文章目录
- 0. Abstract
- 1. Introduction
- 2. Related Work
- 3. Method
- 3.1 Overall Architecture
- 3.2 Shifted Window based Self-Attention
- 3.3 Architecture Variants
- 4. Experiments
- 4.1 Image Classification on ImageNet-1K
- 4.2 Object Detection on COCO
- 4.3 Semantic Segmentation on ADE20K
- 4.4 Ablation Study
- 5. Conclusion
- 6. Acknowledgement
- References
- My thought
- 彩蛋

论文链接: https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.pdf
Article Reading Sharing
0. Abstract
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision.
本文提出了一种新的视觉变压器,称为Swin变压器,它可以作为计算机视觉的通用骨干。
Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
将Transformer从语言应用到视觉的挑战来自于这两个领域之间的差异,例如视觉实体规模的巨大差异以及与文本中的单词相比,图像中像素的高分辨率。
To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows.
为了解决这些差异,我们提出了一个分层的Transformer,它的表示是用移位窗口计算的。
The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection.
移位窗口方案将自关注计算限制在不重叠的局部窗口,同时允许跨窗口连接,从而提高了效率。
This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size.
这种层次结构具有在各种尺度上建模的灵活性,并且相对于图像大小具有线性计算复杂度。
These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO testdev) and semantic segmentation (53.5 mloU on ADE20K val).
Swin Transformer的这些特性使其与广泛的视觉任务兼容,包括图像分类(ImageNet-1K上的87.3 top-1精度)和密集预测任务,如对象检测(COCO testdev上的58.7 box AP和51.1 mask AP)和语义分割(ADE20K val上的53.5 mIoU)。
Its performance surpasses the previous state-of-theart by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mloU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
其性能在COCO上大幅超过了+2.7 box AP和+2.6 mask AP,在ADE20K上超过了+ 3.2 mloU,显示了基于transformer的模型作为视觉骨干的潜力。
The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.
分层设计和移位窗口方法也被证明对所有MLP体系结构都是有益的。
capably serves as a general-purpose(通用) backbone for computer vision.
such as large variations (变化) in the scale of visual entities (实体) and the high resolution of pixels
in images compared to words in text
a hierarchical (分层) Transformer whose representation is computed with Shifted windows.
scheme(计划)brings greater efficiency by limiting self-attention computation to non-overlapping local
windows while also allowing for cross-window connection.
These qualities of Swin Transformer make it compatible with a broad range of vision tasks
dense (密集) prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val)
surpasses (超过) the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on
COCO, and +3.2 mIoU on ADE20K, demonstrating (展示) the potential of Transformer-based models as vision backbones.
代码仓库:https://github.com/microsoft/Swin-Transformer
1. Introduction
本文旨在扩展transformer为计算机视觉的通用backbone,与CNN形成竞争,以提高其在图像分类和视觉语言模型任务上的表现。
Swin Transformer适合作为各种视觉任务的通用主干,与以前基于Transformer的架构形成鲜明对比。
has long been dominated(主导)by convolutional neural networks (CNNs).
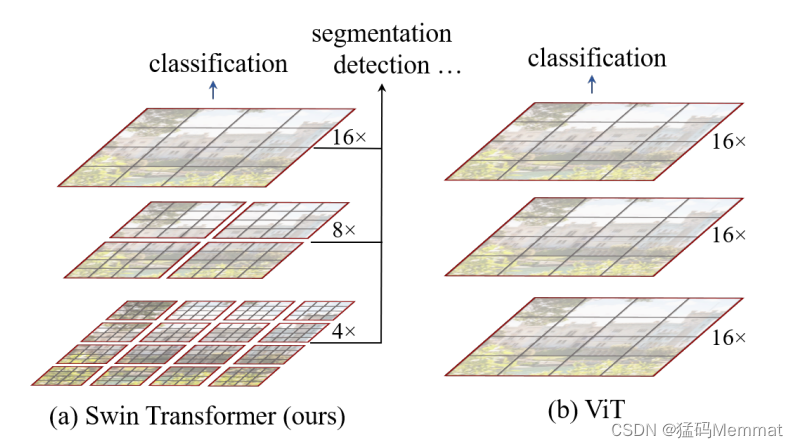
Figure 1. (a) The proposed Swin Transformer builds hierarchical feature maps by merging (合并) image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus (因此) serve as a general-purpose backbone for both image classification and dense recognition tasks. (b) In contrast, previous vision Transformers [19] produce feature maps of a single low resolution and have quadratic (二次) computation complexity to input image size due to computation of self-attention globally.
