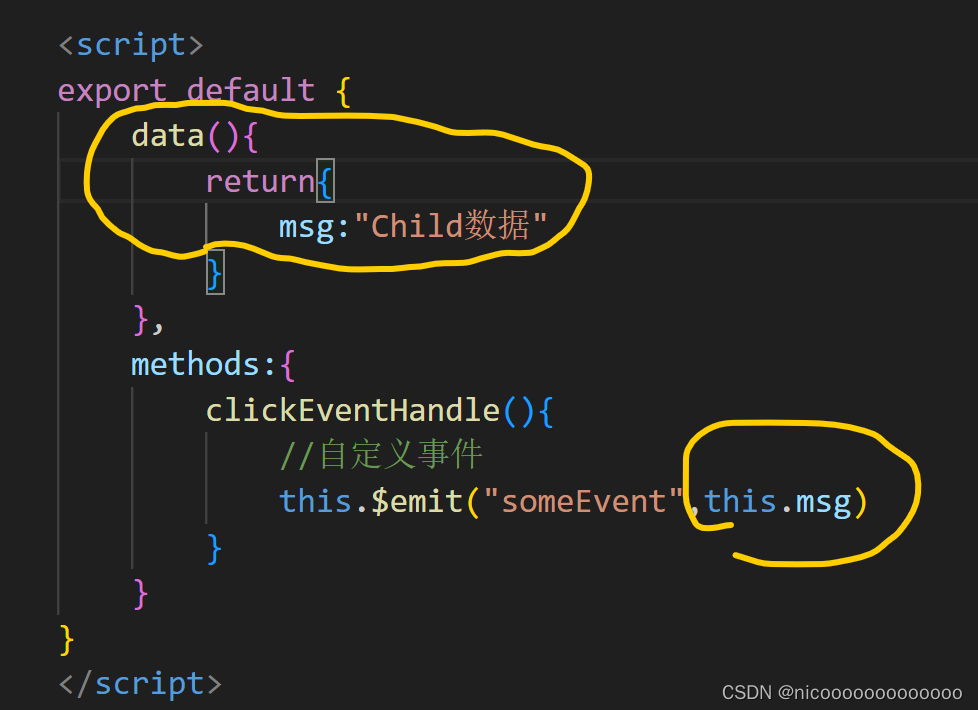
printf的用法
printf的格式有四种:
(1)printf("字符串\n");
其中\n表示换行的意思。其中n是“new line”的缩写,即“新的一行”。此外需要注意的是,printf中的双引号和后面的分号必须是在英文输入法下。双引号内的字符串可以是英文,也可以是中文。
(2)printf("输出控制符",输出参数);
#include<stdio.h>int main() {int i = 10;printf("%d\n", i); //%d是输出控制符,d表示十进制,后面的i是输出参数。return 0;
}这句话的意思是将变量i以十进制输出。那么现在有一个问题:“i本身就是十进制,为什么还要将i以十进制输出呢?”
因为程序中虽然写的是i=10,但是在内存中并不是将10这个十进制数存放进去,而是将10的二进制代码存放进去了。所以输出的时候要强调是以哪种进制形式输出。所以就必须要有“输出控制符”,以告诉操作系统应该怎样解读二进制数据。如果是%x就是以十六进制的形式输出,要是%o就是以八进制的形式输出,大家自己试一下。
(3)printf("输出控制符1输出控制符2…",输出参数1,输出参数2, …);
printf中双引号内除了输出控制符和转义字符'\n'外,所有其余的普通字符全部都原样输出。所以我们可以直接键入空格来表示空格。
(4)printf("输出控制符 非输出控制符",输出参数);
这里的非输出控制符就是那些会原样输出的字符。
注意:这时候会有一个问题:到底什么是“输出控制符”?很简单,凡是以“%”开头的基本上都是输出控制符。
输出控制符
常用的输出控制符主要有以下几个:
1)%d:按十进制整型数据的实际长度输出。
2)%ld:输出长整型数据。
3)%md:m为指定的输出字段的宽度。如果数据的位数小于m,则左端补以空格,若大于m,则按实际位数输出。
4)%u:输出无符号整型(unsigned)。输出无符号整型时也可以用%d,这时是将无符号转换成有符号数,然后输出。但编程的时候最好不要这么写,因为这样要进行一次转换,使CPU多做一次无用功。
5)%c:用来输出一个字符。
6)%f:用来输出实数,包括单精度和双精度,以小数形式输出。不指定字段宽度,由系统自动指定,整数部分全部输出,小数部分输出6位,超过6位的四舍五入。
7)%.mf:输出实数时小数点后保留m位,注意m前面有个点。
8)%o:以八进制整数形式输出,这个就用得很少了,了解一下就行了。
9)%s:用来输出字符串。用%s输出字符串同前面直接输出字符串是一样的。但是此时要先定义字符数组或字符指针存储或指向字符串,这个稍后再讲。
10)%x(或%X或%#x或%#X):以十六进制形式输出整数,这个很重要。
%x、%X、%#x、%#X的区别
一定要掌握%x(或%X或%#x或%#X),因为调试的时候经常要将内存中的二进制代码全部输出,然后用十六进制显示出来。下面写一个程序看看它们四个有什么区别:
#include<stdio.h>
int main(void) {int i = 47;printf("%x\n", i);printf("%X\n", i);printf("%#x\n", i);printf("%#X\n", i);return 0;
}
/*
输出结果是:
--------------------------------------
2f
2F
0x2f
0X2F
--------------------------------------
*/从输出结果可以看出:如果是小写的x,输出的字母就是小写的;如果是大写的X,输出的字母就是大写的;如果加一个“#”,就以标准的十六进制形式输出。最好是加一个“#”,否则如果输出的十六进制数正好没有字母的话会误认为是一个十进制数呢!
总之,不加“#”容易造成误解。但是如果输出0x2f或0x2F,那么人家一看就知道是十六进制。而且%#x和%#X中,笔者觉得大写的比较好,因为大写是绝对标准的十六进制写法。
如何输出“%d”、“\”和双引号
printf中有输出控制符“%d”,转义字符前面有反斜杠“\”,还有双引号。那么大家有没有想过这样一个问题:“怎样将这三个符号通过printf输出到屏幕上呢?”
