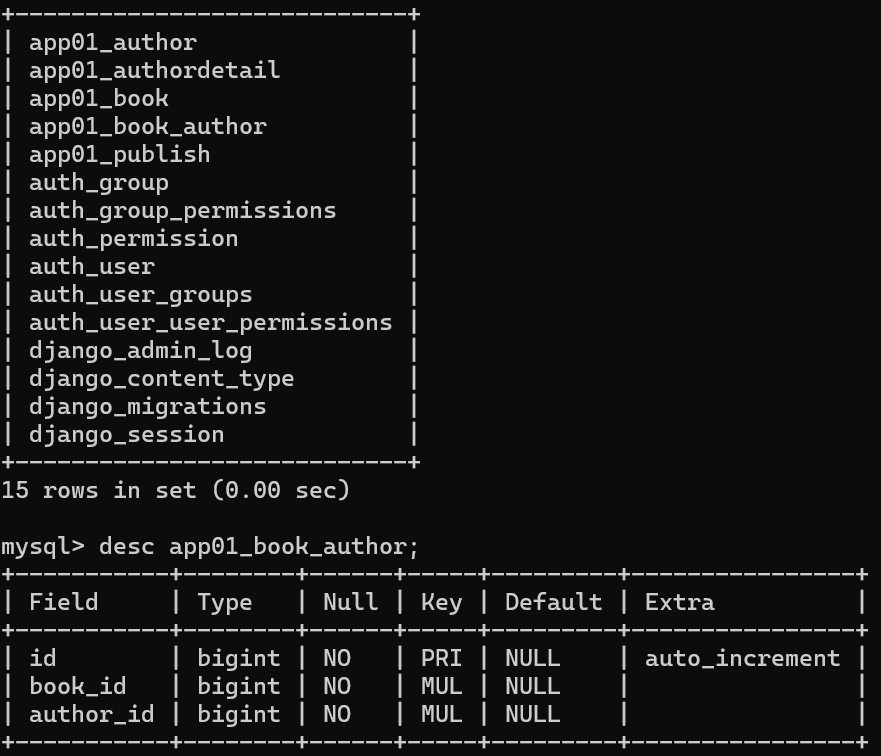
多对多:图书和作者
一本书可以有多个作者,一个作者也可以创作多本书
方式【1】推荐
在Book类中使用ManyToManyField自动创建第三张表
# 绑定图书表和作者表,用ManyToManyField自动创建第三张表
author = models.ManyToManyField('Author')
方式【2】不推荐
手动创建第三张表
class Book_Author(models.Model):book = models.ForeignKey('Book',on_delete=models.CASCADE())author = models.ForeignKey('Author',on_delete=models.CASCADE())
手动制定ManyToManyField参数:
through:绑定的第三张表
through_fields:绑定所需的字段
author = models.ManyToManyField(to='Author',through='Book_Author',through_fields=('book','author'))
校验数据是否存在
data = models.user.objects.filter(id=1).exists()
print(data) # True/False
字段的筛选查询
条件运算
- 大于
gt
data = models.user.objects.filter(id__gt=5)
- 小于
lt
data = models.user.objects.filter(id__lt=5)
- 大于等于
gte
data = models.user.objects.filter(id__gte=5)
- 小于等于
lte
data = models.user.objects.filter(id__lte=5)
- 或
in
data = models.user.objects.filter(id__in=[1, 2, 3])
- 两个条件之间
range
# 顾头顾尾 因此返回id=1,2,3的数据
data = models.user.objects.filter(id__range=[1,3]).values()
- 模糊查询
contains(默认区分大小写)
data = models.user.objects.filter(username__contains='三').values()
- 模糊查询取消大小写限制
icontains
data = models.user.objects.filter(username__icontains='三').values()
- 以指定字符开头/结尾
startswith/endswitch
data = models.user.objects.filter(username__startswith='张').values()
- 过滤指定时间区间
time
# 过滤时间小于当前时间的数据
current_time = datetime.datetime.now()
data = models.user.objects.filter(up_time__lt=current_time).values()
连表查询
对于已经绑定了外键的字段,可以使用连表查询一次查询不同表中的数据
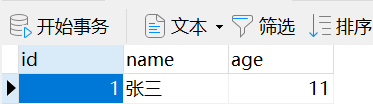

示例中有一个author表和authordetail表,authordetail的author_name_id字段绑定了author的id主键
正向查询
于是便可以通过获取author表中的示例然后.values('authordetail__phone')获取authordetail表中的phone字段,如下:
author_obj = models.Author.objects.filter(name='张三').values('authordetail__phone')
print(author_obj)
反向查询
当要使用没有绑定外键的字段来查询有外键字段的内容时:
author_obj = models.AuthorDetail.objects.filter(author_name__name='张三').values('author_name__name','phone')print(author_obj)
聚合函数(aggregate)
聚合函数需要在分组的情况下使用,并且需要导入Django中内置的聚合模块
from django.db.models import Avg, Sum, Max, Min, Countavg_price = models.Book.objects.aggregate(Avg('price'))
print(avg_price) # 获取书的平均价格
sum_price = models.Book.objects.aggregate(Sum('price'))
print(sum_price) # 获取书的总价
max_price = models.Book.objects.aggregate(Max('price'))