the prevalent (普遍的)architecture today is instead the Transformer
Designed for sequence modeling and transduction tasks, the Transformer is notable (值得注意)for its use
of attention to model long-range dependencies(依赖) in the data.
demonstrated promising (有前途) results on certain tasks
between the two modalities(模式)
can vary substantially(大幅) in scale
this would be intractable(难以对付) for Transformer on high-resolution images
would be intractable(棘手的) for Transformer on high-resolution images, as the computational complexity of its self-attention is quadratic(二次)
conveniently leverage (利用)advanced techniques for dense prediction such as feature pyramid networks (FPN) [38] or U-Net [47]. The linear computational complexity is achieved by computing self-attention locally within non-overlapping(重叠) windows that partition an
image (outlined in red).
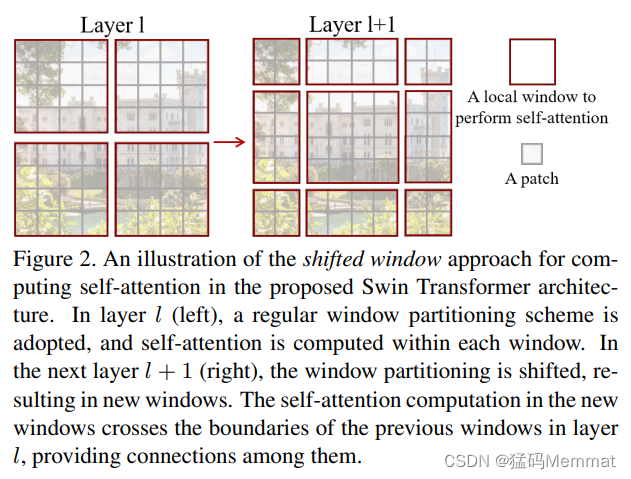
between consecutive (连续) self-attention layers, as illustrated in Figure 2.
strategy is also efficient in regards to real-world latency(延迟): all query patches within a window share the same key set, which facilitates(促进) memory access in hardware.
a unified(统一) architecture across computer vision and natural language processing could benefit both fields, since it would facilitate (促进) joint modeling of visual and textual signals and the modeling knowledge from
both domains can be more deeply shared.
2. Related Work
-
CNN and variants
-
Self-attention based backbone architectures
-
Self-attention/Transformers to complement(补充)CNNs
-
Transformer based vision backbones
本篇工作与Vision Transformer(ViT)非常相关
Our approach is both efficient and effective, achieving state-of-the-art accuracy on both COCO object detection and ADE20K semantic segmentation.
3. Method
3.1 Overall Architecture
It first splits an input RGB image into non-overlapping(非重叠) patches by a patch splitting(分裂) module, like ViT
Each patch is treated as a “token” and its feature is set as a concatenation(连接)of the raw pixel RGB values
project it to an arbitrary(任意) dimension
Several Transformer blocks with modified(修改)self-attention computation (Swin Transformer blocks) are applied on these patch tokens.
is reduced by patch merging(合并) layers as the network
gets deeper
The first patch merging layer concatenates(连接) the
features of
Swin Transformer blocks are applied afterwards(后来) for feature transformation
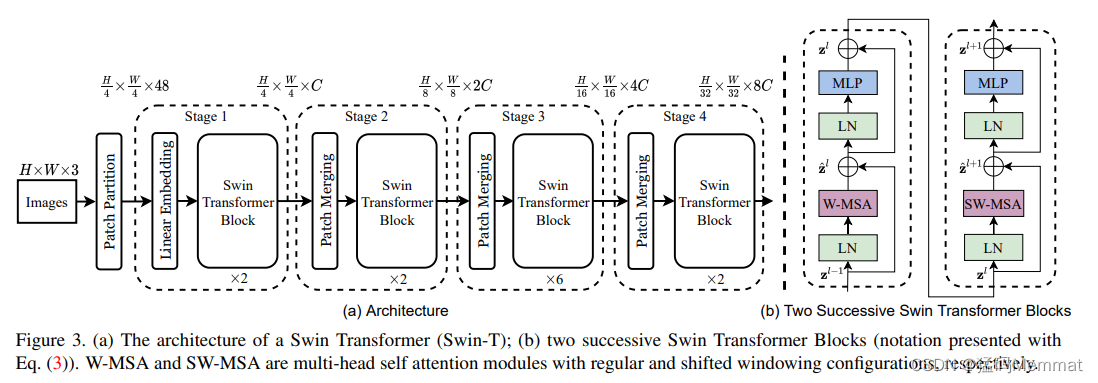
two successive(连续) Swin Transformer Blocks
with regular and shifted windowing configurations(配置), respectively.