要输出“%d”只需在前面再加上一个“%”;要输出“\”只需在前面再加上一个“\”;要输出双引号也只需在前面加上一个“\”即可。程序如下:
#include<stdio.h>
int main(void) {printf("%%d\n");printf("\\\n");printf("\"\"\n");return 0;
}
/*
输出结果是:
--------------------------------------
%d
\
""
--------------------------------------
*/scanf的用法
scanf的功能用一句话来概括就是“通过键盘给程序中的变量赋值”。
它有两种用法,或者说有两种格式。
(1)scanf("输入控制符",输入参数);
功能:将从键盘输入的字符转化为“输入控制符”所规定格式的数据,然后存入以输入参数的值为地址的变量中。
#include<stdio.h
int main(void) {int i;scanf("%d", &i); //&i表示变量i的地址,&是取地址符printf("i = %d\n", i);return 0;
}要想将程序中的scanf行弄明白,首先要清楚的是:我们从键盘输入的全部都是字符。比如从键盘输入123,它表示的并不是数字123,而是字符'1' 、字符'2'和字符'3'。这是为什么呢?操作系统内核就是这样运作的。操作系统在接收键盘数据时都将它当成字符来接收的。这时就需要用“输入控制符”将它转化一下。%d的含义就是要将从键盘输入的这些合法的字符转化成一个十进制数字。经过%d转化完之后,字符123就是数字123了。
第二个要弄清楚的是:&是一个取地址运算符,&后面加变量名表示“该变量的地址”,所以&i就表示变量i的地址。&i又称为“取地址i”,就相当于将数据存入以变量i的地址为地址的变量中。那么以变量i的地址为地址的变量是哪个变量呢?就是变量i。所以程序中scanf的结果就把值123放到变量i中。
注意,为什么不直接说“放到变量i中”?而是说“放到以变量i的地址为地址的变量中”?因为这么说虽然很绕口,但是能加强对&i的理解,这么说更能表达&i的本质和内涵。
(2)scanf("输入控制符 非输入控制符",输入参数);
这种用法几乎是不用的,也建议你们永远都不要用。但是经常有人问,为什么printf中可以有“非输出控制符”,而scanf中就不可以有“非输入控制符”。事实上不是不可以有,而是没有必要!下面来看一个程序:
#include<stdio.h>int main() {int i;scanf("i = %d", &i);printf("i = %d\n", i);return 0;
}在printf中,所有的“非输出控制符”都要原样输出。同样,在scanf中,所有的“非输入控制符”都要原样输入。所以在输入的时候“i=”必须要原样输入。比如要从键盘给变量i赋值123,那么必须要输入“i=123”才正确,少一个都不行,否则就是错误。所以scanf中“%d”后面也没有必要加“\n”,因为在scanf中“\n”不起换行的作用。它不但什么作用都没有,你还要原样将它输入一遍。
所以在scanf的使用中一定要记住:双引号内永远都不要加“非输入控制符”。除了“输入控制符”之外,什么都不要加,否则就是自找麻烦。而且对于用户而言,肯定是输入越简单越好。
但是需要注意的是,虽然scanf中没有加任何“非输入控制符”,但是从键盘输入数据时,给多个变量赋的值之间一定要用空格、回车或者Tab键隔开,用以区分是给不同变量赋的值。而且空格、回车或Tab键的数量不限,只要有就行。一般都使用一个空格。
此外强调一点:当用scanf从键盘给多个变量赋值时,scanf中双引号内多个“输入控制符”之间千万不要加逗号“, ”。
使用scanf的注意事项
在前面介绍printf时说过,“输出控制符”和“输出参数”无论在“顺序上”还是在“个数上”一定要一一对应。这句话同样对scanf有效,即“输入控制符”和“输入参数”无论在“顺序上”还是在“个数上”一定要一一对应。比如:
#include<stdio.h>int main() {char ch;int i;scanf("%c%d", &ch);printf("ch = %c, i = %d\n", ch, i);return 0;
}
这种错误是初学者经常犯的,由于粗心大意,少写一个参数。更严重的是,这种错误在编译的时候不会报错。
输出结果: 注意是VC++下的输出结果。
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
a 6
ch = a, i = -858993460--------------------------------------*/程序中为什么i=-858993460?这个在前面讲过,当变量没有初始化的时候就会输出这个值。在后面会讲到scanf是缓冲输入的,也就是说从键盘输入的数据都会先存放在内存中的一个缓冲区。只有按回车键后scanf才会进入这个缓冲区和取数据,所取数据的个数取决于scanf中“输入参数”的个数。所以上述程序中scanf只有一个输入参数,因此按回车键后scanf只会取一个数据。所以变量ch有数据,而变量i没有数据,没有数据就是没有初始化,输出就是-858993460。
输入的数据类型一定要与所需要的数据类型一致
在printf中,“输出控制符”的类型可以与数据的类型不一致。
但是在scanf中,对于从键盘输入的数据的类型、scanf中“输入控制符”的类型、变量所定义的类型,这三个类型一定要一致,否则就是错的。虽然编译的时候不会报错,但从程序功能的角度讲就是错的,则无法实现我们需要的功能。比如:
#include<stdio.h>
int main() {int i;scanf("%d", &i);printf("i = %d\n", i);return 0;
}
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
a
i = -858993460
--------------------------------------
*/输出-858993460表示变量未初始化。为什么输入a,变量i却显示未初始化呢?在scanf中,从键盘输入的一切数据,不管是数字、字母,还是空格、回车、Tab等字符,都会被当作数据存入缓冲区。存储的顺序是先输入的排前面,后输入的依次往后排。按回车键的时候scanf开始进入缓冲区取数据,从前往后依次取。
