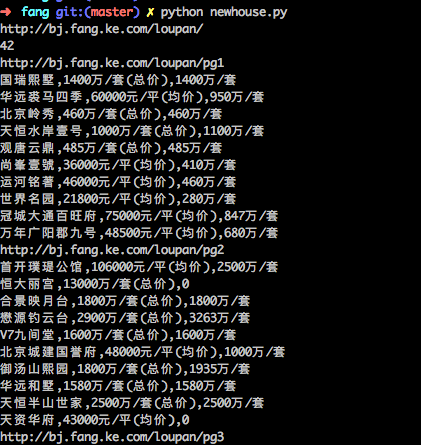
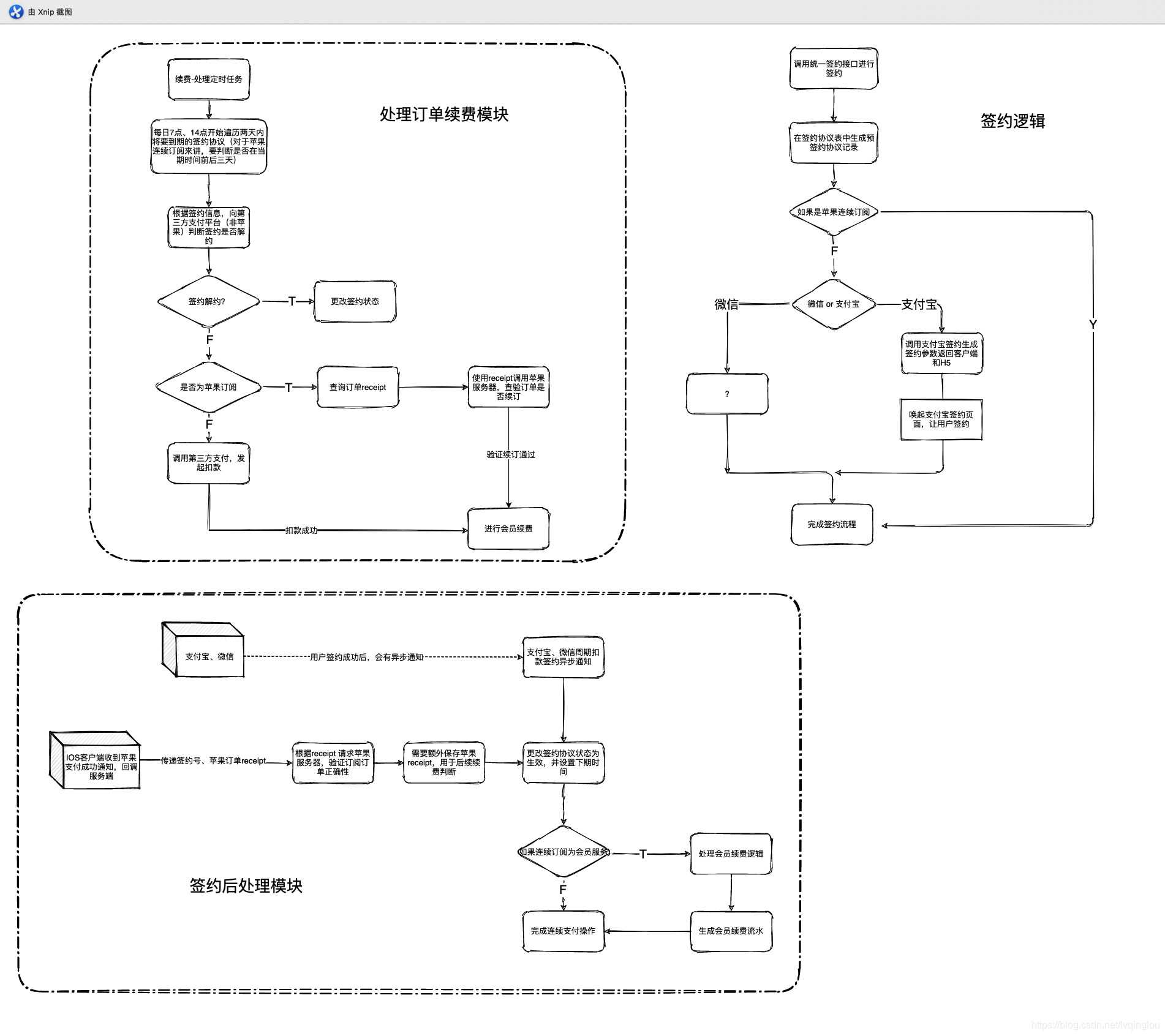
第一步是数据爬取:
import xlwt
from bs4 import BeautifulSoup
from selenium import webdriver
import time,random
from selenium.webdriver import ChromeOptionsdef main():baseurl = "https://xa.fang.anjuke.com/loupan/all/p"datalist = getData(baseurl)savepath = "安居客爬虫数据.xls"saveData(datalist, savepath)def getData(baseurl):datalist = []headers = {"cookie": "isp=true; isp=true; aQQ_ajkguid=C762D025-2585-194F-7317-8EC539296440; _ga=GA1.2.18092521.1626051248; _gid=GA1.2.2133028006.1626051248; id58=e87rkGDrkq+BJ/A5/JzXAg==; 58tj_uuid=4604ab87-5912-4903-a6dc-28ae7ae20bc1; als=0; isp=true; wmda_uuid=dfa952c1ee878d222eeb947c5618cfd7; wmda_new_uuid=1; wmda_visited_projects=%3B8788302075828; cmctid=483; xxzl_cid=629248c0af8e4b1e8a3219e3d1e090d7; xzuid=144b3c94-6fb0-45e0-b7f8-6e43c085f8a4; ctid=31; sessid=A07D28BD-B371-B893-463C-SX0712140406; obtain_by=2; twe=2; wmda_session_id_8788302075828=1626069849725-02cb50ff-be87-431f; init_refer=; new_uv=3; lp_lt_ut=1023adc4fcf5533ab348b520b9a4ce05; ved_loupans=472113; new_session=0","referer": "https://xa.fang.anjuke.com/loupan/all/p13/","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"}for i in range(0,26):url = baseurl+ str(i)driver = webdriver.Chrome()driver.get(url)html = driver.page_sourcesoup = BeautifulSoup(html, "html.parser")trs = soup.select("div.key-list>.item-mod")print(len(trs))for div in trs:data=[]name = div.select(".infos>.lp-name>.items-name")[0].get_text()print("名字:" + name)data.append(name)tstate = div.select(".tags-wrap>.tag-panel>i:nth-of-type(1)")if tstate:state = tstate[0].get_text()print(state)data.append(state)else:data.append(" ")position = div.select(".address>.list-map")[0].get_text()print("位置:" + position)data.append(position)thuxing = div.select("div.infos > a.huxing>span:nth-of-type(1)")if thuxing:huxing = thuxing[0].get_text()print(huxing)data.append(huxing)else:data.append(" ")thuxing2 = div.select("div.infos > a.huxing>span:nth-of-type(2)")if thuxing:huxing2 = thuxing[0].get_text()print(huxing2)data.append(huxing2)else:data.append(" ")tarea = div.select("div.infos > a.huxing > span.building-area")if tarea:area = tarea[0].get_text()print(area)data.append(area)else:data.append(" ")ttpe = div.select(".tags-wrap>.tag-panel>.wuyetp")if ttpe:type = ttpe[0].get_text()print("类型:" + type)data.append(type)else:data.append(" ")tshuxing1 = div.select(".tags-wrap>.tag-panel>span:nth-of-type(1)")if tshuxing1:shuxing1 = tshuxing1[0].get_text()print(shuxing1)data.append(shuxing1)else:data.append(" ")tshuxing2 = div.select(".tags-wrap>.tag-panel>span:nth-of-type(2)")if tshuxing2:shuxing2 = tshuxing2[0].get_text()print(shuxing2)data.append(shuxing2)else:data.append(" ")tshuxing3 = div.select(".tags-wrap>.tag-panel>span:nth-of-type(3)")if tshuxing3:shuxing3 = tshuxing3[0].get_text()print(shuxing3)data.append(shuxing3)else:data.append(" ")tshuxing4 = div.select(".tags-wrap>.tag-panel>span:nth-of-type(4)")if tshuxing4:shuxing4 = tshuxing4[0].get_text()print(shuxing4)data.append(shuxing4)else:data.append(" ")tshuxing5 = div.select(".tags-wrap>.tag-panel>span:nth-of-type(5)")if tshuxing5:shuxing5 = tshuxing5[0].get_text()print(shuxing5)data.append(shuxing5)else:data.append(" ")tprize = div.select("div.infos>a.favor-pos>p.around-price,p.favor-tag>span")if tprize:prize = tprize[0].get_text()print(prize)data.append(prize)else:data.append(" ")ts = div.select("div.item-mod>.infos>.tags-wrap>i:nth-of-type(2)")if ts:s = ts[0].get_text()print(s)data.append(prize)else:data.append(" ")datalist.append(data)time.sleep(1)driver.quit()return datalistdef saveData(datalist, savepath):header = ['名字', '售卖状态','位置', '房型', '房型', '面积', '类型', '属性1', '属性2', '属性3', '属性4', '属性5', '房价']book = xlwt.Workbook(encoding="utf-8", style_compression=0)sheet = book.add_sheet('Sheet1,cell_overwrite_ok=True')for h in range(len(header)):sheet.write(0, h, header[h])for i in range(0, 1531):print("第%d条" % (i + 1))data = datalist[i]for j in range(0, 13):sheet.write(i + 1, j, data[j])book.save(savepath)if __name__ == "__main__": # 当程序执行时# 调用函数main()# init_db("movietest.db")print("爬取完毕!")下面用pyecharts对爬取的数据展示:
- 漏斗图:

代码:
from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.faker import Faker# 漏斗
key = ["浐灞","西咸新区","城东","城西","城南","城北","咸阳","鄠邑区","长安","曲江","临潼","经济开发区","高陵","阎良","高新","泾渭"
]
value = [176,200,107,137,129,154,16,20,109,118,30,93,5,19,153,72
]
c = (Funnel().add("房源",[list(z) for z in zip(key, value)],sort_="ascending",label_opts=opts.LabelOpts(position="inside"),gap=3).render("picture/房源占比漏斗图.html")
)- 折线图:

from pyecharts.charts import Line
from pyecharts import options as opts
import pandas as pd
path = "data/各区均价.xlsx"
df = pd.read_excel(path)print(df)
line = Line()
line.add_xaxis(df["区"].to_list())line.add_yaxis("均价",df["均价"].to_list())line.set_global_opts(title_opts=opts.TitleOpts(title="西安各区房屋均价"),tooltip_opts=opts.TooltipOpts(trigger="axis",axis_pointer_type="cross"),toolbox_opts=opts.ToolboxOpts(is_show=True),)
line.render("picture/各区均价折线图.html")
- 饼图

import pyecharts.options as opts
from pyecharts.charts import Pieinner_x_data = ["城东", "城西", "城南", "城北"]
inner_y_data = [107, 137, 129, 154]
inner_data_pair = [list(z) for z in zip(inner_x_data, inner_y_data)]outer_x_data = ["浐灞", "西咸新区", "咸阳", "鄠邑区", "长安区", "曲江区", "临潼区", "经济开发区", "高陵区", "阎良区", "高新区", "泾渭"]
outer_y_data = [176, 200, 16, 20, 109, 118, 30, 93, 5, 19, 153, 72]
outer_data_pair = [list(z) for z in zip(outer_x_data, outer_y_data)](Pie(init_opts=opts.InitOpts(width="1600px", height="800px")).add(series_name="房源占比",data_pair=inner_data_pair,radius=[0, "30%"],label_opts=opts.LabelOpts(position="inner"),).add(series_name="房源占比",radius=["40%", "55%"],data_pair=outer_data_pair,label_opts=opts.LabelOpts(position="outside",formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",background_color="#eee",border_color="#aaa",border_width=1,border_radius=4,rich={"a": {"color": "#999", "lineHeight": 22, "align": "center"},"abg": {"backgroundColor": "#e3e3e3","width": "100%","align": "right","height": 22,"borderRadius": [4, 4, 0, 0],},"hr": {"borderColor": "#aaa","width": "100%","borderWidth": 0.5,"height": 0,},"b": {"fontSize": 16, "lineHeight": 33},"per": {"color": "#eee","backgroundColor": "#334455","padding": [2, 4],"borderRadius": 2,},},),).set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", orient="vertical")).set_series_opts(tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)")).render("picture/pies.html")
)- 树状图

from pyecharts import options as opts
from pyecharts.charts import Treedata = [{"children": [{"children": [{"name": "中铁·卓越城"}, {"name": "融创云潮府"}, {"name": "中铁·卓越城"}, {"name": "公寓-保利·心语花园K2立方"},{"name": "公寓-万科·悦湾·臻域"}, {"name": "中冶奥体云璟"}, {"name": "中粮·奥体壹号"}, {"name": "融创时代奥城"},{"name": "源邸壹号"}, {"name": "中铁·卓越城"}, {"name": "公寓-万科·悦湾·臻域"}], "name": "灞桥区",},{"children": [{"name": "隆基泰和·云玺领峯"}, {"name": "阳光城檀境"}, {"name": "新希望·锦麟天玺"}, {"name": "招商华宇·臻境"},{"name": "商铺-中海·熙峰广场"}, {"name": "紫薇·华发CID中央首府"}, {"name": "隆基泰和·云玺领峯"},{"name": "新希望·锦麟天玺"}, {"name": "荣民捌号"}],"name": "高新区",},{"children": [{"name": "德信·西宸府"}],"name": "鄠邑区",},{"children": [{"name": "公寓-曲江奥园城市天地"},],"name": "曲江",},{"children": [{"name": "盛唐长安4"},],"name": "临潼",},{"children": [{"name": "中建财智广场"},],"name": "经济开发区",},{"children": [{"name": "陕建航天新天地"},{"name": "招商华宇长安4玺"},{"name": "莱安领域"}],"name": "长安区",},],"name": "西安",}
]
c = (Tree().add("", data).set_global_opts(title_opts=opts.TitleOpts(title="西安部分城区部分小区")).render("picture/西安部分城区部分小区.html")
)- 词云

#词云图
import pyecharts.options as opts
from pyecharts.charts import WordCloud
import pandas as pdpath = "data/小区.xlsx"
df = pd.read_excel(path)col1 = df["名字"].unique()
col2 = df["名字"].value_counts()list = [tuple(z) for z in zip(list(col1), col2.to_list())](WordCloud().add(series_name="西安小区",data_pair=list, word_size_range=[20,46],shape= 'circle').set_global_opts(title_opts=opts.TitleOpts(title="西安小区", title_textstyle_opts=opts.TextStyleOpts(font_size=23)),tooltip_opts=opts.TooltipOpts(is_show=True),toolbox_opts=opts.ToolboxOpts(is_show=True),).render("picture/xiaoqu_wordcloud.html")
)想要了解更多pyecharts数据可视化可以查看文档:Echarts