- Swin Transformer block
Swin Transformer is built by replacing the standard multi-head self attention (MSA) module in a Transformer block by a module based on
shifted windows
3.2 Shifted Window based Self-Attention
-
Self-attention in non-overlapped windows
-
Shifted window partitioning in successive blocks
-
Efficient batch computation for shifted configuration
-
Relative position bias
3.3 Architecture Variants
除了构建的基础模型swin-B之外,还有swin-T、swin-S、和swin-L

4. Experiments
We conduct experiments on ImageNet-1K image classification [19], COCO object detection [43], and ADE20K semantic segmentation [83].
我们对ImageNet-1K图像分类[19]、COCO目标检测[43]、ADE20K 语义分割 [83]进行了实验。
In the following, we first compare the proposed Swin Transformer architecture with the previous state-of-the-arts on the three tasks.
在下文中,我们将首先比较所建议的Swin Transformer体系结构与之前关于这三个任务的最新技术。
Then, we ablate the important design elements of Swin Transformer.
然后,对Swin变压器的重要设计要素进行了分析。
4.1 Image Classification on ImageNet-1K
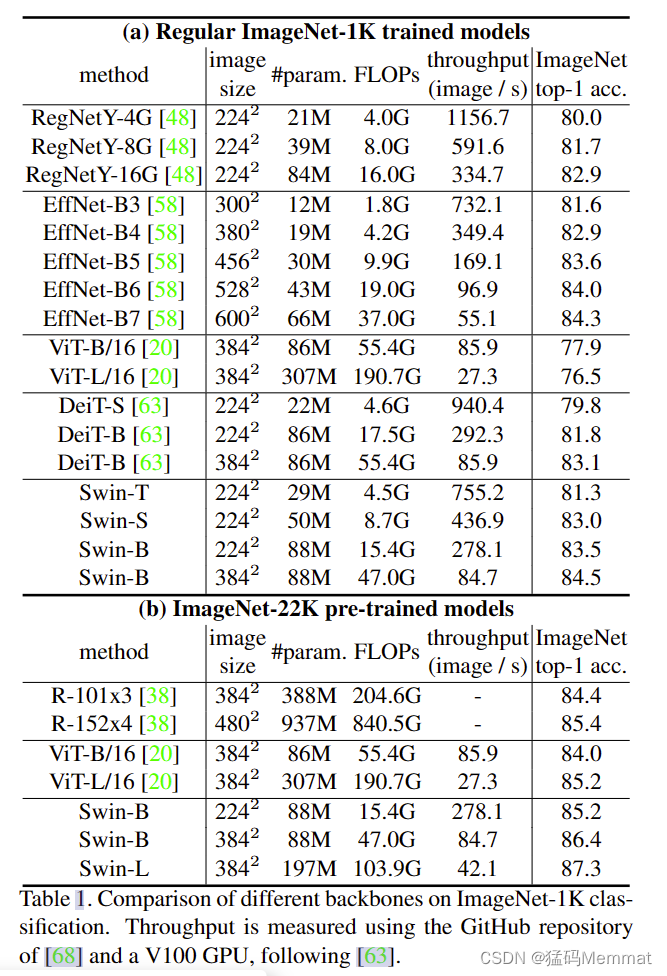
4.2 Object Detection on COCO