但scanf中%d只识别“十进制整数”。对%d而言,空格、回车、Tab键都是区分数据与数据的分隔符。当scanf进入缓冲区中取数据的时候,如果%d遇到空格、回车、Tab键,那么它并不取用,而是跳过继续往后取后面的数据,直到取到“十进制整数”为止。对于被跳过和取出的数据,系统会将它从缓冲区中释放掉。未被跳过或取出的数据,系统会将它一直放在缓冲区中,直到下一个scanf来获取。但是如果%d遇到字母,那么它不会跳过也不会取用,而是直接从缓冲区跳出。
所以上面这个程序,虽然scanf进入缓冲区了,但用户输入的是字母a,所以它什么都没取到就出来了,而变量i没有值,即未初始化,所以输出就是-858993460。
但如果将%d换成%c,那么任何数据都会被当作一个字符,不管是数字还是空格、回车、Tab键它都会取回。不但如此,前面讲过,你从键盘输入123,这个不是数字123,而是字符'1' 、字符'2'和字符'3',它们依次排列在缓冲区中。因为每个字符变量char只能放一个字符。所以输入“123”之后按回车,scanf开始进入缓冲区,按照次序,先取字符'1',如果还要取就再取字符'2',以此类推。如果都取完了还有scanf要取数据,那么用户就需要再输入。先写一个程序看一下:
#include<stdio.h>int main(void) {char i, j, k;scanf("%c%c%c", &i, &j, &k);printf("i = %c, j = %c, k = %c\n", i, j, k);return 0;
}
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
123
i = 1, j = 2, k = 3--------------------------------------*/从这个程序中我们看出,就单纯地输入123,不加任何空格,按回车键之后就同我们所讲的一样,分别将字符'1' 、字符'2'和字符'3'赋给字符变量i、j和k。
如果在输入的时候在123之间加空格,那么输出结果是就是:
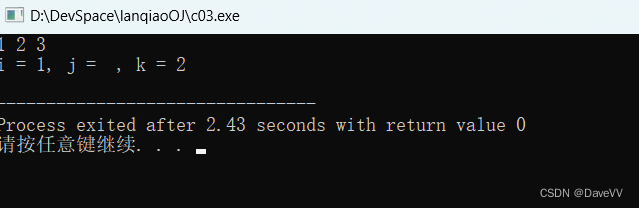
这个正好对应刚才讲的知识,不难理解。
但是需要提醒大家注意的是,在之前程序中,因为scanf是%d,所以a没有被取出来,还在缓冲区中。当遇到下一个scanf是%c时它就会被取出来。但是如果一直没有出现%c,那么这时就会出现一个问题:“scanf怎么取十进制整数?”即使使用%d,但是由于字符a“挡”在最前面,scanf进去先碰到的总是a,也就无法取到它后面的整数,所以必须先将a“弄走”。这就牵涉到“清空输入缓冲区”的概念,这个稍后再讲。
注意:在使用scanf之前请使用printf提示输入,这样看起来更加清楚用户要输入什么数据。
运算符和表达式
C语言中的运算符有很多,但本章只介绍下面四个:算术运算符、关系运算符、逻辑运算符和赋值运算符。这四个是C语言中最基本的运算符,其他运算符等到后面用到的时候再讲。
表达式就是指用运算符连接起来的、有意义的式子。表达式就是一个式子,是不带分号的。带分号的是语句。
算数运算符
在C语言中,除法“/”的运算结果与运算对象的数据类型有关。如果两个数都是int型,那么商就是int型,若商有小数,则舍去小数部分,只取整数部分作为结果;两个数中只要有一个是浮点型数据(包括两个都是浮点型),那么结果就是浮点型,不舍去小数部分。
在实际编程中,取余“%”用得很少,但也有必要了解一下。取余“%”只需掌握两点就掌握其精髓了:
1)取余“%”的运算对象必须是整数,运算结果是整除后的余数。
2)运算结果的符号与被除数的符号相同。只看被除数的符号,不看除数的符号。
关系运算符
在C语言中,关系运算符也是用得非常多的,主要用于条件结构和循环结构程序设计中。这几个运算符中,>=、<=、!=、==与数学中的符号外形上有所不同,但用法上是一样的。其中主要需要注意“==”,在数学中,等于用“=”表示,而在C语言中“=”表示赋值,双等号“==”才表示“等于”。
逻辑运算符
逻辑运算符主要有:&&:逻辑与 ||:逻辑或 ! :逻辑非
逻辑与“&&”就是“并且”的意思;逻辑或“||”就是“或者”的意思;而逻辑非“! ”是“反过来”的意思。
在C语言中用什么表示真,用什么表示假呢?“真”用1表示,“假”用0表示。所以逻辑运算的结果要么是1,要么是0,因为逻辑运算的结果要么是真,要么是假。
对于逻辑与(&&)运算符,当左边是假的时候,右边就不执行,这个一定要记住。也因为这个原因,逻辑与又称为“短路与”。
那么逻辑或(||)呢?当“或”的左边是真的时候,那么不管右边是真还是假,结果都是真,所以此时右边就不会执行了。所以逻辑或又称为“短路或”,即当左边为真的时候右边就相当于被短路了,不会执行。
赋值运算符
赋值运算符:
1.=
2.+=
3.-=
4.*=
5./=
其中后面四个都是“=”的扩展。以“+=”为例:
a += 3;就等价于:
a = a + 3;运算符的优先级
所谓优先级就是当一个表达式中有多个运算符时,先计算谁,后计算谁。
在编程的时候其实不需要考虑优先级的问题。因为如果不知道优先级高低的话,加一个括号就可以了,因为括号“()”的优先级是最高的。
此外运算符还有“目”和“结合性”的概念,这个很简单。“目”就是“眼睛”的意思,一个运算符需要几个数就叫“几目”。比如加法运算符“+”,要使用这个运算符需要两个数,如3+2。对“+”而言,3和2就像它的两只眼睛,所以这个运算符是双目的。C语言中大多数的运算符都是双目的,也有单目和三目的。单目运算符比如逻辑非,如!1,它就只有一只眼睛,所以是单目的。整个C语言中只有一个三目运算符,即条件运算符“ ? : ”。
那么“结合性”是什么呢?上面讲的优先级都是关于优先级不同的运算符参与运算时先计算谁后计算谁。但是如果运算符的优先级相同,那么先计算谁后计算谁呢?这个就是由“结合性”决定的。比如1+2×3÷4,乘和除的优先级相同,但是计算的时候是从左往右,即先计算乘再计算除,所以乘和除的结合性就是从左往右。就是这么简单!C语言中大多数运算符的结合性都是从左往右,只有三个运算符是从右往左的。一个是单目运算符,另一个是三目运算符,还有一个就是双目运算符中的赋值运算符。
选择结构程序设计
流程控制
所谓流程控制就是指“程序怎么执行”或者说“程序执行的顺序”。
