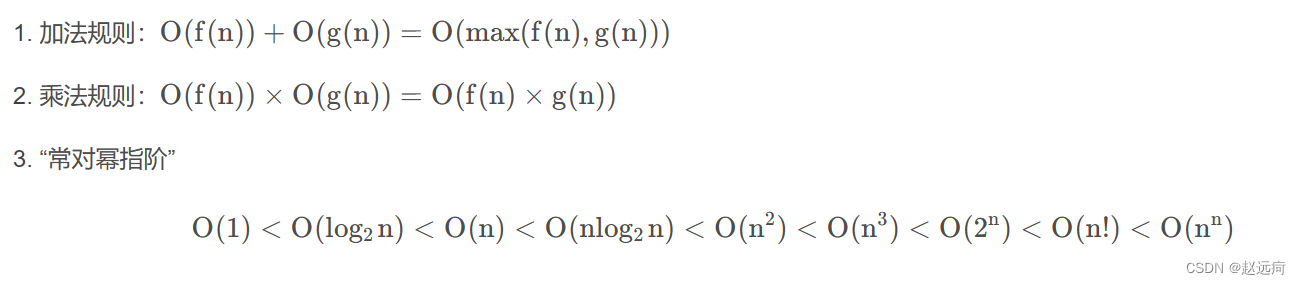classSolution:defhIndex(self, citations: List[int])->int:# 根据定义,h 指数的理论最大值max_h =min(max(citations),len(citations))# 从 max_h 开始反向遍历考察所有 h 指数的可能取值 i for i inrange(max_h,-1,-1):# 统计引用次数 >= i 的论文数量paper_cnt =0for cite in citations:if cite >= i:paper_cnt +=1# 满足 h 指数定义则返回if paper_cnt >= i:return ireturn0
时间复杂度 O ( n 2 ) O(n^2) O(n2),空间复杂度 O ( 1 ) O(1) O(1)
11.2 解法2:计数排序
以上暴力法中,对于每一个候选的 h 指数取值都做了一次遍历计数,因此时间复杂度高。一种优化方式是,先用过一次遍历完成所有计数操作,再通过另一次和暴力法相同的反向遍历确定 h 指数的值。具体而言,第一次遍历中我们用 defaultdict 统计引用量为 h 指数各可能取值i 的论文数量,之后在反向遍历时通过求和得到引用量 >=i 的论文数量
这种方法通过引入 O ( n ) O(n) O(n) 的额外存储空间,将时间复杂度从 O ( n 2 ) O(n^2) O(n2) 降低到 O ( n ) O(n) O(n)
classSolution:defhIndex(self, citations: List[int])->int:# 根据定义,h 指数的理论最大值max_h =min(max(citations),len(citations))# 用 counter 统计引用量 >= 不同 cite 值的论文数量from collections import defaultdictcounter = defaultdict(int)for cite in citations:cite = max_h if cite > max_h else citecounter[cite]+=1# 从 max_h 开始反向遍历考察所有 h 指数的可能取值 i tot =0for i inrange(max_h,-1,-1):tot += counter[i]# 引用量不少于 i 次的论文总数if tot >= i:# 满足 h 指数定义则返回return ireturn0
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
11.3 解法3:排序
先初始化 h=0,然后把引用次数 citations 排序并大到小遍历。如果当前 h 指数为 h 并且在遍历过程中找到当前值 citations[i]>h,则说明我们找到了一篇被引用了至少 h+1 次的论文,所以 h+=1。继续遍历直到 h 无法继续增大后返回即可
classSolution:defhIndex(self, citations: List[int])->int:sorted_citation =sorted(citations, reverse =True)h =0; i =0; n =len(citations)while i < n and sorted_citation[i]> h:h +=1i +=1return h
时间复杂度 O ( n l o g n ) O(nlogn) O(nlogn),空间复杂度 O ( l o g n ) O(logn) O(logn)(这两个都是排序算法的复杂度)
12. [中等] O(1) 时间插入、删除和获取随机元素
题目链接
标签:设计、数组、哈希表、数学
12.1 解法1:哈希表+变长数组
要求实现插入、删除和获取随机元素操作的平均时间复杂度为 O ( 1 ) O(1) O(1)
变长数组:可以在 O ( 1 ) O(1) O(1) 的时间内完成获取随机元素操作。但是由于需要 O ( n ) O(n) O(n) 时间判断元素是否存在,因此无法满足插入和删除的时间复杂度要求
哈希表:哈希表的核心思想,是通过函数函数把元素映射到存储位置索引,这样就能在 O ( 1 ) O(1) O(1) 的时间内判断元素是否存在,或找到元素存储位置进行插入或删除。但哈希表无法在 O ( 1 ) O(1) O(1) 时间内获取当前全体元素,因此无法满足随机取元素的时间复杂度要求
通过结合变长数组和哈希表,可以实现题目要求
classRandomizedSet:def__init__(self):from collections import defaultdictimport randomself.item =[]# 在此存储元素self.idx ={}# 哈希表,将元素映射到其在 self.item 中的索引位置definsert(self, val:int)->bool:if val in self.idx:returnFalseself.item.append(val)self.idx[val]=len(self.item)-1returnTruedefremove(self, val:int)->bool:ifnot val in self.idx:returnFalseidx_val = self.idx[val] item_last = self.item[-1] self.item[idx_val]= item_last # self.item 中,用 item_last 替换目标元素self.idx[item_last]= idx_val # self.idx 哈希表中,更新 item_last 对应的索引位置self.item.pop()# 弹出已经移动到 idx_val 处的 item_lastdel self.idx[val]# 删除目标元素在哈希表中的索引returnTruedefgetRandom(self)->int:return random.choice(self.item)# Your RandomizedSet object will be instantiated and called as such:# obj = RandomizedSet()# param_1 = obj.insert(val)# param_2 = obj.remove(val)# param_3 = obj.getRandom()# @lc code=end
classSolution:defproductExceptSelf(self, nums: List[int])-> List[int]:# pre_prods 存储每个索引位置所有前驱元素乘积# post_prods 存储每个索引位置所有后继元素乘积pre_prod, post_prod =1,1pre_prods, post_prods =[],[]left, right =0,-1for i inrange(len(nums)):pre_prods.append(pre_prod)post_prods.append(post_prod)pre_prod *= nums[left]post_prod *= nums[right]left +=1right -=1post_prods.reverse()# 输出中每个索引位置,取 pre_prods 和 post_prods 对应位置元素相乘即可res =[]for i inrange(len(nums)):res.append(pre_prods[i]* post_prods[i])return res
时间复杂度 O ( n ) O(n) O(n),空间复杂度 O ( n ) O(n) O(n)
13.2 解法2:左右乘积列表
以上方法需要构造存储前缀积和后缀积的两个辅助列表。为了减少空间复杂度,可以先构造前缀积列表,然后在计算后续元素乘积时直接将其乘到前缀积列表中并作为输出。这样可以把空间复杂度降低到 O ( 1 ) O(1) O(1)(不考虑输出数组)
classSolution:defproductExceptSelf(self, nums: List[int])-> List[int]:# pre_prods 存储每个索引位置所有前驱元素乘积pre_prod =1res =[]for num in nums:res.append(pre_prod)pre_prod *= num# 再把后续元素乘积直接乘到 res 的对应位置上,实现 O(1) 的空间复杂度post_prod =1for i inrange(len(nums)-1,-1,-1):res[i]*= post_prodpost_prod *= nums[i]return res
经过两次遍历得到 L 和 R 后,直接给第 i i i 个小孩分配 max(L[i], R[i]) 颗糖果即可。为了分析这种操作的正确性,假设 L [ i ] > R [ i ] L[i] > R[i] L[i]>R[i],则 max ( L [ i ] , R [ i ] ) = L [ i ] \max(L[i], R[i]) = L[i] max(L[i],R[i])=L[i],此时左规则一定满足,考虑右规则
若 ratings[i]>ratings[i+1],此时分配数量 L [ i ] > R [ i ] > R [ i + 1 ] L[i]>R[i]>R[i+1] L[i]>R[i]>R[i+1] 一定满足右规则
若 ratings[i-1]>ratings[i],这意味着 i i i 处于一个递减序列内,此时 L [ i ] = 1 L[i]=1 L[i]=1,不可能有 L [ i ] > R [ i ] L[i] > R[i] L[i]>R[i],故增加给第 i i i 个小孩的糖果数量不会导致在 i − 1 i-1 i−1 处违反右规则
综上,给出如下的求解代码
classSolution:defcandy(self, ratings: List[int])->int:n =len(ratings)# 仅考虑左规则对应的最少糖果分配left =[1,]for i inrange(n-1):left.append(left[i]+1if ratings[i+1]> ratings[i]else1)# 仅考虑右规则对应的最少糖果分配ratings.reverse()right =[1,]for i inrange(n-1):right.append(right[i]+1if ratings[i+1]> ratings[i]else1)right.reverse()# max 操作确定每个索引处同时满足左右规则的糖果数,求和returnsum([max(l, r)for l, r inzip(left, right)])