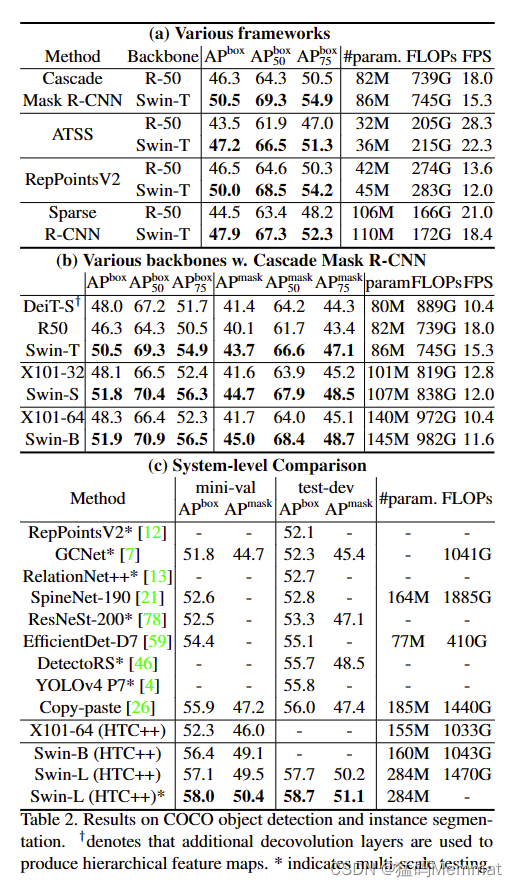
4.3 Semantic Segmentation on ADE20K
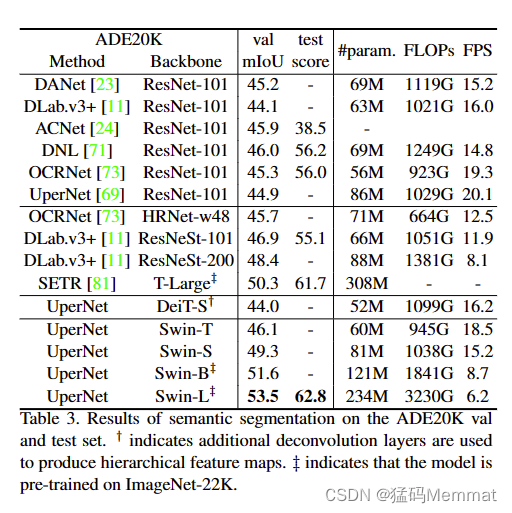
FLOPS 注意全部大写 是floating point of per second的缩写,意指每秒浮点运算次数。用来衡量硬件的性能。
FLOPs 是floating point of operations的缩写,是浮点运算次数,可以用来衡量算法/模型复杂度。
4.4 Ablation Study
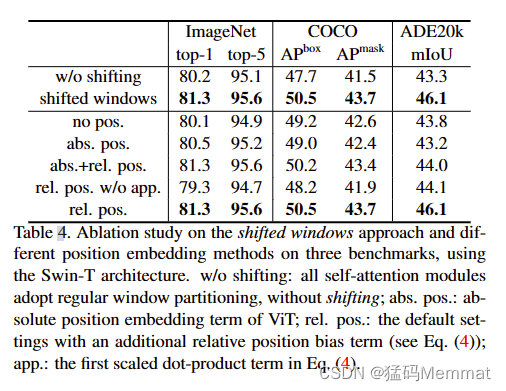
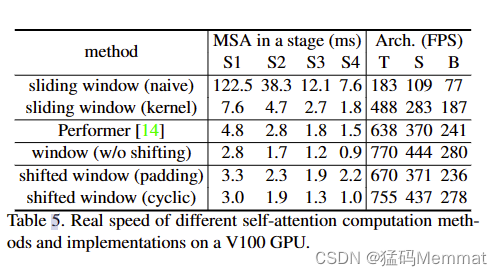
5. Conclusion
swin transformer 可以产生 层次特征表示 和 相对于输入图像的大小 具有线性计算复杂度,在COCO和ADE20K方面实现了SOTA。
本文提出的基于位移窗口的自注意力在视觉问题上是有效和高效的。
6. Acknowledgement
We thank many colleagues at Microsoft for their help, in particular, Li Dong and Furu Wei for useful discussions; Bin Xiao, Lu Yuan and Lei Zhang for help on datasets.
此部分不包含已有作者。
References
https://github.com/microsoft/Swin-Transformer
https://gitcode.com/microsoft/Swin-Transformer/overview?utm_source=csdn_github_accelerator&isLogin=1
https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.pdf
My thought
swin transformer 更强调在视觉任务和语言任务上的通用性,本文更强调其在不同视觉任务上的backbone能力。
彩蛋
轻松一刻

欢迎在评论区讨论本文

![[机器视觉]halcon应用实例 找圆](https://img-blog.csdnimg.cn/direct/d9a82e38836842378c8c1a826c0b6d32.png)