这时有人说:“这不是很简单吗,肯定是从上往下执行啊!”说的没错,程序整体上确实是从上往下执行,但又不单纯是从上往下。这些等到我们学完流程控制之后就明白了。
流程控制可分为三类:第一个是顺序执行。第二个是选择执行。第三个是循环执行。
流程控制是一个叫“图灵”的人提出来的。这个人对计算机的贡献很大,所以为了纪念他,计算机领域专门设立了一个“图灵奖”。
图灵最大的贡献就是他认为现在所有的程序,小到一个计算器,大到宇宙飞船,无论是多么复杂的程序,只需要用三种结构就可以将它设计出来。这三种结构就是顺序、选择和循环。他认为,只需要将这三种结构组合在一起,就可以解决现实世界中任何一个复杂的问题。
选择执行的定义和分类
什么是选择执行?选择执行就是“某些代码可能执行,也可能不执行,有选择地执行某些代码”。
选择执行分两类:if和switch。if是“如果”的意思,switch是“开关”的意思。其中用得最多的是if。switch用得不多,但用得不多不代表不重要,switch同样非常重要。
if语句
if最简单的格式是:
if (表达式){语句}功能:如果表达式为真,就执行下面的语句;如果表达式为假,就不执行下面的语句。
只要if后面的表达式成立或非零,就执行其下的语句。表达式为0的时候即假,就不执行其下的语句了。
if的控制范围问题:if只能控制其后的一个语句。如果要控制多个语句就必须加大括号“{}”。
注意:if、else、for、while、do后面的执行语句不论有多少行,就算只有一行也要加“{}”。这是规范问题,大家一定要记住。按规范书写就不容易出错,看着也舒服。
if … else的用法:
#include<stdio.h>int main(void) {int i, j;printf("请输入两个数:"); //提示输入scanf("%d %d", &i, &j); //注意取地址符&if (i>j) {printf("i大于j\n");} else {printf("i小于j\n");}return 0;
}
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
请输入两个数:43 56
i小于j
--------------------------------------
*/前面强调,scanf中双引号内多个“输入控制符”之间不要加任何“非输入控制符”。但这里我要说的是:“可以加一个符号”,就是“空格”。空格在scanf中比较特殊,虽然它是“非输入控制符”,但它又算不上是真正的需要“原样输入”。因为就算不加空格,从键盘输入的时候还是要加空格(或回车)。而且在scanf中添加一个空格,输入的时候输入100个空格也是正确的;在scanf中添加100个空格,而输入的时候只输入一个空格也是正确的。所以说算不上是真正的“原样输入”。
那么scanf中“%d”之间为什么要加空格呢?原因只有一个——“好看”。如果不加空格的话,看起来就很挤,不好看。但是尽管如此,仍然建议你们什么都不要加,统一思维和用法。在实际编程中也是不要求加空格的,在这里只是告诉你们可以这么做。
if可以没有else单独使用,这个前面已经应用过了。但如果要用else,它必须是if的一部分。else绝对不可能脱离if而单独使用,这一点大家一定要注意。
注意:在C语言中,一个分号也是一条语句,叫“空语句”,就是一个什么都不执行的语句。
这里顺便给大家介绍一下“三目运算符”。在前面讲优先级的时候提到过它。在整个C语言中只有一个三目运算符,它的格式是:
表达式1?表达式2:表达式3它就相当于:
if (表达式1){表达式2;}else{表达式3;}if…else if…else的用法:
if…else if…else的意思就是:“如果”第一个成立,就执行第一个;“否则 如果”第二个成立就执行第二个;“否则”就执行第三个。这个应该很好理解吧,与我们平时讲话时的思维逻辑一样。
强调:在printf中,不管是float还是double型变量都可以用“%f”,只不过在printf中double型变量用“%f”精度会降低而已。但是在scanf中,double型变量只能用“%lf”(其中l是字母L的小写,不是数字1),如果用“%f”就是错的。
if的常见问题解析
(1)if后面最好加上else这一点大家一定要注意,分号不能乱加。
我们看一个程序:
#include<stdio.h>int main(void) {if (3>2) {printf("I Love You\n");}return 0;
}
不加else的if程序,在语法上是正确的,就算是if…else if…else if…else把最后的那个else去掉也是正确的,但这样写不好。这样写虽然语法上不会出错,但逻辑上有漏洞。若黑客抓住这个漏洞,他就会加上else执行一个病毒语句,这样就很危险了。所以在编写正规程序的时候,是不允许出现这样的漏洞的,一定要加else。例如上面这个程序可以这么写:
#include<stdio.h>
int main(void) {if (3>2) {printf("I Love You\n");} else {;}return 0;
}switch语句
switch是“开关”的意思,它也是一种“选择”语句,但它的用法非常简单。switch是多分支选择语句。说得通俗点,多分支就是多个if。
从功能上说,switch语句和if语句完全可以相互取代。但从编程的角度,它们又各有各的特点,所以至今为止也不能说谁可以完全取代谁。
switch的一般形式如下:
switch (表达式){case常量表达式1: 语句1case常量表达式2: 语句2┇case常量表达式n: 语句ndefault: 语句n+1}说明:
(1)switch后面括号内的“表达式”必须是整数类型。也就是说可以是int型变量、char型变量,也可以直接是整数或字符常量,哪怕是负数都可以。但绝对不可以是实数,也就是float型变量、double型变量、小数常量通通不行,全部都是语法错误。
(2)switch下的case和default必须用一对大括号{}括起来。
(3)当switch后面括号内“表达式”的值与某个case后面的“常量表达式”的值相等时,就执行此case后面的语句。执行完一个case后面的语句后,流程控制转移到下一个case继续执行。如果你只想执行这一个case语句,不想执行其他case,那么就需要在这个case语句后面加上break,跳出switch语句。
(4)如果default是最后一条语句的话,那么其后就可以不加break,因为既然已经是最后一句了,则执行完后自然就退出switch了。