print(max_price) # 获取最贵的书
min_price = models.Book.objects.aggregate(Min('price'))
print(min_price) # 获取最便宜的书
count_price = models.Book.objects.aggregate(Count('price'))
print(count_price) # 获取书的数量
分组查询
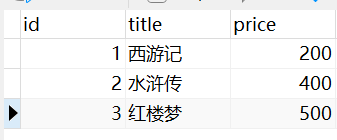
查询每本书有几个作者(作者绑定外键)
书
作者
绑定的外键表
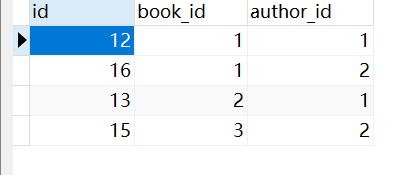
book_obj = models.Book.objects.annotate(a=Count("author")).values('a')
print(book_obj)
# <QuerySet [{'a': 2}, {'a': 1}, {'a': 1}]>
F与Q查询
首先要导入模块
from django.db.models import Count, F, Q, Value
from django.db.models.functions import Concat
F查询
将所有书的价格增加100
# 将所有书的价格增加100
book_obj = models.Book.objects.update(price=F('price')+100)
Q查询
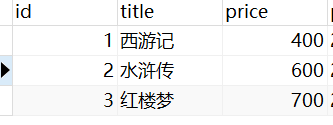
# 原语句
# book_obj = models.Book.objects.filter(price__gt=400,price__lt=700)
# Q语句
book_obj = models.Book.objects.filter(Q(price__gt=400),Q(price__lt=700)
print(book_obj.values('title'))
# <QuerySet [{'title': '水浒传'}]>
获取价格大于400或小于700的数据
book_obj = models.Book.objects.filter(Q(price__gt=400) or Q(price__lt=700))print(book_obj.values('title'))
book_obj = models.Book.objects.filter(Q(price__gt=400) | Q(price__lt=700))print(book_obj.values('title'))
or和|的区别:
- 使用
|运算符时,两个条件都会被考虑,并返回满足任何一个条件的结果 - 使用
or运算符时,只有第一个条件会被返回,不会考虑第二个条件
Django开启事务
from django.db import transaction
try:# 开启事务with transaction.atomic():# 在事务开启前的保存点save_id = transaction.savepoint()# 这部分代码会在事务中执行models.Book.objects.create(title='三国演义',price=1000)transaction.savepoint_commit(save_id)
except Exception as e:# 出错后回滚到save_id开始的地方transaction.savepoint_rollback(save_id)
choices参数
gender_choice 是一个元组列表,用于定义 Author 模型中 gender 字段的选项
class Author(models.Model):gender_choice = ((0,'男'),(1,'女'),(2,'保密'))# 作者名name = models.CharField(max_length=32, unique=True)# 年龄age = models.IntegerField()# 性别gender = models.IntegerField(choices=gender_choice,default=2)
if __name__ == '__main__':os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDJ.settings')import djangoimport datetimedjango.setup()from app01 import modelsfrom django.db import transactionauthor_obj = models.Author.objects.get(id=1)print(author_obj.gender)# 直接获取得到的是实际值:2print(author_obj.gender_choice)# 获取关联的choice元组:((0, '男'), (1, '女'), (2, '保密'))print(author_obj.get_gender_display())# 获取展示给用户的值:保密