(5)switch是“选择”语句,不是“循环”语句。很多新手看到break就以为是循环语句,因为break一般给我们的印象都是跳出“循环”,但break还有一个用法,就是跳出switch。
(6)每个case后面“常量表达式”的值必须互不相同。
(7)各个case和default的出现次序不影响执行结果。但从阅读的角度最好是按字母或数字的顺序写。
循环控制
循环执行分三类:for、while、do…while。其中用得最多的是for语句,它也是逻辑最清晰、用法最灵活、难度最大的语句,所以我们要重点介绍for语句。
for循环完全可以代替while循环和do…while循环,凡是while和do…while能实现的功能,for全部能实现。
for循环
for语句的一般形式为:
for (表达式1;表达式2;表达式3){语句;}下面来看看它的执行过程:
1)求解表达式1。
2)求解表达式2。若其值为真,则执行for语句中指定的内嵌语句,然后执行第3步;若表达式2值为假,则结束循环,转到第5步。
3)求解表达式3。
4)转回上面第2步继续执行。
5)循环结束,执行for语句下面的语句。
我们按照一般形式写一个for的简单形式:
for (i=1; i<=100;++i) {
}我们注意到这个形式完全可以写成“for (i=1; i<101;++i),而且我们也建议这样写,也就是说,循环语句的循环条件尽量写成半开半闭的,不管是for循环还是while循环。
“for (i=1; i<101;++i)”实际上是1≤i<101,是半开半闭的;而“for (i=1; i<=100;++i)”实际上是1≤i≤100,是全闭的。那么为什么建议使用半开半闭的呢?因为如果写成i<=100的话,那么每次判断的时候都要判断两次,即i<100和i==100,而写成i<101的话每次只需要判断一次。
也许有人说:“程序在执行i<=100的时候不是将它转换成i<100 || i==100吗?这样由“短路或”的知识可知,如果前面的为真那么后面的不就不会执行了吗?这样不也是判断一次吗?”不是这样的,系统是不会将i<=100转换成i<100|| i==100的,每次判断的时候i<100和i==100都要判断。
但是写成半开半闭也有一个问题,就是会影响对代码的理解。有时候写成全闭的区间理解起来才顺畅,而写成半开半闭反而不易理解,而且现在CPU速度那么快,也不在乎那点效率。所以前面说“尽量”,没有要求一定要那样写。
自增和自减
简单地说:++i和i++在单独使用时,都表示i=i+1; --i和i--在单独使用时,都表示i=i -1。
对于自增和自减还有一点需要强调的是:只有“变量”才能进行自增和自减!你认为3++等于多少?C语言中没有这种写法,常量是不能进行自增和自减的。
强制类型转换
首先给大家写一个程序:
#include<stdio.h>
int main(void) {int i;float sum = 0 ;for (i=1; i<101; ++i) {sum = sum + 1/i;}printf("sum = %f\n", sum);return 0;
}
/*在VC++ 6.0中的输出结果是:--------------------------------------sum = 1.000000--------------------------------------
*/大家想想这个程序哪里错了?1+1/2+1/3+1/4+…+1/100结果不可能是1。问题就出在1/i上,还记得前面算术运算符中讲的除“/”吗?
在C语言中,除法“/”的运算结果与运算对象的数据类型有关。如果两个数都是int,则商就是int,若商有小数,则舍去小数部分,只取整数部分作为结果;两个数中只要有一个是浮点型数据,包括两个都是浮点型,那么结果就是浮点型,不舍小数部分。
程序中i定义的是int型,所以1到100之间,除了1以外,1/i都是一个小数,舍去小数部分,只取整数部分,1/i都等于0。所以最后的结果就是1+0+0+…+0,即1。那怎么办?在1/i前面加个“(float)”进行强制类型转换,即:
sum = sum + (float)1/i;它的意思就是将后面的值强制转换成前面的类型,即float型。后面是什么意思?你觉得是将1/i的值强制转换为float型,还是将数字1强制转换为float型?
注意:在C语言中,“强制类型转换”强制转换的是紧跟其后的值或变量。如果需要强制转换一个表达式,那么这个表达式就必须要加括号。如(int)x+y就表示强制将变量x的值转换成int型,然后再与变量y相加;而(int)(x+y)就表示将变量x和y相加得到的值强制转换成int型。
所以“(float)1/i”就表示将数字1强制转换成float型。前面说过,除法中只要有一个是float型,那么结果就是float型,所以将1转换成float型就可以了。
但是注意,千万不能写成“(float)(1/i)”。因为1/i的结果是0,强制转换成float型之后就是0.000000,还是0。
如果1/(float)i将i强制类型转换成float型后,i本身的值有没有发生改变?i是不是就变成float型了?不是的,i本身的值并没有发生改变,它的类型也仍然是int型的。强制类型转换只是产生一个临时的值,然后用这个临时的值进行运算。
此外,上面这个程序其实还有更简单的写法,不需要进行强制类型转换。即直接将1/i写成1.0/i,这样除法里面1.0是实数,那么结果就是实数了。但编译的时候会有一个警告:
conversion from ' double' to ' float' , possible loss of data意思是:将double型赋给float型可能会丢失数据。
在前面讲过,不管是C语言还是Java语言,实数默认都是double类型。float是4字节,有效数字只有7位;而double是8字节,有效数字有16位。将double类型的数据赋给float型,计算机认为将8字节整合成了4字节,很可能会丢失数据,所以产生一个警告。忽略这个警告就可以了,因为在数学计算中一般就要求保留有效数字2~3位,float有7位,已经足够了,所以问题不是很大。
浮点数的存储所带来的问题
float和double都不能保证可以精确地存储一个小数,通常是近似值,这句话一定要记住。
公司面试C语言时通常会考核一个题目:有一个浮点型变量i,如何判断i的值是否是2.3?
很多人感觉这题目挺简单,用if判断一下(i==2.3)就行了,然而,在通常情况下,浮点型数据只能存储近似值。因此在写程序的时候,在if语句中千万不要用浮点数进行比较,不然结果往往都是错。
那么到底该如何判断i的值是否是2.3呢?最标准的写法是这样的:
#include<stdio.h>
#include<math.h> //要用fabs()函数int main(void) {float i = 2.3;if (fabs(i-2.3) < 0.000001) {printf("是2.3\n");} else {printf("不是2.3\n");}return 0;
}
/*在VC++ 6.0中的输出结果是:--------------------------------------是2.3--------------------------------------
*/因为浮点型数据存储的是近似值,所以不能直接判断它是不是2.3。最标准的写法是“如果它跟2.3相差非常非常小,那么就可以近似是2.3”。其中fabs()是C语言中的库函数,直接调用就可以了,它表示求浮点数的绝对值。
scanf再拓展1
前面在介绍scanf的时候说过:在scanf中,从键盘输入的一切数据,不管是数字、字母,还是空格、回车、Tab等字符,都会被当作数据存入缓冲区。如果是用%c获取,那么任何数据都会被当作一个字符,不管是数字还是空格、回车、Tab键。但是scanf中有一个知识点我们前面没有讲,就是scanf最后按的那个回车键也会被存放到缓冲区中。这是scanf非常重要的一个特性,如果忽略的话往往会导致程序出错。因此我们使用完scanf后会用getchar()吸收回车,getcahr()的功能是从缓冲区中取出一个字符,所以通过它就可以将回车符取出来。
但前面也说过,如果是给int型变量赋值,那么%d会跳过回车,这时是不是就不用getchar()了呢?是的,但是为了避免每次都要考虑回车这个问题,习惯上在scanf后面都加上“getchar(); ”。
while循环
while的执行顺序非常简单,它的格式是:
while (表达式){语句;}功能:当表达式为真,则执行下面的语句;语句执行完之后再判断表达式是否为真,如果为真,再次执行下面的语句;然后再判断表达式是否为真……就这样一直循环下去,直到表达式为假,跳出循环。
注意:是不是所有的for循环都可以转化成while循环?答案是“Yes”!同样,所有的while循环也都可以转化成for循环,for循环和while循环可以相互转换。但是前面讲过,用for比用while好。虽然while和for是等价的,但for逻辑性更强,更容易理解,更不容易出错,推荐多使用for循环。
但并不是说只用for循环,不用while循环。for循环的确比while循环用得多,但有些时候用while更方便。比如死循环往往就是用while (1),这样更方便!
do…while
do…while用得不多,主要用于人机交互。它的格式是:
do{语句;}while (表达式);注意:while后面的分号千万不能省略。
do…while和while的执行过程非常相似,唯一的区别是:“do…while是先执行一次循环体,然后再判别表达式”。当表达式为“真”时,返回重新执行循环体,如此反复,直到表达式为“假”为止,此时循环结束。
我们前面讲,while和for是完全等价的,它们是可以相互转换的。那do…while和while、for等价吗?它们可以相互转换吗?答案是“不能”。原因十分简单,while循环体内部不是一定会执行,当表达式一开始就为假的时候它就不会执行。但do…while不管表达式开始为真还是为假,循环体内部最少会执行一次。
scanf再拓展2
程序中可以在scanf后面加上“while(getchar() !=' \n' ); ”,这句是什么意思呢?我们前面讲过getchar()的用法,它可以用来吸收scanf遗留在缓冲区中的回车。这句里面也有getchar(),还有一个while()循环。这是getchar()的高级用法,是真正地清空输入缓冲区。getchar()每次从缓冲区中取出一个字符,只要取出的字符不是回车就一直取,这样就将缓冲区中所有的垃圾字符都取出来了。那么有人会说,要是缓冲区中有多个回车呢?不会的,只要按回车scanf就会进去取数据。
break和continue
前面已经介绍过break语句,它不仅可以跳出“循环体”,还可以跳出switch。break语句不能用于循环语句和switch语句之外的任何其他语句中。当有多层循环嵌套的时候,break只能跳出“包裹”它的最里面的那一层循环,无法一次跳出所有循环。
continue的用法十分简单,其作用为结束本次循环,即跳过循环体中下面尚未执行的语句,然后进行下一次是否执行循环的判定。
continue语句和break语句的区别是,continue语句只结束本次循环,而不是终止整个循环。而break语句则是结束整个循环过程,不再判断执行循环的条件是否成立。而且,continue只能在循环语句中使用,即只能在for、while和do…while中使用,除此之外continue不能在任何语句中使用。所以,再次强调:continue不能在switch中使用,除非switch在循环体中。此时continue表示的也是结束循环体的本次循环,跟switch也没有关系。
那么我们写一个程序来演示一下continue在switch中的应用(前提switch在循环体中):
该程序是用switch模拟电梯。
#include<stdio.h>
int main(void) {int val; //variable的缩写,“变量”的意思printf("请输入您想去的楼层:");while (1) {scanf("%d", &val);switch (val) {case 1:printf("1层开!\n");break; //跳出switchcase 2:printf("2层开!\n");break; //跳出switchcase 3:printf("3层开!\n");break; //跳出switchdefault:printf("该层不存在,请重新输入:");continue; //结束本次while循环}break; //跳出while,这个break不能省略的。}return 0;
}
/*在VC++ 6.0中的输出结果是:--------------------------------------请输入您想去的楼层:4该层不存在,请重新输入:33层开!--------------------------------------
*/此时在default中如果不使用continue的话,那么最后的“该层不存在,请重新输入:”会不起作用。它虽然能输出,但输出之后直接就执行后面的break了,用户仍然没有重新输入的机会。而加continue之后就会结束本次while循环,即后面的break语句本次就不会执行,而是直接进入while循环,这样用户就有“重新输入”的机会了。
清空输入缓冲区
所有从键盘输入的数据,不管是字符还是数字,都是先存储在内存中的一个缓冲区,叫作“键盘输入缓冲区”,简称“输入缓冲区”或“输入流”。
我们先来看一个程序:
#include<stdio.h>
int main(void) {int a, b, c;scanf("%d", &a);printf("a = %d\n", a);scanf("%d", &b);printf("b = %d\n", b);scanf("%d", &c);printf("c = %d\n", c);return 0;
}
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
1
a = 1
2
b = 2
3
c = 3
--------------------------------------
1 2 3
a = 1
b = 2
c = 3
--------------------------------------
*/从输出结果可以看出,不管是一个一个地输入:1(回车)2(回车)3(回车);还是三个数字一次性输入:1(空格)2(空格)3(回车),这两种输入方法的结果都是一样的。原因就是从键盘输入的数据都会被依次存入缓冲区,不管是数字还是字符都会被当成数据存进去。但只有按回车,scanf才会进去取数据,所取数据的个数取决于scanf中“输入参数”的个数。因此不在于怎么输入,我们可以存一个取一个,也可以一次性全存入进去,然后一个个取。
那么一次性全存进去scanf是怎么取的呢?
首先我们输入的数据是放在输入缓冲区中的,先输入的排在最前面,后输入的依次往后排。如果scanf中“输入参数”的个数只有一个,那么我们调用一次scanf就把缓冲区中离出口最近的一个数据输出给scanf,也就是把排在最前面的一个数据输出给scanf。输出后,缓冲区中就没有这个数据了。如果scanf中“输入参数”的个数为n,那么就从排在最前面的开始,依次往后取n个数据输出给scanf。没取完的仍旧放在缓冲区中,直到取用完毕为止。如果缓冲区中的数据全被取完了,但还有scanf要取数据,那就要再从键盘输入数据。
%d和%c读取缓冲区的差别
我们需要注意的是,对于%d,在缓冲区中,空格、回车、Tab键都只是分隔符,不会被scanf当成数据取用。%d遇到它们就跳过,取下一个数据。但是如果是%c,那么空格、回车、Tab键都会被当成数据输出给scanf取用。
例如下面这个程序:
#include<stdio.h>
int main(void) {int a, c;char b;scanf("%d%c%d", &a, &b, &c);printf("a = %d, b = %c, c = %d\n", a, b, c);return 0;
}
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
1 5 6
a = 1, b = , c = 5
--------------------------------------
1
5 6
a = 1, b =
, c = 5
-------------------------------------
1 5 6
a = 1, b = , c = 5
-------------------------------------
1a6
a = 1, b = a, c = 6
-------------------------------------
*/原本我们希望的是将数字1赋给变量a,将字符'5'赋给变量b,将数字6赋给变量c。但从输出结果可以看出,按一下回车,scanf开始到缓冲区中取数据,因为“输入参数”有三个,所以scanf从缓冲区中取三个数据。数字1赋给变量a,而因为变量b是%c,所以前三种情况分别将空格、回车和Tab键赋给变量b,然后数字5赋给变量c,而数字6仍然在缓冲区中,等待下一个scanf来取。这样的话就会有一个问题,我们看下面这个程序:
#include<stdio.h>
int main(void) {int a;char i;while (1) {printf("请输入一个数字:");scanf("%d", &a);printf("a = %d\n", a);printf("您想继续吗(Y/N):");scanf("%c", &i);if ((' Y' == i) || (' y' == i)) {;} else {break; // 跳出本层循环体}}return 0;
}
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
请输入一个数字:10
a = 10
您想继续吗(Y/N):
--------------------------------------
*/当我们输入“10”之后希望系统问:“您想继续吗(Y/N):”,然后输出“Y”就再重新输入一个值,然后输出,否则就跳出本循环体。但是执行的时候我们发现,刚按完“10”然后回车,直接就结束了,都不给我们输入“Y”和“N”的机会,这是为什么?因为输入“10”然后回车,“10”赋给了a,但是回车遗留在了缓冲区,所以等下面又遇到“scanf("%c", &i); ”的时候就直接把字符'\n'赋给变量i了(注意,按回车不是把回车符'\r'存到缓冲区,而是把换行符'\n'存进去了,因为按回车确实就是换行)。字符'\n'明显不等于字符'Y',所以直接break跳出本层循环体。
那么该怎么办呢?方法有两个:第一,既然不想将字符'\n'赋给变量i,那么就先定义一个字符变量ch,然后用scanf将字符'\n'取出来给变量ch,这样就有机会输入“Y”或者“N”了;第二,直接清空输入缓冲区。这里的第一中方法就是用scanf吸收回车,定义变量把'\n'赋值ch,达到了吸收回车的目的,这时有人说,如果缓冲区前面排了三个字符,我都不需要,想先把它们取出来,那是不是要先定义三个变量呢?当然不是!存储不需要的垃圾字符只需要一个变量即可,因为它们都是垃圾,所以直接覆盖就行了。取一个后,再取一个就把第一个覆盖,再取一个就再覆盖。但是在实际编程中我们一般不会用scanf吸收回车,也不会用scanf给一个字符变量赋值,因为有更简单的方法,就是用getchar()。getchar()是专门从缓冲区读取一个字符的函数。它是“吸收回车专业户”,简单、方便、好用。
getchar()
功能是从缓冲区中读取一个字符。这个函数非常简单,连参数都没有,而且非常好用,也非常有用。
下面给出程序:
#include<stdio.h>
int main(void) {int a;char ch;while (1) {printf("请输入一个数字:");scanf("%d", &a);printf("a = %d\n", a);printf("您想继续吗(Y/N):");getchar();/*用getchar吸收回车,简单、方便、好用,都不需要定义变量用来存储获取的回车符*/ch = getchar(); //用getchar从缓冲区中读取一个字符赋给字符变量chif ((' Y' == ch) —— (' y' == ch)) {;} else {break; // 跳出本层循环体}}return 0;
}
/*
在VC++ 6.0中的输出结果是:
--------------------------------------
请输入一个数字:10
a = 10
您想继续吗(Y/N):y
请输入一个数字:5
a = 5
您想继续吗(Y/N):y
请输入一个数字:333
a = 333
您想继续吗(Y/N):n
--------------------------------------
*/在程序中,“ch=getchar(); ”这句之前我们先用getchar()清空缓冲区,然后重新从键盘输入一个字符。同样,必须按回车getchar()才会进去取这个字符。这时候需要注意的是,同scanf一样,按的这个回车也会被遗留在缓冲区中,大家要注意。
这时有人会说,如果前面有多个scanf给int型变量赋值,那么每个scanf都会遗留一个回车,那这时是不是有几个scanf就要用几个getchar()呢?不需要,仍然只需要一个getchar()!这是为什么呢?我们前面说过,当scanf用%d取缓冲区数据的时候,如果遇到空格、回车或Tab键就跳过去。那么被跳过去的这些空白符去哪了呢?系统会如何处置它们呢?它们是不是还在缓冲区中呢?事实上,这些被跳过去的空白符都被释放了。所以假如前面有三个scanf给int型变量赋值,那么第一个scanf输入回车后把回车遗留在了缓冲区,而第二个scanf取值时会越过第一个scanf遗留在缓冲区中的回车,那么这个回车就会从缓冲区中释放。但第二个scanf取完值后也在缓冲区中留下了一个回车,而当第三个scanf到缓冲区中取值时会跳过第二个scanf遗留的回车,这个回车同样也会从缓冲区中释放,所以归根结底最后缓冲区中只有一个回车,也就是说,缓冲区中永远不可能遗留多个回车。
注意,上面讲述了如何吸收回车,但是并不是任何时候我们都需要吸收回车。那么到底什么时候才需要这么做呢?我们知道,当用%d获取输入流中的数据的时候,如果遇到字符(空格、回车、Tab除外),则直接从输入流中退出来,什么都不取。但如果是用%c获取,那么任何数据都会被当作一个字符。所以如果你要从输入流中取一个字符,但在之前使用过scanf,那么此时就必须要先用getchar()吸收回车。否则取到的将不是你想要的字符,而是scanf遗留在输入流中的回车。但是,如果你要从输入流中取的不是字符,那就不需要用getchar()吸收回车了。
此外还有一点在这里跟大家说一下。后面讲字符串的时候会讲到字符数组的赋值,给字符数组赋值时可以用scanf,也可以用gets或fgets。这时候问题就是,在用这三个函数给字符数组赋值的时候,如果之前使用过scanf,那么:
1)当使用scanf给字符数组赋值时,之前scanf遗留的回车对其不会产生影响,所以无需吸收回车。因为用scanf将从键盘输入的字符转化为字符串时,输入的内容是以第一个非空白符开始,直到下一个空白符之间的全部字符。空白符指的是空格、回车、Tab键。
2)但是如果使用gets或fgets给字符数组赋值,那么之前scanf遗留的回车将会被它们取出并赋给字符串,并且只能取到这个回车,不再有机会从键盘输入想要的字符串。所以当使用gets或fgets给字符数组赋值时,如果前面使用过scanf,那么必须先用getchar()将回车吸收。这点大家先了解一下,gets和fgets函数稍后再讲。
上面详细分析了什么时候需要吸收回车,什么时候不需要。但是在实际编程中,程序往往很长,我们很难预测到下一次到缓冲区中取数据的是%d还是%c或者是gets()、fgets()。所以为了避免忘记吸收回车或耗费精力考虑回车的问题,习惯上scanf后面都加上getchar()。
fflush(stdin)
前面介绍了使用getchar()吸收回车的方法,除此之外还有一个更强大、更直接的方法,就是直接将输入缓冲区全部清空。那么如何清空缓冲区呢?加一句fflush(stdin)即可。fflush是包含在文件stdio.h中的函数。stdin是“标准输入”的意思。std即standard(标准), in即input(输入),合起来就是标准输入。fflush(stdin)的功能是:清空输入缓冲区。
下面将前面的一个程序修改一下:
#include<stdio.h>int main(void) {int a;char i;while (1) {printf("请输入一个数字:");scanf("%d", &a); //因为读取的是数字,所以不需要清空缓冲区printf("a = %d\n", a);printf("您想继续吗,Y想,N不想:");fflush(stdin);scanf("%c", &i);if (' Y' ==i —— ' y' ==i) {;} else {break; // 跳出本层循环体}}return 0;
}
但是使用fflush(stdin)吸收缓冲区遗留的回车有一点“杀鸡用牛刀”的感觉,我们用getchar()足以应付。所以fflush一般用于清除用户前面遗留的垃圾数据,提高代码的健壮性。因为如果是我们自己编程的话,我们一般都会按要求输入。但对于用户而言,难免会有一些误操作,多输入了一些其他没有用的字符,如果程序中不对此进行处理的话往往会导致程序瘫痪。所以我们在编程的时候一定要考虑到各种情况,提高代码的健壮性和容错性。使用fflush就可以将用户输入的垃圾数据全部清除。但是fflush有一个问题,就是可移植性。并不是所有的编译器都支持fflush,比如gcc就不支持。那么此时怎么办?还是用getchar()。
下面给大家推荐一个getchar()的高级用法:
while (getchar() ! = ' \n' ){;}如果想省事的话可以直接将分号写在while那行的后面。这种用法其实我们在前面也使用过,它可以完全代替fflush(stdion)来清空缓冲区。不管用户输入多少个没用的字符,他最后都得按回车,而且只能按一次。只要他按回车那么回车之前的字符就都会被getchar()取出来。只要getchar()取出来的不是回车(' \n')那么就会一直取,直到将用户输入的垃圾字符全部取完为止。这里再次强调一下,从键盘按回车不是将回车符'\r'放到了缓冲区中,而是将换行符'\n'放到了缓冲区中,因为回车本身就是换行。
![[机器视觉]halcon应用实例 找圆](https://img-blog.csdnimg.cn/direct/d9a82e38836842378c8c1a826c0b6d32.png)